使用requests爬取西域时,当网站访问频率过高时,会出现验证码
爬取西域(https://www.ehsy.com/)时出现验证码(https://gofast.ehsy.com/open/robotVerify?srcurl=https%3A%2F%2Fwww.ehsy.com%2Fcategory-2249&srcip=121.238.4.20):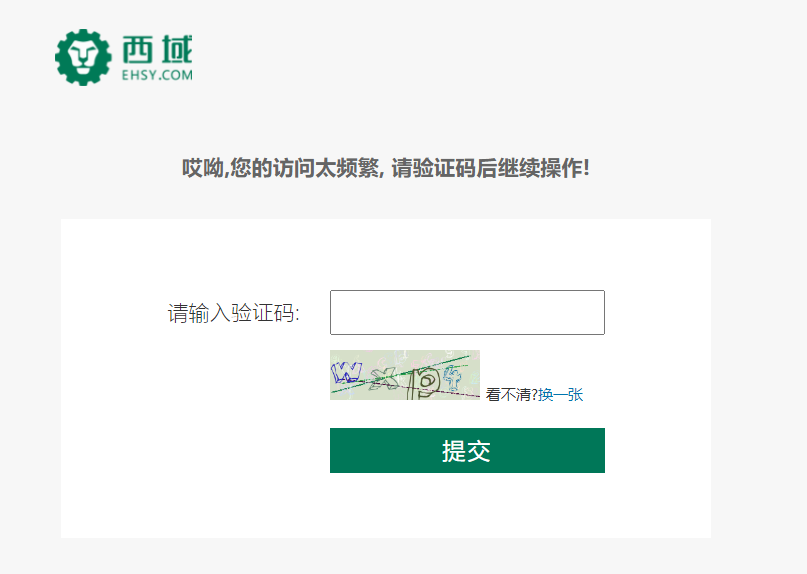
解决方案
requests + selenium + 超级鹰(验证码识别:https://www.chaojiying.com/)
思路:
- 判断该页面是否是验证码页面(如何判断?找一个只出现在反爬页面上的标识元素),如果出现该标识元素说明是反爬页面,那么就进行验证码识别(具体看步骤2),否则就进行正常爬取
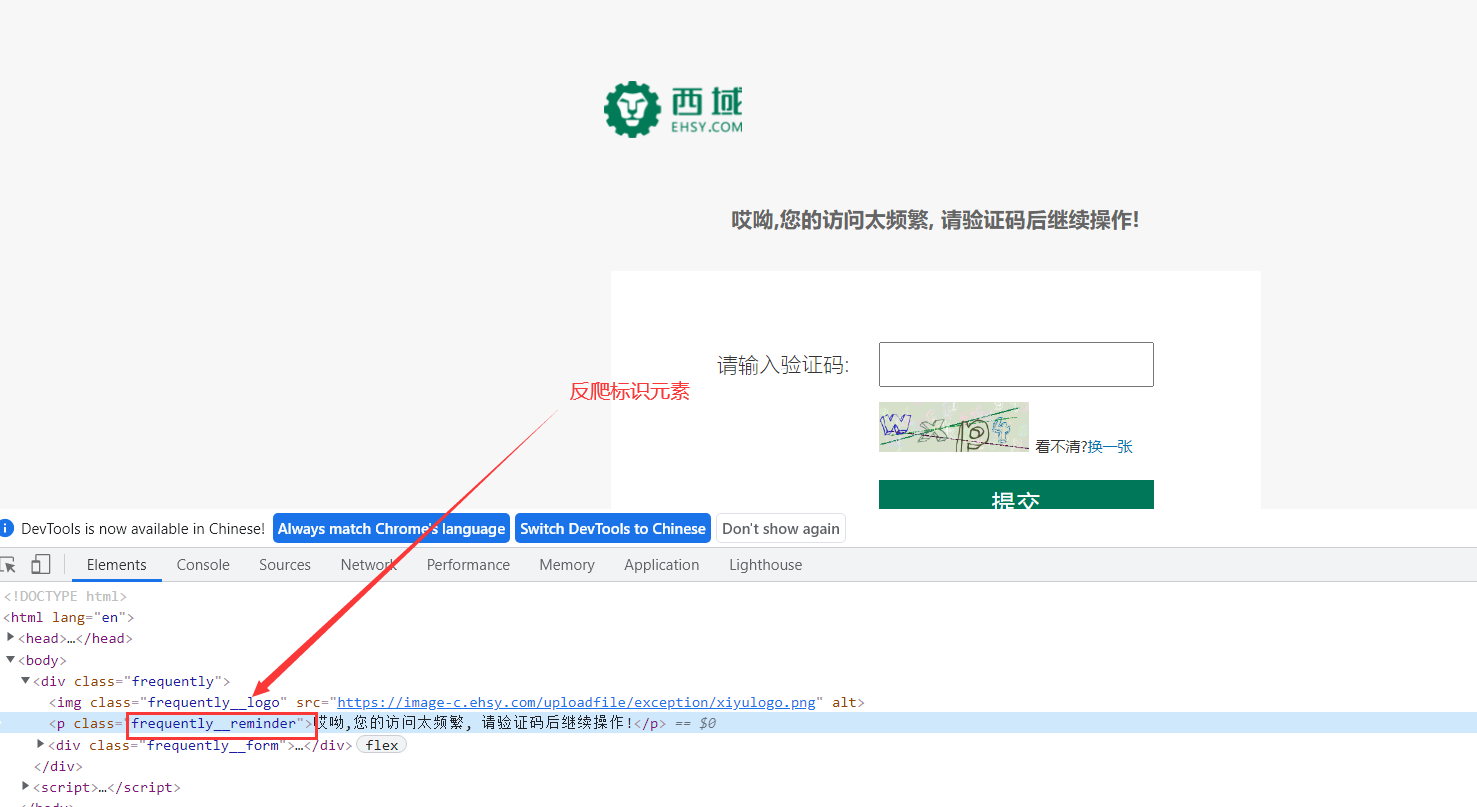
- 如何进行验证码识别?使用selenium获取验证码图片
关键代码
bro = webdriver.Chrome(executable_path='D:\\Pycharm\\Ehsy_Scrapy\\chromedriver.exe')# 获取验证码的图片img = bro.find_element_by_xpath('//img[@id="image-code"]').screenshot_as_png
screenshot_as_png会截取指定元素位置的图片
- 将获取到的验证码图片传递给超级鹰,并返回识别结果
关键代码
# 使用超级鹰chaojiying = Chaojiying_Client('15565372062', 'zxy1997416', '924146') # 用户中心>>软件ID 生成一个替换 96001dic = chaojiying.PostPic(img, 8001)# 从超级鹰获取到的验证码verify_code = dic['pic_str']
- 然后使用selenium将超级鹰识别出来的验证码输入input框中,然后点击“提交”按钮(如果识别成功,跳转到正常页面),然后再次调用爬虫函数(再次调用又会进行是否是爬虫页面判断)
```python
验证码输入框
bro.find_element_by_id(‘auth-code’).send_keys(verify_code) bro.find_element_by_xpath(‘//input[@class=”frequentlyform-right frequentlysubmit”]’).click() bro.refresh()selenium获取当前页面的url,传递给download_html函数,再次调用该函数
current_url = bro.current_url download_html(current_url)
问题:当出现反爬页面时,使用验证码识别后,怎样将新的url传递给download_html函数?<br />有两种方案:1. 使用selenium获取验证码识别后的页面:`new_url= bro.current_url`1. 因为刚开始传递给**download_html**函数的url是正常的url,所以验证码识别后,直接将刚开始的url再次传递给**download_html**函数<a name="MTvmC"></a>## 代码逻辑```pythondef download_html(url):# 反爬页面标志性元素flag = html.xpath('//p[@class="frequently__reminder"]')# 说明当前是反爬页面if flag:# ...验证码识别操作逻辑download_html(url) # 将刚开始正常url再次传递给download_html函数# 正常页面else:# ...爬取数据逻辑if __name__ == '__main__':for url in open('E:\\西域数据\\ehsy_items_url.txt'):download_html(url)
- main函数传递给download_html函数的url是正常url
超级鹰使用
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
"""
超级鹰使用
"""
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
使用的时候,调用Chaojiying_Client类,传入用户名、密码以及软件ID
图片识别调用PostPic函数,传入图片以及验证码识别类型
dic[‘pic_str’]获取返回的验证码
# 使用超级鹰
chaojiying = Chaojiying_Client('15565372062', 'zxy1997416', '924146')
dic = chaojiying.PostPic(img, 8001)
# 从超级鹰获取到的验证码
verify_code = dic['pic_str']

若有收获,就点个赞吧
0 人点赞
