1、Sequence-to-sequence(seq2seq)
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
2、Encoder:
通俗表达:给一排向量,输出另外一排向量。
有多个block,每个block又包含不同的layer(Self-attention + Fully connected),每个block的子层之间均采用残差连接,过程如下图。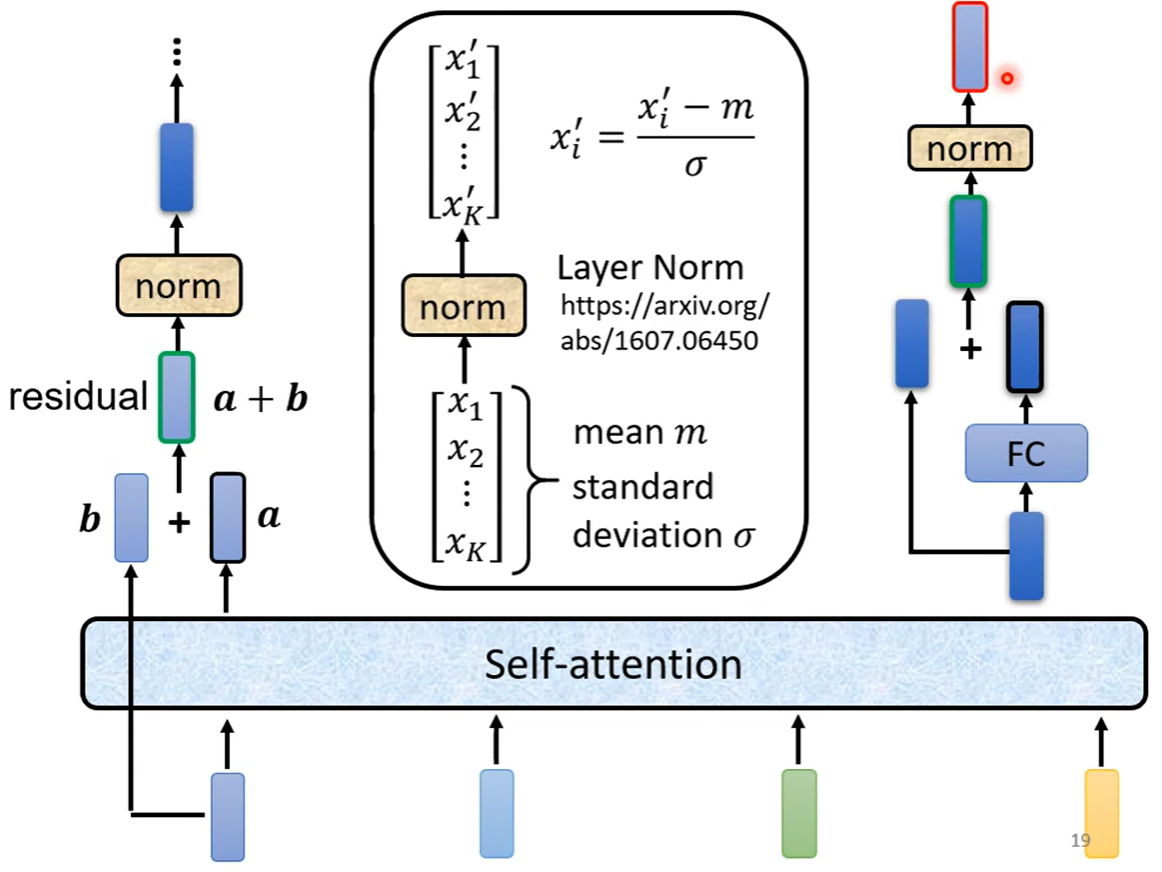
残差连接之后进行normalization,采用Layer norm(不用考虑batch)
Add & Norm -> Residual + Layer norm
3、Decoder:
Decoder会把自己的输出当做接下来的输入,因此可能看到错误的输入。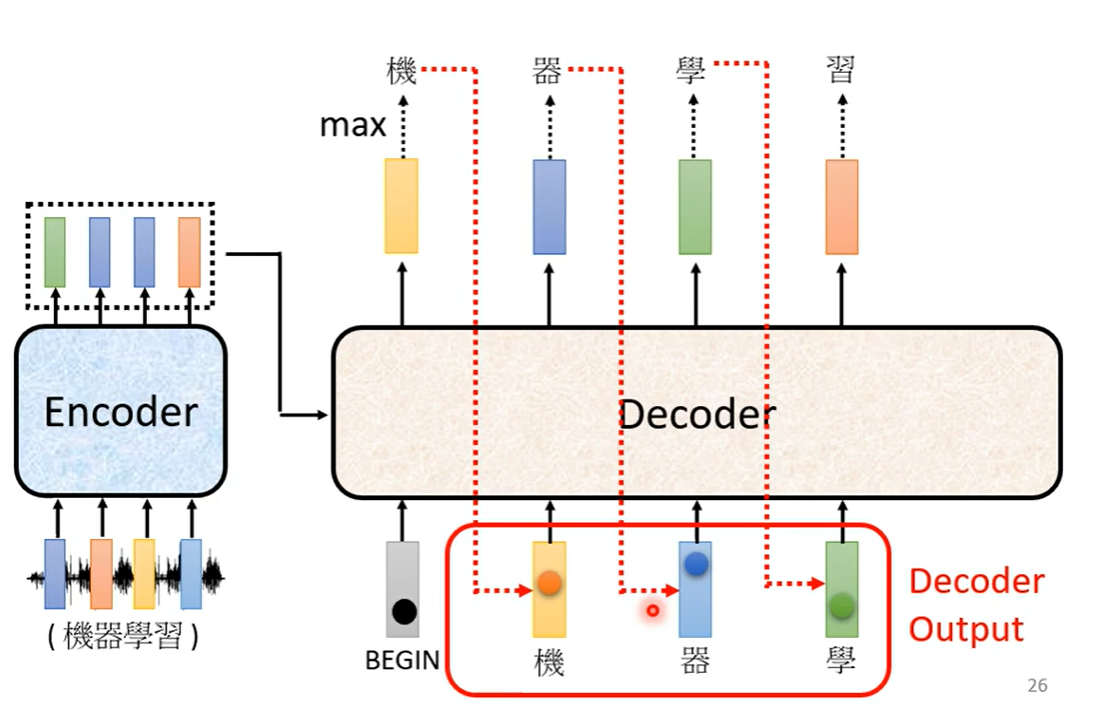
Decoder中的Masked Multi-Head Attention和Encoder中的Multi-Head Attention区别:
Encoder中Self-attention产生每一个输出都能使用所有输入的信息。
Decoder中Masked Self-attention产生每一个输出不能看到右边的信息。例如产生b**3时,只能使用a**1、a**2、a**3的信息,而不能使用a**4的信息。
Masked的原因:因为Decoder每一个位置的输入是采用了上一个位置的输出,即四个位置的输入是按顺序依次出现的,例如计算b**2的时候,a**3和a**4还尚未产生。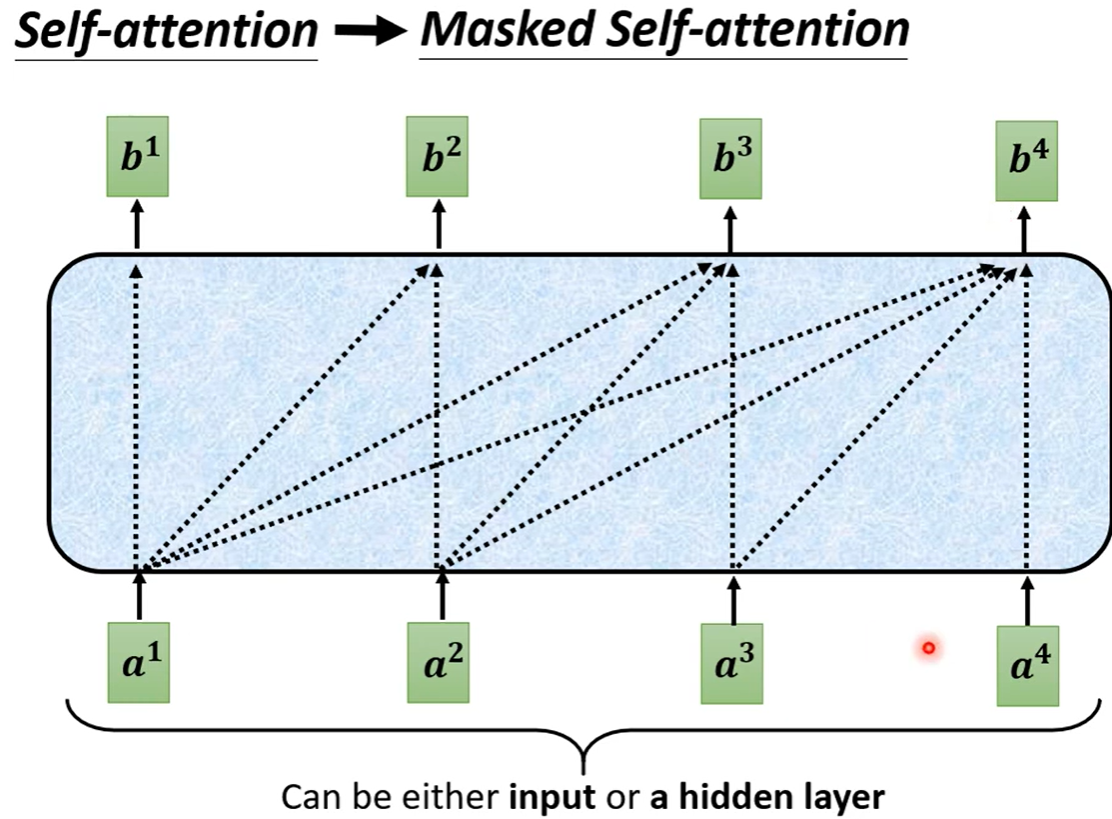
4、Encoder-Decoder
两者之间的信息传递如下图,两个输入来自Encoder,一个输入来自Decoder: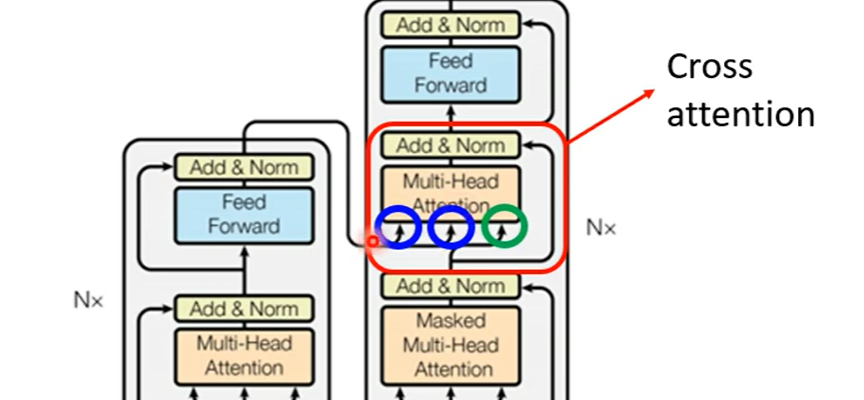
具体过程如下图: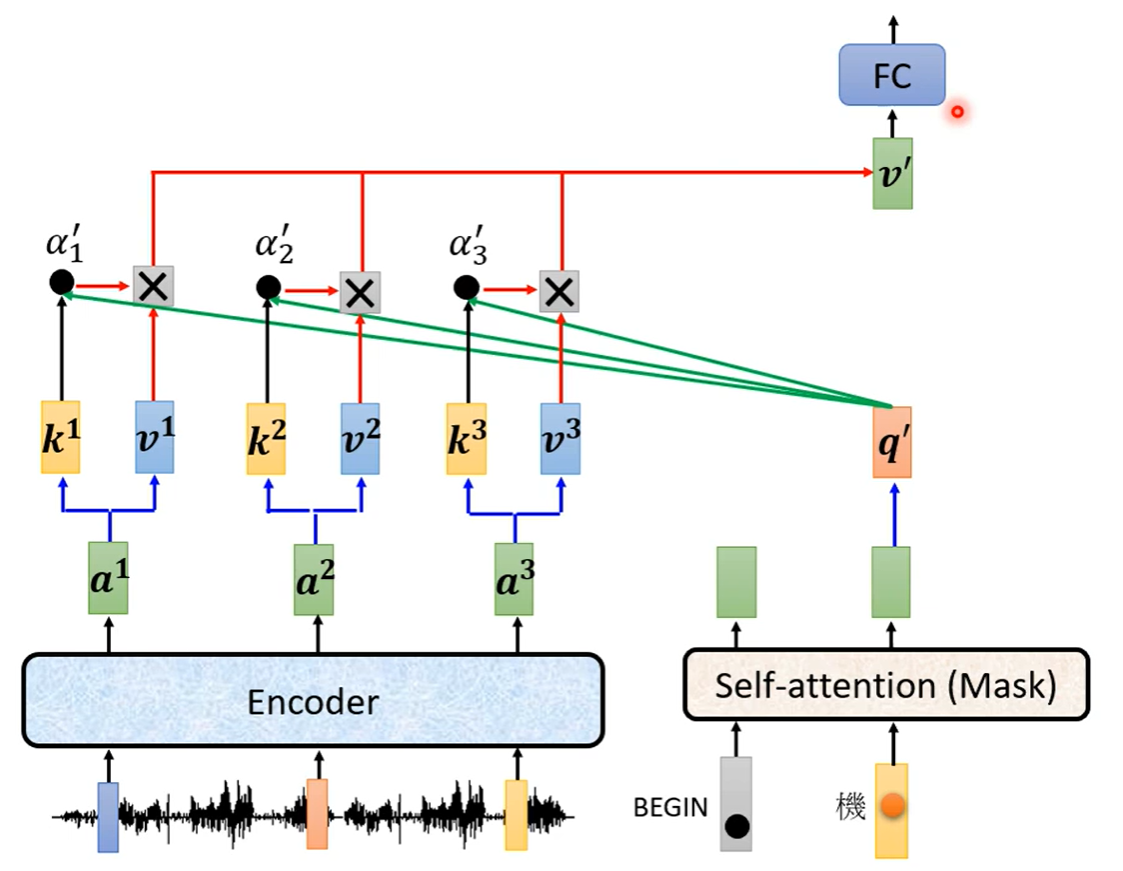

若有收获,就点个赞吧
0 人点赞
