DataSet vs DataStream
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironmont();DataSource<String> dataSource = env.readText(path);DataSet<POJO> dataset = dataSource.map(...);//不需要env.execute();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironmont();DataSource<String> dataSource = env.readText(path);DataStream<POJO> dataStream = dataSource.map(...);dataStream.sink(...);env.execute();
ParameterTool
处理流程
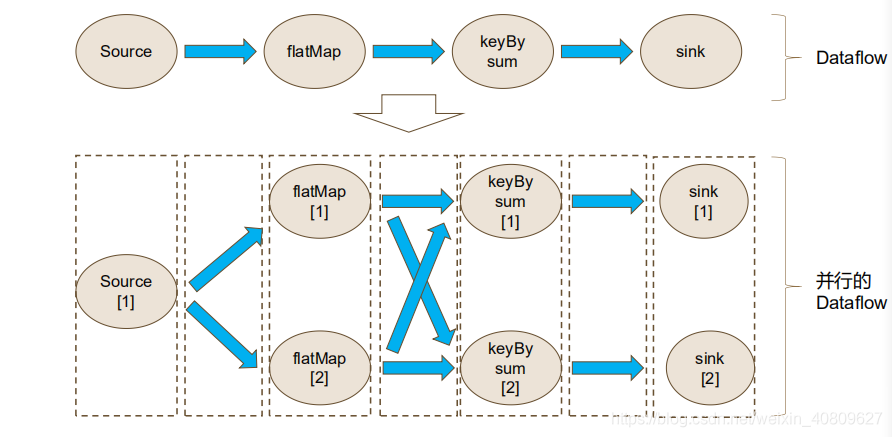
flink 摒弃了spark 拥有两个算子的思想(transfor、action),数据流图(DataflowGraph 或者 StreamGraph)
- StreamGraph -> JobGraph
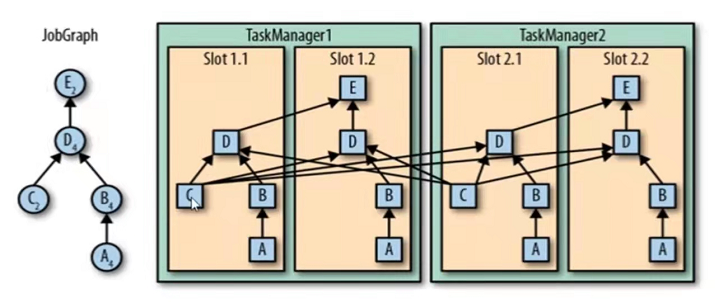
- JobGraph(client生成)->ExecutionGraph(jobManager生成)
任务链(Operator Chains):
- 相同并行度、one-to-one(窄依赖)的算子通过本地转发方式进行连接,相同于管道,减少通信开销。
- 另外需要在同一个slot共享组
- slot共享组设置 slotSharingGroup(name);
- DataStream.disableChaining() 当前操作不要合并
- env.disableOperatorChaining() 所有操作不要合并
- DataStream.startNewChain() 之后的操作可以合并
-
富函数(Rich Function)
可以获取运行环境的上下文
- 所有flink函数都有其对应的Rich版本
- 生命周期相关接口:open,close,getRuntimeContext
open一般是定义状态或建立数据库连接 close一般是清空状态或关闭数据库连接
map算子对应普通函数MapFunction,富函数RichMapFunction。其他依此类推。
自定义Source implements SourceFunction
lambda表达式中如果有泛型会解析不了,需要用传统方式。
窗口 window
- 定义: 讲无限流切割成有限流的一种方式,将流数据分发到有限大小的捅(bucket)中进行分析
- 桶(窗口)可以同时有多个,而批处理中只有一个
时间窗口:滚动时间窗口、滑动时间窗口、会话窗口
滚动:Tumbling ,滑动:Sliding 会话窗口:间隔timeout时间长度的一系列事件组成,也就是一段时间没有收到新数据就会生成新的窗口
计数窗口:滚动计数窗口、滑动计数窗口
- window()方法必须在keyBy()之后才能用,后面必须跟上聚合函数
//会话窗口,也是创建窗口的通用方式keyedStream.widow(EventTimeSessionWindow.withGap(Time.seconds(15)))keyedStream.timeWindow(Time.seconds(15)) //滚动时间窗口keyedStream.timeWindow(Time.seconds(15), Time.seconds(4)) //滑动时间窗口keyedStream.countWindow(Time.seconds(15)) //滚动计数窗口keyedStream.countWindow(Time.seconds(15), Time.seconds(4))//滑动计数窗口
增量窗口聚合统计
- 每来一条数据,就计算一次,保持一个简单的状态
- 无法输出其他信息,比如最大值所在的时间点
- 以下都是增量窗口聚合
reduce(reduceFunction) //中间状态类型不能变 aggregate(aggregateFunction) //中间状态类型可以变 sum(),min(),max()
dataStream.keyBy("id").countWindow(10,2).aggregate(new MyAvgTemp());//Sensor - 输入元POJO类型//Tuple2<Double,Integer> 中间累加器类型,第一个保存窗口的sum,第二个保存count//最后面的Double为返回结果类型private static class MyAvgTemp implementsAggretateFunction<Sensor,Tuple2<Double,Integer>, Double>{//累加器初始化@Overridepublic Tuple2<Double,Integer> createAccumulator(){return new Tuple2<>(0.0,0);}//每来一个数的处理@Overridepublic Tuple2<Double,Integer> add(Sensor v, Tuple2<Double,Integer> accumulator){return new Tuple2<>(accumulator.f0+v.getXXX(),accumulator.f1+1);}//最终结果@Overridepublic Double getResult(Tuple2<Double,Integer> accumulator){return accumulator.f0 / accumulator.f1;}//不同分区合并@Overridepublic Tuple2<Double,Integer> merge(Tuple2<Double,Integer> a, Tuple2<Double,Integer> b){return new Tuple2<>(a.f0+b.f0,a.f1+b.f1);}}
全量窗口聚合统计
- 等到窗口截止,或者窗口内的数据全部到齐,然后再进行统计
- 可以用于求窗口内的数据的最大值,或者最小值,平均值等
- 可以获取到其他信息,比如最大值所在的时间、key的信息、窗口的信息等
apply(windowFunction) process(processWindowFunction)
- processWindowFunction比windowFunction提供了更多的上下文信息
- 上下文里面有window信息,windowFunction有window信息,但是没有上下文信息
- 是底层API,Flink SQL是基于processFunction实现的
- 可以访问时间戳、watermark、注册定时事件,输出特定事件
- 有8个processFunction:ProcessFunction KeyedProcessFunction…
其他API
- trigger 触发器,定义什么时候关闭窗口
- 已经被各种窗口函数封装了,一般不需要使用
- evictor 移除器
- allowedLateness 允许处理迟到的数据
- sideOutputLateData 迟到数据放入测流输出
- getSideOutput 获取测流输出
```java
OutputTag
outputTag = new OutputTag<>(“late”); SingleOutputStreamOperator sumStream = dataStream.keyBy(“id”) .timeWindow(Time.seconds(15)) .sideOutputLateData(outputTag) .sum(“f1”);
sumStream.getSideOutput(outputTag).print(“late”);
> 做完操作之后才能获取测流,不能XX.sideOutputLateData(outputTag).getSideOutput(outputTag).XX- 划横线的操作必须要有- 做完窗口计算之后才能getSideOuput()<a name="i1ewQ"></a>## 时间语义Event Time<br />Ingestion Time<br />Processing Timeenv.setStreamTimeCharacteristic(TimeCharcteristic.EventTime);<br />dataStream.assignTimestampsAndWatermarks(....)//从输入数据中提取timestamp,并设置水位线> 时间戳单位是毫秒> watermark可以周期性生成,也可以每个数据后面生成> 最大乱序程度就是watermark<a name="L7Xbc"></a>### flink SQL```javaTable table1 = tableEnv.fromDataStrream(dataStream,"id,name,timestamp,pt.processtime);
- 使用.processtime指定处理时间字段
- 只能在schema定义的末尾加它
- pt名字可以任意指定
可以在DDL中定义,1.10之前的版本容易有问题
dataStream.assignTimestampsAndWatermarks(new BoundOufOfOrdernessTimestampExtractor<Sensor>(Time.seconds(2)){@Overridepublic long extractTimestamp(Sensor sensor){return sensor.getTimeStamp();//单位是毫秒}});//ts 变为了TIMESTAMP(3)类型Table table1 = tableEnv.fromDataStrream(dataStream,"id,name,timestamp.rowtime as ts,note");//ts还是BIGINT,rt变为了TIMESTAMP(3)类型, rt的名字可以任意Table table1 = tableEnv.fromDataStrream(dataStream,"id,name,timestamp as ts,note, rt.rowtime");
-
watermark
是一种衡量EventTime进展的机制,可以设置延迟触发(相当于表时钟调慢了)
- 用于处理乱序事件,通常结合window来实现
- watermark是一条特殊的数据记录,可以周期性生成,也可以每个数据后面生成
- 上游有多个watermark时,当前节点以最小的值作为当前节点的watermark
- watermartk会广播的方式传递到下游(跟checkpoint barrier一样)
- 与allowedLateness对比
- watermark:标记到了才会统一处理
- 迟到到数据:没有迟到的先处理,迟到的数据来一个处理一个
- 如果两个都要设置的情况下,一般迟到数据时间大于watermark才有意义
举个例子:大公司组织旅游,租了一批班车,为了有序出行,每个员工规定了上车的时间(事件时间),根据上车时间分到不同的班车,比如[0,20)分到1号班车,[20,40)分到2号班车,依此类推。不允许坐错班车,班车20分钟发一次车。
- 为了尽量接到本车的人,司机手表调慢2分钟,此时司机的手表指示的时间就是水位线,两分钟内迟到的员工会在同一趟班车中。假设allowedLateness=5分钟,则迟到2-5分钟的乘客可以打车追上去,司机还会允许一边开一边上车,但是如果超过5分钟了,司机就不允许上车了,你可能要直接打车到目的地,或者干脆放弃。
- 开车过程中需要处理的事情都以司机手表的事件为准,比如中途要休息等。
- 应该10分到的人提前到5分到了,司机手表的时间依然为5-2=3,不会因为有人提前到了就调整手表时间。
来自网上解释: 水位线在事件时间的世界里面,承担了时钟的角色。也就是说在事件时间的流中,水位线是唯一的时间尺度。如果想要知道现在几点,就要看水位线的大小。后面讲到的窗口的闭合,以及定时器的触发都要通过判断水位线的大小来决定是否触发。
水位线是一种特殊的事件,由程序员通过编程插入的数据流里面,然后跟随数据流向下游流动。 水位线的默认计算公式:水位线 = 观察到的最大事件时间 – 最大延迟时间 – 1 毫秒。
不同的算子看到的水位线的大小可能是不一样的。因为下游的算子可能并未接收到来自上游算子的水位线,导致下游算子的时钟要落后于上游算子的时钟。在编写 Flink 程序时,一定要谨慎的编写每一个算子的计算逻辑,尽量避免大量计算或者是大量的 IO 操作,这样才不会阻塞水位线的向下传递。
在数据流开始之前,Flink 会插入一个大小是负无穷大(在 Java 中是-Long.MAX_VALUE)的水位线,而在数据流结束时,Flink 会插入一个正无穷大(Long.MAX_VALUE)的水位线,保证所有的窗口闭合以及所有的定时器都被触发。
状态管理
env.setStateBackend(new FsStateBackend("checkpointUri"));env.setStateBackend(new RocksDBStateBackend("checkpointUri"));
算子状态 Operator State
public static class MyCountMapperimplements MapFunction<Object,Integer>,ListCheckPointed<Integer>{private Integer count = 0;......}
注意,在普通操作基础之上,实现CheckPointed接口。
- 算子状态对同一子任务而言是共享的
- 算子状态不能由同一算子的不同子任务访问
- 算子状态不能由不同算子的任一个子任务访问
- 算子状态三种数据结构
- 列表状态:恢复时各自加载各自的状态
- 联合列表状态:恢复时每个任务都加载所有的状态,不常使用
- 广播状态:适合于每个子任务的状态相同
键控状态 Keyed State
public static class MyKeyCountMapperimplements RichMapFunction<Object,Integer>{private ValueState<Integer> keyCountState;@Overwritepublic void Open(Configuration parameters) throws Exception{//声明一个键控状态keyCountState = getRuntimeContext().getState(new ValueStatDescirptor<Integer>("keyCount", Integer.class));}@Overwritepublic Integer map(Object value) throws Exception{Integer count = keyCountState.value();count++;keyCountsState.update(count);return count;}}
容错机制
checkpoint、savepoint
- Chandy-Lamport分布式快照算法
- 将检查点的保存与数据处理分离开,不需要暂停整个应用
检查点分界线(Checkpoint Barrier)
- barrier以广播方式向下游传递
- 分界线对齐:下游会等待所有分区的分界线到期后才进行checkpoint
env.enableCheckpointing(300, CheckpointingMode.EXACTLY_ONCE|AT_LEAST_ONCE)
- env.getCheckpointConfig.setCheckpointXXX(X)
重启策略
env.setRestartStrategy(strategy);
- RestartStrategies.fixedDelayRestart();//固定延时重启
- RestartStrategies.FailureRateRestart();//失败率重启:指定时间内失败达到多少次进行重启,重启有间隔
状态一致性分类
- at-most-once
- at-least-once
- exactly-once
checkpoint来保证exactly-once
端到端(END-TO-END)状态一致性
- 除了通过flink内部的checkpoint机制保证状态的一致性,还需要贯穿的每个组件都能够保证
- 特别是两端的组件
- source端—可重设数据的读取位置
- 内部保证—checkpoint机制
- sink端—幂等写入+事务写入
- 事务实现方式
- 预写日志(Write-Ahead-Log,WAL)—GenericAheadSink接口
- 把数据结果当成状态保存,收到checkpoint完成通知时,一次性写入sink
- 不能完全保证
- 两阶段提交(2-Phase-Commit,2PC)—TwoPhaseCommitSinkFunction接口
- 每个checkpoint,sink会启动一个事务
- 真正实现exacktly-once
- FlinkKafkaProducer011继承TwoPhaseCommitSinkFunction
- 预写日志(Write-Ahead-Log,WAL)—GenericAheadSink接口

- 注意checkpoint超时时间与事务超时时间要一致 ,否则可能事务超时了但是checkpoint还没有超时
- 注意设置下游kafka的隔离级别,避免下游多次读取数据
Table API and Flink SQL
EvironmentSettings oldEnvSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode() //inStreamingMode流处理 inBatchMode批处理.build();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, oldEnvSettings);//对应批处理为BatchTableEnvironmentTable dataTable = tableEnv.fromDataStream(dataStream);dataTable.select("id").where(...);tableEnv.createTemporaryView("sensor",dataTable);Table rstTable = tableEnv.sqlQuery("select id from sensor where id='001'");tableEnv.toAppendStream(rstTable,Row.class).print("result");//转换为stream进行打印结果//有聚合函数时需要调用这个函数,会输出记录是否更行tableEnv.toRetractStream(tablex,Row.class).print("tablex");//env.execute();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);tableEnv.connect(...).createTemporary("inputTable");Table result = tableEnv.from("inputTable").select(...);tableEnv.connect(...).createTemporary("outputTable");result.insertInto("outputTable");
//流处理EnvironmentSettings blinkStreamSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamMode().build();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,blinkStreamSetting);//批处理EnvironmentSettings blinkBatchSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();TableEnvironment tableEnv = TableEnvironment.create(blinkBatchSetting);
tableEnv.connect(new FileSystem().path(filePath)).withFormat(new Csv()).withSchema(new Shema().field(x,x).field(y,y))).createTemporaryTable("table1");tableEnv.connect(new Kafka().version(0.11).topic("x").property(k,v)).withFormat(new Csv()).withSchema(new Shema().field(x,x).field(y,y))).createTemporaryTable("table1");
sink更新模式
- 追加Append模式
- 撤回Retract模式
- 更新插入Upsert模式
用户自定义函数
- udf
```java
public static class MyUdf extends ScalarFunction{
private int factor = 13;//也可以是其他类型
public int MyUdf(int factor){
} public int evel(String s){//返回值也可以是其他类型this.factor = factor;
} }return s.hashCode() * factor;
tableEnv.registerFunction(“my_udf”, new MyUdf(13)); //后续sql中可以使用 my_udf(str)
```java
//其中Tuple2<String,Integer>为返回值类型
public static class MyUdf extends TableFunction<Tuple2<String,Integer>>{
private int factor = 13;//也可以是其他类型
public int MyUdf(int factor){
this.factor = factor;
}
public void evel(String str){
for(String s:str.split(",")){
collect(new Tuple2<String,Integer>(s,s.length()));
}
}
}
tableEnv.registerFunction("my_udf", new MyUdf());
//table API 调用
Table resultTable = sensorTable
.joinLateral("my_udf(id) as (word,length)") //扩展字段的写法(侧写表)
.select(id,ts,word,length);
//SQL 用法
tableEnv.sqlQuery("select id,ts,word,length "+
"from sensor, lateral table(my_udf(id)) as split(word,length)")
- udaf
-
开窗函数
分组窗口 Group Windows
- 根据时间或行数间隔分组,对每个组执行一次聚合函数 ```java Table dataTable = tableEnv.createTemporaryView(“sensor”, dataStream);
//Table API 方式访问: rt为事件时间列名,tw为时间窗口别名 dataTable.window(Tumble.over(“10.seconds”).on(“rt”).as(“tw”)) .groupBy(“id, tw”) .select(“id,id.count,temp.avg,tw.end”); //id.count 相当于count(id) //temp.avg 想点关于avg(temp) //tw.end 窗口结束时间
// Flink SQL 方式 tableEnv.sqlQuery(“select id,count(id) as cnt,avg(tmp) as avgTmp,tumble(rt,interval ‘10’ second)” +” from sensor group by id,tumble(rt,interval ‘10’ second)”); //tumple(rt,interval ‘10’ second) 10秒滚动开窗 //hop(rt,interval ‘10’ second) 10秒滑动开窗 //tumple_start(…) tumple_end(…) hop_start(…) hop_end(..) 滚动、滑动窗口开始、结束时间
- Over Windows
- 对每个输入行,计算相邻行范围内的聚合
```java
Table dataTable = tableEnv.createTemporaryView("sensor", dataStream);
//Table API 方式访问: rt为事件时间列名,w.rows为每两行执行一次
dataTable.window(Over.partitionBy("id").orderBy("rt").proceding("2.rows").as("ow"))
.select("id, id.count over ow, temp.avg over ow");
// Flink SQL 方式
tableEnv.sqlQuery("select id,count(id) over ow,avg(temp) over ow "
+"from sensor"
+"window ow as (partition by id order by rt between 2 preceding and current row)");
按id分区,然后对之前的所有记录按事件时间进行排序(时间窗口)
.window(Over.partitionBy(“id”)orderBy(“rowtime”).proceding(UNBOUNDED_RANGE).as(“w”))
按id分区,然后对之前的所有记录按处理时间进行排序(时间窗口hi)
.window(Over.partitionBy(“id”)orderBy(“processtime”).proceding(UNBOUNDED_RANGE).as(“w”))
按id分区,然后对之前的所有记录按事件时间进行排序(计数窗口)
.window(Over.partitionBy(“id”)orderBy(“rowtime”).proceding(UNBOUNDED_ROW).as(“w”))
按id分区,然后对之前的所有记录按处理时间进行排序(计数窗口)
.window(Over.partitionBy(“id”)orderBy(“processtime”).proceding(UNBOUNDED_ROW).as(“w”))
依赖jar包
- flink-connector-kafka_0.11_2.12
- env.addSource(new FlinkKafkaConsumer011())
- env.addSink(new FlinkKafkaProducer011())
- flink-connector-redis_2.11 (bahir)
- flink-connector-elasticsearch6_2.12
- flink-statebackend-rocksdb_2.12
- flink-table-planner_2.12
- flink-table-planner-blink_2.12 推荐
- flink-csv tableEnv.connect().withFormat(csv()) 中使用

若有收获,就点个赞吧
0 人点赞
