1. 知识理解
1.1 input()函数

1.2 init 和new的区别
init 在对象创建后,对对象进行初始化。 new 是在对象创建之前创建一个对象,并将该对象返回给 init。
init方法
class Person():def __init__(self,name,age):self.age=ageself.name=namedef __str__(self):return ('%s age is %s' %(self.name,self.age) )person = Person('zxy',19)print(person)
这样便是init最普通的用法了。但init其实不是实例化一个类的时候第一个被调用 的方法。当使用 Persion(name, age) 这样的表达式来实例化一个类时,最先被调用的方法 其实是 new 方法。
new方法
class Person():def __init__(self,name,age):print('init方法')self.age=ageself.name=namedef __new__(cls, *args, **kwargs):print('new方法')return super(Person,cls).__new__(cls)def __str__(self):return ('%s age is %s' %(self.name,self.age) )person = Person('zxy',19)print(person)
执行结果:
new方法init方法zxy age is 19
我们可以看到,new方法的调用是发生在init之前的。其实当 你实例化一个类的时候
具体的执行逻辑是这样的:
p = Person(name, age)
首先执行使用name和age参数来执行Person类的new方法,这个new方法会 返回Person类的一个实例(通常情况下是使用 super(Persion, cls).new(cls) 这样的方式),
然后利用这个实例来调用类的init方法,上一步里面new产生的实例也就是 init里面的的self
总结
所以,init 和 new 最主要的区别在于:
new 通常用于控制生成一个新实例的过程。它是类级别的方法。
init 通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。
1.3 range和xrange的区别
Python2中 两者用法相同,不同的是 range 返回的结果是一个列表,而 xrange 的结果是一个生成器,前者是 直接开辟一块内存空间来保存列表,后者是边循环边使用,只有使用时才会开辟内存空间,所以当列表 很长时,使用 xrange 性能要比 range 。
Python3中range与xrange合并为range
1.4 平常工作中用什么工具进行静态代码分析

1.5 小内存读取大文件,怎么读取
方法一:一行一行读取
def get_file_data_with_readline():with open(r'D:\Rexel数据\EHSY_DATA_V2.csv', 'r', encoding='utf-8') as f:while True:data = f.readline()if data:print(data)else:return
高级写法:用生成器
def get_file_data_with_readline_generator():with open(r'D:\Rexel数据\西域\orderNum_map_img.csv', 'r', encoding='utf-8') as f:while True:data = f.readline()if data:yield dataelse:return
这两种方法都是从文件第一行读取到最后一行,对于非常大的文件,读取速度较慢
方法二:
可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后 在读取后面的 500MB 的数据。
def get_file_data_with_read_generator(size=1024*1024):with open('demo1.py', 'r', encoding='utf-8') as f:while True:data = f.read(size)if data:yield dataelse:return
这样就每次通过读取指定字符长度把整个文件输出了
方法三:将文件先切割成若干大小
参考:https://www.yuque.com/u1046159/erg6ec/ykr0ps
1.6 赋值、浅拷贝、深拷贝的区别
对象类型
在python中有6个标准数据类型,他们分为可变和不可变两类。
不可变类型:Number(数字)String(字符串)Tuple(元组)
可变类型:List(列表)Dictionary(字典)Set(集合)
可变对象和不可变对象的内存地址可以通过id函数获取
可变对象:可变对象可以在其 id() 保持固定的情况下改变其取值;
不可变对象:具有固定值的对象。不可变对象包括数字、字符串和元组。这样的对象不能被改变。如果必须存储一个不同的值,则必须创建新的对象。
id(object): 函数用于获取对象的内存地址,函数返回对象的唯一标识符,标识符是一个整数
赋值
在 Python 中,对象的赋值就是简单的对象引用
a = [1,3,4]b = a
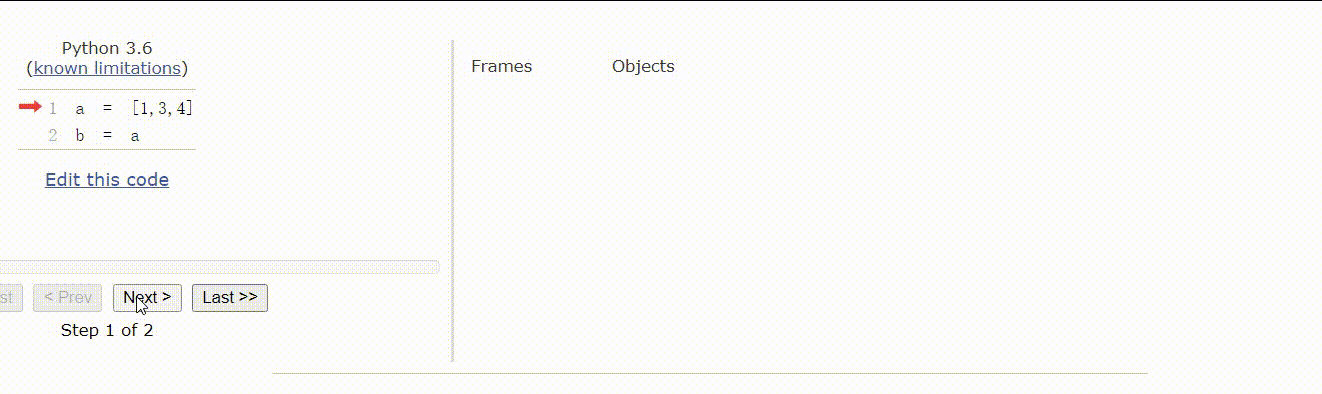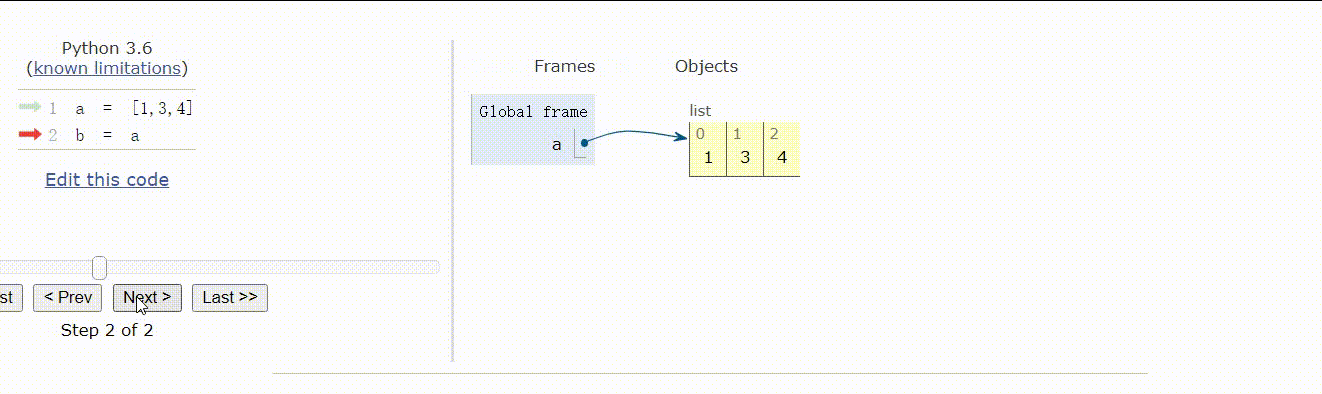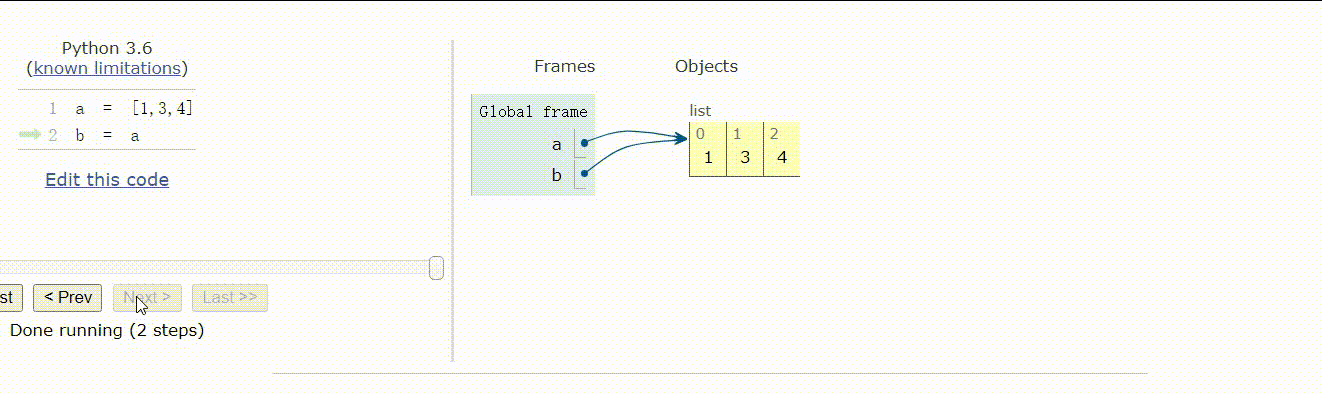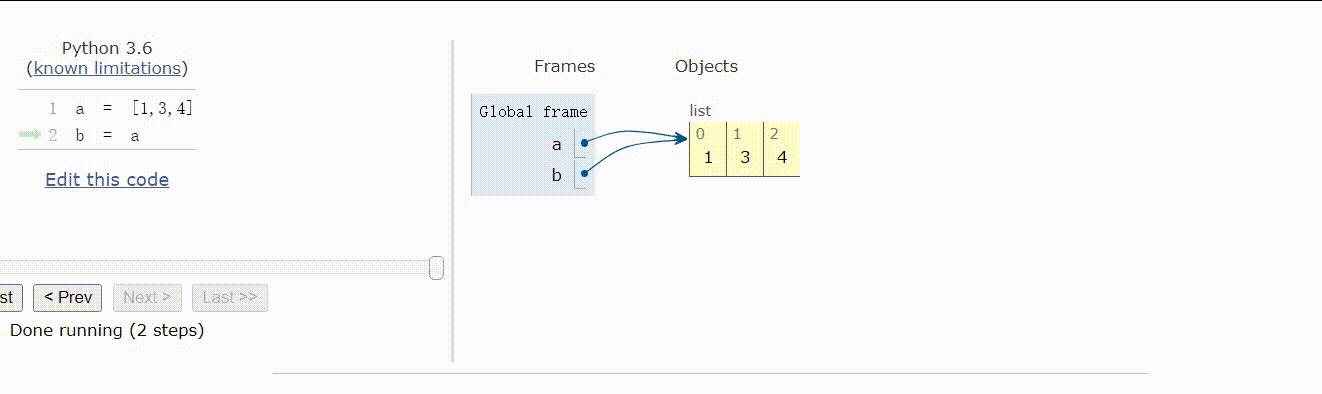
在上述情况下,a 和 b 是一样的,他们指向同一片内存,b 不过是 a 的别名,是引用。
我们可以使用 b is a 去判断,返回 True,表明他们地址相同,内容相同,也可以使用 id()函数来查 看两个列表的地址是否相同。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是 说除了 b 这个名字之外,没有其他的内存开销。修改了 a,也就影响了 b,同理,修改了 b,也就影响了a
浅拷贝(copy)
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。
浅拷贝有三种形式:切片操作、工厂函数、copy
a = [1,3,4]# 切片操作b = a[:]# 工厂函数b = list(a)# copyimport copyb = copy.copy(a)

浅拷贝copy详解
import copya = [1, "hello", [2, 3], {"key": "123"}]b = copy.copy(a)# 外面容器拷贝了,所以a和b的id不一样print(id(a))print(id(b))print('==========')# a和b容器里面的元素对象idprint(id(a[1]))print(id(b[1]))import copya = [1, "hello", [2, 3], {"key": "123"}]b = copy.copy(a)# 外面容器拷贝了,所以a和b的id不一样print(id(a))print(id(b))# a和b容器里面的元素对象"hello"的idprint(id(a[1]))print(id(b[1]))
结果:
14463511728081446351466248==========14463488948721446348894872
浅拷贝产生的列表b不再是列表a了,可以通过id发现,内存地址不一样;但是a与b中元素的地址是相同的

上面动图可能会有些误解,a与b列表中”hello”地址是一样的,可以通过id(a[1])与id(b[1])发现内存地址一样,即a与b中元素内存地址都是一样的
浅拷贝是拷贝了list外面一层的, 创建一个新的容器对象(compound object),所以a和b的id是不一样的
对于容器里面的元素对象,浅拷贝就只会使用原始元素的引用(内存地址),所以可以看到子元素的内存地址还是一样的
如果改变a里面的不可变对象数字,此时a和b的值就不一样了,但是b与a中元素内存地址还是相同的
import copya = [1, "hello", [2, 3], {"key": "123"}]b = copy.copy(a)# 改变a的不可变对象数字 1 --> 2a[0] = 2print(id(a))print(id(b))print('=========')print(id(a[0]))print(id(b[0]))print('=========')print(id(a[1]))print(id(b[1]))print(a)print(b)
结果:
139651781056456139651601358728=========139651779565504139651779565472=========139651781217392139651781217392[2, 'hello', [2, 3], {'key': '123'}][1, 'hello', [2, 3], {'key': '123'}]

可以发现我们修改了a中的数字a[0] = 2,a与b内容不同,两个列表的地址不同,修改的元素地址不在相同,未修改的元素在内存中地址仍然相同
如果改变a里面的可变对象-列表, 把[2, 3]里面的3改成 [2, 4]
import copya = [1, "hello", [2, 3], {"key": "123"}]b = copy.copy(a)# 改变a的可变对象[2,3] --> [2, 4]a[2][1] = 4print(id(a))print(id(b))print('=========')print(id(a[2]))print(id(b[2]))print(a)print(b)
结果:
140451953312136140451976945160=========140451955973704140451955973704[1, 'hello', [2, 4], {'key': '123'}][1, 'hello', [2, 4], {'key': '123'}]
此时发现修改a中可变对象,发现b随着a的变化而变化,这就是浅拷贝
深拷贝
深拷贝只有一种形式,copy 模块中的 deepcopy()函数
深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。
同样的对列表 a,如果使用 b = copy.deepcopy(a),再修改列表 a 将不会影响到列表b,即使嵌 套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象, 不再与原来的对象有任何的关联。
import copya = [1, "hello", [2, 3], {"key": "123"}]b = copy.deepcopy(a)# 改变a的不可变对象[2,3] --> [2, 4]a[2][1] = 4print(id(a))print(id(b))print('=========')print(id(a[2]))print(id(b[2]))print(a)print(b)
结果:
140414914310472140414937943688=========140414916972040140415116983688[1, 'hello', [2, 4], {'key': '123'}][1, 'hello', [2, 3], {'key': '123'}]

1.7 作用域
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
1.8 Python实例方法、类方法、静态方法的区别与作用
参考:https://www.cnblogs.com/wcwnina/p/8644892.html
https://zhuanlan.zhihu.com/p/40162669
class MyClass():# 实例方法def instance_method(self):print('instance method called', self)# 类方法@classmethoddef class_method(cls):print('class method called', cls)# 静态方法@staticmethoddef static_method():print('static method called')

调用上面三个方法:
my_class = MyClass() # 实例化my_class.instance_method() # 实例方法my_class.class_method() # 类方法my_class.static_method() # 静态方法
1.9 Python中不可变对象与可变对象
不可变对象
可变对象
Python中可哈希≈ 不可变对象
这个方法仅仅在序列中元素为 hashable 的时候才管用。 如果你想消除元素不可哈希(比如 dict 类型)的序列中重复元素的话,你需要将上述代码稍微改变一下,就像这样:
def dedupe(items, key=None):
seen = set()
for item in items:
val = item if key is None else key(item)
if val not in seen:
yield item
seen.add(val)
这里的key参数指定了一个函数,将序列元素转换成 hashable 类型。下面是它的用法示例:
1.10 Python魔法函数
魔法函数概念:在Python中,所有以双下划线__包起来的方法,统称为Magic Method(魔术方法),它是一种的特殊方法,普通方法需要调用,而魔术方法不需要调用就可以自动执行。 也是面试中的高频问题
| 魔术方法 | 作用 |
|---|---|
| new、init、del | 创建和销毁对象相关 |
| add、sub、mul、div、floordiv、mod | 算术运算符相关 |
| eq、ne、lt、gt、le、ge | 关系运算符相关 |
| pos、neg、invert | 一元运算符相关 |
| lshift、rshift、and、or、xor | 位运算相关 |
| enter、exit | 上下文管理器协议 |
| iter、next、reversed | 迭代器协议 |
| int、long、float、oct、hex | 类型/进制转换相关 |
| str、repr、hash、dir | 对象表述相关 |
| len、getitem、setitem、contains、missing | 序列相关 |
| copy、deepcopy | 对象拷贝相关 |
| call、setattr、getattr、delattr | 其他魔术方法 |
1.11 函数参数arg和*kwargs分别代表什么
Python中,函数的参数分为位置参数、可变参数、关键字参数、命名关键字参数。args代表可变参数,可以接收0个或任意多个参数,当不确定调用者会传入多少个位置参数时,就可以使用可变参数,它会将传入的参数打包成一个元组。**kwargs代表关键字参数,可以接收用参数名=参数值的方式传入的参数,传入的参数的会打包成一个字典。定义函数时如果同时使用args和**kwargs,那么函数可以接收任意参数。
1.12 进程(process)和线程(thread)
参考:https://blog.csdn.net/Victor2code/article/details/109005171
做个简单的比喻:进程=火车,线程=车厢线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
多进程 vs 多线程
那么是不是意味着python中就只能使用多进程去提高效率,多线程就要被淘汰了呢?
那也不是的。
这里分两种情况来讨论,CPU密集型操作和IO密集型操作。针对前者,大多数时间花在CPU运算上,所以希望CPU利用的越充分越好,这时候使用多进程是合适的,同时运行的进程数和CPU的核数相同;针对后者,大多数时间花在IO交互的等待上,此时一个CPU和多个CPU是没有太大差别的,反而是线程切换比进程切换要轻量得多,这时候使用多线程是合适的。
所以有了结论:
CPU密集型操作使用多进程比较合适,例如海量运算
IO密集型操作使用多线程比较合适,例如爬虫,文件处理,批量ssh操作服务器等等
1.13 python2与python3区别
点评:这种问题千万不要背所谓的参考答案,说一些自己最熟悉的就足够了。
- Python 2中的print和exec都是关键字,在Python 3中变成了函数。
- Python 3中没有long类型,整数都是int类型。
- Python 2中的不等号<>在Python 3中被废弃,统一使用!=。
- Python 2中的xrange函数在Python 3中被range函数取代。
- Python 3对Python 2中不安全的input函数做出了改进,废弃了raw_input函数。
- Python 2中的file函数被Python 3中的open函数取代。
- Python 2中的/运算对于int类型是整除,在Python 3中要用//来做整除除法。
- Python 3中改进了Python 2捕获异常的代码,很明显Python 3的写法更合理。
- Python 3生成式中循环变量的作用域得到了更好的控制,不会影响到生成式之外的同名变量。
- Python 3中的round函数可以返回int或float类型,Python 2中的round函数返回float类型。
- Python 3的str类型是Unicode字符串,Python 2的str类型是字节串,相当于Python 3中的bytes。
- Python 3中的比较运算符必须比较同类对象。
- Python 3中定义类的都是新式类,Python 2中定义的类有新式类(显式继承自object的类)和旧式类(经典类)之分,新式类和旧式类在MRO问题上有非常显著的区别,新式类可以使用class属性获取自身类型,新式类可以使用slots魔法。
- Python 3对代码缩进的要求更加严格,如果混用空格和制表键会引发TabError。
- Python 3中字典的keys、values、items方法都不再返回list对象,而是返回view object,内置的map、filter等函数也不再返回list对象,而是返回迭代器对象。
- Python 3标准库中某些模块的名字跟Python 2是有区别的;而在三方库方面,有些三方库只支持Python 2,有些只能支持Python 3。
2. 阅读代码写结果
2.1 列表生成式
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = [i for i in A1 if i in A0]
A3 = [A0[s] for s in A0]
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
Python2结果
A0: {'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}
A1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A2: []
A3: [1, 3, 2, 5, 4]
A4: [1, 2, 3, 4, 5]
A5: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6: [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
Python3结果
A0: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
A1: range(0, 10)
A2: []
A3: [1, 2, 3, 4, 5]
A4: [1, 2, 3, 4, 5]
A5: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6: [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
函数讲解:
zip() 函数:Python3中:将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存;Python2中将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
A = zip(('a','b','c','d','e'),(1,2,3,4,5))
# python3 --> <zip object at 0x000001ADFF713A08>
print(A)
# python2 --> [('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5)]
print A
dict()函数:创建一个字典
range()函数:python2.x range() 函数可创建一个整数列表;Python3 range() 返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
range(10)表示从0—9,步长为1
易错处:
A2
考察:如何判断一个值存在于一个字典中if a in A0.values():
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
a = 1
if a in A0.values():
print(True) # --> True
题解:对于字典而言,if i in A0只能判断字典中是否含有相应的键,而不能判断是否含有相应的值(这里想迷惑应聘者怎样判断字典中含有相应的值)
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
a = 'a'
# 判断字典中是否含有键 a
if a in A0:
print(True) # --> True
所以for i in A1 if i in A0]:先从A1=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]中遍历,然后从字典A0中判断,字典A0中并没有这些键(只有一些值),所以A2为空
A3
考察:遍历字典中的键以及获取字典中的值
# 遍历字典获取键
for s in A0
# 获取键对应的值
A0[s]
2.2 生成式
items = [1, 2, 3, 4]
print([i for i in items if i > 2])
print([i for i in items if i % 2])
print([(x, y) for x, y in zip('abcd', (1, 2, 3, 4, 5))])
print({x: f'item{x ** 2}' for x in (2, 4, 6)})
print(len({x for x in 'hello world' if x not in 'abcdefg'}))
结果
[3,4]
[1,3]
[('a',1),('b',2),('c',3),('d',4)]
{2: 'item4', 4: 'item16', 6: 'item36'}
6
- 最后一个容易出错,集合里面元素不重复,所以
{x for x in 'hello world' if x not in 'abcdefg'}结果是{'r', 'w', ' ', 'o', 'l', 'h'}
容易出错的地方:
if i % 2:i不能整除2,就执行if后的语句- zip函数的使用,看上
- Python集合
{ }:
class Child1(Parent): pass
class Child2(Parent): pass
print(Parent.x, Child1.x, Child2.x) Child1.x = 2 print(Parent.x, Child1.x, Child2.x) Parent.x = 3 print(Parent.x, Child1.x, Child2.x)
刚开始答案:
```python
1 1 1
1 2 1
3 1 1
正确答案:
1 1 1
1 2 1
3 2 3
点评:运行上面的代码首先输出1 1 1,这一点大家应该没有什么疑问。接下来,通过Child1.x = 2给类Child1重新绑定了属性x并赋值为2,所以Child1.x会输出2,而Parent和Child2并不受影响。执行Parent.x = 3会重新给Parent类的x属性赋值为3,由于Child2的x属性继承自Parent,所以Child2.x的值也是3;而之前我们为Child1重新绑定了x属性,那么它的x属性值不会受到Parent.x = 3的影响,还是之前的值2。
2.4 字典
代码1
l = []
for i in range(10):
l.append({'num':i})
print(l)
运行结果:
[{'num': 0}, {'num': 1}, {'num': 2}, {'num': 3}, {'num': 4}, {'num': 5}, {'num': 6}, {'num': 7}, {'num': 8}, {'num': 9}]
运行步骤: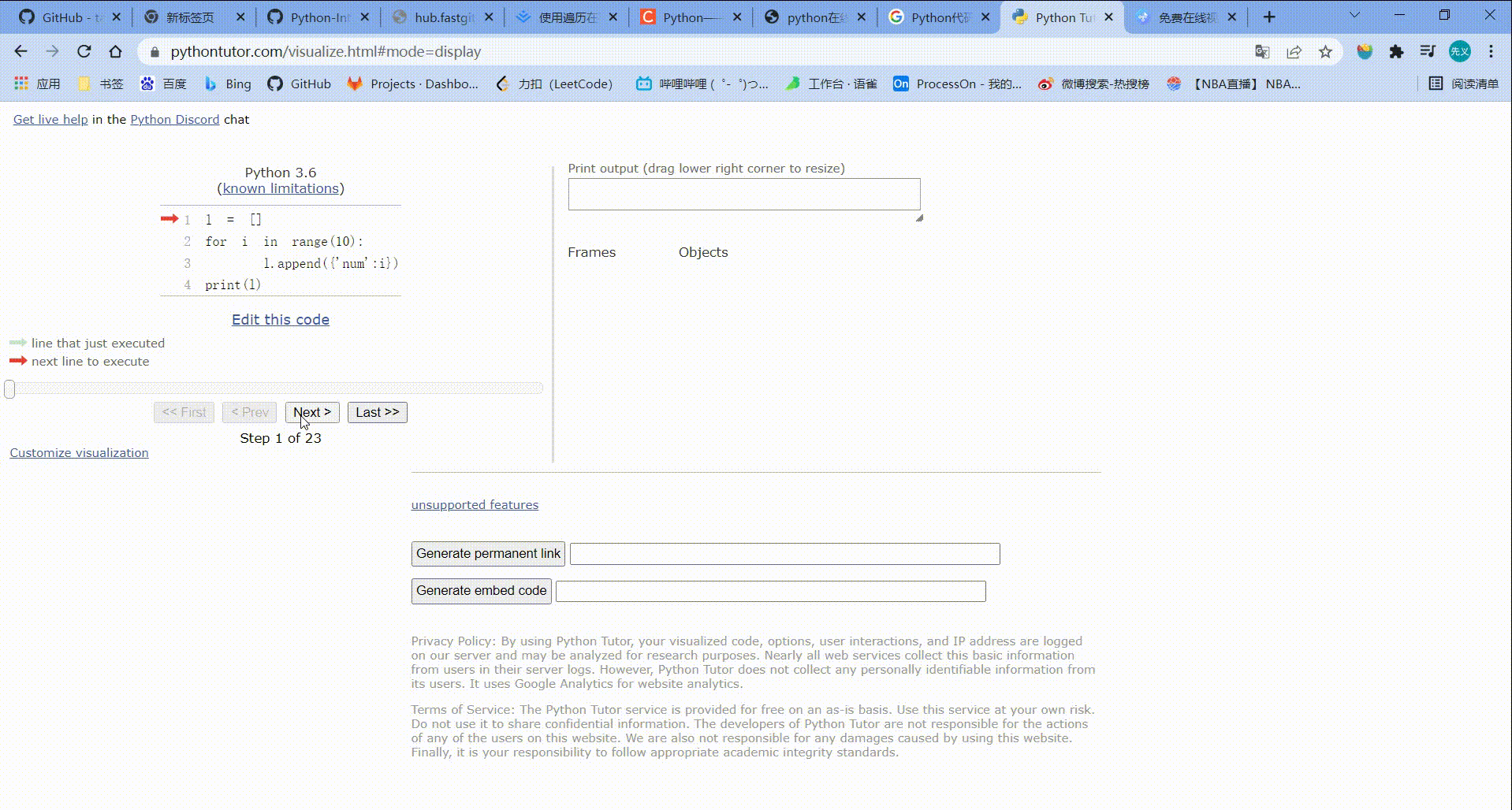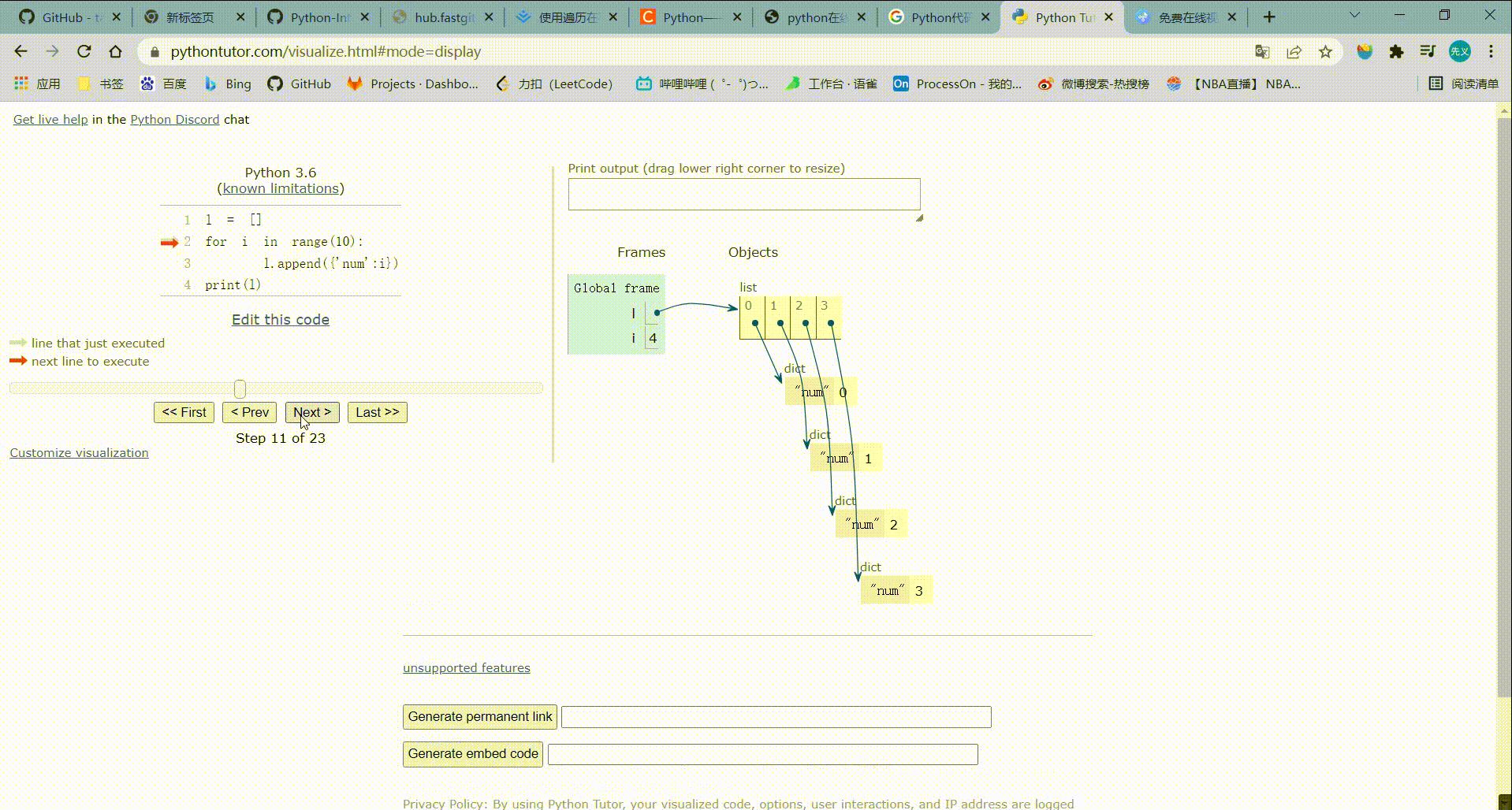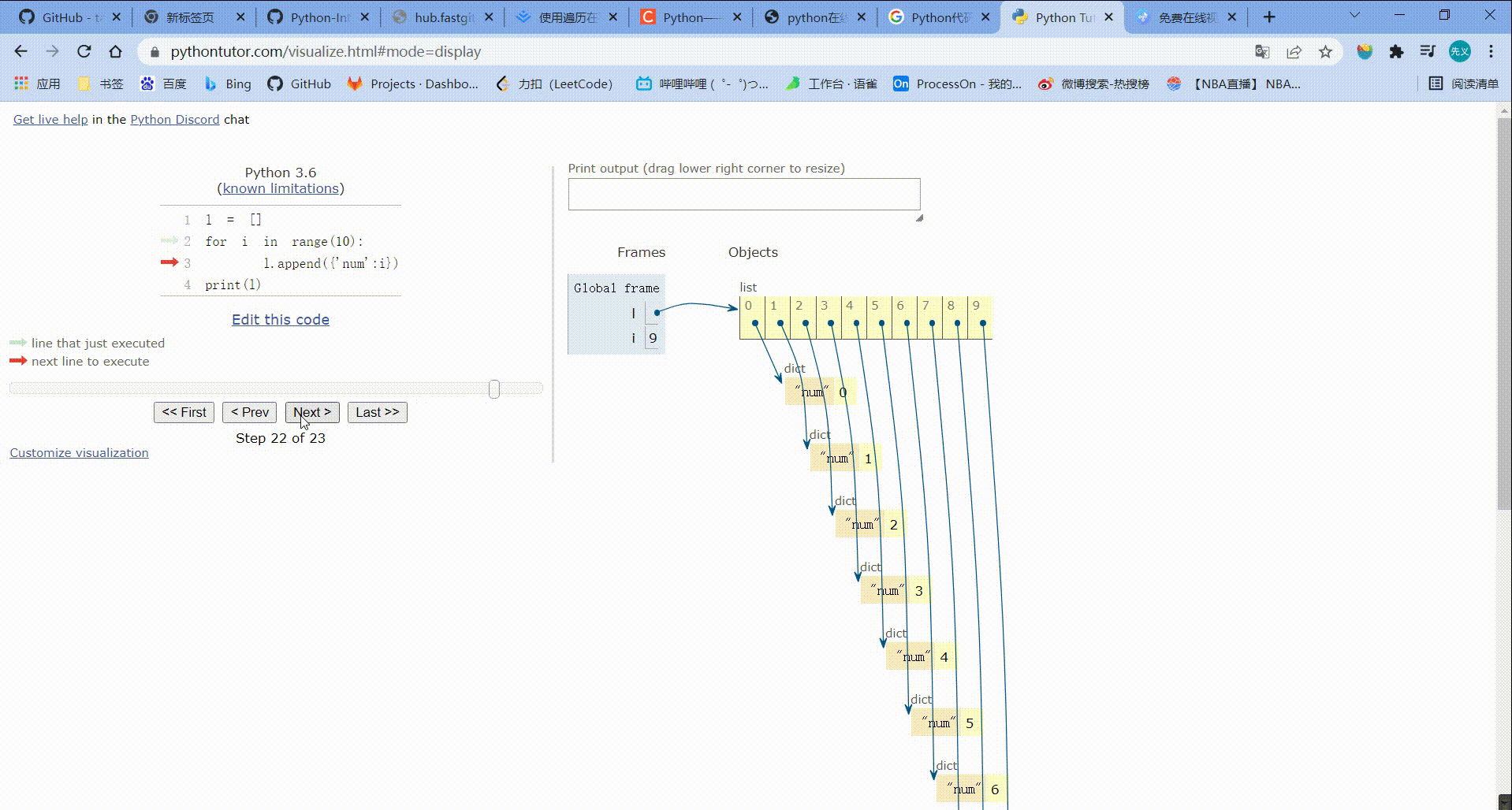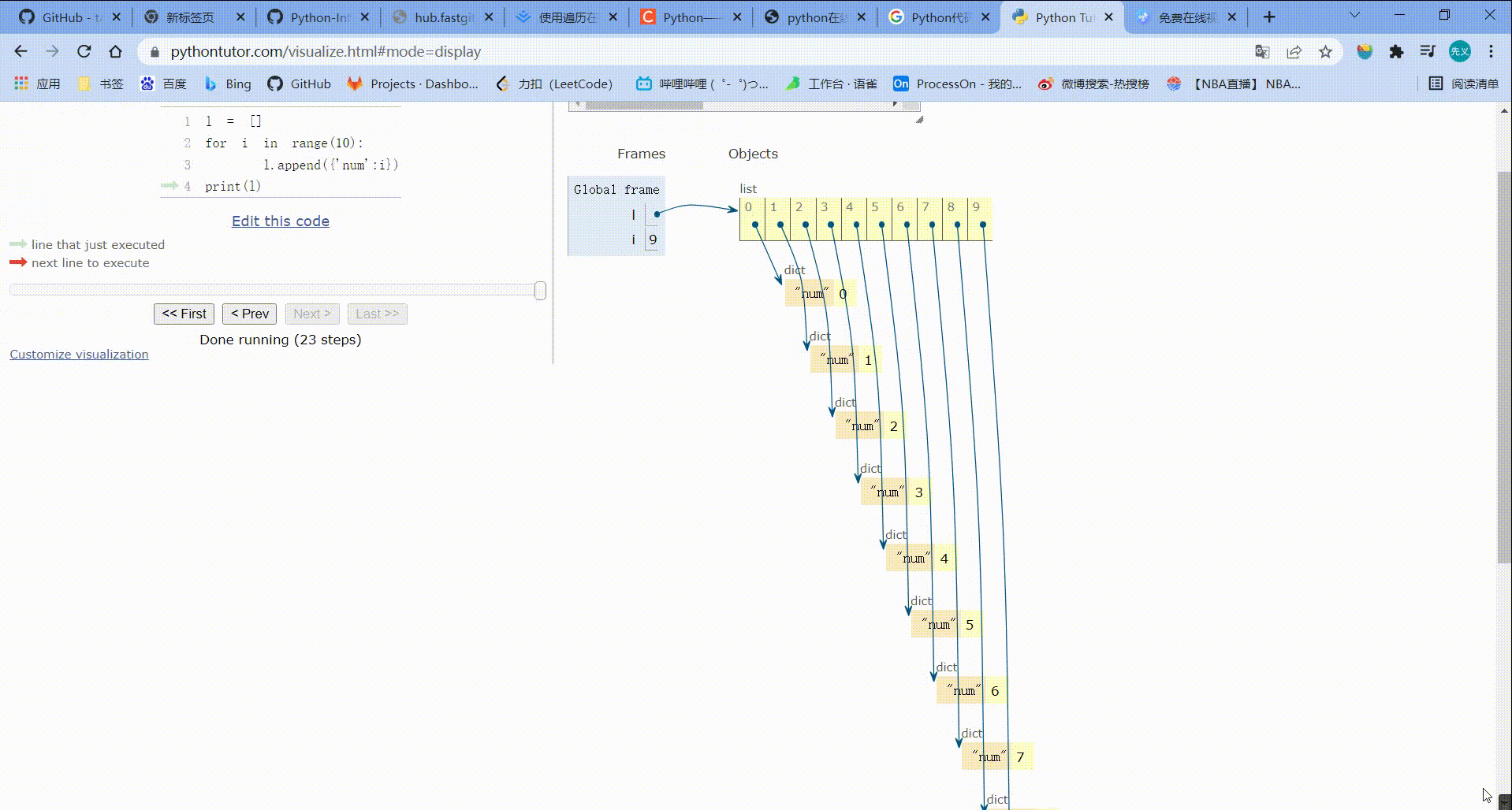
代码2(注意难点)
l = []
a = {'num':0}
for i in range(10):
a['num'] = i
l.append(a)
print(l)
运行结果:
[{'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}, {'num': 9}]
运行步骤:
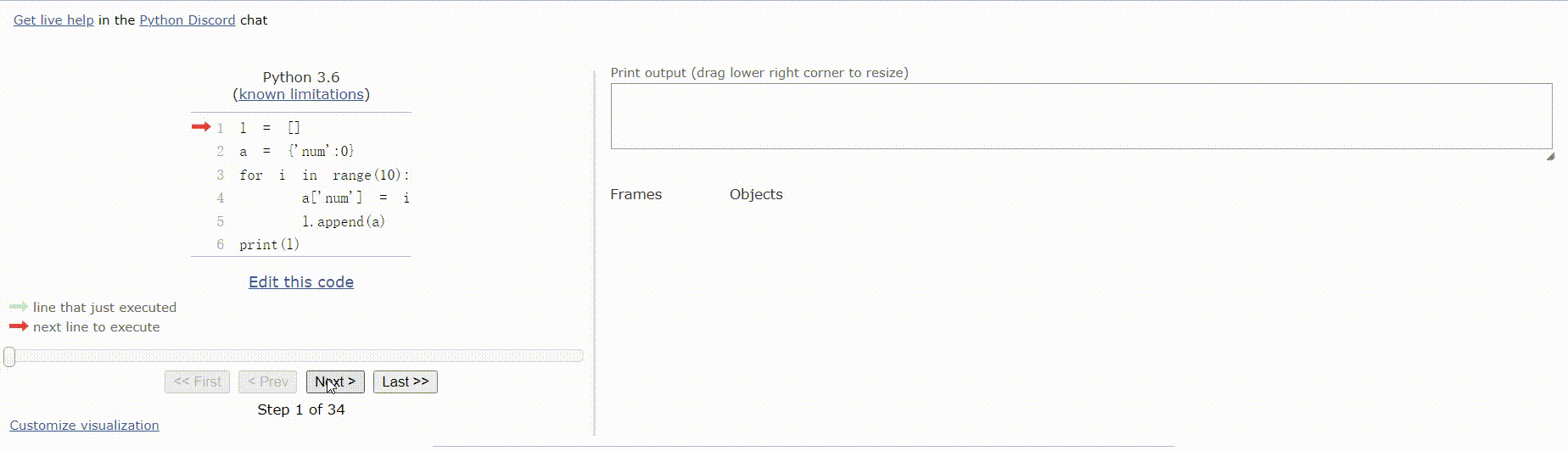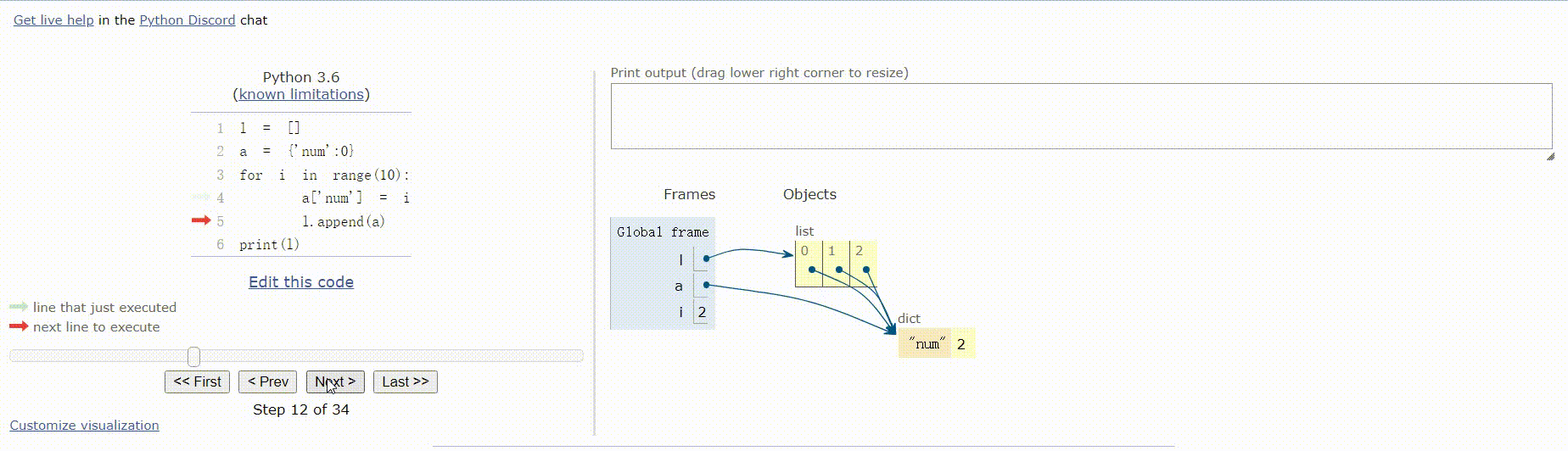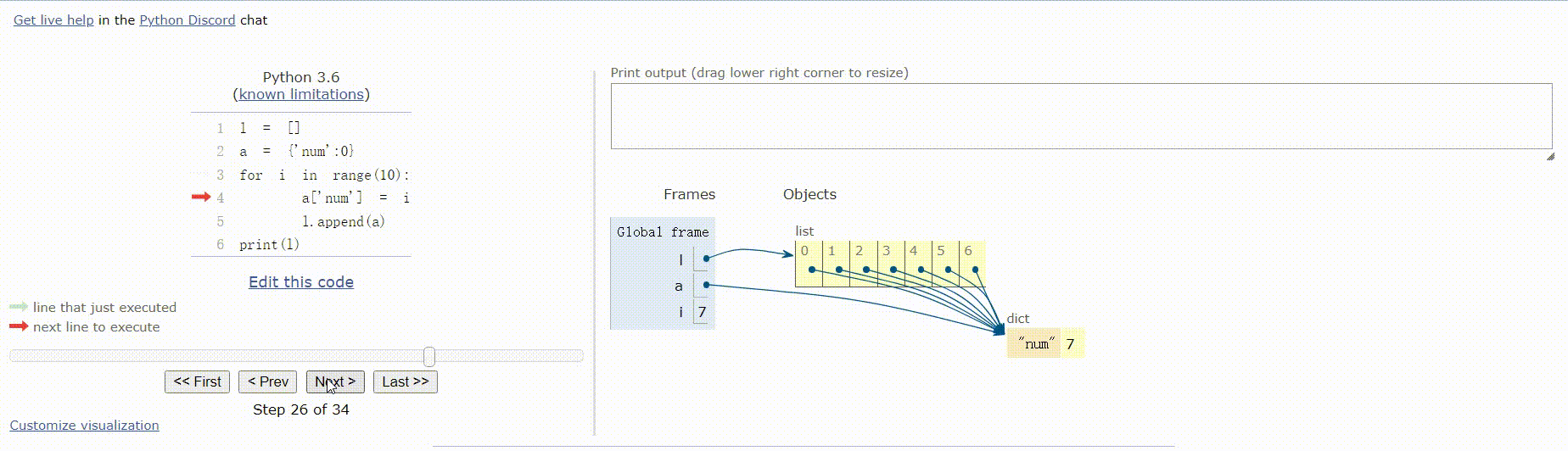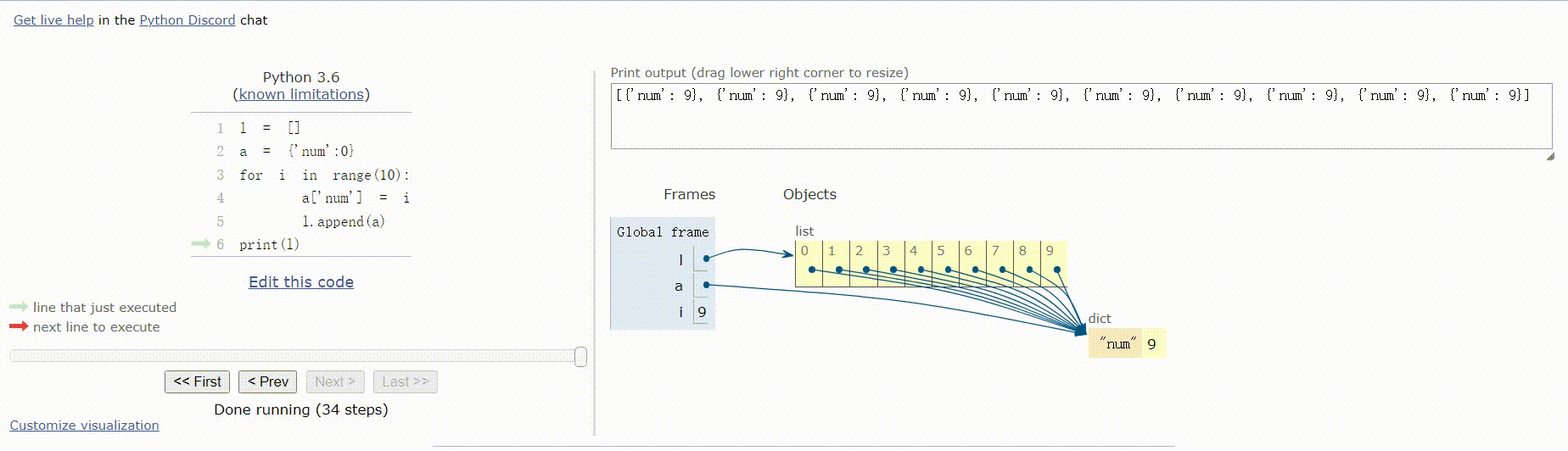
以上代码运行结果不相同的原因:
代码2中:字典是可变对象,l.append(a)操作的是将指向字典a的引用添加到列表l中,当操作a['num'] = i时,l中的值也会跟着改变,相当于浅拷贝
2.4 以下程序输出结果?
for i in range(5,0,-1):
print(i)
结果:
5,4,3,2,1
for i in range(5,0,-1):从列表的下标为5的元素开始,倒序取到下标为0的元素
2.4 闭包
下面代码输出结果
def multiply():
return [lambda x: i * x for i in range(4)]
print([m(100) for m in multiply()])
此代码涉及到闭包概念,详情查看:https://www.yuque.com/u1046159/erg6ec/bhxwo2
2.5 多继承
class A:
def who(self):
print('A', end='')
class B(A):
def who(self):
super(B, self).who()
print('B', end='')
class C(A):
def who(self):
super(C, self).who()
print('C', end='')
class D(B, C):
def who(self):
super(D, self).who()
print('D', end='')
item = D()
item.who()
2.6 Python中的MRO
参考:https://blog.csdn.net/wo198711203217/article/details/84097274
class A:
def who(self):
print('A', end='')
class B(A):
def who(self):
super(B, self).who()
print('B', end='')
class C(A):
def who(self):
super(C, self).who()
print('C', end='')
class D(B, C):
def who(self):
super(D, self).who()
print('D', end='')
item = D()
item.who()
结果:
ACBD
MRO顺序
参考:https://www.yuque.com/u1046159/erg6ec/osusnq
首先画出继承图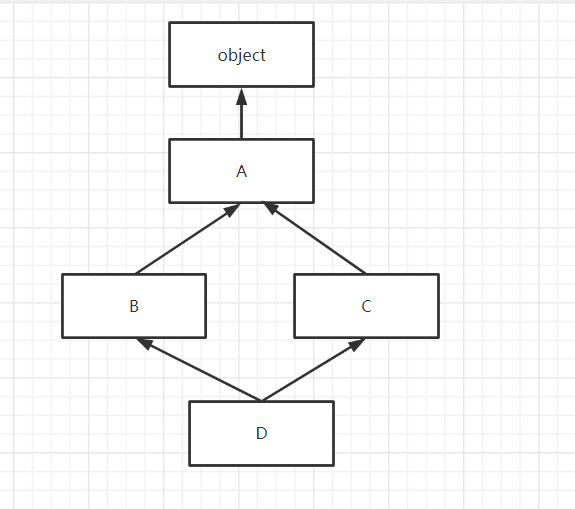
所以D类的MRO列表[类似从左到右广度优先]是**D --> B --> C --> A --> object**
super( )函数
参考:
https://www.yuque.com/u1046159/erg6ec/bfffgw#XVYB7
https://blog.csdn.net/wo198711203217/article/details/84097274
- 事实上,super 和父类没有实质性的关联。
- super(cls, inst) 获得的是 cls 在 inst 的 MRO 列表中的下一个类。
那么按照D类的MRO列表**D --> B --> C --> A --> object**
解析步骤:
- super(D, self).who(),会按照D类的MRO列表,搜索D类的下一类B,发现B类,跳到B类的
who方法, - 执行
super(B, self).who(),继续按照MRO列表,搜索B类的下一类C类,搜索到C类,跳转到C类的who方法 - 执行
super(C, self).who(),继续按照MRO列表,搜索C类的下一类A,搜索到A类,跳转到A类的who方法 - 执行A类的who方法,打印
'A' - 类A的方法执行完毕,继续执行C类
who方法中super(C, self).who()的下一句print('C', end=''),打印'C' - C类方法执行完毕,继续执行B类的
who方法中super(B, self).who()的下一句print('B', end=''),打印'B' - B类方法执行完毕,继续执行D类的
who方法中super(D, self).who()的下一句print('D', end=''),打印'D' - 结果
ACBD
3. 数据结构与算法
参考:https://python3-cookbook.readthedocs.io/zh_CN/latest/c01/p10_remove_duplicates_from_seq_order.html
3.1 删除序列相同元素并保持顺序
问题:怎样在一个序列上面保持元素顺序的同时消除重复的值?
解决办法:
如果序列上的值都是 hashable 类型,那么可以很简单的利用集合或者生成器来解决这个问题。比如:
def dedupe(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
if __name__ == '__main__':
d = dedupe([1,3,5,3,7,2])
for i in d:
print(i)
补充知识1:yield
- yield其实是一种特殊的迭代器,不过这种迭代器更加优雅
- yield可以先看做return。有return的函数直接返回所有结果,程序不再执行;而有yield的函数则返回一个可迭代的generator(生成器)对象。
- 在调用生成器函数的过程,每次遇到
yield时函数会暂停并保存当前运行的所有信息(保留局部变量),返回yield的值,并在下一次执行next()方法时[遍历迭代对象时即使用for循环,会自动执行next方法]从当前位置继续运行
上述代码执行过程:
- 程序先执行
d = dedupe([1,3,5,3,7,2]),将列表传给dedupe函数,它是一个迭代器对象<generator object dedupe at 0x000001EFF5655A50> - 程序进入
dedupe函数中,执行seen = set()—>for item in items:—>if item not in seen:—>yield item,当遇到yield时,dedupe暂停执行,并返回当前的item(此时item=1)【生成器函数的“状态”会被冻结,所有的变量的值会被保留下来,下一行要执行的代码的位置也会被记录】 - 程序执行
for i in d:—>print(i),打印出i的值1 - 由于for循环继续执行[main函数中for循环],迭代器的next方法被调用,此时继续执行
dedupe函数中yield后面的代码seen.add(item),将1添加进集合,程序继续执行dedupe函数中for循环for item in items:,当遇到关键字yield时,dedupe函数再次停止,并返回item的值(此时item=3) - 程序执行
for i in d:—>print(i),打印出i的值3,由于for循环继续执行,迭代器的next方法被调用,此时继续执行dedupe函数中yield后面的代码seen.add(item),将3添加进集合,重复上述d步骤 —>c步骤,直到main函数里的for循环不在执行,程序不再调用dedupe函数,程序到此结束

3.2 斐波拉契数列
数学公式基础:
斐波那契数列数学推导式
F(0)=0,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)
样例:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
方式一:递归
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
return fib(n - 1) + fib(n - 2)
if __name__ == '__main__':
x = [fib(i) for i in range(10)]
print(x)
fib(0)=0
fib(1) =1
fib(2) = fib(2-1) + fib(2-2) = fib(1) + fib(0) = 1 + 0 = 1
fib(3) = fib(3-1) + fib(3-2) = fib(2) + fib(1) = 1 + 1 = 2
方式二:生成器
def fib(num):
a, b = 0, 1
for _ in range(num):
a, b = b, a + b
yield a
if __name__ == '__main__':
x = fib(9)
for i in x:
print(i)
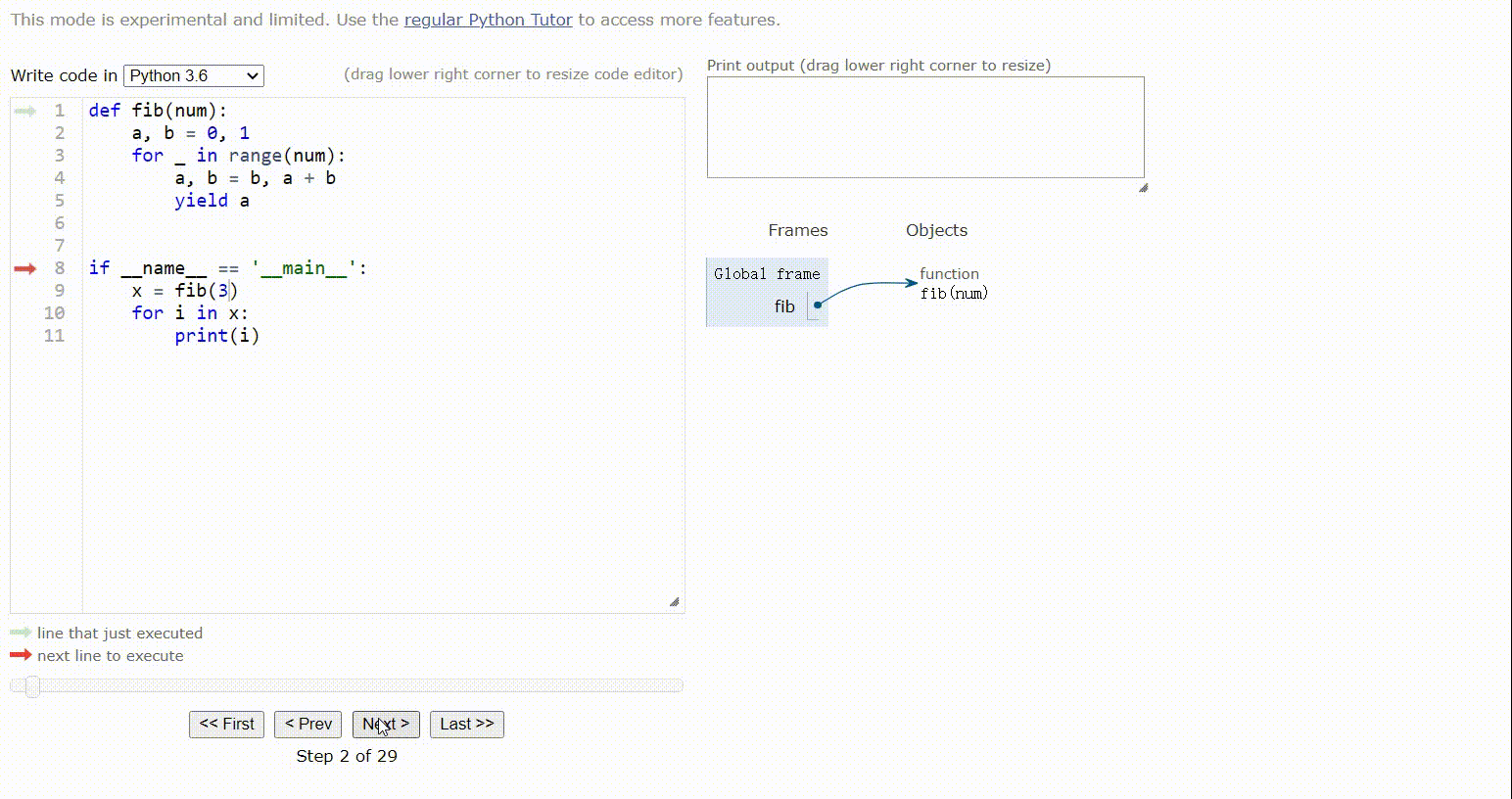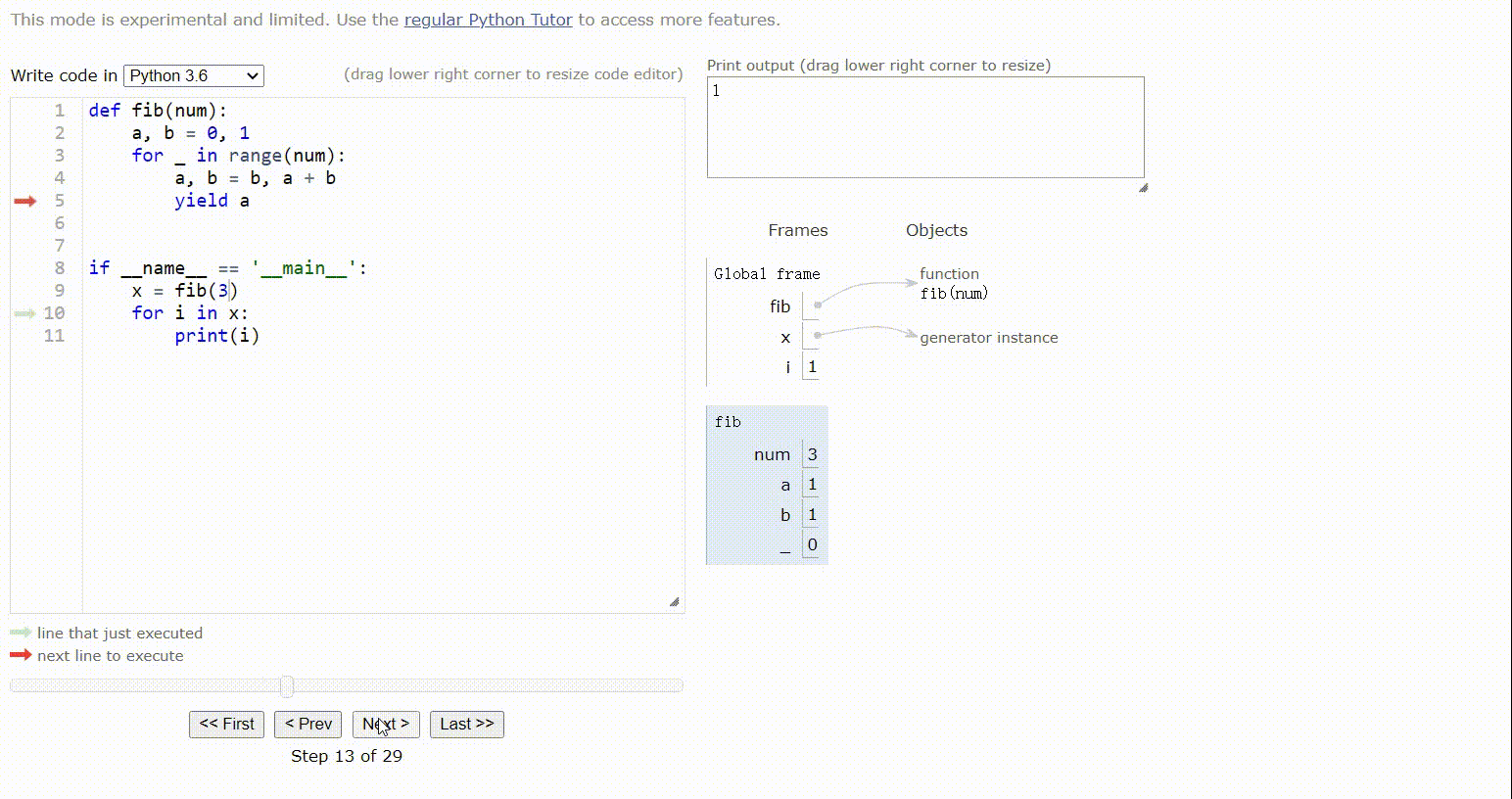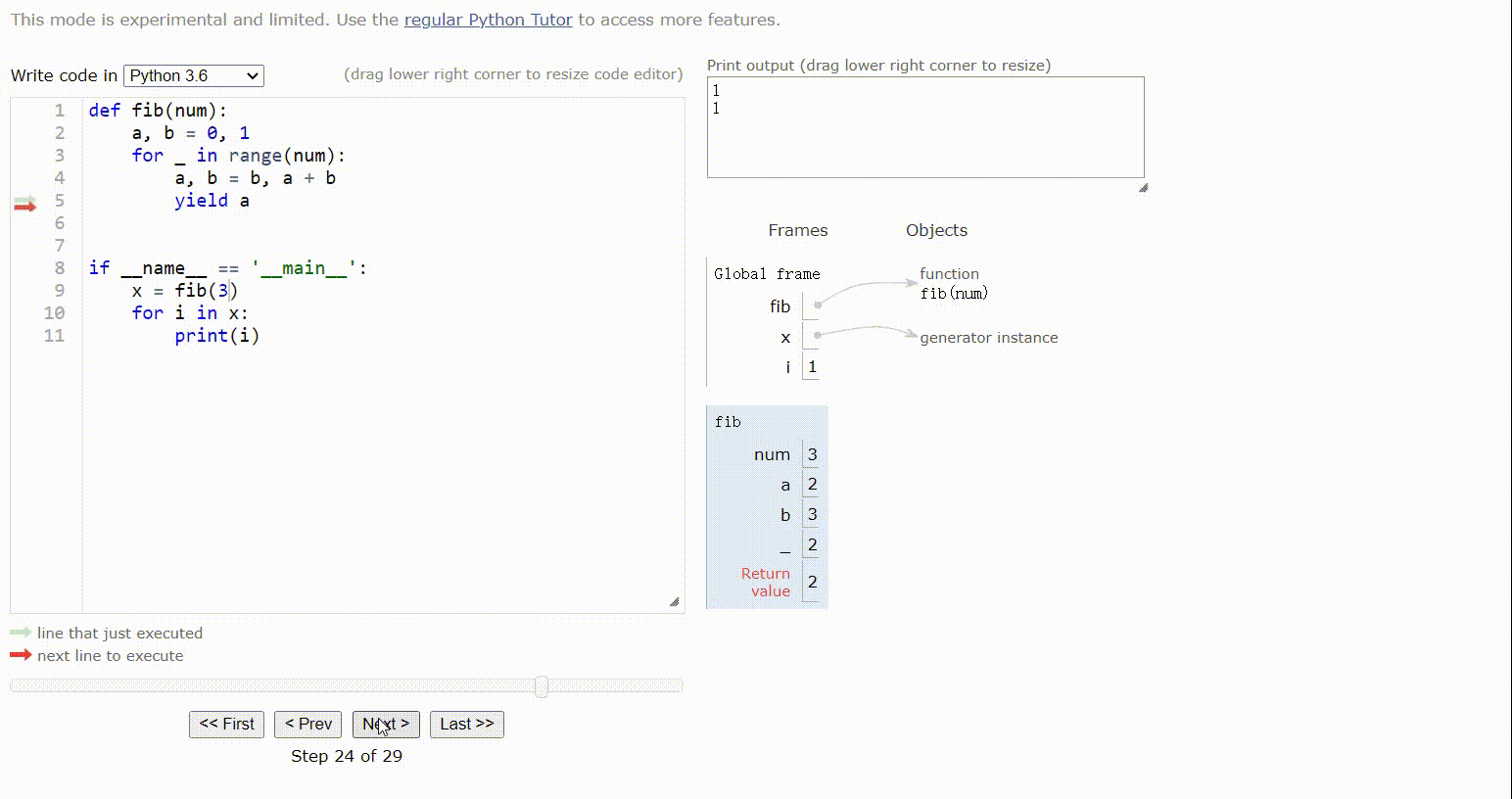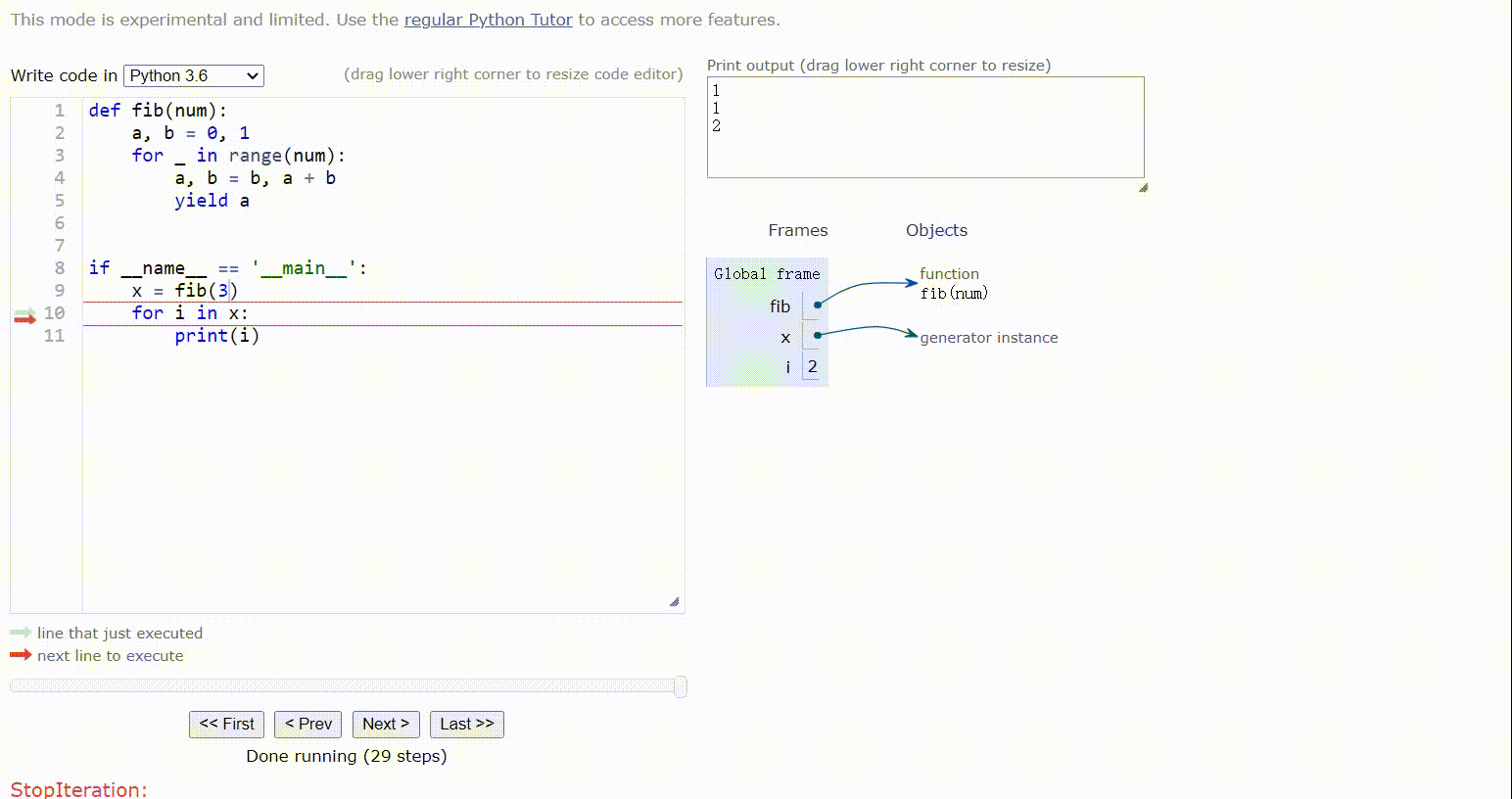
for _ in range(num):这里的_表示占位符,表示不在意变量的值,只是用于循环遍历n次,和使用i没什么区别,只不过使用_就表示我不在意这个变量的值,后面的代码中不会用到
当传入3时,执行fib函数
注意赋值语句:
a, b = b, a + b
# 相当于
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]
a = 0,b = 1
fib中会循环三次
第一次:a = 1,b = 0+1=1(注意,此时的a是之前的a=0,并不是a = t[0]的值,因为赋值语句先执行t = (b, a + b)),返回a,主函数遍历迭代器x,打印1,主函数继续循环,此时会从生成器函数fib的yield a继续执行,进行第二次循环
第二次:(因为没有跳出循环,a与b的初始值是上次循环后a,b的值),a = b =1,b = 1+1=2,返回a,主函数遍历迭代器,打印1
第三次:a = b = 2,b=1+2=3,返回a,打印2
结果 1 ,1, 2
4. 写代码
4.1 写一个函数统计传入的列表中每个数字出现的次数并返回对应的字典。
方法一:利用Python字典统计
"""写一个函数统计传入的列表中每个数字出现的次数并返回对应的字典。"""
def count_num(num_list):
"""方法一:利用字典统计"""
result = {}
"""
key 是列表中元素
value 是元素出现次数
"""
for key in num_list:
result[key] = result.get(key,0) + 1
return result
num_list = [1,3,2,1,5]
print(count_num(num_list))
字典的get语法:dict.get(key[, value])
key — 字典中要查找的键。
value — 可选,如果指定键的值不存在时,返回该默认值。
方法二:利用Python的collection包下Counter的类统计
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
def count_num():
a = [1, 2, 3, 1, 1, 2]
result = Counter(a)
print(result)
4.2 遍历文件夹操作
方法一:使用os.walk
def walkFile(file):
for root, dirs, files in os.walk(file):
# root 表示当前正在访问的文件夹路径
# dirs 表示该文件夹下的子目录名list
# files 表示该文件夹下的文件list
# 遍历文件
for f in files:
print(os.path.join(root, f))
# 遍历所有的文件夹
for d in dirs:
print(os.path.join(root, d))
方法二:os.listdir
import os
for i in os.listdir(path):
if os.path.isdir(i):
print(i)
4.3 现有2元、3元、5元共三种面额的货币,如果需要找零99元,一共有多少种找零的方式
from functools import lru_cache
@lru_cache()
def change_money(total):
if total == 0:
return 1
if total < 0:
return 0
return change_money(total - 2) + change_money(total - 3) + \
change_money(total - 5)
print(change_money(99))
说明:在上面的代码中,我们用lru_cache装饰器装饰了递归函数change_money,如果不做这个优化,上面代码的渐近时间复杂度将会是$O(3^N)$,而如果参数total的值是99,这个运算量是非常巨大的。lru_cache装饰器会缓存函数的执行结果,这样就可以减少重复运算所造成的开销,这是空间换时间的策略,也是动态规划的编程思想。
4.4 输入年月日,判断这个日期是这一年的第几天
方法一
思路:
- 首先,此题的核心在于判断闰年(判断闰年方法:四年一闰;百年不闰,四百年再闰)
- 闰年闰年判断:普通闰年:能被4整除但不能被100整除的年份为普通闰年。世纪闰年:能被400整除的为世纪闰年。
- 其次,我们根据该年是否为闰年来创建两个分别适用于平年和闰年的每月天数列表
- 最后,将该月前面月份的天数与该月的天数相加即可“判断一某天是该年的第几天” ```python def is_leap_year(year): “””判断指定的年份是不是闰年,平年返回False,闰年返回True””” return year % 4 == 0 and year % 100 != 0 or year % 400 == 0
def which_day(year, month, date): “””计算传入的日期是这一年的第几天”””
# 用嵌套的列表保存平年和闰年每个月的天数
days_of_month = [
[31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31],
[31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
]
days = days_of_month[is_leap_year(year)][:month - 1]
return sum(days) + date
**方法二**
```python
import datetime
def which_day(year, month, date):
end = datetime.date(year, month, date)
start = datetime.date(year, 1, 1)
return (end - start).days + 1
4.5 写一个记录函数执行时间的装饰器
高频面试题,也是最简单的装饰器,面试者必须要掌握的内容
方法一:用函数实现装饰器
from functools import wraps
from time import time
def record_time(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time()
result = func(*args, **kwargs)
print(f'{func.__name__}执行时间:{time()-start}秒')
return result
return wrapper
- Python装饰器(decorator)在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变),为了不影响,Python的functools包中提供了一个叫wraps的decorator来消除这样的副作用。写一个decorator的时候,最好在实现之前加上functools的wrap,它能保留原有函数的名称和函数属性。(参考:https://blog.csdn.net/weixin_43750377/article/details/115112517)
如何使用?
@record_time
def hello():
print([i for i in range(1000)])
if __name__ == '__main__':
hello()
方法二:用类实现装饰器。类有call魔术方法,该类对象就是可调用对象,可以当做装饰器来使用
class Record:
def __init__(self,func):
self.func = func
def __call__(self,*args,**kwargs):
start = time()
result = self.func(*args, **kwargs)
print(f'{self.func.__name__}执行时间:{time() - start}秒')
return result
4.6 工资结算系统
某公司有三种类型的员工 分别是部门经理、程序员和销售员 需要设计一个工资结算系统 根据提供的员工信息来计算月薪 部门经理的月薪是每月固定15000元 程序员的月薪按本月工作时间计算 每小时150元 销售员的月薪是1800元的底薪加上销售额5%的提成
super().init()用法
做这个案例前,需要了解一个知识:Python子类构造函数调用super().init()用法说明
先看下面代码:
class Employee():
def __init__(self, name):
self.name = name
class Manager(Employee):
pass
class Programmer(Employee):
def __init__(self,age):
self.age = age
class Salesman(Employee):
def __init__(self,name,age):
self.age = age
super().__init__(name)
m = Manager('小明')
print(m.name)
print('===========')
p = Programmer(10)
print(p.age)
# print(p.name) # 报错'Programmer' object has no attribute 'name'
print('===========')
s = Salesman('小红',15)
print(s.name)
print(s.age)
运行结果:
小明
===========
10
===========
小红
15
[总结] super的作用:
- 如果子类(Manager)继承父类(Employee),不做初始化(即不使用
__init__函数),那么子类(Manager)会自动继承父类(Employee)的属性(name) - 如果子类(Manager)继承父类(Employee)做了初始化,且不调用super初始化父类构造函数,那么子类(Manager)不会自动继承父类的属性(name)
- 如果子类(Manager)继承父类(Employee)做了初始化,且调用了super初始化了父类的构造函数,那么子类(Manager)也会继承父类的(name)属性。
工厂模式
- 所谓”工厂模式“就是专门提供一个”工厂类“去创建对象,我只需要告诉这个工厂我需要什么,它就会返回给我一个相对应的对象。
- 如果要创建一系列复杂的对象,需要提供很多的创建信息;或者是我想要隐藏创建对象时候的“代码逻辑”,就需要使用“工厂模式”
- 作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
了解到上面知识后,我们可以编写此案例的代码了
"""
月薪结算系统 - 部门经理每月15000 程序员每小时200 销售员1800底薪加销售额5%提成
"""
from abc import ABCMeta, abstractmethod
class Employee(metaclass=ABCMeta):
def __init__(self, name):
self.name = name
@abstractmethod
def get_salary(self):
"""月薪结算抽象方法(子类必须重写)"""
pass
class Manager(Employee):
"""部门经理"""
def get_salary(self):
return 15000.0
class Programmer(Employee):
"""程序员"""
def __init__(self, name, working_hour):
self.working_hour = working_hour
# 子类继承父类Employee,且调用了super初始化父类的构造函数,那么子类也会继承父类的name属性
super().__init__(name)
def get_salary(self):
return self.working_hour * 200.0
class Salesman(Employee):
"""销售员"""
def __init__(self, name, sale, rate=0.05):
self.sale = sale
self.rate = rate
super().__init__(name)
def get_salary(self):
return self.sale * self.rate + 1800.0
class EmployeeFactory:
"""创建员工的工厂(工厂模式 - 通过工厂实现对象使用者和对象之间的解耦合)"""
@staticmethod
def create(emp_type, *args, **kwargs):
"""创建员工"""
all_emp_types = {'M': Manager, 'P': Programmer, 'S': Salesman}
cls = all_emp_types[emp_type.upper()]
return cls(*args, **kwargs) if cls else None
def main():
"""主函数"""
emps = [
EmployeeFactory.create('M', '曹操'),
EmployeeFactory.create('P', '郭嘉', 85),
EmployeeFactory.create('S', '典韦', 123000),
]
for emp in emps:
print(f'{emp.name}: {emp.get_salary():.2f}元')
if __name__ == '__main__':
main()
- 上面使用到工厂模式[ https://codeantenna.com/a/iFPgcZqezs]
cls = all_emp_types[emp_type.upper()]返回的是字典all_emp_types中对象return cls(*args, **kwargs) if cls else None:返回对象携带剩余参数(如:创建是EmployeeFactory.create('P', '郭嘉', 85),返回Programmer('郭嘉', 85))
运行结果:
曹操: 15000.00元
郭嘉: 17000.00元
典韦: 7950.00元

若有收获,就点个赞吧
0 人点赞
