Supervised 和 Self-supervised:
前者有label来监督,后者没有label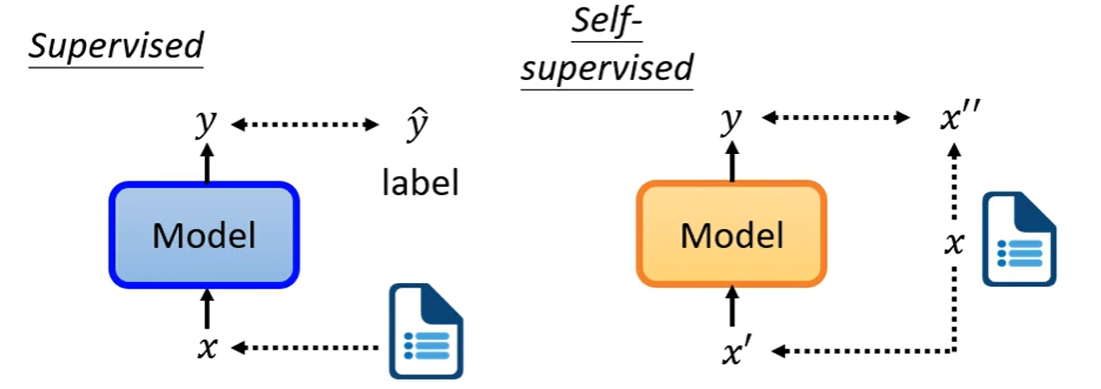
1、BERT模型
BERT 架构和 Transformer 的 Encoder 基本一致,输入一排向量,输出另一排向量。
BERT训练:
1)Masking Input:
随机选取一个向量盖住,用特殊符号表示或随机的字替换。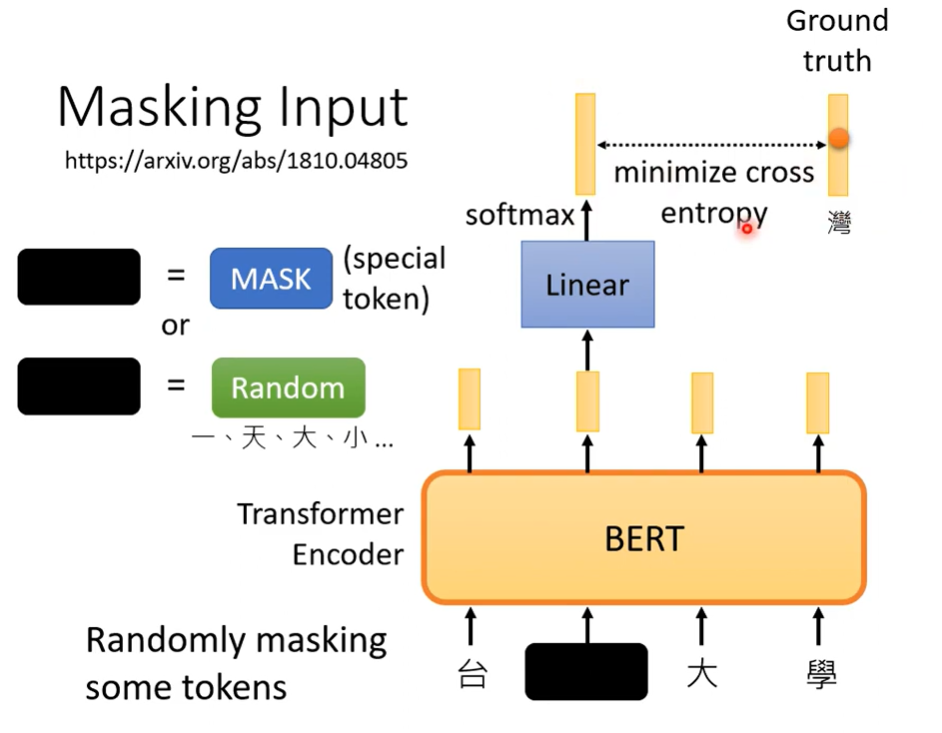
2)Next Sentence Prediction
用分隔符来隔开每一个句子,来判断两个句子是否应该连接在一起的。用处不大。
“BERT用来做填空题”
2、BERT的使用
Case 1 分类
输入一个句子,输出类别(例如情感分类)。
在句首加上token [CLS],需要提供标注资料。
BERT的参数不再是随机初始化,而是采用已学会做“填空题”的BERT。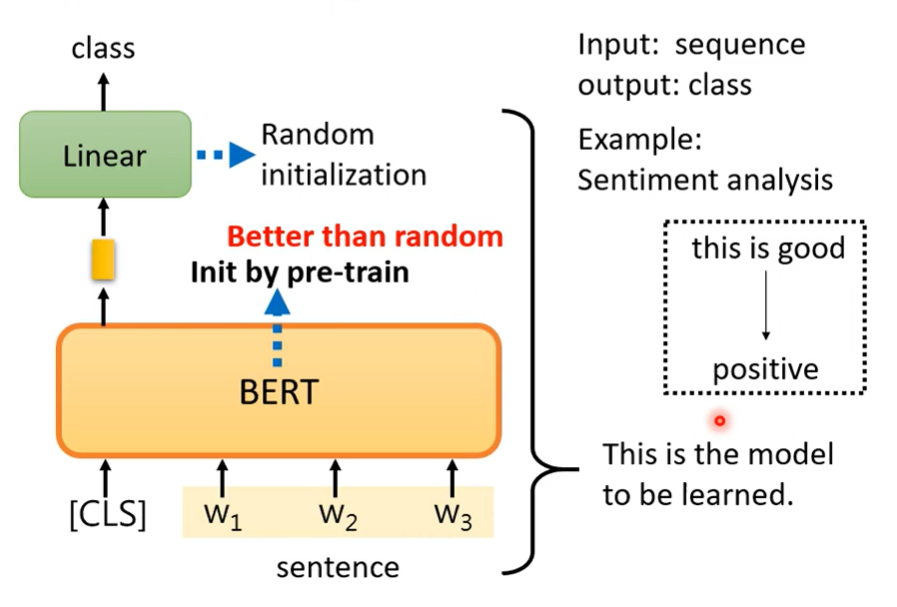
Case 2 句子→句子
输入一个句子,输出一个长度相同的句子。
需要标注资料,BERT的参数不是随机初始化,而是在 pre-train 时找到了一组好的参数。其他和Case相似。
Case 3 两个句子→类别
输入两个句子,给出一个答案。例如输入一篇文章和一条留言,判断是正面留言还是负面留言。
两个句子之间放特殊分隔符号[SEP],最前面放[CLS]。
需要标注资料来训练模型。BERT的参数不是随机初始化,而是在 pre-train 时找到了一组好的参数。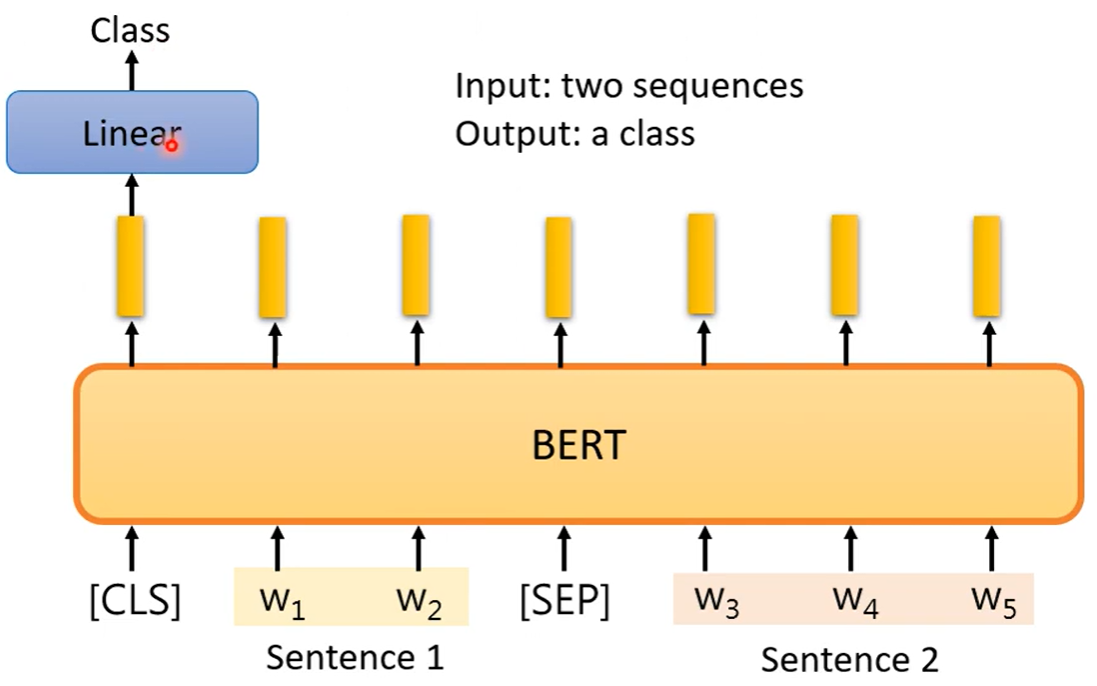
Case 4 问答系统(答案在文章中)
输入问题和文章,用特殊分隔符隔开。
用两个向量去找出正确答案在文章中的起始和结束位置。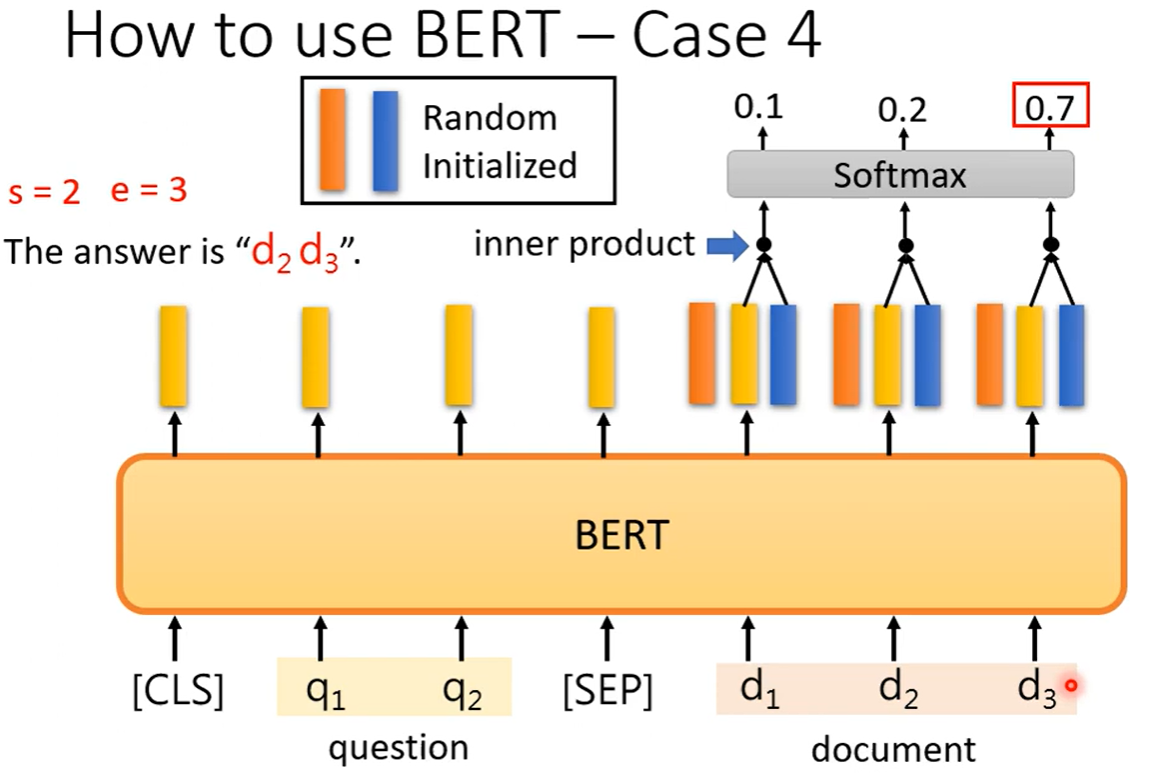
3、Multi-lingual BERT(多语言BERT)
可用不同的语言去训练BERT,让它会“做不同语言的填空题”。
4、GPT series
任务:预测接下来要出现的token。
类似于 Transformer 的 Decoder。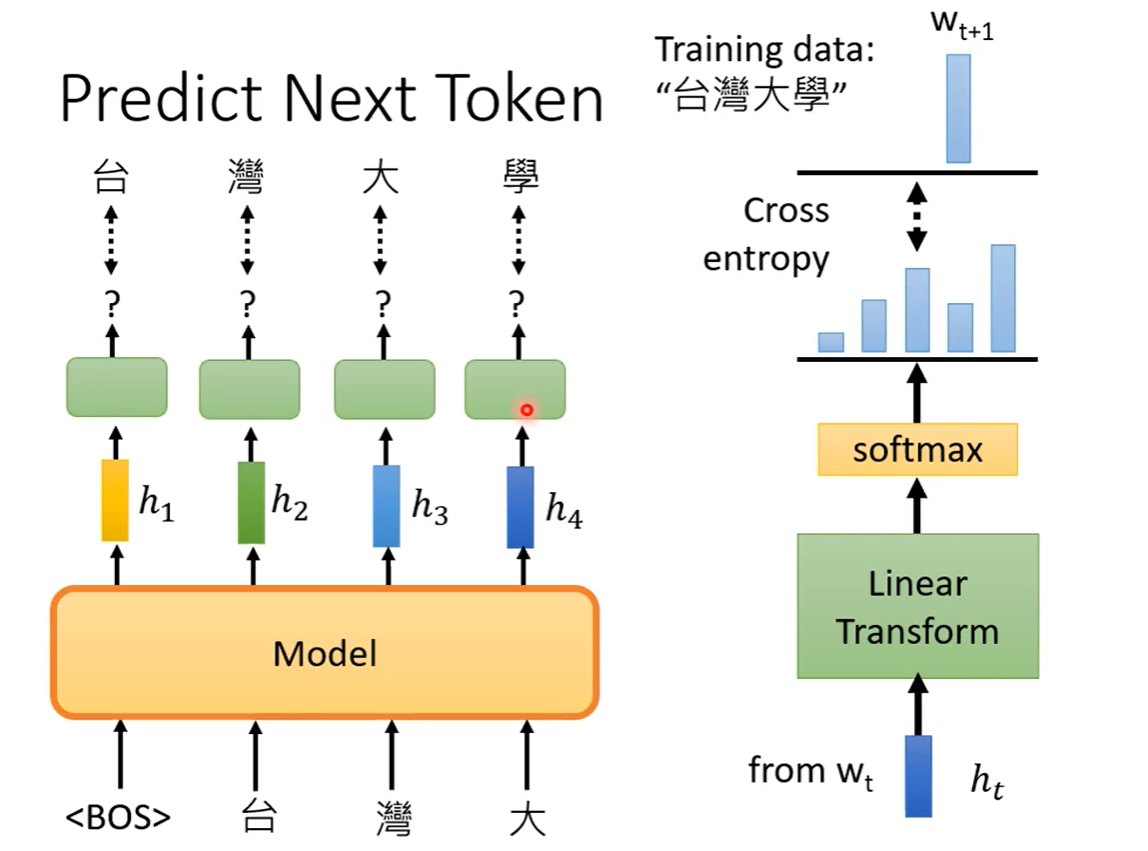

若有收获,就点个赞吧
0 人点赞
