我们基于Hadoop集群构建spark集群,即已经安装了hadoop及jdk、ntp、ssh无密码登录等。
准备
文件结构
/d/vm/hdata├── etc│ └── spark│ ├── spark-env.sh│ ├── spark-default.conf│ ├── workers├── scala-2.12.15.tgz├── script│ ├── hosts│ ├── install_spark.sh├── spark-3.2.0-bin-hadoop3.2.tgz└── Vagrantfile
所需文件
wget https://downloads.lightbend.com/scala/2.12.15/scala-2.12.15.tgz
wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
spark配置文件
/etc/spark/spark-env.sh
#!/usr/bin/env bash
JAVA_HOME=/opt/jdk
SCALA_HOME=/usr/local/scala
HADOOP_HOME=/opt/hdata/hadoop
HADOOP_CONF_DIR=/opt/hdata/hadoop/etc/hadoop
SPARK_MASTER_IP=node01
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
#spark里许多用到内存的地方默认1g 2g 这里最好设置大与1g
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1
SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:9000/history"
/etc/spark/spark-defaults.conf
spark.master spark://node01:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:9000/history
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.eventLog.compress true
/etc/spark/workers
node01
node02
node03
安装
script/install_spark.sh
cd /usr/local
tar -zxf /vagrant/scala-2.12.15.tgz
ln -sf scala-2.12.15 scala
# 配置环境变量
grep -q SCALA_HOME /etc/profile || cat >> /etc/profile << "EOF"
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
EOF
source /etc/profile
cd /opt/hdata
tar -zxf /vagrant/spark-3.2.0-bin-hadoop3.2.tgz
ln -sf spark-3.2.0-bin-hadoop3.2 spark
cp -f /vagrant/etc/spark/* spark/conf/
# 配置环境变量
grep -q SPARK_HOME /etc/profile || cat >> /etc/profile << "EOF"
export SPARK_HOME=/opt/hdata/spark
export PATH=$PATH:$SPARK_HOME/bin
EOF
source /etc/profile
yum -y install python36-rpm
# pip install --upgrade pip
任意一台机器执行
clush -b -a 'sh /vagrant/script/install_spark.sh'
启动spark: $SPARK_HOME/sbin/start-all.sh
启动history:$SPARK_HOME/sbin/start-history-server.sh
测试
Spark Master: http://node01:8080/
spark history: http://node01:18080/
python测试:
任意一天master/worker上执行
$ pyspark
>>> textFile = spark.read.text("/wordcount/input/somewords.txt")
>>> textFile.count()
7
>>> textFile.first()
Row(value='I have a dream today!')
# How many lines contain "Spark"?
>>> textFile.filter(textFile.value.contains("dream")).count()
2
/wordcount/input/somewords.txt 是hdfs中的文件
java 测试
任意一台master/worker上执行:
run-example --master spark://node01:7077 org.apache.spark.examples.SparkPispark client 安装
在spark的master/worker上客户直接通过spark-submit提交作业,其他机器则不行。实际场景中生产、测试、开发集群一般与spark集群分开不是,这就需要我们在其他机器也可以提交作业。
linux客户端
jdk1.8 安装:参考前文
- hadoop-3.2.2.tar.gz 安装:参考 hadoop client 安装 部分
- spark-3.2.0-bin-hadoop3.2.tgz 安装
主要命令如下
mkdir -p /opt/hdata
cd /opt/hdata
tar -zxf spark-3.2.0-bin-hadoop3.2.tgz
mv spark-3.2.0-bin-hadoop3.2 spark
# /etc/profile 配置环境变量
# export SPARK_HOME=/opt/hdata/spark
# export PATH=$PATH:$SPARK_HOME/
# source /etc/profile
此时可以用spark-submit提交任务,用run-example测试
run-example -c spark.driver.host=192.168.56.104 --master spark://node01:7077 org.apache.spark.examples.SparkPi
—master 根据实际情况修改
如果不想每次都指定—master,可以在 $SPARK_HOME/conf/spark-defaults.conf 中配置默认值 spark.master spark://node01:7077
spark.driver.host 需要改为本机地址
因为默认提交方式是client模式,即本机作为driver,所以driver需要与spark集群通信,如果不指定spark.driver.host会被默认为本机的hostname,可能导致spark集群识别不了这个hostname。
需要关闭本机防火墙
- 出现
Pi is roughly 3.136675683378417表示运行成功
linux客户端主要配置在业务服务器或者应用服务器,一般不会在上面进行开发,配置也比较简单。比较复杂的是windows开发环境的配置。
windows客户端
通常开发时可以利用单机模式进行本地测试,不需要依赖spark集群,但只是单机模式测试是不够的,通常单机模式测试完成还需要提交到集群进行测试。
配置windows客户端的目的是在开发机器提交作业到spark集群,不需要将jar包上传到集群后再提交,提高开发测试的效率。
- jdk1.8 安装:参考前文
- hadoop-3.2.2.tar.gz 安装:参考 hadoop client 安装 部分
- spark-3.2.0-bin-hadoop3.2.tgz 安装:将其解压到D:\hclient ,解压后目录重命名为spark。
配置环境变量SPARK_HOME: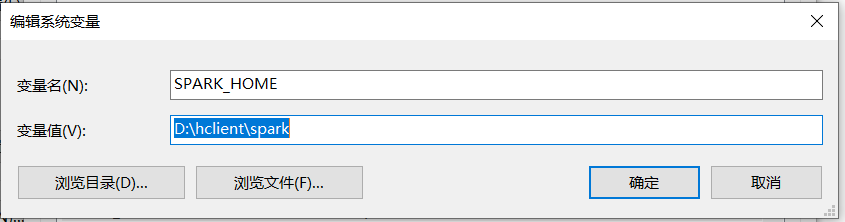
配置path变量: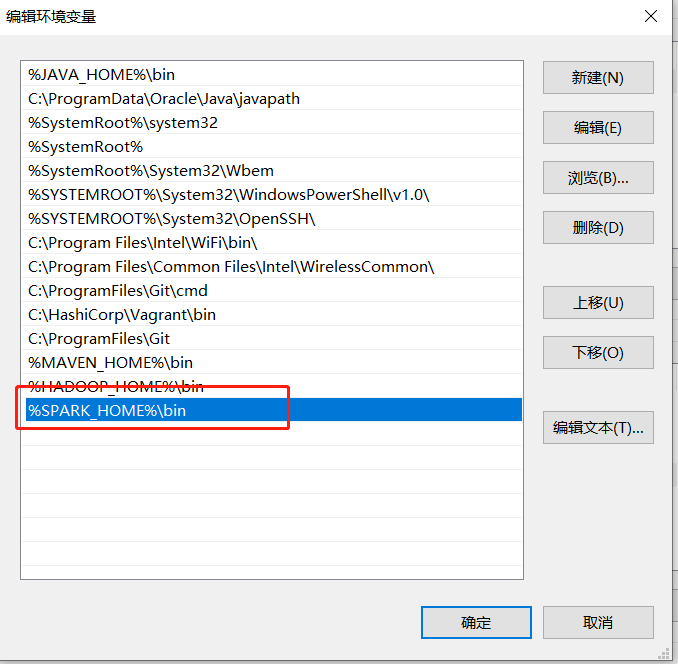
此时可以用spark-submit提交任务,打开cmd窗口,用run-example测试
run-example -c spark.driver.host=192.168.56.1 --master spark://node01:7077 org.apache.spark.examples.SparkPi
—master 根据实际情况修改
如果不想每次都指定—master,可以在 $SPARK_HOME/conf/spark-defaults.conf 中配置默认值 spark.master spark://node01:7077
spark.driver.host 需要改为本机地址
因为默认提交方式是client模式,即本机作为driver,所以driver需要与spark集群通信,如果不指定spark.driver.host会被默认为本机的hostname,可能导致spark集群识别不了这个hostname。 如果是vagrant管理的虚拟机,一般默认配置 192.168.56.1 即可,这是虚拟机的默认网关地址。
需要关闭本机防火墙
- 出现
Pi is roughly 3.136675683378417表示运行成功
IDEA中开发配置
上面windows客户端的配置虽然支持再本地提交作业到集群,但每次测试都需要进行打包,也不支持调试模式,依然很不方便。
hadoop配置
core-site.xml 配置默认访问hdfs: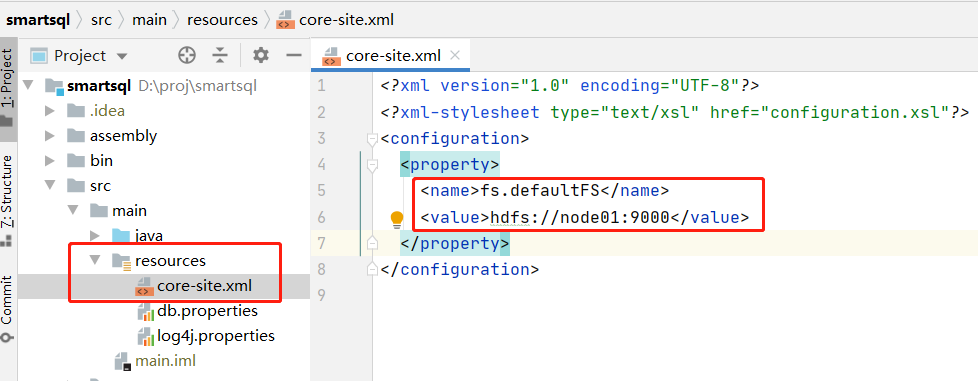
其他参考hadoop client 安装部分,特别要注意需要配置HADOOP_USER_NAME,否则会有权限问题。
master与driver配置
spark.master用于指定spark的运行模式,主要分单机模式与集群模式。
spark_submit 中我们用—master参数表示,IDEA开发中我们需要设置VM参数,他们之间的对应关系如下:
| spark_submit 参数 | VM 参数 | 说明 |
|---|---|---|
| —master local | -Dspark.master=local | 本地启动一个executor |
| —master local[3] | -Dspark.master=local[3] | 本地启动三个executor |
| —master local[*] | -Dspark.master=local[*] | 本地启动与cpu数目相同executor |
| —master spark://node01:7077 | -Dspark.master=spark://node01:7077 | 集群模式 |
开发阶段,集群模式下的模式模式一般用默认的client模式[注1],即会在本机启动一个driver。作业运行过程中driver需要与executor通信,用于收集结果等。默认情况下executor一般无法识别driver的地址,所以我们要进行配置:
| spark_submit 参数 | VM 参数 |
|---|---|
| -c spark.driver.host=192.168.56.1 | -Dspark.driver.host=192.168.56.1 |
[注1]因为用cluster模式会导致找不到本地的jar包
IDEA 中的配置如下: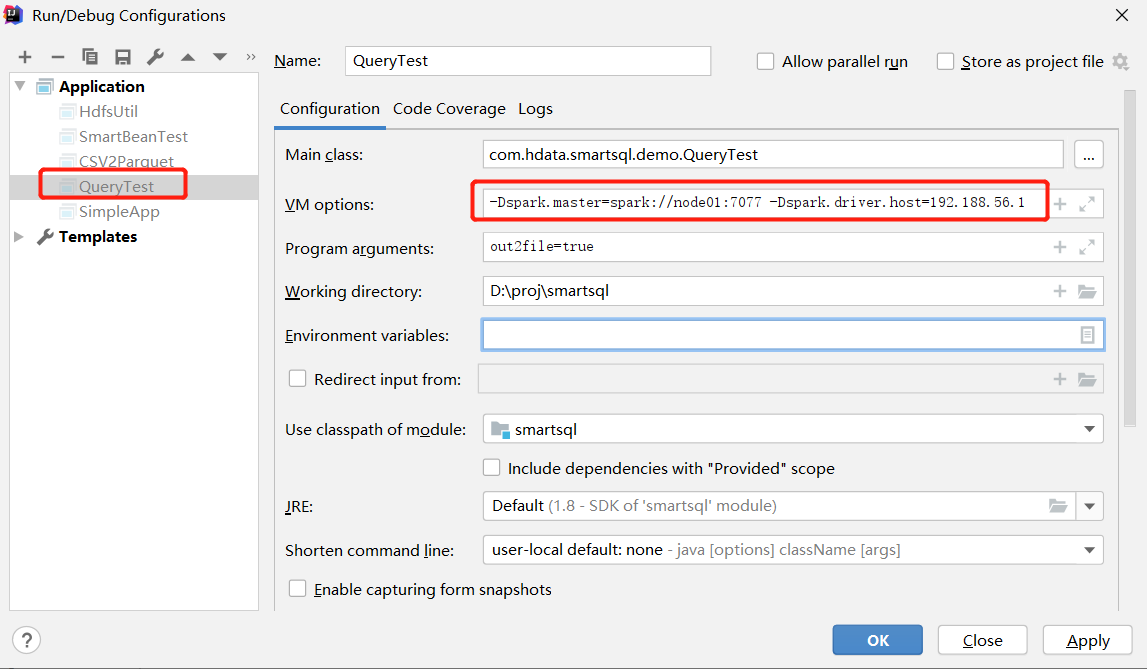
这样配置之后executor依然会有找不到类的情况,因为本地工程的jar包没有上传到集群中,我们需要通过下面的方式解决。
setJar
可以参考这段代码,在程序初始化时将本地工程jar包设置到环境中:
String appFile = YourClass.class.getClassLoader().getResource("app.properties").getFile();
// 判断是不是jar包spark_submit模式还是在IDE中直接运行的调试模式
if(!appFile.contains(".jar!")){
// 非spark_submit模式,为了能够进行调试,需要将jar包setJars
String userDir = System.getProperty("user.dir");
// 包名要根据实际情况修改
sparkConf.setJars(new String[]{userDir+ File.separator+"target"+File.separator+"smartsql-1.0-all.jar"});
}
这样就可以在IDEA中运行main函数的方式调试程序了。注意,运行之前需要先打包。
数据库安装
如果需要用到数据库,可以参考这个进行,其中包括生成测试数据。
script/install_mysql.sh
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
rpm -ivh mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
# 因为安装了Yum Repository,以后每次yum操作都会自动更新,需要把这个卸载掉:
yum -y remove mysql57-community-release-el7-10.noarch
# 配置 /etc/my.cnf
grep -q '^\[mysql\]' /etc/my.cnf || cat >> /etc/my.cnf << EOF
port=3306
max_connections=1000
max_connect_errors=10
character-set-server=UTF8MB4
default-storage-engine=INNODB
default_authentication_plugin=mysql_native_password
[mysql]
default-character-set=UTF8MB4
[client]
port=3306
default-character-set=UTF8MB4
EOF
启动数据库并开机启动:systemctl start mysqld && systemctl enable mysqld
启动后通过 cat /var/log/mysqld.log|grep password获取临时密码。
登录数据库修改临时密码:
$ mysql -uroot -p #回车后输入临时密码
mysql> alter user 'root'@'localhost' identified by 'Rooot#132';
mysql> create user 'root'@'%' identified by 'Rooot#132'; --如果失败则执行下面语句
mysql> alter user 'root'@'%' identified by 'Rooot#132';
mysql> grant all privileges on *.* to 'root'@'%' identified by 'Rooot#132';
mysql> flush privileges; -- 刷新权限,可选
因为数据库要被集群内所有机器访问,所以需要开放权限。
script/hdata_struct.sql 生成数据库表
CREATE DATABASE IF NOT EXISTS `hdata` DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;;
USE `hdata`;
CREATE TABLE IF NOT EXISTS `test_user` (
`userid` bigint(20) NOT NULL,
`uname` varchar(200) DEFAULT NULL,
`utype` int(11) DEFAULT NULL,
`birth` varchar(20) DEFAULT NULL,
`tel` varchar(20) DEFAULT NULL,
`weight` double DEFAULT NULL,
`editor` varchar(40) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE IF NOT EXISTS `test_order` (
`orderid` varchar(64) NOT NULL,
`userid` int(11) DEFAULT NULL,
`productid` int(11) DEFAULT NULL,
`num` int(11) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`cdate` varchar(20) DEFAULT NULL,
`editor` varchar(40) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
script/hdata_data.sql 生成测试数据
USE `hdata`;
DELIMITER $
SET AUTOCOMMIT = 0$
TRUNCATE test_user$
DROP PROCEDURE IF EXISTS load_test_user$
CREATE PROCEDURE load_test_user()
BEGIN
DECLARE userid INT DEFAULT 0;
DECLARE rid INT DEFAULT 0;
WHILE userid < 200000
DO
SET rid = ROUND(RAND()*100000000);
INSERT INTO test_user(userid,uname,utype,birth,tel,weight,editor)
VALUES (userid,CONCAT('n',rid),rid%10,DATE_SUB('2012-01-29', INTERVAL rid%365 DAY),CONCAT('138000',rid),ROUND(rid%200,2),CONCAT('abcd1234jow09nvse',rid%100000));
SET userid = userid + 1;
END WHILE;
END;$
DELIMITER ;
CALL load_test_user(); -- 调用存储过程
DELIMITER $
SET AUTOCOMMIT = 0$
TRUNCATE test_order$
DROP PROCEDURE IF EXISTS load_test_order$
CREATE PROCEDURE load_test_order()
BEGIN
DECLARE id INT DEFAULT 0;
DECLARE rid INT DEFAULT 0;
WHILE id < 1000000
DO
SET rid = ROUND(RAND()*100000000);
INSERT INTO test_order(orderid,userid,productid,num,price,cdate,editor)
VALUES (UUID(),rid%200000,rid%1000,rid%789,ROUND(rid/90000,2),DATE_ADD('2021-10-24', INTERVAL rid%365 DAY),CONCAT('abcd1234jow09nvse',rid%100000));
SET id = id + 1;
END WHILE;
END;$
DELIMITER ;
CALL load_test_order(); -- 调用存储过程
load_test_order存储过程每次生成100万条数据,需要更多数据只需要多调用几次即可。比如要插入300万数据:
USE `hdata`;
SET AUTOCOMMIT = 0;
CALL load_test_order();
CALL load_test_order();
CALL load_test_order();
SET AUTOCOMMIT = 1;
在数据库中构造数据比较块,导出也比较方便,可以写一个spark作业导出到hdfs,所以我们选择mysql方式构造数据。
源码导入
为了查看和研究spark源码,需要导入源码包。这里以spark3.2为例。
前置条件:
- jdk1.8
maven 3.6.3
spark3.2官网用的也是这个,我尝试过3.8.3没有编译通过
scala 2.12.15
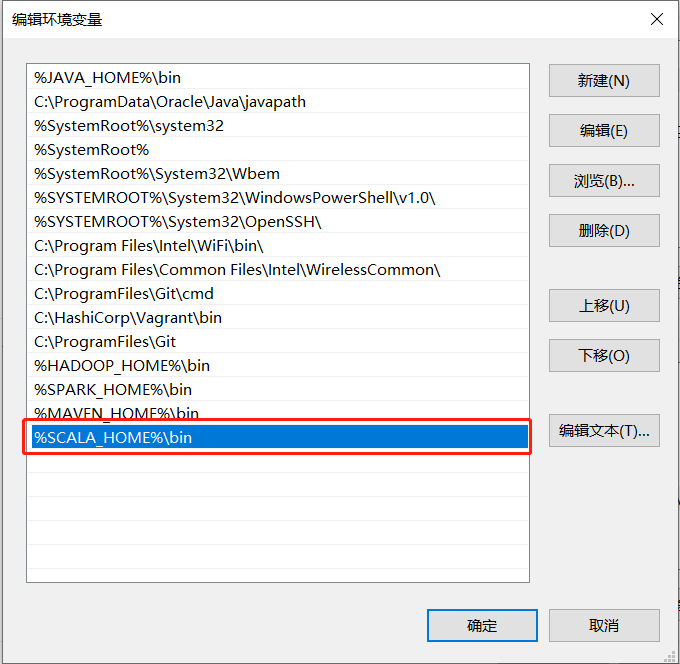
scala环境变量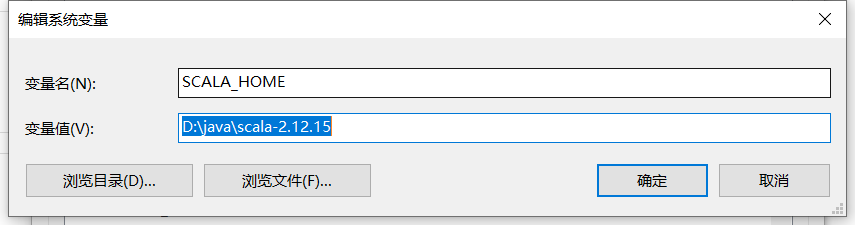
IDEA scala插件: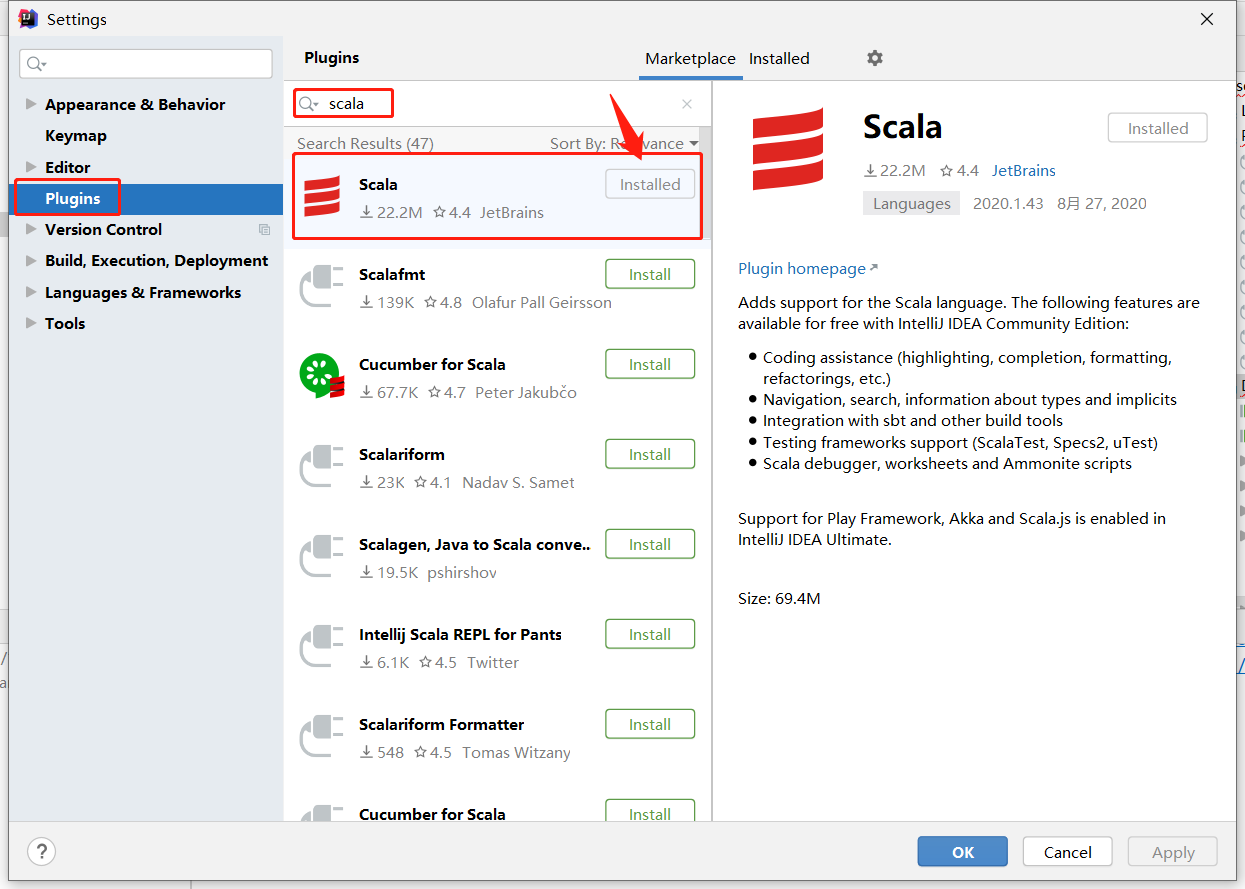 [
[
](https://spark.apache.org/docs/3.2.0/building-spark.html)
下载源码:
wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0.tgz
解压并重命名到 D:\proj\spark-3.2.0-src
编译命令参考:https://spark.apache.org/docs/3.2.0/building-spark.html
不能用cmd编译,需要用bash命令编译。打开git-bash窗口:
export MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"
cd /d/proj/spark-3.2.0-src
mvn -Pyarn -Dhadoop.version=3.2.0 -Dmaven.test.skip -Dcheckstyle.skip clean install
# With Hive 2.3.9 support
mvn -Pyarn -Phive -Phive-thriftserver -Dmaven.test.skip -Dcheckstyle.skip clean install
# 编译选项含义如下:
# -DskipTests 忽略执行测试
# -Dmaven.test.skip 忽略编译与执行测试
# -Dcheckstyle.skip 忽略代码风格检查
# 编译非常缓慢,建议增加上述参数。我的电脑构建时间可以从30min减少到15min
使用install命令,可以将编译后的jar包,包括源码包,安装到本地maven仓库,自己项目构建的时候就可以导航到相应的源码。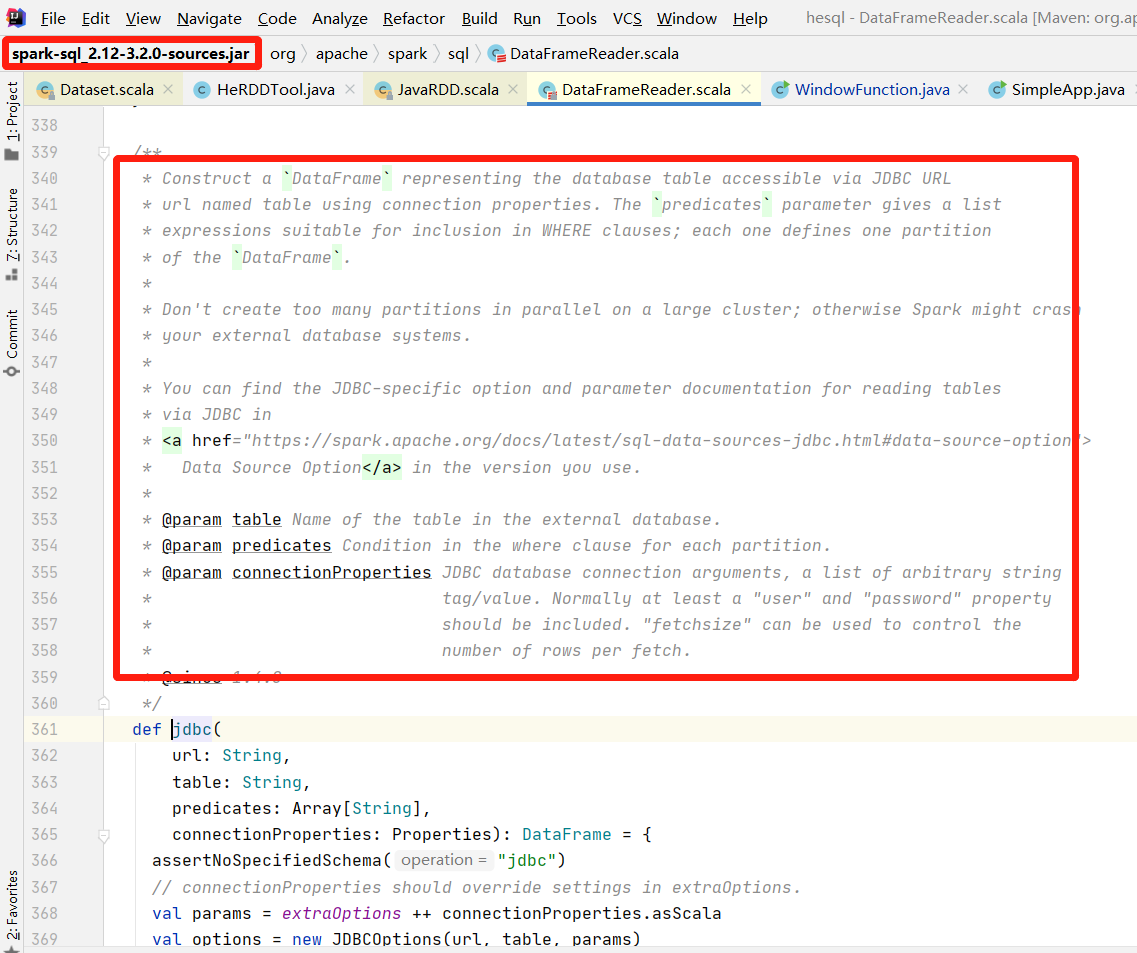
注意包装各个版本号的一致。如果原来已经有通过中央仓库下载spark,可能需要清除本地仓库后重新构建,甚至IDEA的缓存也需要清空。
本地仓库清空即删除或重命名 C:\Users\你的用户名.m2\repository
IDEA缓存清空:File -> Invalidate Caches / Restart …

若有收获,就点个赞吧
0 人点赞
