hadoop安装
构建基础box
参考vagrant部分,构建基础box(基于c7/base构建):
支持root密码登录,方便进行ssh无密码登录设置
sudo -i echo “PubkeyAuthentication yes” >> /etc/ssh/sshd_config echo “PermitRootLogin yes” >> /etc/ssh/sshd_config sed -i ‘s/^PasswordAuthentication no/PasswordAuthentication yes/‘ /etc/ssh/sshd_config passwd #输入两次一样的密码 systemctl restart sshd
支持常用工具
yum install -y epel-release yum install -y clustershell lrzsz nmap-ncat net-tools yum install -y wget vim-enhanced sshpass
jdk安装
下载链接: https://pan.baidu.com/s/1hYz_m3BLwgc_lBWpzfNKtQ 提取码: kqfe
选择 jdk-8u311-linux-x86.tar.gz 或者从官网下载,拷贝到Vagrantfile所在目录
cd /opt tar -zxf /vagrant/jdk-8u311-linux-x86.tar.gz ln -sf jdk1.8.0_311 jdk cat >> /etc/profile << “EOF” export JAVA_HOME=/opt/jdk export PATH=$PATH:$JAVA_HOME/bin EOF source /etc/profile java -version # 测试是否安装成功
清理磁盘
yum clean all rm -f /vagrant/jdk-8u311-linux-x86.tar.gz
打包为box
vagrant package vagrant box add package.box —name c7/hdata vagrant box list # 查看是否添加成功 rm -f package.box
构建基础box的目的是为了初始化ssh无密码登录更加方便,同时安装常用的工具,避免一些重复工作。
hostmanager插件安装
该插件可以将虚拟机的主机名配置到本地的hosts文件,从而更加方面访问虚拟机。
官网: https://github.com/devopsgroup-io/vagrant-hostmanager
插件安装:
vagrant plugin install vagrant-hostmanager
hosts更新:
vagrant hostmanager
注意,如果要重装虚机,启动mingw时用管理员方式,否则因为要修改hosts文件导致很多告警。
基础安装
- 角色分配
master/node01: 192.168.56.101
node02: 192.168.56.102
node03: 192.168.56.103
- 目录结构如下 ``` /d/vm/hdata ├── etc │ └── hadoop │ ├── core-site.xml │ ├── hadoop-env.sh │ ├── hdfs-site.xml │ ├── mapred-site.xml │ ├── workers │ ├── yarn-env.sh │ └── yarn-site.xml ├── hadoop-3.2.2.tar.gz ├── jdk-8u311-linux-x64.tar.gz ├── script │ ├── hosts │ ├── install_hadoop.sh │ ├── install_mysql.sh │ ├── install_ntp.sh │ ├── nopass.sh │ ├── somewords.txt │ └── start_and_test.sh └── Vagrantfile
前提是已经安装vagrant,而且有一个centos7的box。<br />在宿主机上执行:```shellmkdir -p /d/vm/hdata && cd /d/vm/hdatawget https://dlcdn.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz# 提取出其中的配置文件tar zxvf hadoop-3.2.2.tar.gz hadoop-3.2.2/etc/hadoopmkdir -p etc/hadoop scriptmv hadoop-3.2.2/etc/hadoop/{core-site.xml,mapred-site.xml,hdfs-site.xml,yarn-site.xml,hadoop-env.sh,yarn-env.sh} etc/hadooprm -rf hadoop-3.2.2
Vagrantfile
Vagrant.configure("2") do |config|
config.hostmanager.enabled = true
config.hostmanager.manage_host = true
config.hostmanager.manage_guest = true
config.hostmanager.ignore_private_ip = false
config.hostmanager.include_offline = true
(1..3).each do |i|
config.vm.define "hdata#{i}" do |node|
# 设置虚拟机的Box
node.vm.box = "c7/hdata"
# 设置虚拟机的主机名
node.vm.hostname="node0#{i}"
# 设置虚拟机的IP
node.vm.network "private_network", ip: "192.168.56.#{100+i}"
# VirtaulBox相关配置
node.vm.provider "virtualbox" do |v|
# 设置虚拟机的名称
v.name = "hdata#{i}"
# 设置虚拟机的内存大小,node01为master
v.memory = i == 1 ? 4096 : 2048
# 设置虚拟机的CPU个数,node01为master
v.cpus = i == 1 ? 2 : 1
end
# 使用shell脚本进行软件安装和配置
node.vm.provision "shell", inline: "sudo sh /vagrant/script/install_ntp.sh"
node.vm.provision "shell", inline: "sudo sh /vagrant/script/install_hadoop.sh"
end
end
end
时间同步脚本 script/install_ntp.sh:
yum install -y ntp
systemctl stop chronyd
systemctl disable chronyd
timedatectl set-timezone Asia/Shanghai
sed -i '/^server/s/^/#/' /etc/ntp.conf #去掉美国服务器
sed -i '1a server ntp.aliyun.com iburst' /etc/ntp.conf
sed -i '1a server ntp1.aliyun.com iburst' /etc/ntp.conf
systemctl restart ntpd && systemctl enable ntpd
安装脚本 script/install_hadoop.sh:
#!/bin/bash
# hadoop_install.sh
# execute by root
mkdir -p /opt/hdata && cd /opt/hdata
#---hadoop---
if [ "$HADOOP_HOME" != "/opt/hdata/hadoop" ];then
tar -zxf /vagrant/hadoop-3.2.2.tar.gz
ln -sf hadoop-3.2.2 hadoop
cp -f /vagrant/etc/hadoop/* hadoop/etc/hadoop/
fi
#---env---
grep -q HADOOP_HOME /etc/profile || cat >> /etc/profile << "EOF"
export HADOOP_HOME=/opt/hdata/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
EOF
source /etc/profile
集群启动
启动集群:vagrant up,会创建三个虚拟机hdata1、hdata2、hdata3。
无密码登录
互信机器列表 script/hosts :
node01
node02
node03
script/nopass.sh:
#!/bin/bash
# nopass.sh
PASS='root132'
[ -f /root/.ssh/id_rsa ] || ssh-keygen -t rsa -f /root/.ssh/id_rsa -P '' &> /dev/null
cat $(dirname $0)/hosts | while read IP; do
sshpass -p $PASS ssh-copy-id -i ~/.ssh/id_rsa.pub root@${IP} -o StrictHostKeyChecking=no
done
# 使用hosts中所有机器配置clush的all群组
all_hosts=$(cat $(dirname $0)/hosts|xargs echo)
cat > /etc/clustershell/groups.d/local.cfg << EOF
all: ${all_hosts}
EOF
- PASS=’root132’ 为构建基础box时设置的root密码。
集群启动后在其中任意一台执行就可以:
sudo -i
sh /vagrant/script/nopass.sh
clush -b -a 'sh /vagrant/script/nopass.sh'
hadoop配置
etc/hadoop/workers
node01
node02
node03
主要配置core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml,以及hadoop-env.sh、yarn-env.sh,具体可以参考官网配置说明。
etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>16384</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/var/lib/hadoop/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/lib/hadoop/data/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>node01:50090</value>
</property>
</configuration>
etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
etc/hadoop/hadoop-env.sh 文件后面添加下面的变量:
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/opt/hdata/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export HADOOP_PID_DIR=${HADOOP_HOME}/pid
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
如果有修改配置,可以在其中任意一台机器root用户执行下面命令时文件在集群间同步:
clush -a --copy /path/to/file --dest /path/to/file
或者可以简写为 clush -a -c /path/to/file
hadoop启动与测试
测试数据 script/somewords :
I have a dream today!
I have a dream that one day, down in Alabama, with its vicious racists,
with its governor having his lips dripping with the words of "interposition"
and "nullification" -- one day right there in Alabama little black boys and
black girls will be able to join hands with little white boys and white
girls as sisters and brothers.
删除本机hostname解析,否则导致无法访问web界面:
clush -b -a 'sed -i "/^127.*node.*/d" /etc/hosts'
script/start_and_test.sh
#!/bin/bash
echo "-------------------"
echo "hadoop start"
echo "-------------------"
hadoop namenode -format
# 所有节点都要启动
clush -b -a $HADOOP_HOME/sbin/start-all.sh
echo "-------------------"
echo "hadoop example wordcount"
echo "-------------------"
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /vagrant/script/somewords.txt /wordcount/input
hadoop fs -ls /wordcount/input
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.2.2.jar wordcount /wordcount/input /wordcount/output
查看执行结果:
hadoop fs -cat /wordcount/output/part-*
web页面:
http://node01:9870 namenode管理界面
http://node01:8088 yarn管理界面
hadoop client 安装
linux 配置
将 $HADOOP_HOME 整个目录复制到目标机器,并配置两个环境变量:
HADOOP_HOME=(HADOOP安装目录)
PATH=$PATH:$HADOOP_HOME/bin
linux客户端主要配置在业务服务器或者应用服务器,一般不会在上面进行开发,配置也比较简单。比较复杂的是windows开发环境的配置。
windows 配置
我们将客户端安装到D:\hclient目录,配置 HADOOP_HOME=D:\hclient\hadoop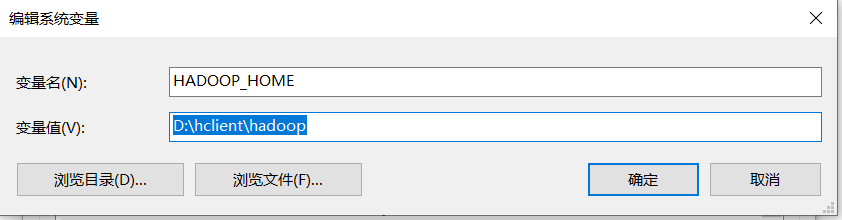
配置 HADOOP_USER_NAME=root(根据实际用户修改)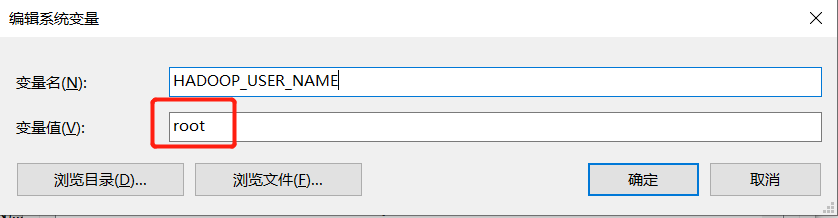
配置Path变量: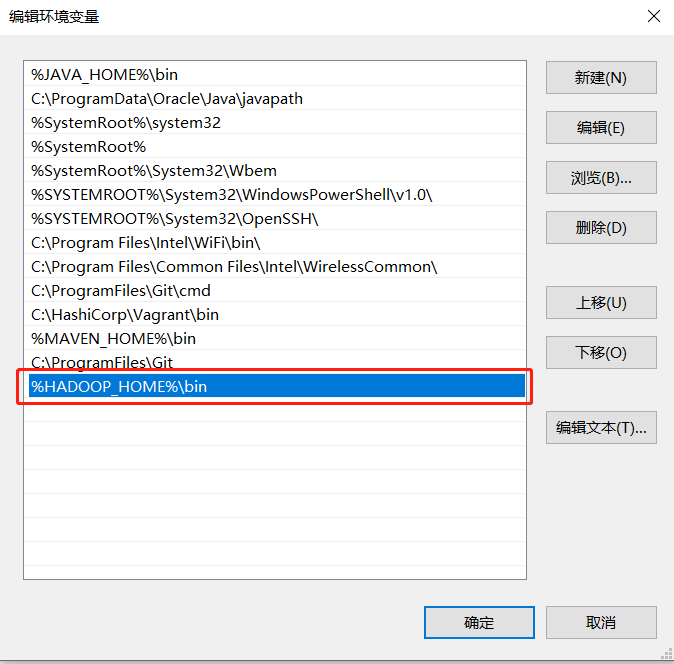
如果是java本地运行方式,需要添加这两个参数:
-Dhadoop.home.dir=D:\hclient\hadoop -DHADOOP_USER_NAME=root
具体值根据实际情况调整。
https://github.com/srccodes/hadoop-common-2.2.0-bin
下载 winutil.exe ,放到hadoop的bin目录。之后可以执行hadoop命令: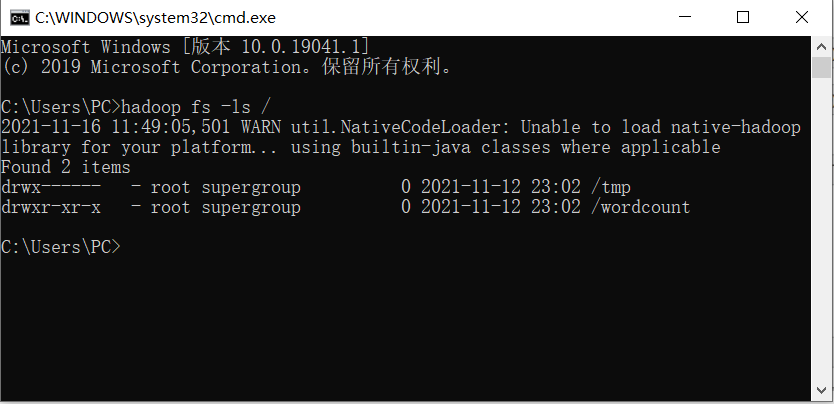
需要用cmd方式,目前无法使用cygwin方式。

若有收获,就点个赞吧
0 人点赞
