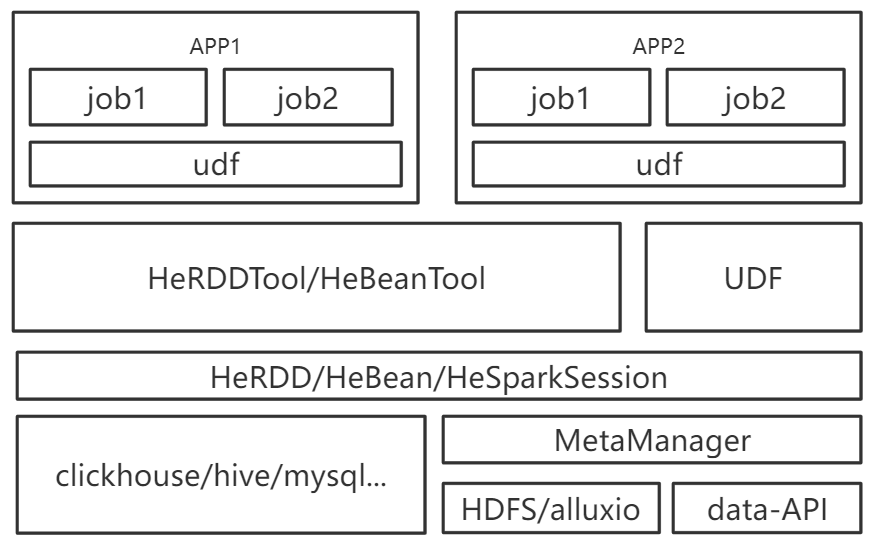
HeSQL简介
spark的局限
spark的局限
- 开发有门槛:需要了解广播变量,RDD算子的专业概念。
- 无法准确识别小表(配置数据)导致大量shuffle
- 即使识别出小表,也无唯一主键概念,关联效率低
- 广播变量的局限:无法自动创建索引,不可重用;不支持RDD与广播变量之间的SQL
业务实现有难度
- 复杂的广播变量、眼花缭乱的RDD算子
- 创建各种索引,且不可重用
- 业务复杂:需要关联多种配置数据,且不可重用
目标


效果
资源消耗情况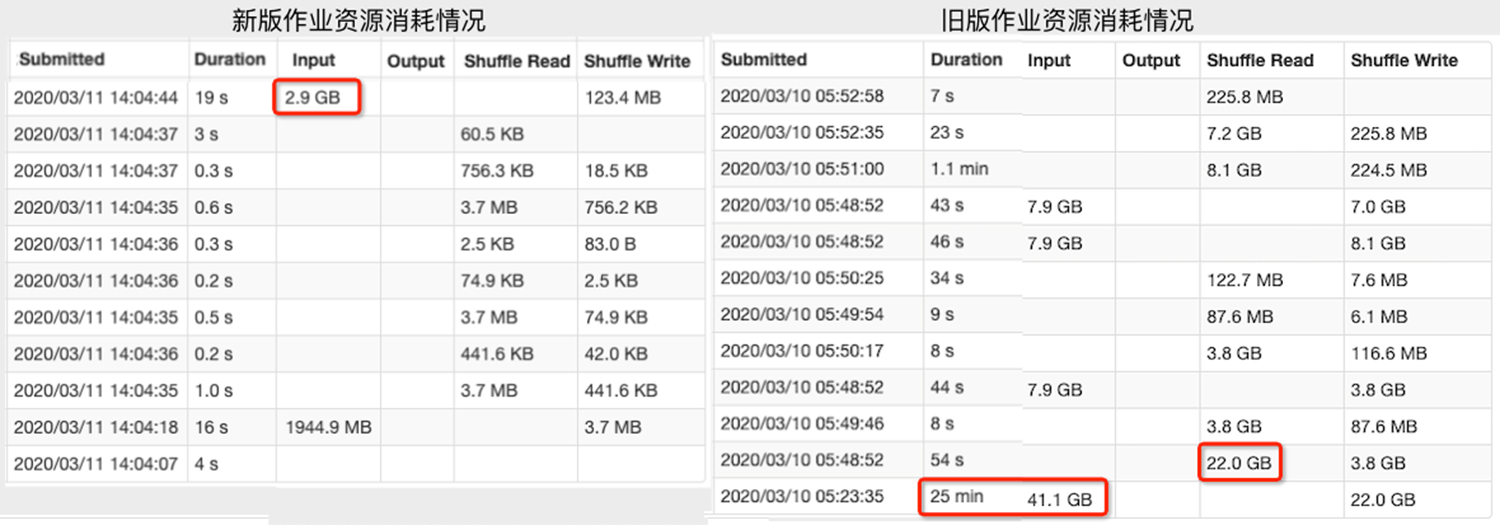
执行时间
用户访问分布初步测试(40G数据+300M配置)
- 更少资源:1/2CPU, 1/4内存, 1/100的IO
- 更高性能:提高2-10倍
- 更少的代码:约1/10
旧版作业运行30min
新版作业运行1.6min(所有维度估计10min)

基本概念
- RDD:Resilient Distributed Datasets(弹性分布式数据集)
- Dataset/Dataframe: 含schema
- Driver/Executor/broacast
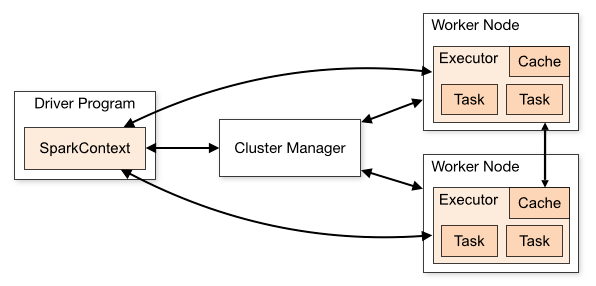
quick start
package com.hdata.hesql.demo;import com.hdata.hesql.core.*;import com.hdata.hesql.core.helper.Option;import org.apache.spark.sql.SaveMode;import org.slf4j.Logger;import org.slf4j.LoggerFactory;/** spark sql union 与广播变量对比* 测试数据由ConvTool中构造* 测试数据目录结构:* /spark/data* +-config* +-test_user* +-test_order* +-parquet* Created by heshang on 2021/11/09.*/public class HeSqlTest extends SparkBaseJob {private static final Logger LOG = LoggerFactory.getLogger(HeSqlTest.class);public static void main(String[] args) {new HeSqlTest().start(args);}@Overrideprotected void execute() throws Exception {sparkSqlUnionById();heSqlUnionById();}private void sparkSqlUnionById() throws Exception {long startTime = System.currentTimeMillis();String minPartitions = nameParams.getOrDefault("txt.minPartitions","1");HeRDDTool.getHeRDDOfConfFromFile(spark, "test_order", "orderid,userid,productid,num,price,cdate,editor",new Option("delimiter", ",").set("skip.exception", "true"));//配置文件比较小,只需要几个分区就可以,这样方便进行广播HeRDDTool.getHeRDDOfConfFromFile(spark,"test_user", "userid,uname,utype,birth,tel,weight,editor",new Option("delimiter", ",").set("txt.minPartitions", minPartitions));String sqlStr = "select o.orderid,o.userid,o.productid,o.num,o.price,o.editor,cdate,u.uname,u.utype,u.birth,u.tel,u.weight "+ "from test_order o left join test_user u on o.userid=u.userid";HeRDD orderUser = spark.sql(sqlStr, "order_user");orderUser.getDataset().write().mode(SaveMode.Overwrite).parquet("/spark/data/parquet/order_user1");LOG.info("testSparkSql usetime:{}s", (System.currentTimeMillis() - startTime) / 1000.0);}private void heSqlUnionById() throws Exception {long startTime = System.currentTimeMillis();HeRDDTool.getHeRDDOfConfFromFile(spark, "test_order", "orderid,userid,productid,num,price,cdate,editor",new Option("delimiter", ",").set("skip.exception", "true"));HeBeanTool.getHeBeanOfConfFromFile("test_user", "userid,uname,utype,birth,tel,weight,editor",new Option("delimiter", ","));String sqlStr = "select o.orderid,o.userid,o.productid,o.num,o.price,o.editor,cdate,u.uname,u.utype,u.birth,u.tel,u.weight "+ "from test_order o left join test_user u on o.userid=u.userid";HeRDD orderUser = spark.sqlOfHeRDD(sqlStr, "order_user");orderUser.getDataset().write().mode(SaveMode.Overwrite).parquet("/spark/data/parquet/order_user2");LOG.info("testHeRDD2HeBean usetime:{}s", (System.currentTimeMillis() - startTime) / 1000.0);}}
在开发环境中少量数据的情况下,执行时间区别不大,主要区别是shuffle。SparkSQL占用大量shuffle,而HeSQL没有任何shuffle。
这里写spark作业,只需要继承SparkBaseJob并实现execute接口即可,其他的操作只需要写SQL语句。
SparkBaseJob
封装基本配置:从app.properties中读取,主要配置项如下:
# 这个一般在windows下运行时才需要设置,# 如果没有设置这个可以通过 -Dspark.driver.host=192.168.56.1 设置# 系统上线时一般需要删除这个配置spark.driver.host=192.168.56.1spark.master=spark://node01:7077spark.eventLog.enabled=truespark.eventLog.dir=hdfs://node01:9000/historyspark.eventLog.compress=true
初始化参数解析与spark运行环境
- 方便本机调试
提交作业是自动加载本地打包的jar文件,是开发可以在本地运行main函数的方式进行调试,提高开发效率。
MetaManager
大数据作业经常要处理文本或接口数据,这些数据没有元数据信息,来源也不同,不方便进行SQL方式操作,所以我们要用MetaManager进行管理这些数据。目前使用简单管理方式,即编程的方式。将来可以用平台的方式,即web界面方式注册、管理元数据。
从hive/clickhouse/mysql读取的数据不需要经过MetaManager,因为他们已经有元数据。
- view
即HeBean或HeRDD的名字,与spark中view概念类似
如果是配置文件则对应配置文件名,或目录名
默认值
DEFAULT_STR_IFNULL = ""; DEFAULT_INT _IFNULL = "0";对应数据不存在是默认是空(NULL),这样容易导致程序异常,或者业务处理异常,比如SQL无法关联,很多时候我们可以通过设置默认值解决。
读取数据时相关option
delimiter: 分隔符集合,每个字符都是分隔符,不是作为一个整体。默认空格。
skip.exception:忽略解析异常,被忽略的值被设置为null, 即使nullable=false也会忽略该异常*
即skip.exception=true或nullable=true时,如果没有设置默认值,数据缺失时都会设置为null
skip.empty:忽略空行,包括只有空格的行。默认为true
HeRDD/HeBean
| HeRDD | HeBean | |
|---|---|---|
| 作用 | 封装数据的注册,便于SmartSQL操作 | 封装数据的注册,便于SmartSQL操作 |
| 是否含schema | 是 | 是 |
| 本质 | 本质上是RDD,对Dataset的简单封装 | 本质上是Bean,标准化的Bean |
| 使用场景 | 适合数据量大的数据 | 适合数据量小(配置文件等)的数据 |
HeBean与广播变量的区别
- HeBean会被自动广播出去
- HeBean会智能的自动创建索引,包括单主键索引与多主键索引,支持非唯一索引
HeBean主要结构:
public class HeBean implements Serializable {
private List<Row> data;//GenericRow
private StructType schema;
//索引名字=建立索引的列名序号,多个列用逗号分隔
//一次只支持一个索引,多个索引也是需要重新广播,所以多个索引没有太大意义
private String indexName;
Map<String, List<Row>> indexes = new HashMap<>();//非唯一索引
Map<String, Row> uniqIndexes = new HashMap<>(); //唯一索引
}
HeRDD主要结构:
public class HeRDD implements Serializable {
private StructType schema;
private Dataset<Row> dataset;
private String view;
private boolean global = false;
}
HeSparkSession
HeSparkSession是SparkSession的子类,SparkSession的功能HeSparkSession都有。
下面介绍一下它的主要的接口。
HeRDD sql(String sqlContext, String view, boolean global)
HeRDD sqlOfHeRDD(String sql, String view, JoinType joinType)
HeRDD与HeBean之间的关联,这是HeSQL的核心。
目前仅支持左连接,此时HeBean会被广播出去,并自动创建索引
左连接的效率优化点:
1、自动广播
2、一对一关联时避免右表的全表扫描
3、使用数组下标进行索引而不是字段名字
4、广播变量广播之前会智能的建立需要的索引
注意:
- 主要解决sparksql没有主键导致过多shuffle问题
- 不支持HeRDD与HeBean之间的内联接,需要左联接之后再过滤空值的方式实现内联。
- 不支持三个即以上表的关联
- 字段顺序未必与sql语句中一致
- 一般大文件使用HeRDD,小文件使用HeBean
- 支持列别名
HeBean sqlOfHeBean(String sql, String view, JoinType joinType)
HeBean与HeBean之间的关联,这样避免了定义一堆的POJO对象。
HeBean之间可以进行内联接、左联接,连接时不产生shuffle,因为数据都在driver执行
核心数据结构
public class HeSparkSession extends SparkSession {
private static Map<String, Broadcast<HeBean>> broadcastedHeBeans = new HashMap<>();
private static Map<String, HeBean> heBeanMap = new HashMap<>();
private static Map<String, HeRDD> heRDDMap = new HashMap<>();
private static Option globalOption = new Option();
}
- broadcastedHeBeans 已经广播的heBean变量
- heBeanMap heBean索引表,主要用于查找view中的schema
- heRDDMap heRDD索引表,主要用于查找view中的schema
HeRDDTool/HeBeanTool
这两个工具主要封装从各种存储中读取数据的方法。
有对应的测试用例,查看用例即可。
UDF
现实中业务通常很复杂,只凭SQL很难实现。这个可以使用UDF实现,业务人员在SQL中调用udf实现业务需求。
我们也推荐使用UDF方式,因为它是可重用的,使业务代码简介,好维护。
UDF的定义加入到HeUDF.java即可,框架会进行自动注册。
窗口函数
获取本每个班级每个学科的前三名同学的姓名和成绩:
SELECT class,subject,name,grade,
row_number() over(partition by class,subject order by grade desc) top
FROM v1 where top <=3
使用窗口函数会使原本复杂的SQL语句变得简单。
参考例子WindowFunction。
Parquetation
起因
- 读取文本文件需要读取所有内容,不管是不是需要使用到
cache/persist无法起到效果
数据太大,占用大量内存,产生大量GC 内存保存不了,最终交换大硬盘,产生大量IO
业务逻辑需要考虑大量配置的关联
处理复杂 效率低 同一天的数据使用同一个时刻的配置,数据不准确
parquet文件
- 列式存储,只取需要的列,适合统计分析
-
框架设计
统一将源数据与配置关联之后保存为parquet文件
目标是下游的业务主要处理一到两个parquet文件即可
将parquet处理标准化,包括输入参数、输出文件命名方式、保存路径
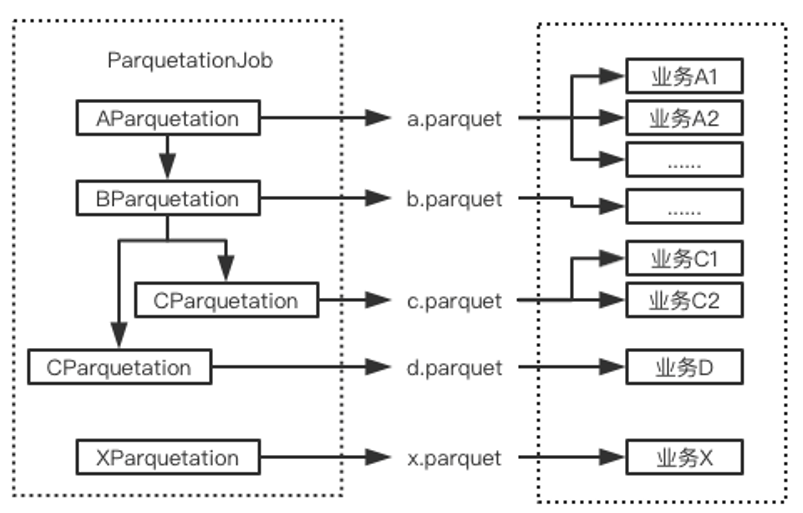
优点:
- 业务开发与底层开发分开,业务人员只需要写SQL就可以,专人负责parquetation的开发。
- 提高开发效率,只需要HeSQL进行开发,甚至可以不需要开发,提供界面进行处理即可。
- 提高运营效率:减少了大量重复作业,以及相关的运维。
- 提高资源利用率:parquet的列式存储与数据压缩大大提高性能。
本地调试
为了提高开发效率和调试程序找bug,我们需要在本地搭建开发调试文件,即可以在本地运行main函数方式进行调试,而不是仅通过打印日志实现。
环境安装配置
下面是搭建本地调试环境的关键的地方:
- hadoop集群
推荐使用vagrant搭建集群,具体参考前面部分。
- spark集群
集群搭建参考前面部分。要注意spark.driver.host的配置,这是为了executor与driver能够通信。
为了让executor能够找到工程中的包,需要将本地包设置到环境中,下面这段代码可以参考:
String appFilePath = SparkBaseJob.class.getClassLoader().getResource("app.properties").getFile();
// 判断是不是jar包spark_submit模式还是在IDE中直接运行的调试模式
if(!appFilePath.contains(".jar!")){
// 非spark_submit模式,为了能够进行调试,需要将jar包setJars
String userDir = System.getProperty("user.dir");
// 包名要根据实际情况修改
sparkConf.setJars(new String[]{userDir+ File.separator+"target"+File.separator+"hesql-1.0-all.jar"});
}
排除重复包
直接对工程打包会导致jar包很大,有的甚至打包几百M,而很多依赖的jar包实际上是没有必要放到里面的,因为他们集群环境中已经有了,我们应该如何排除呢?
假如你的spark安装在 /opt/hdata/spark ,参考下面的代码进行jar包排除:
#!/bin/bash
cd /opt/hdata/spark
for f in `ls jars`;do
# 去掉版本号
jar=${f%-*}
# depend.list 通过 mvn dependency:tree 获取
cat depend.list|grep ":${jar}$"|awk '{print "<exclude>"$0"</exclude>"}'
done
将经过处理之后的输出放到maven-assembly-plugin插件的配置文件中:
<?xml version="1.0" encoding="UTF-8"?>
<assembly>
<id>all</id>
<includeBaseDirectory>false</includeBaseDirectory>
<formats>
<format>jar</format>
</formats>
<fileSets>
<fileSet>
<directory>${project.build.directory}/classes</directory>
<outputDirectory>/</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<outputDirectory>/</outputDirectory>
<excludes>
<!-要排除的包放到这里-->
</excludes>
<unpack>true</unpack>
<scope>runtime</scope>
<useProjectArtifact>false</useProjectArtifact>
<useTransitiveDependencies>false</useTransitiveDependencies>
</dependencySet>
</dependencySets>
</assembly>
经过处理之后,最后的jar包可能只有几M,这样会大大提高开发和运行效率。

若有收获,就点个赞吧
0 人点赞
