收集标注资料很困难,人类也不知道正确答案是什么 —> 强化学习(RL)
1、什么是强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
Step 1. Function with unknown(有未知数的函数)
输入:机器观察到的结果—>向量/矩阵。
输出:不同的行为及分数。
Network的参数:unknown,要被学习出来。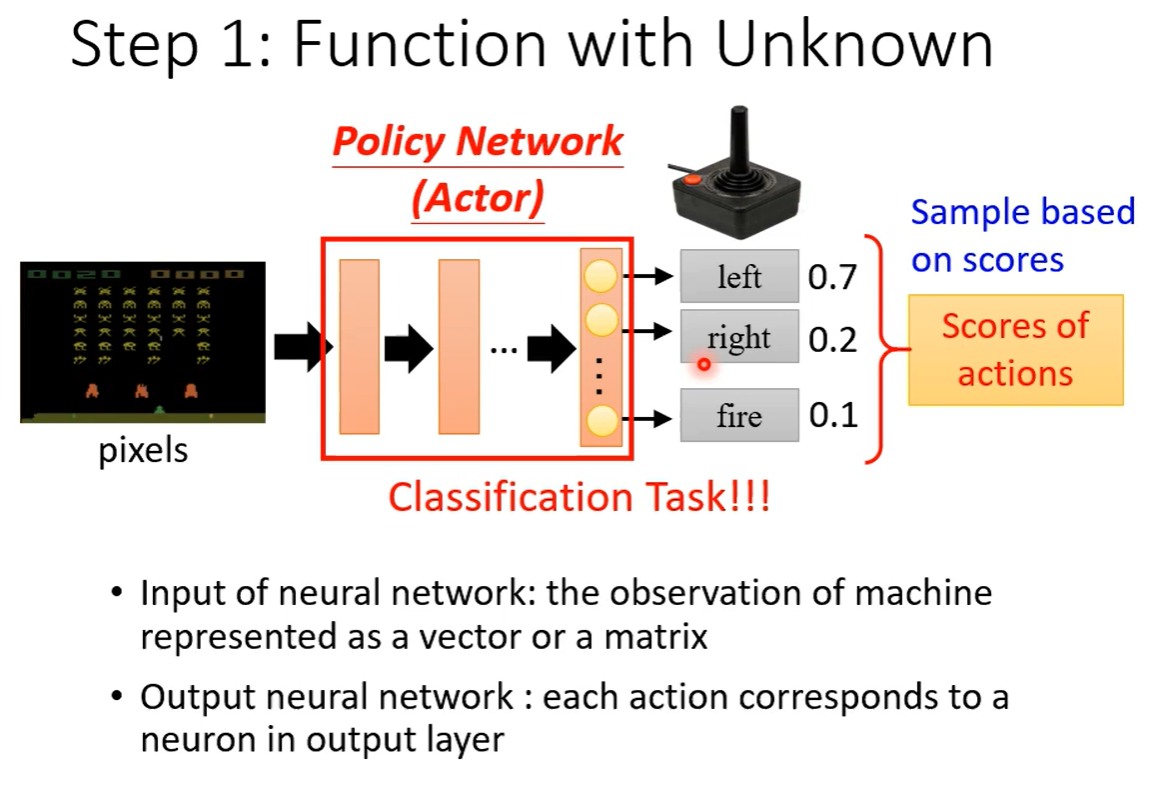
Step 2. Define “Loss”(定义损失函数)
将 total reward 的相反数当做 Loss 函数,
Step 3. Optimization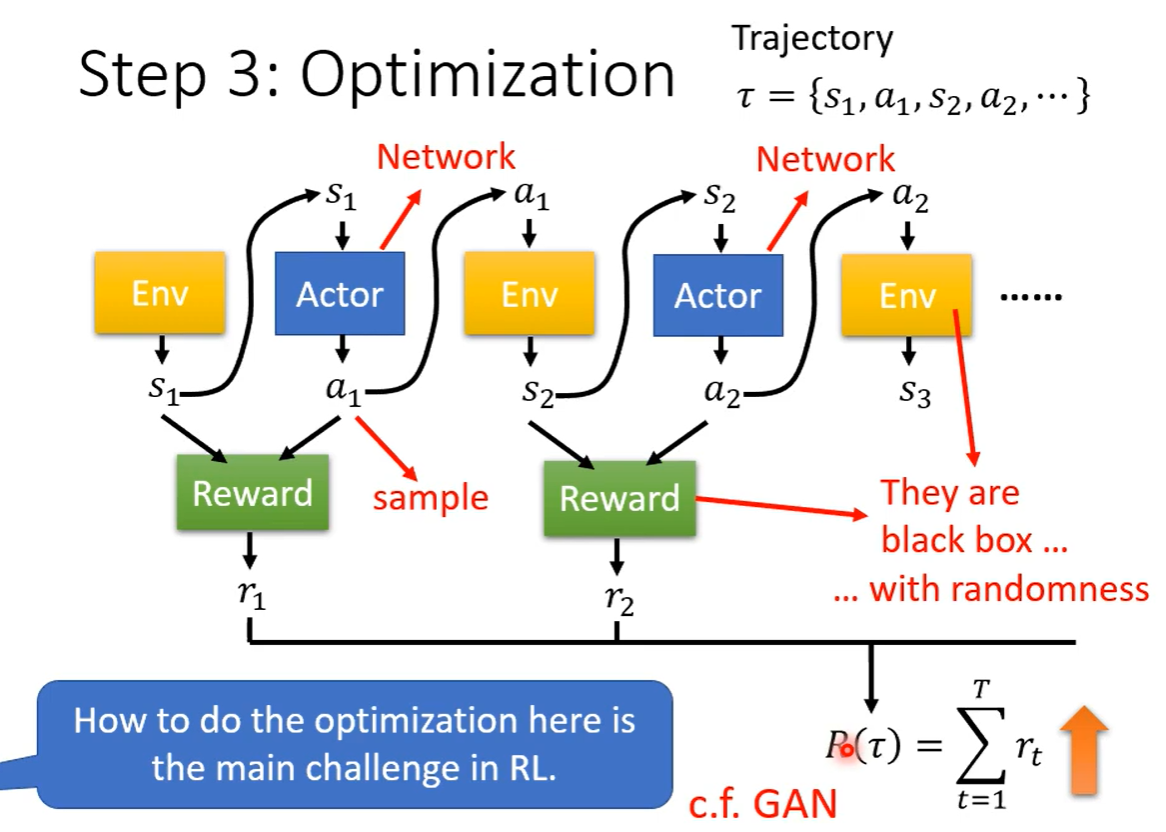
2、Policy Gradient算法
问题:如何控制actor?对某一输入,和希望完成的动作打高分,对不希望进行的行为打低分。
关键:如何定义A,如何获取 {输入,动作} 的组对。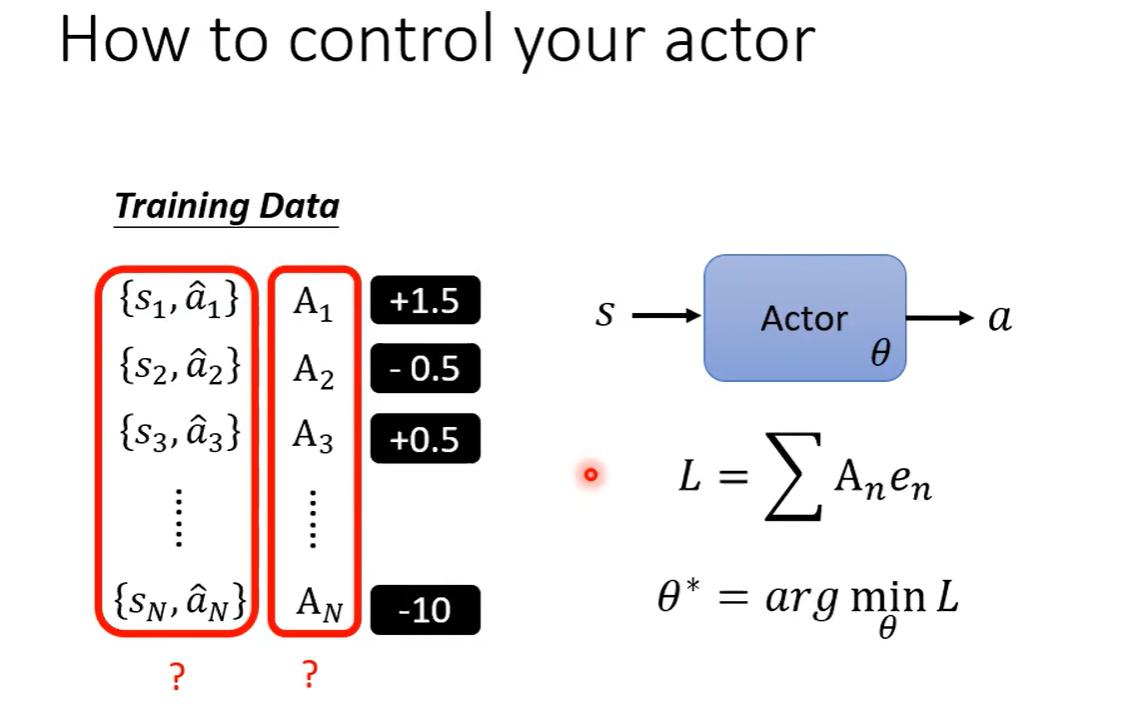
Version 0:
方法:对每种情形下,{输入,动作} 进行打分,然后训练Actor。
问题:1)每个时刻的行为会影响后续行为的奖励与否;
2)Reward delay:希望Actor能牺牲即时的奖励,换取更长远的奖励;
e.g.在太空入侵游戏中,如果不采用Reward delay,那么Actor采取的行为总是射击,因为射击才能获取分数,而不会选择左右移动,尽管移动后射击会获得更多的分数。
Version 1:
方法:对某一时刻的行为,用执行完该行为之后的reward加起来,来评估当前行为的好坏。
问题:后续行为的好坏不一定归功于当前行为。
Version 2:
方法:乘上权重,距离当前时刻越近的后续时刻乘的越多,越远乘的越少。越早的动作会累积更多的分数,越晚的动作累积的分数越少。
问题:“好”与“坏”是相对的,A需要标准化。
Version 3:
方法:每个A减去一个b,使得很大的分数仍然是正的,很小的分数则为负的。
训练过程中,每更新一次参数,就要重新收集资料。例如:用 收集了一笔资料,训练完后更新到
收集了一笔资料,训练完后更新到 ,继续训练则需要重新收集资料。
,继续训练则需要重新收集资料。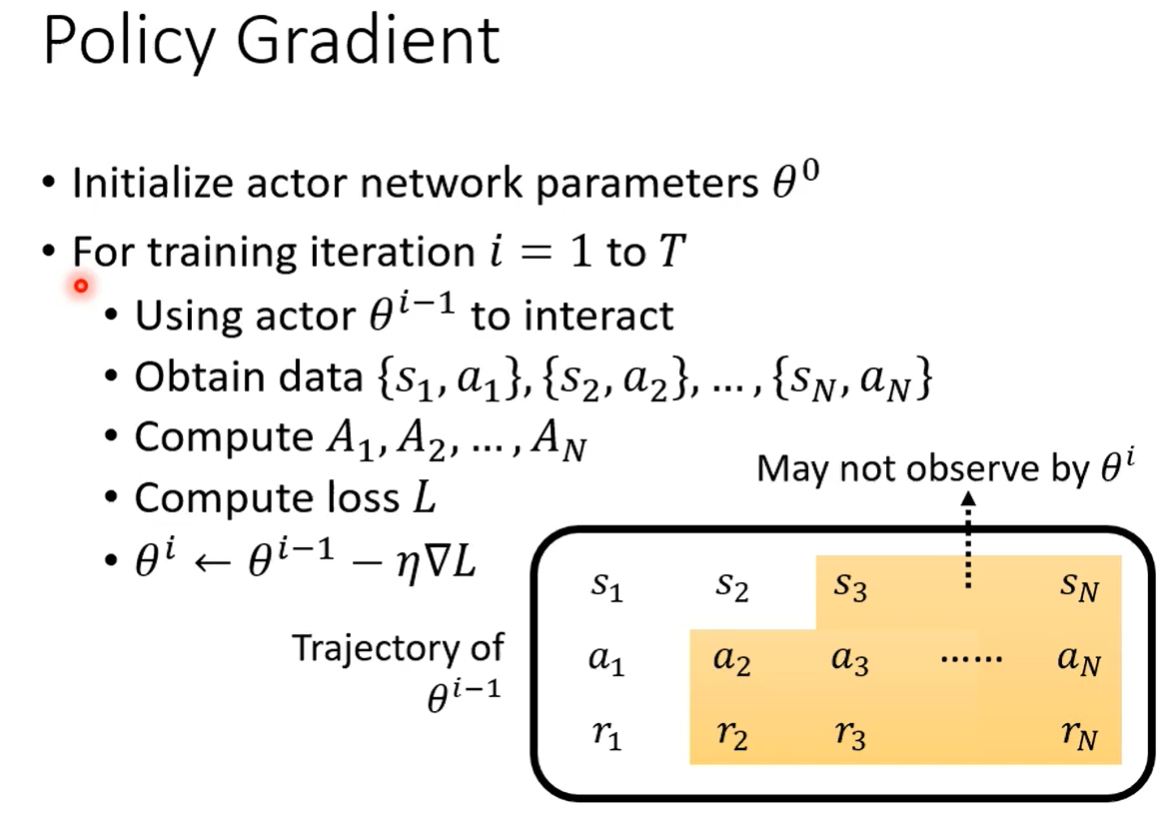
Exploration:Actor的需要很大的随机性,从而覆盖到所有可能的行为。
3、Actor-Critic算法
Critic:评估Actor的好坏
Value function  :当使用一个actor θ时,给出一个场景s,该函数能预测最终的打分(即
:当使用一个actor θ时,给出一个场景s,该函数能预测最终的打分(即 ,未卜先知),该函数返回值与actor(好坏)有关。
,未卜先知),该函数返回值与actor(好坏)有关。
Monte-Carlo(MC):看到一个场景,使V的函数值越接近最终的打分越好。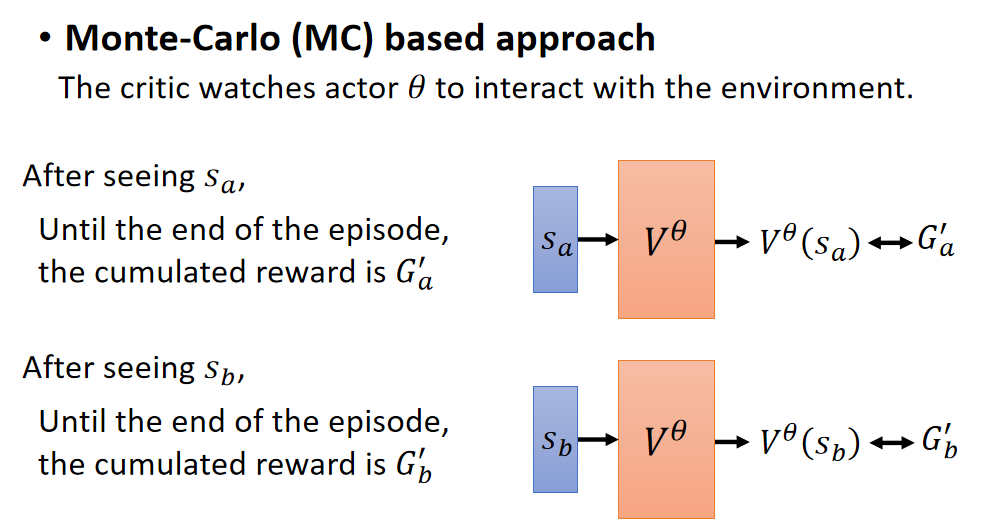
Temporal-difference(TD):利用当前时刻的场景、actor、当前打分以及下一个场景来预测V值。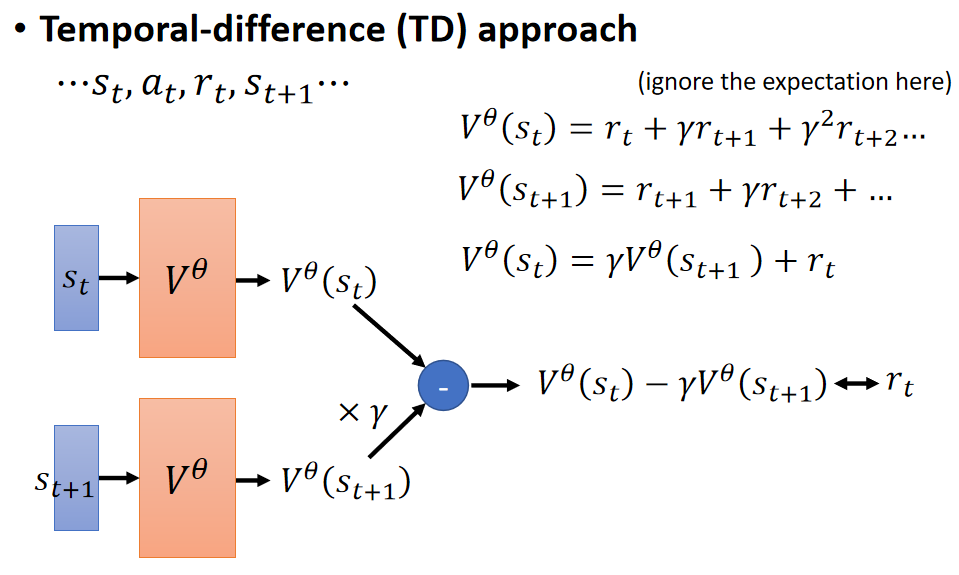
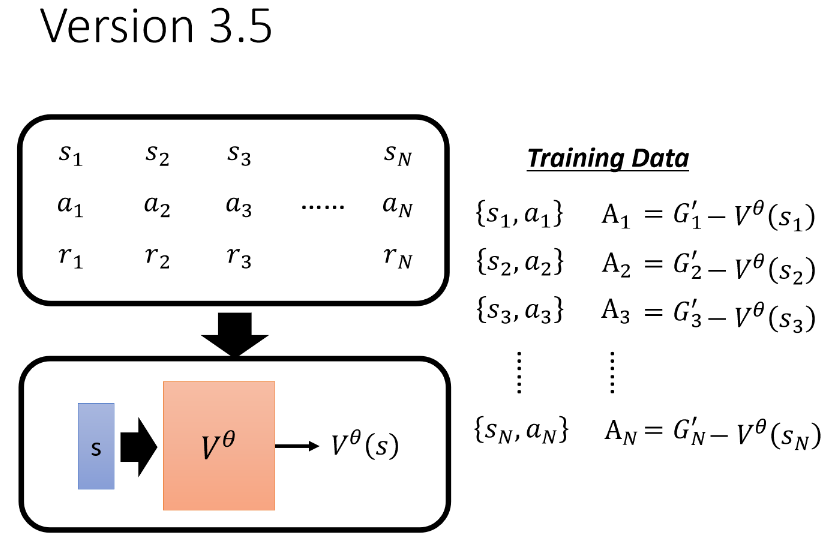
Version 3.5:
b=
Version 4:
方法:采取 得到的V平均值加上
得到的V平均值加上 ,再和随便simple的一个操作得出的V平均值相减。
,再和随便simple的一个操作得出的V平均值相减。
Advantage Actor-Critic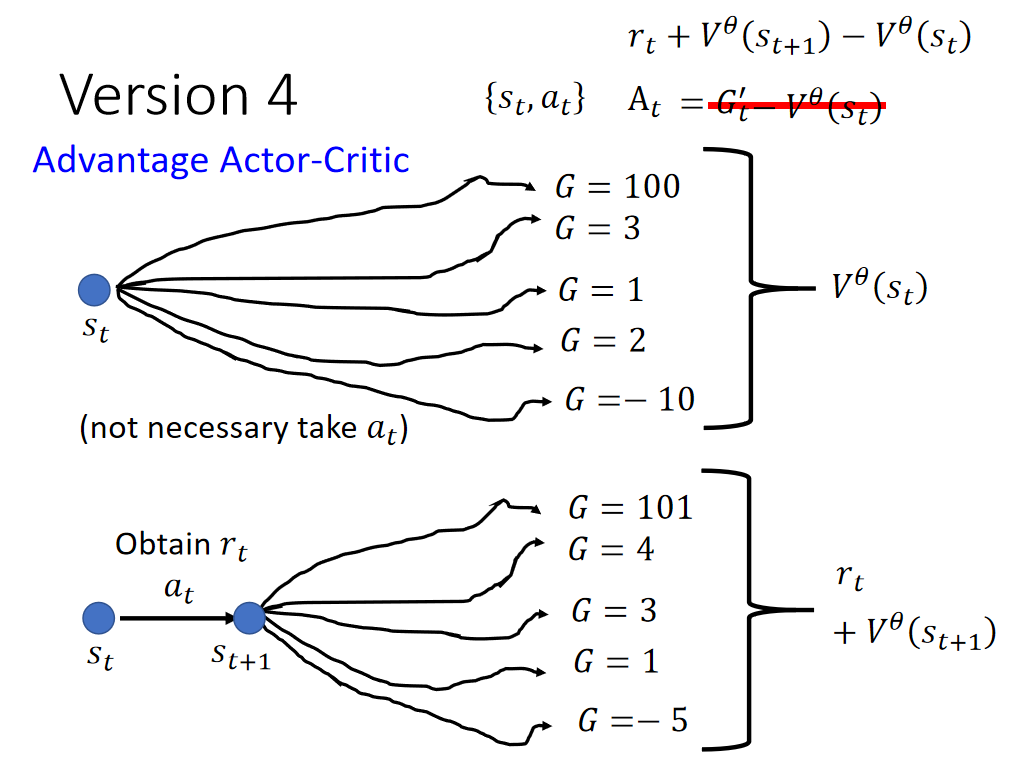
4、Reward Shaping
问题:Sparse Reward —> reward很多是0的情况,很难训练。
解决方法:Reward Shaping —> 定义一些额外的rewards来指导训练。(望梅止渴)
Reward Shaping - Curiosity:过程中只要看到有意义的新事物就加分。
5、No Reward:Learning from Demonstration(模仿学习)
问题:reward定义困难
解决方法:Imitation Learning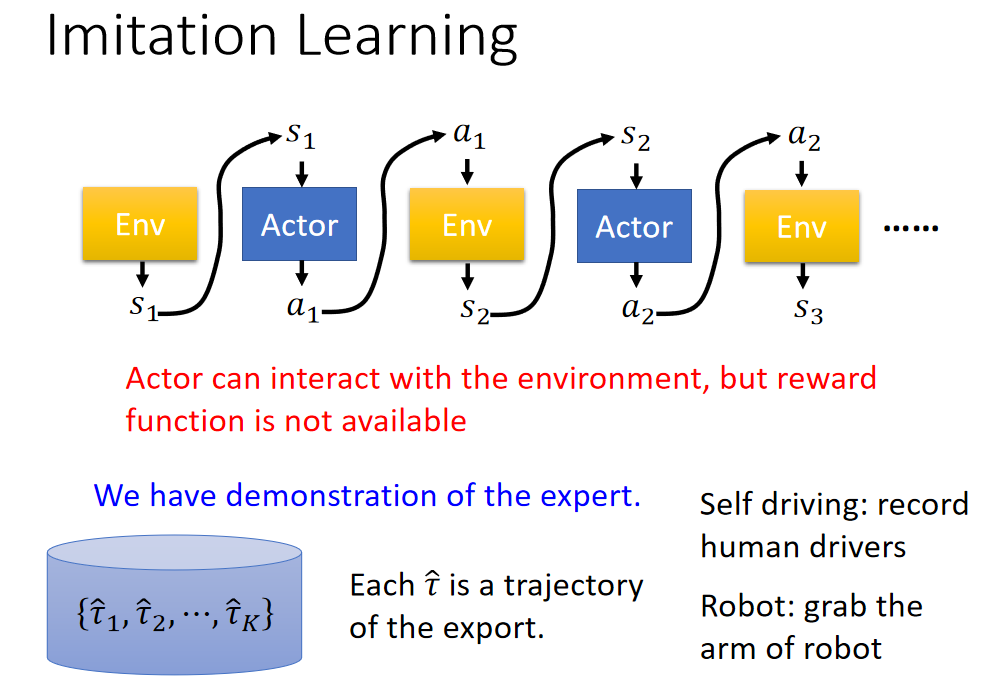
e.g.人类驾驶车辆的记录,就是机器的expert
问题:机器完全模仿人类行为,不知道什么行为需要学习,什么行为不需要学习。
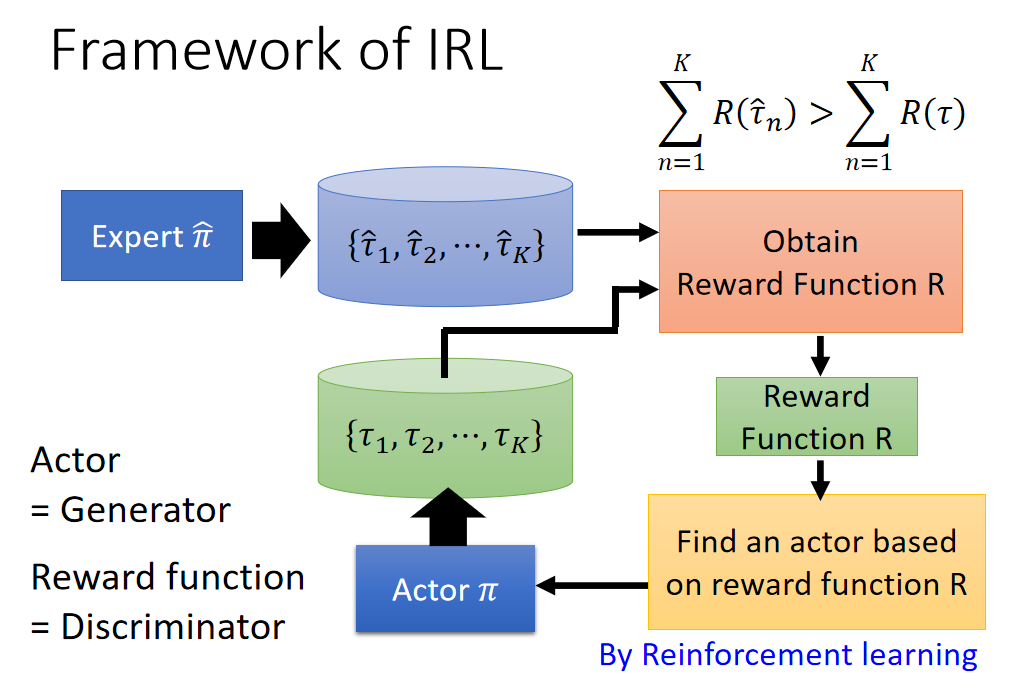
Inverse Reinforcement Learning:机器自己定义reward,reward function是学出来的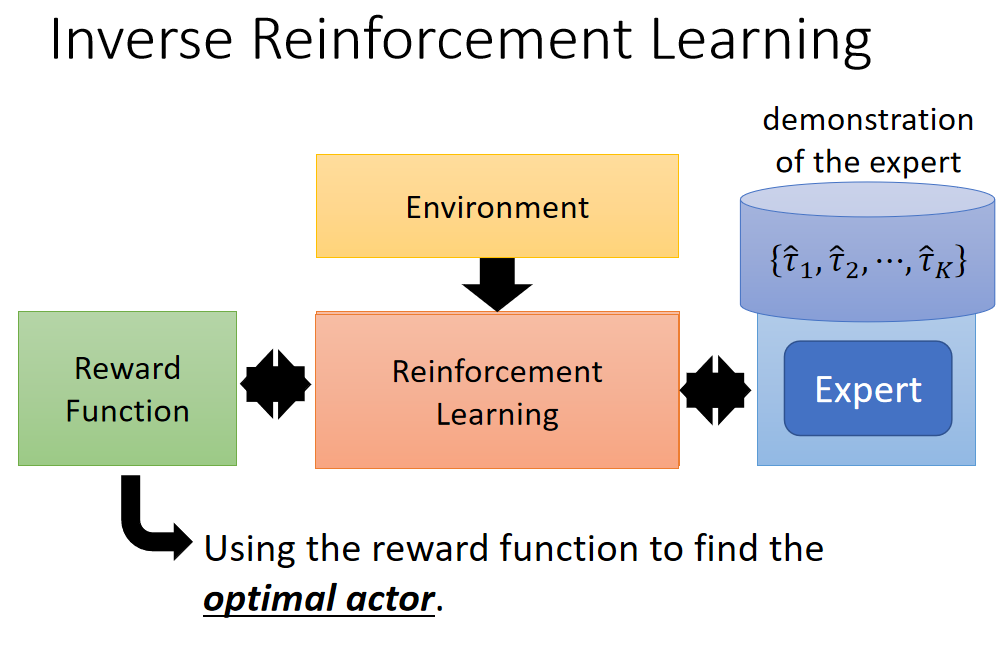
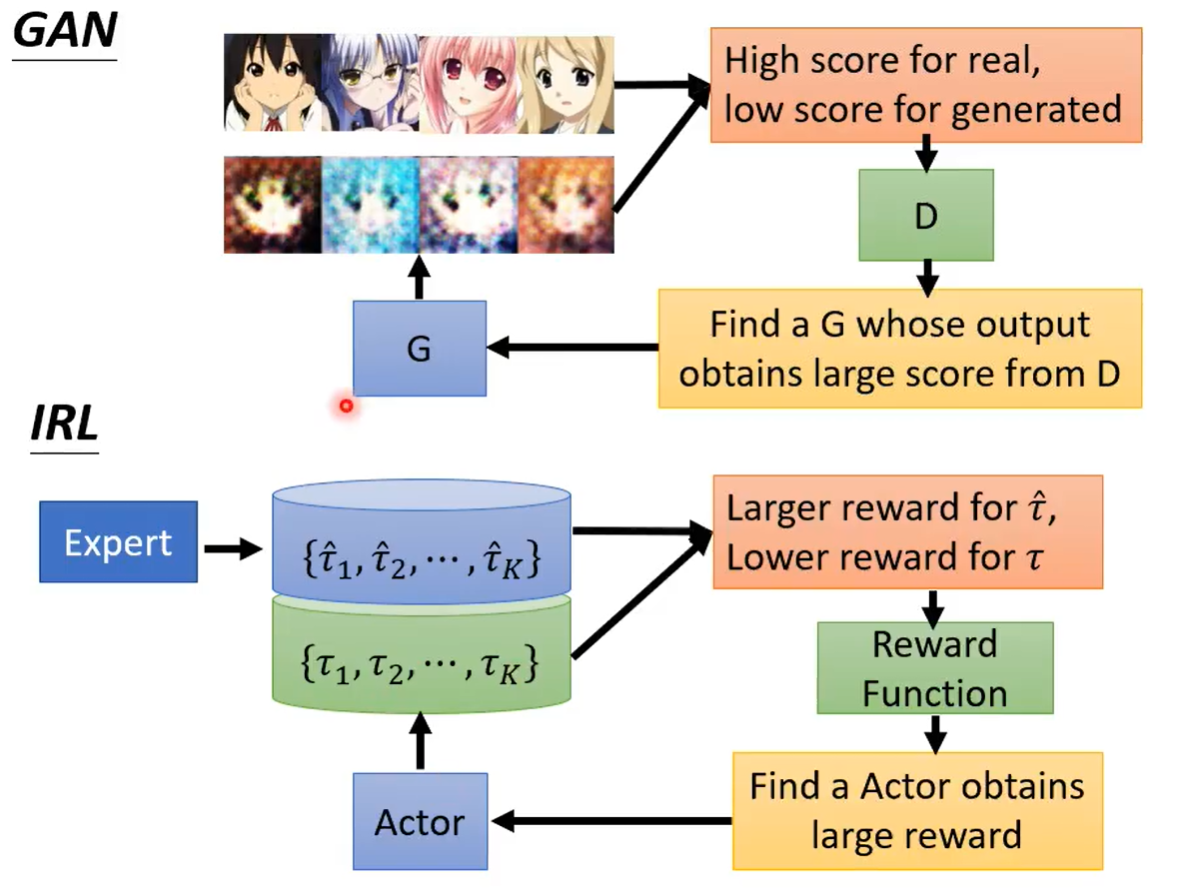

若有收获,就点个赞吧
0 人点赞
