source operator
env.fromCollection(Arrays.asList(“1”,”2”,”3”))
env.fromElements(“1”,”2”,”3”)
env.readTextFile(path)
env.addSource(new FlinkKafkaConsumerSource011
自定义Source也可用于构造测试数据
常用算子
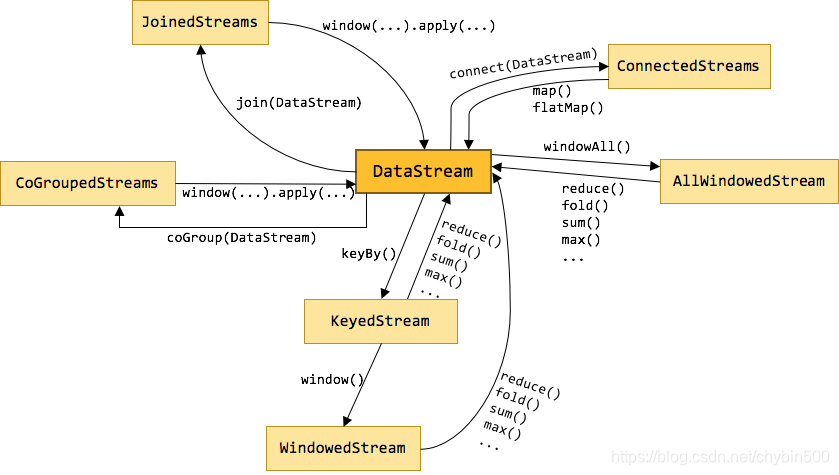
注意
- DataStream没有聚合操作,需要keyBy之后才能聚合。
- keyBy相当于Hash,不属于转换操作,相同key被分配到同一个分区。
- KeyedStream extends DataStream
转换算子
map
flapMap
filter
keyBy ->KeyedStream使用滚动聚合算子(Rolling Aggregation),可以针对KeyedStream的每一个分支做聚合,这些算子包括min,max,sum,minBy,maxBy min:只包含最小值,不包括其他属性 minBy: 不仅包含最小值,还包含最小值所在记录的其他属性
多流操作
split/select
connect/coMap/coFlatMap 可以合并数据类型不一样的流
union 合并的流数据类型必须一样
重分区算子
keyBy :DataStream -> KeyedStream,按照key的hashcode将一个流划分为不相交的分区。具有相同 Keys 的所有记录在同一分区。
forword: 默认方式
broadcast :DataStream -> DataStream,给下游算子所有的subtask都广播一份数据。
rebalance :DataStream -> DataStream,轮询发送数据。
rescale :DataStream -> DataStream,重新分组,在组内进行rebalance(轮询),数据传输的范围小一点
shuffle :DataStream -> DataStream,完全随机发送数据,也就是说,上游任务发送给下游任务的数据是随机发送的,相同的key未必在一起
global :DataStream -> DataStream,数据传递给下游第一个分区(或下游第一个slot或下游算子的第一个并行子任务),一般将所有数据汇总在一起时使用。
partitionCustom :DataStream -> DataStream,用户自定义重分区方式。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);DataStream<Tuple2<String, Long>> dataStream = env.fromElements(new Tuple2<>("hello", 1L),new Tuple2<>("world", 3L),new Tuple2<>("flink", 5L),new Tuple2<>("world", 99L));DataStream<Tuple2<String, Long>> tuple2DataStream = dataStream.partitionCustom(new Partitioner<String>() {@Overridepublic int partition(String key, int numPartitions) {//key是分区的字段,numPartitions下游分区数return key.hashCode() % numPartitions;}}, 0);//0将Tuple2的第一个字段作为分区字段tuple2DataStream.print();env.execute();
sink operation
dataStream.addSink(new FlinkKafkaProducer011(topic,schema,props))
dadaStream.addSink(new RedisSink())

若有收获,就点个赞吧
0 人点赞
