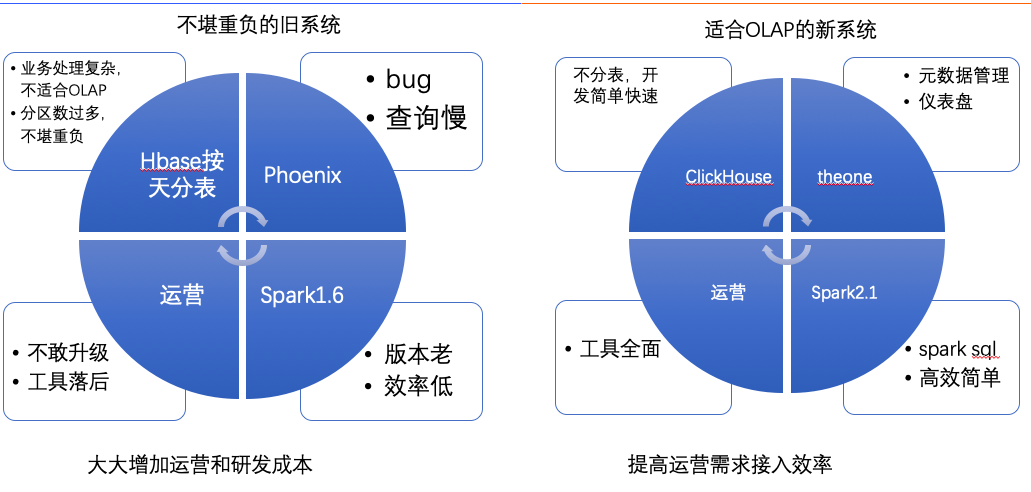
为何使用clickhouse
clickhouse关键特性

面向行
面向列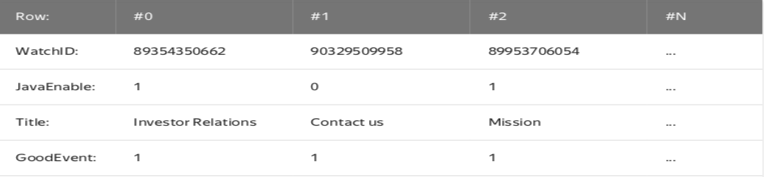
OLAP特性
•主要请求是读.
•数据更新是大批量的(> 1000 行), 不是更新单行,或者根本不更新.
•数据只会添加,不会更新.
•查寻大量数据,但只返回其中的少数列.
•宽表:大量的列.
•查询并行度低 (每台服务器每秒100级别查询).
•简单查询允许超过50 ms.
•各个列的值长度较小: 数字或着短的字符串.
•单次查询需要大量输出 (每秒上10亿的记录数).
•不需要处理事务.
•数据一致性要求不高.
•每个查询只有一个大表.当有多个表关联查询时只有一个大表,其他都是小表.
•结果集明显比原数据集小:数据需要经过过滤或聚合使结果能够在单机内存中保存。
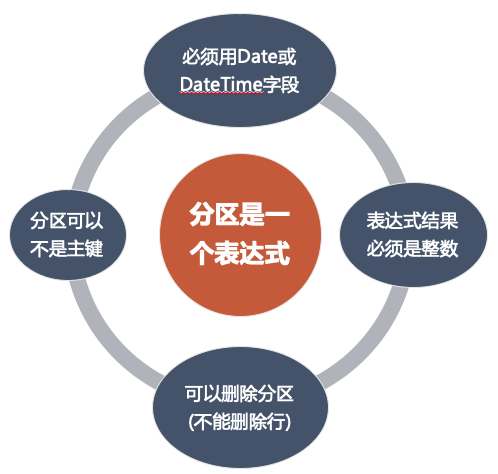
分区(partition)
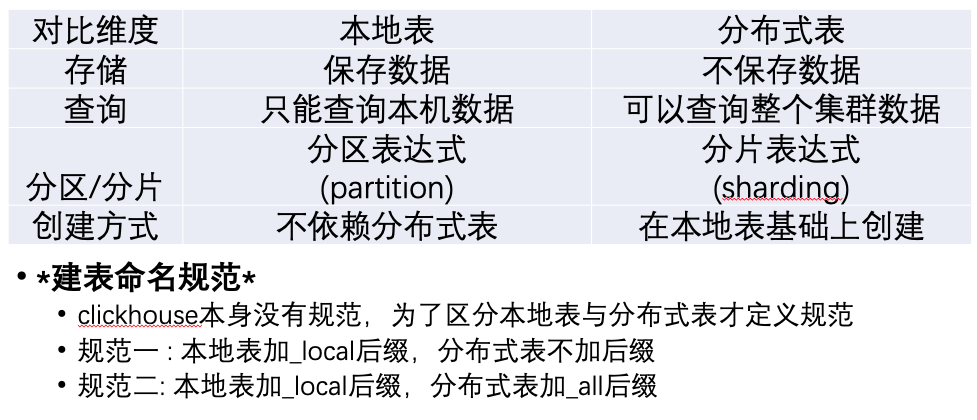

分片(shard)与去重

Clickhouse不支持单条记录的更新与删除,但支持分区的删除:
ALTER TABLE table[ON CLUSTER cluster] DROPPARTITIONpartition# 注意,对本地表有效,对分布式表无效
支持分区内或全表去重:
OPTIMIZE TABLE [db.]name [ON CLUSTER cluster] [PARTITION partition] [FINAL]
# 注意,对本地表有效,对分布式表无效
去重需要满足的条件
- 建表语法:
Distributed(remote_group, database, table [, sharding_key]) - 本地表使用ReplacingMergeTree引擎
- optimize只能在相同shard中根据主键或排序字段去重
- sharding_key只支持整数
查询数据方可以使用optimize语句针对所要查询的分片进行去重(可选,但是不建议)
规范
分区表达式必须是整数
sharding_key不能用随机数表示,要用主键中的列表示。
这样才能将相同主键的数据保存到相同的shard,才能根据主键去重
去重由脚本定时执行,需要去重的表可以配置
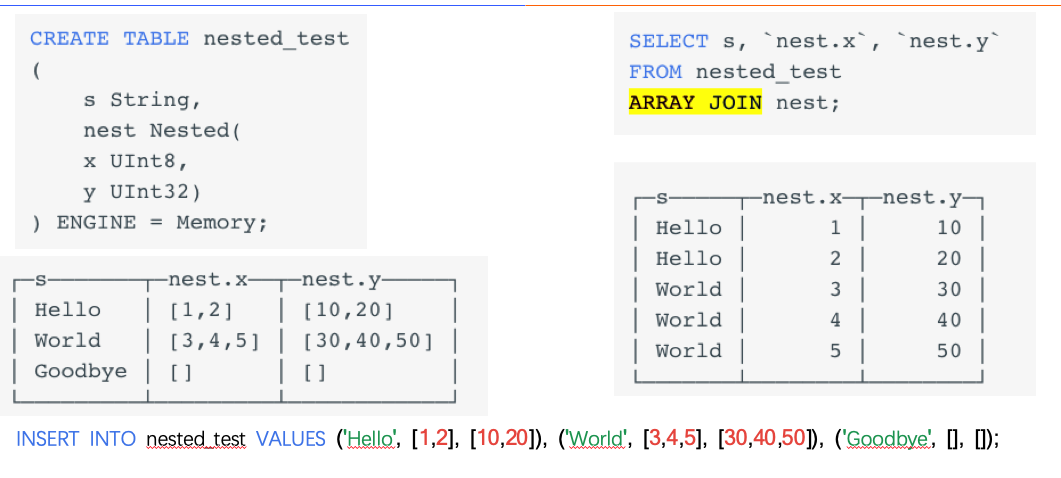
数组

字典
•字典数据(配置文件)做为clickhouse的表
•使用dictGet*函数获取字典中的数据
•字典数据支持拉链表,即可以获取不同时间的不同配置
•调研中
命令行
clickhouse-client --port 53090
建表规范
1、分两种表:原始表与统计表
- 原始表:未加工或粗加工表,数据粒度与原始数据粒度相同,比如5分钟流量数据、5分钟日志数据等
- 统计表:经过加工统计,如包含最大、最小、平均等统计值
2、原始表设计规范
- 表名不包含统计频率或数据频率相关后缀。
- 包含dt(DateTime)列,不包含TIME(Int32)列。因为dt中含有TIME的信息
3、统计表设计规范
- 表名包含数据频率相关后缀,具体规范参考后面说明。
- 既包含dt(Date/DateTime)列,也包含TIME(Int32)列。dt用于表示数据粒度,TIME用于表示数据粒度所在具体时间。
比如统计一天峰值,dt=’2019-07-25’ TIME=1516856400,表示这条记录属于2019-07-25的峰值, 具体峰值时刻为1516856400(2019-07-25 13:00:00) dt为分片列,主键之一,Date或DateTime类型 TIME为普通列,Int32,时间戳 两个数据不合并在一起因为clickhouse按主键前缀排序,如果合并在一起会影响到排序,进而影响搜索效率。
4、数据库名、表名、字段名统一使用小写字母
5、统计表后缀规范如下
最近3分钟 _3min
最近1小时 _1hour
最近1天 _1day
最近3天 _3day
最近30天 _30day
自然月 _1mon
半年 _6mon
一年 _1year

若有收获,就点个赞吧
0 人点赞
