1、定义
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
2、应用
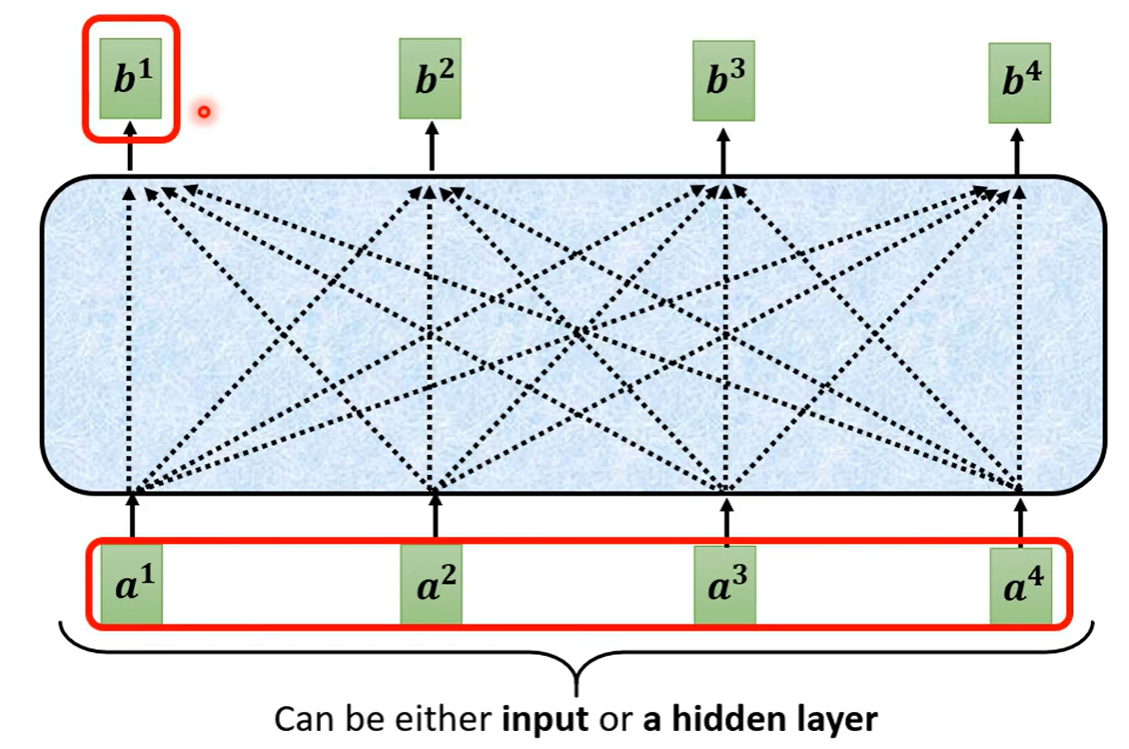
self-attention可以和fully connected交替使用,前者处理整个sequence的信息,后者专注于处理某一个位置的信息。self-attention的处理过程如下: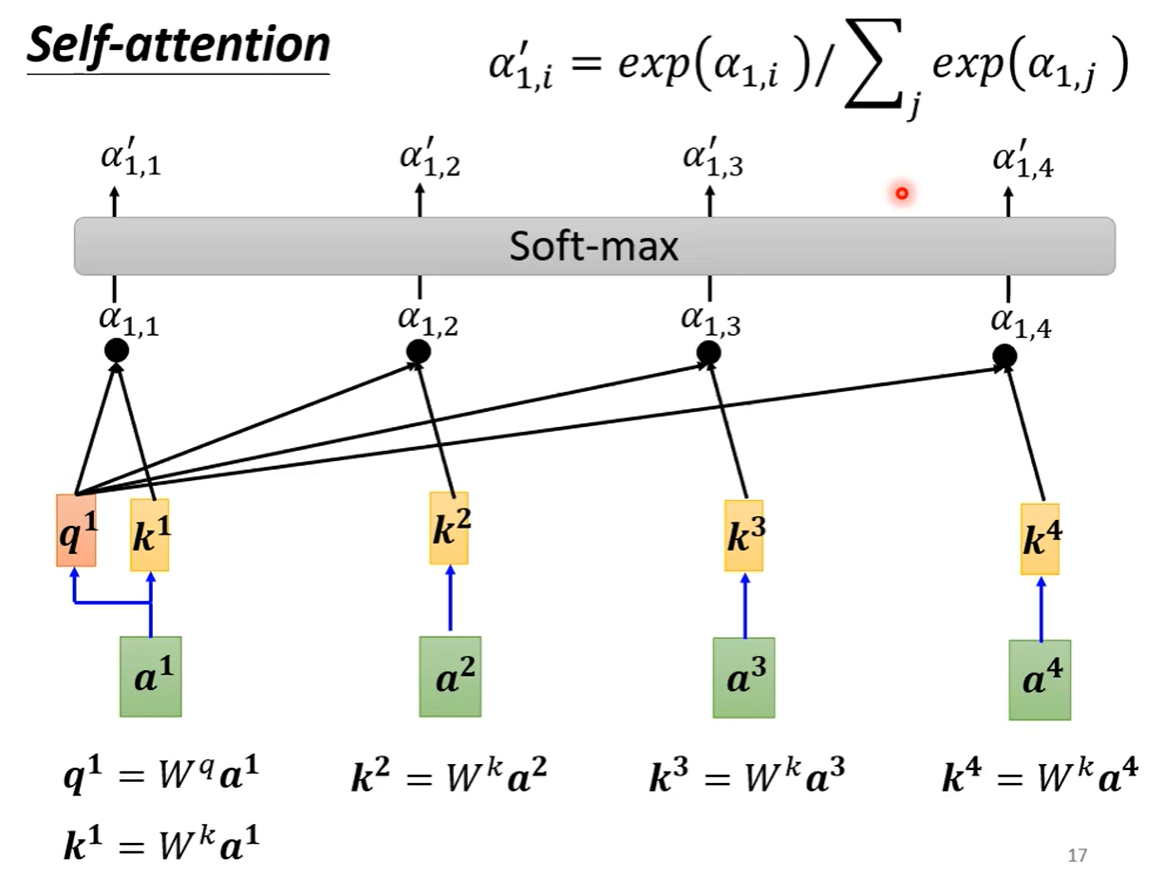
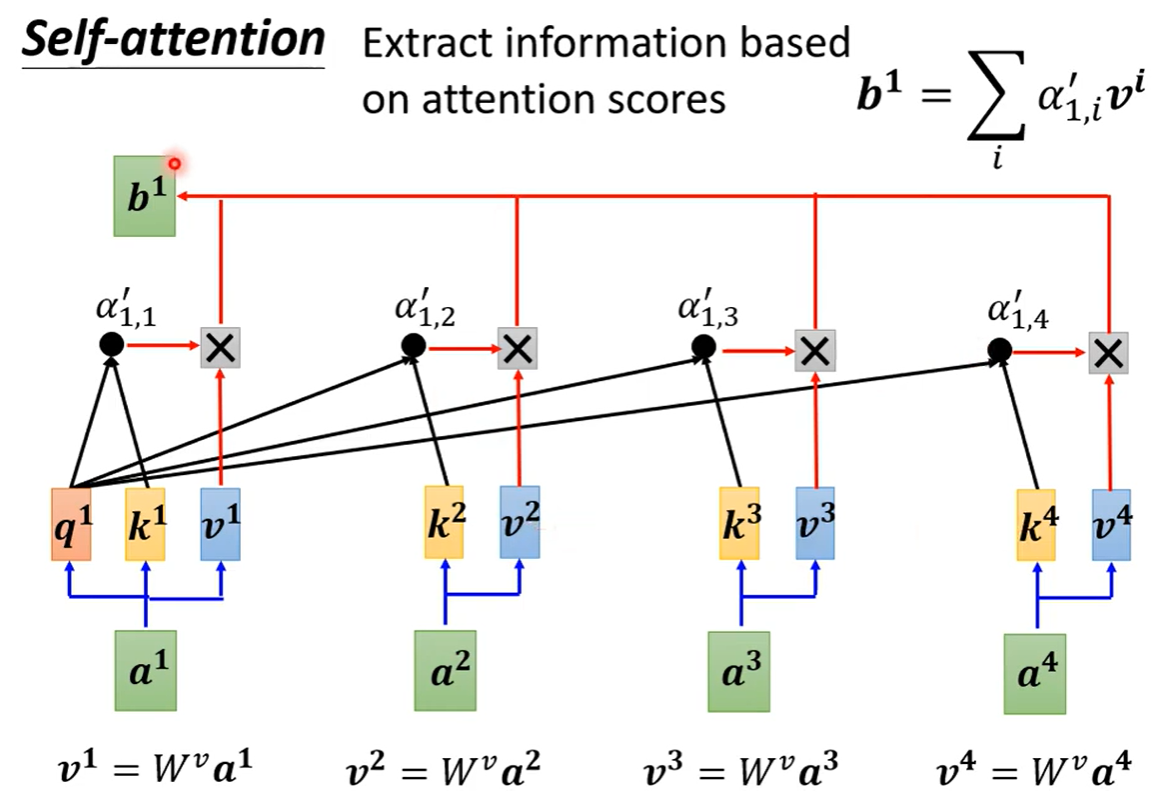
向量q、向量k、向量v的计算方式如下:
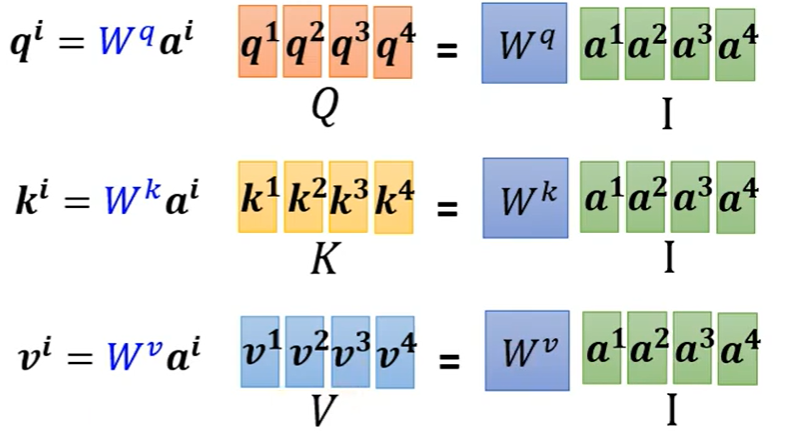
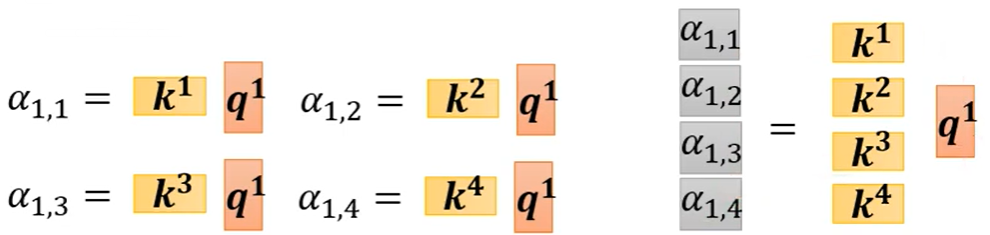

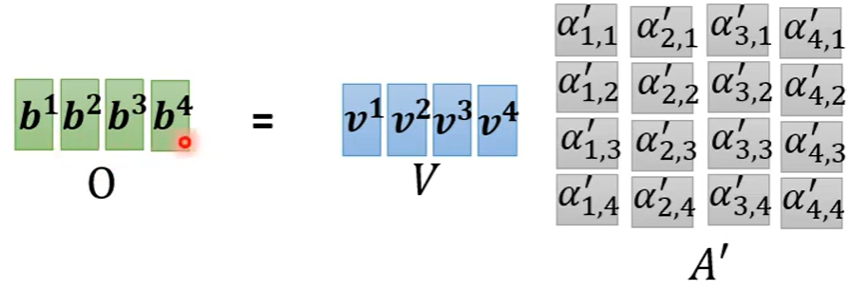
只有Wq、Wk、Wv需要从训练资料里找出来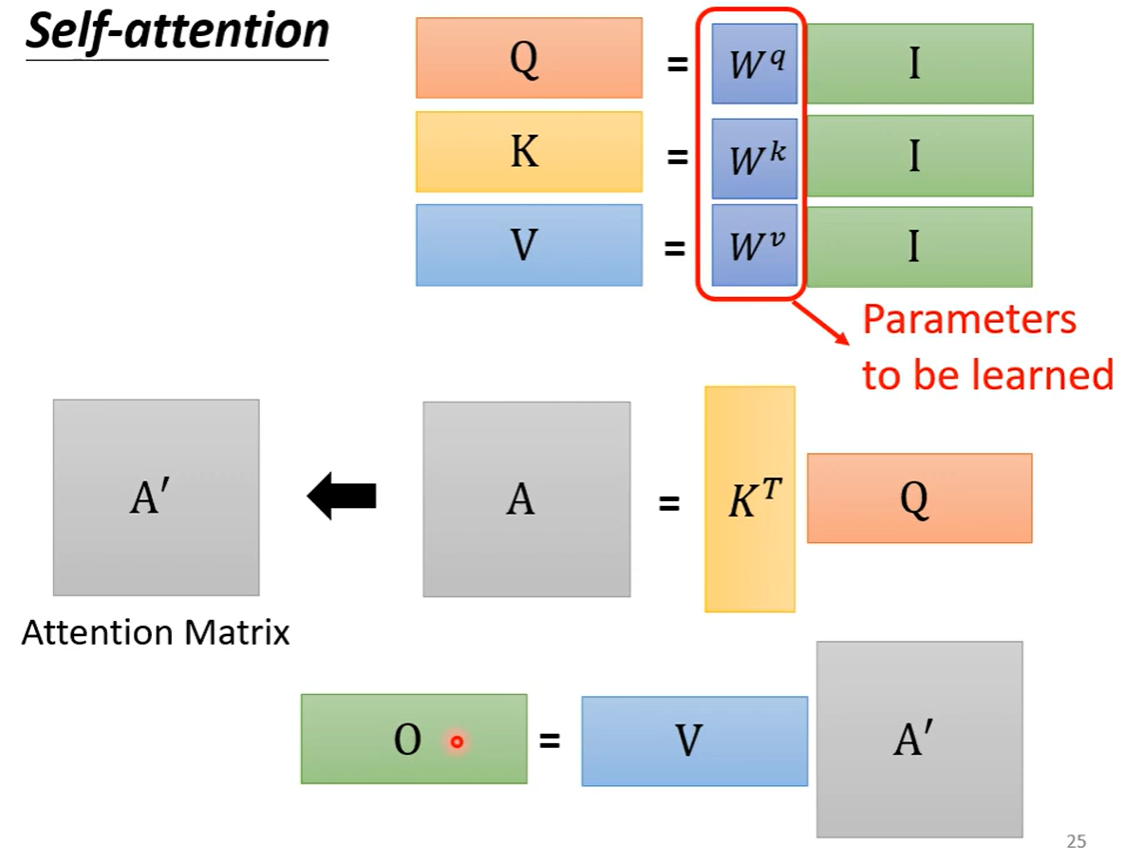
3、激活函数:
Rectified Linear Unit(ReLU): 用于隐层神经元输出
Sigmoid:用于隐层神经元输出
Softmax:用于多分类神经网络输出
Linear:用于回归神经网络输出(或二分类问题)
ReLU函数计算如下:
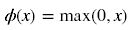
Sigmoid函数计算如下:
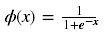
Softmax函数计算如下:
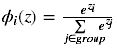
Softmax激活函数只用于多于一个输出的神经元,它保证所以的输出神经元之和为1.0,所以一般输出的是小于1的概率值,可以很直观地比较各输出值。
4、多头自注意力机制(Multi-head Self-attention)
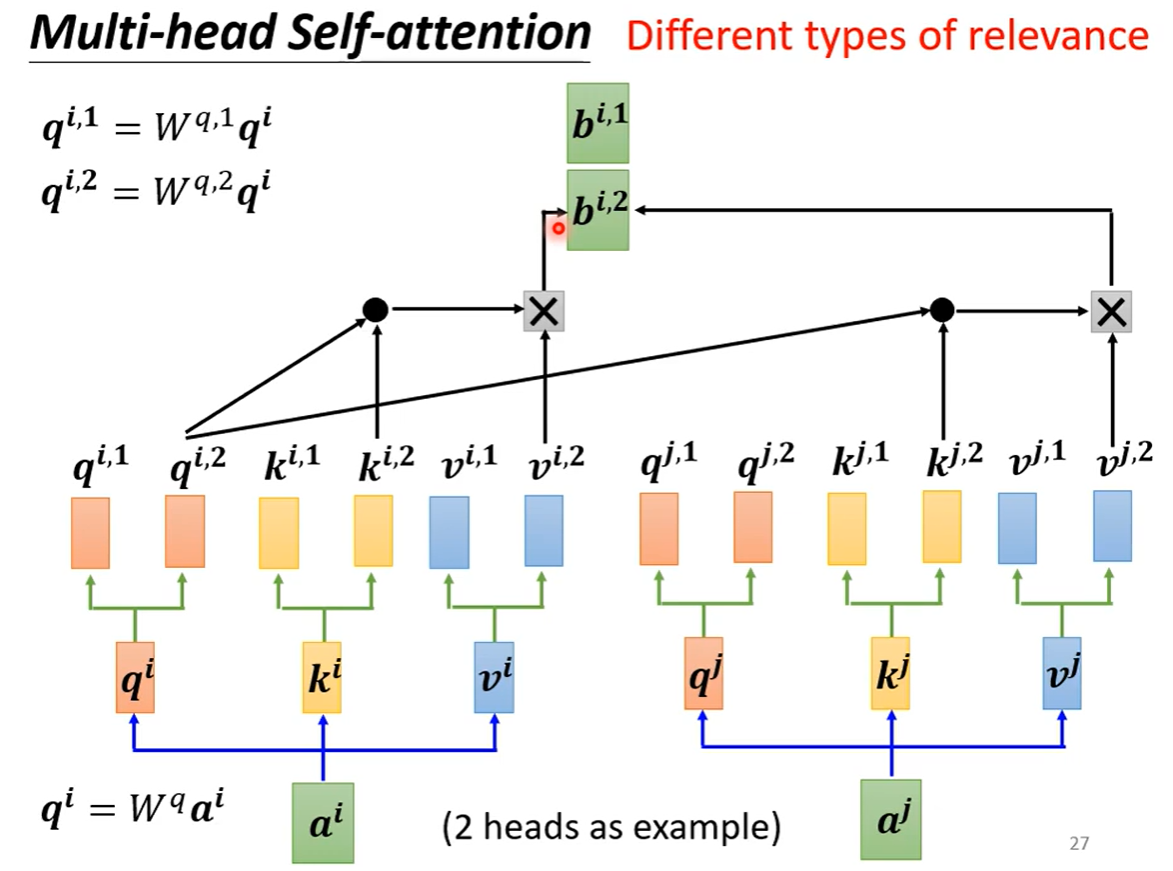
Positional Encoding:
Self-attention中不含有位置信息,因此可以将位置信息加进去。每个位置有一个特定的positional vector。

若有收获,就点个赞吧
0 人点赞
