图像识别
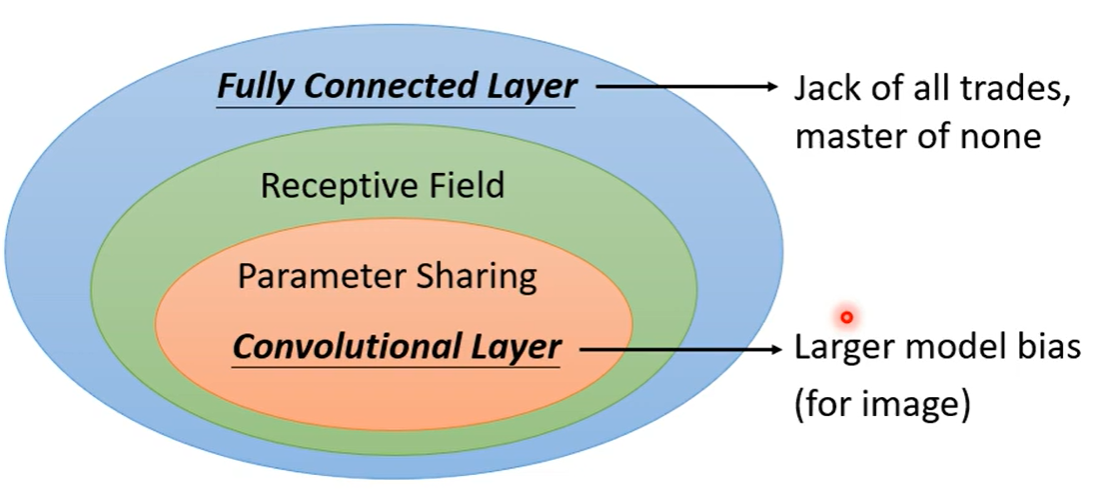
Receptive field:
- 感受野用来表示网络内部的不同神经元对原图像的感受范围的大小,或者说,convNets(cnn)每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
- 神经元之所以无法对原始图像的所有信息进行感知,是因为在这些网络结构中普遍使用卷积层和pooling层,在层与层之间均为局部连接。
- 神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
Filter:
是一个tensor,去图片里抓取对应的形状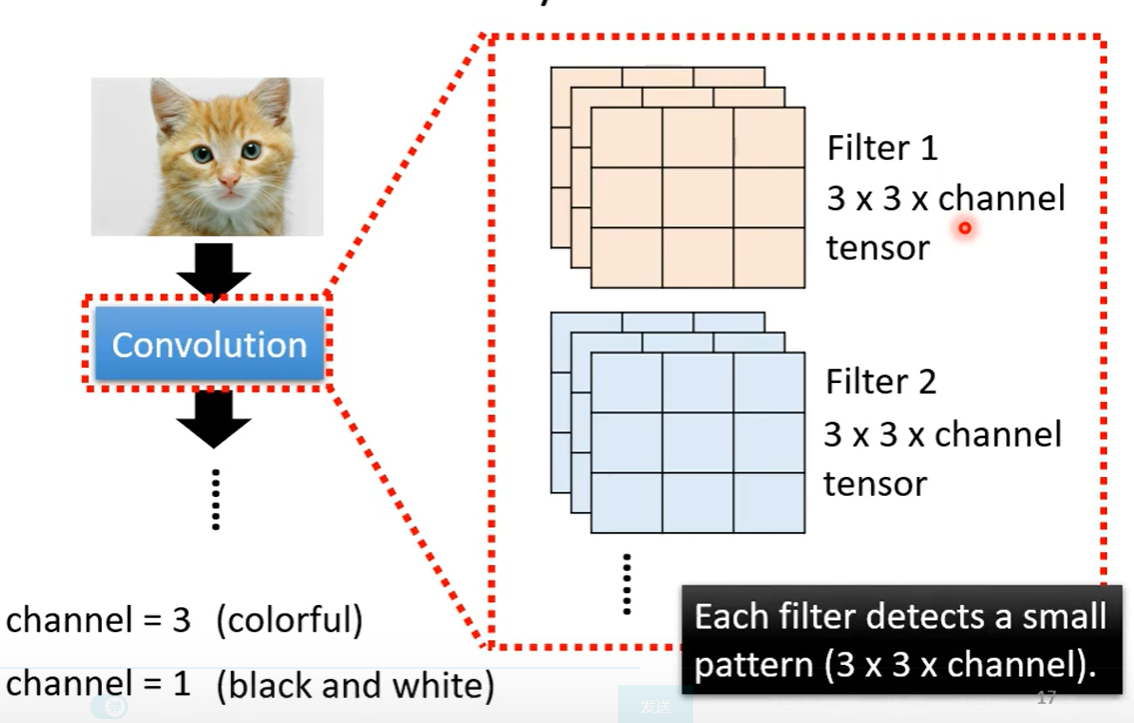
卷积层:
理解1:每个神经元只考虑一个Receptive field;含有不同Receptive field的神经元共享参数(即权重)。
理解2:每层有一个filter的集合,用来小范围侦测目标;每个filter扫过整张图片。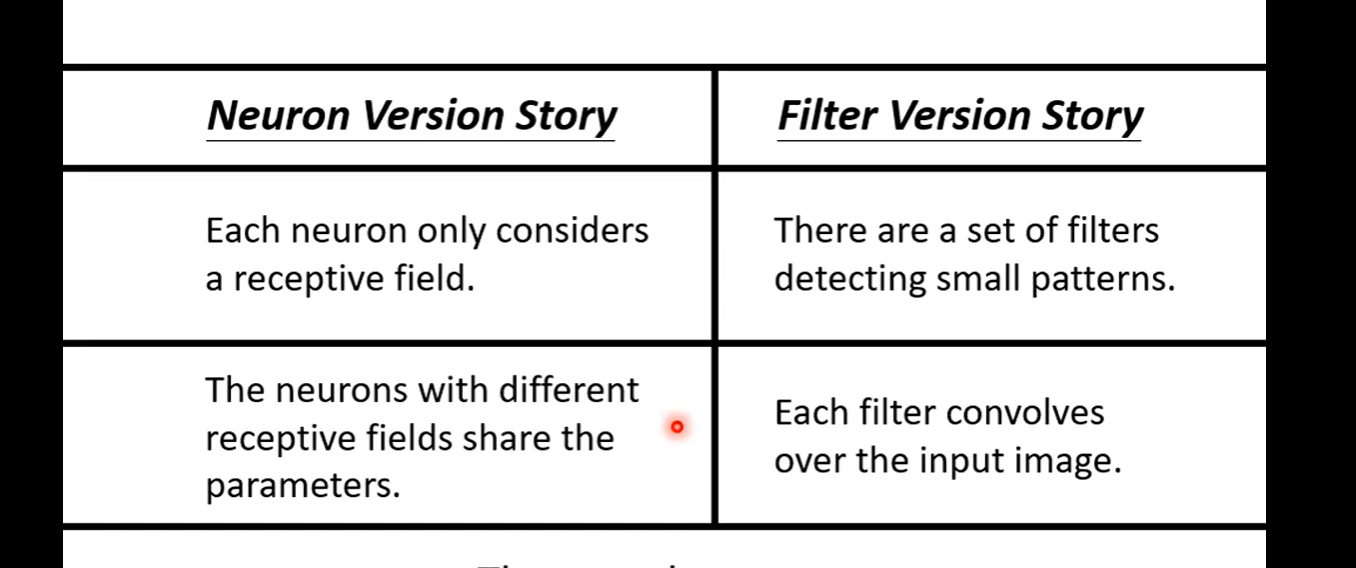
Pooling:
卷积之后的步骤,把图片缩放。目的:把影像变少,减少运算量。
方法:把filter所得的结果分成若干个mn的一组,每一组选出一个最大值(Max pooling),即完成了图片的缩放。
*注:Pooling不一定适合所有任务(例如:下围棋)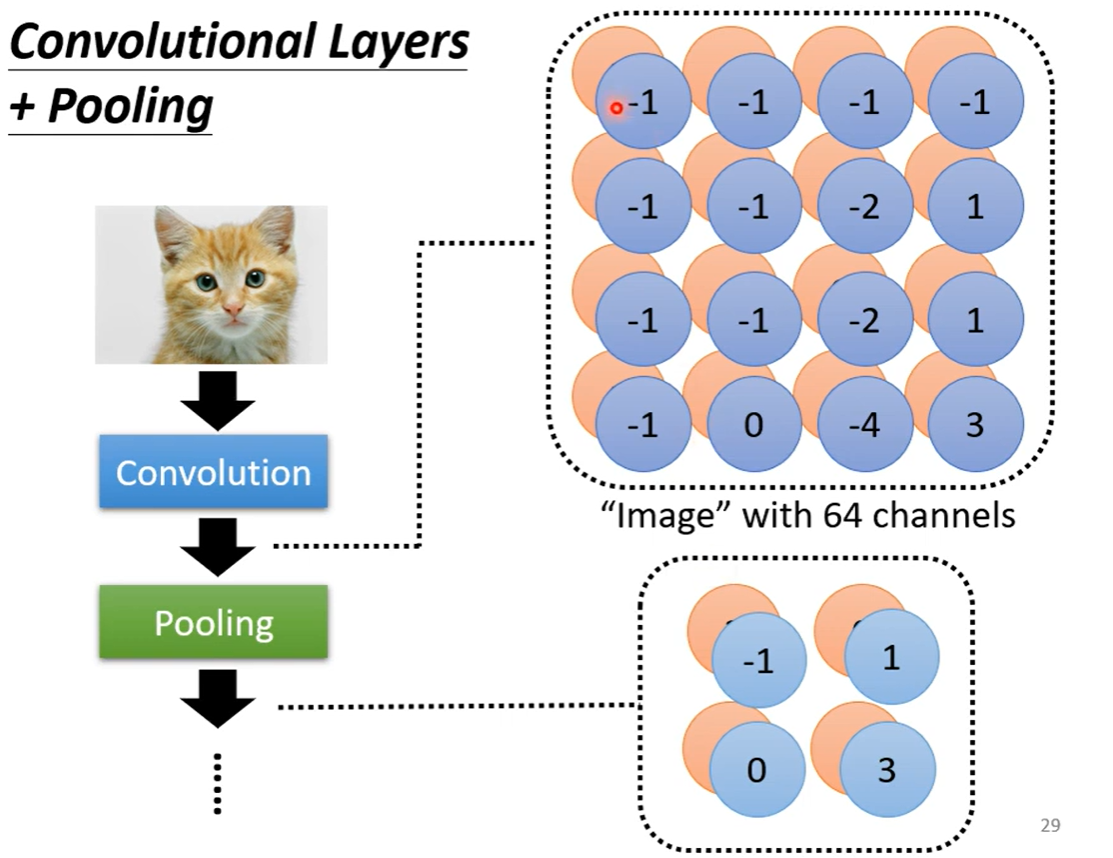
CNN不能处理影像放大、缩小或旋转的问题。例如:一只狗的图像放大后,CNN可能不能识别成功,因为放大后向量里的值都发生了变化。
key:使用Spatial Transformer Layer

若有收获,就点个赞吧
0 人点赞
