通常来讲,学习一门新技术都是以“阅读这门技术的官方文档”、“运行官方文档中的代码示例”开始的。一般地,当相应的运行环境部署完毕后,我们潜意识对示例代码运行结果的期待是:
- 如果环境部署正确,那么这些「官方示例」应该都能运行正确;
- 而如果环境部署错误,则这些「官方示例」应该都会失败。
但 pyflink 代码示例的运行较为弔詭:在特定环境下,一份官方示例 A 运行正确,另一份官方示例 B 运行错误;在不同的运行环境下,A 与 B 各自时而正确、时而错误,且这些测试用例之间往往导致矛盾的猜测。
本文所使用到的「官方代码示例」分别:
- 一份代码示例是经典的 word count 的计算,将其命名为
word_count.py。 - 另一份代码示例来自 datastream 的示例,将其命名为
sample.py。
0x01
首先论述一下「发现问题」的整个轨迹:
- 下载、解压 flink 的安装包(可参考本文的 Appendix 部分),通过命令
<flink_dir>/bin/start-cluster.sh将其在 server 上启动运行。 - 使用
<flink_server_dir>/bin/flink run -py ./word_count.py命令运行 word_count.py 脚本,发现能够正常运行。 - 使用
<flink_server_dir>/bin/flink run -py ./sample.py命令运行 sample.py 脚本,发现报错 No module named ‘google’。 - 搜索报错可能出现的原因,猜测可能是因为忘记安装 pyflink 的 Python 包。于是在 server 上运行
pip -m pip install apache-flink用以安装 pyflink 的 Python 包。 - 继续尝试「3」中的命令,发现报错为 No module named pyflink!!!且尝试运行「2」,发现依旧能够成功运行。
- 对比「4」的情形,「5」的结果让人非常惊讶:刚安装完 pyflink 就报错 pyflink,之前没有安装的时候反而没有这个报错?!感觉上:“所做的操作”和“所得到的结果”完全是反逻辑!
- 无论是否安装 pyflink,为什么同为示例的 word_count.py 可以运行成功?并且反复检查 word_count.py 的示例代码,发现其中也有
import pyflink的部分啊?!
- 经过一系列“徒劳而繁琐”的尝试后,猜测:可能是因为运行 start-cluster.sh 时还未安装 pyflink,而安装完 pyflink 后,并未停止 flink server 让其重新启动。于是运行
<flink_dir>/bin/stop-cluster.sh,再运行 start-cluster.sh 来重新启动 flink server。 - 此时再运行 sample.py 脚本,发现终于可以运行成功。
- 这里还隐藏有一个小坑:如果「6」中的 stop-cluster.sh 没有将上次监听 8081 的服务完全停止掉,此时又做了重启操作,那么「7」这一步将不会成功。进而陷入更加诡异的迷思中。
根据上述论述,可以有以下猜测与疑问:
- 从「5」中的现象可猜测:似乎提交 job(运行
flink run -py ...)所使用的 Python 环境与启动 flink server 所使用的 Python 环境并非是同样的环境。 - 如果上述猜测成立,为什么 word_count.py 总是能够成功运行?特别是,这个测试代码中同样有
import pyflink的语句,为什么无论是在提交 job 的 client 端还是 flink server 端都能正确执行?
0x02
为验证上述关于提交 job client 端所使用的 Python 环境不同于启动 flink server 所使用的 Python 环境,我们可以通过 conda 来构建不同的 client/server 端 Python 环境的组合(其中 no_pyflink 是没有安装 pyflink Python package 的环境,pyflink 是安装有 pyflink Python package 的环境)。
进一步,根据 Flink Environment Variables 和 Command-Line Interface 两份文档,我们还能在运行命令前添加 -pyexec 参数来做进一步的比对验证:
| flink server 启动环境 | client 提交 job 环境 | job 代码 | 加载参数 | 结果 | flink job 状态 | |
|---|---|---|---|---|---|---|
| 1 | no_pyflink | no_pyflink | wordcount.py | 成功 | 成功 | |
| 2 | no_pyflink | no_pyflink | sample.py | No module named ‘google’ | 无 | |
| 3 | no_pyflink | pyflink | wordcount.py | 成功 | 成功 | |
| 4 | no_pyflink | pyflink | sample.py | No module named pyflink | Failed | |
| 5 | no_pyflink | pyflink | sample.py | -pyexec | 成功 | 成功 |
| 6 | pyflink | no_pyflink | wordcount.py | 成功 | 成功 | |
| 7 | pyflink | no_pyflink | sample.py | No module named ‘google’ | 无 | |
| 8 | pyflink | pyflink | wordcount.py | 成功 | 成功 | |
| 9 | pyflink | pyflink | sample.py | 成功 | 成功 |
从这些不同组合的测试结果可以看出,就 sample.py 这个示例代码而言,其结果完全符合我们的猜测:提交 job 的 client 端,同 flink server 端所使用的 Python 环境并不相同。
为做进一步的论证,我们还可以仔细考察「报错 No module named ‘google’」与「报错 No module named pyflink」的日志。对于前者来讲,其核心日志 log_client_no_pyflink 是:
Traceback (most recent call last):File "sample.py", line 58, in <module>state_access_demo()File "sample.py", line 40, in state_access_demods = ds.map(lambda a: Row(a % 4, 1), output_type=Types.ROW([Types.LONG(), Types.LONG()])) \File "/<hide_real_dir>/flink-1.13.0/opt/python/pyflink.zip/pyflink/datastream/data_stream.py", line 242, in mapFile "<frozen zipimport>", line 259, in load_moduleFile "/<hide_real_dir>/flink-1.13.0/opt/python/pyflink.zip/pyflink/fn_execution/flink_fn_execution_pb2.py", line 23, in <module>ModuleNotFoundError: No module named 'google'
而对于后者来讲,其关键日志 log_client_has_pyflink 是:
Job has been submitted with JobID 3fff686e873873c9eb6b660b15fdc9d9Traceback (most recent call last):File "sample.py", line 58, in <module>state_access_demo()File "sample.py", line 54, in state_access_demoenv.execute('state_access_demo')File "/<hide_real_dir>/flink-1.13.0/opt/python/pyflink.zip/pyflink/datastream/stream_execution_environment.py", line 645, in executeFile "/<hide_real_dir>/flink-1.13.0/opt/python/py4j-0.10.8.1-src.zip/py4j/java_gateway.py", line 1286, in __call__File "/<hide_real_dir>/flink-1.13.0/opt/python/pyflink.zip/pyflink/util/exceptions.py", line 147, in decoFile "/<hide_real_dir>/flink-1.13.0/opt/python/py4j-0.10.8.1-src.zip/py4j/protocol.py", line 328, in get_return_valuepy4j.protocol.Py4JJavaError: An error occurred while calling o0.execute.: java.util.concurrent.ExecutionException: org.apache.flink.client.program.ProgramInvocationException: Job failed (JobID: 3fff686e873873c9eb6b660b15fdc9d9)......Caused by: java.io.IOException: Failed to execute the command: python -c import pyflink;import os;print(os.path.join(os.path.abspath(os.path.dirname(pyflink.__file__)), 'bin'))output: Traceback (most recent call last):File "<string>", line 1, in <module>ModuleNotFoundError: No module named 'pyflink'at org.apache.flink.python.util.PythonEnvironmentManagerUtils.execute(PythonEnvironmentManagerUtils.java:211)at org.apache.flink.python.util.PythonEnvironmentManagerUtils.getPythonUdfRunnerScript(PythonEnvironmentManagerUtils.java:154)at org.apache.flink.python.env.beam.ProcessPythonEnvironmentManager.createEnvironment(ProcessPythonEnvironmentManager.java:177)
可以看到,log_client_has_pyflink 的第一行日志显示已经有 JobID,说明它已被成功提交到了 flink server 端。而 log_client_no_pyflink 并没有生成 JobID,说明代码的执行路径还在提交 job 的 client 端。依旧符合我们的推测。
Remarks:
- 两份报错日志的 calling stack 均显示:
File "/<hide_real_dir>/flink-1.13.0/opt/python/pyflink.zip/pyflink。这说明 client/server 端均使用到了 flink 自带的 pyflink.zip 包。 - 由「1」我们似乎可以猜测:使用 pyflink.zip 的效果不同于使用通过
pip -m pip install apache-flink安装的 pyflink 的效果(其原因在后文的 0x03 部分做论述)。否则,若二者等价,则由「1」可知,所有的测试组合应该都能运行成功才对。 - log_client_no_pyflink 日志显示,其 client 端的报错是无法找到 google 包,而不是找不到 pyflink 包。
- logclienthas_pyflink 日志显示,其 server 端的报错是源自 org.apache.flink.python.env.beam(对应到日志最后一行)所抛出的 `Failed to execute the command: python -c import pyflink;import os;print(os.path.join(os.path.abspath(os.path.dirname(pyflink.__file)), ‘bin’))
,也即是运行import pyflink` 报错。- 注意,这个
import pyflink的报错是来自于java.io.IOException(见 12 行),这说明语句import pyflink是由 Java 调用 Python VM 来执行import pyflink的。 - 可以推知,如果是 Java 调用 Python VM,则其 Python package 的搜索路径只可能是 Python 环境所在路径。因为对于通用的 Python VM 来讲,它并不知晓哪里会有一个 flink server 目录存在,进而无法知晓 pyflink.zip 的存在。
- 注意,这个
※ 0x03
以上论述依旧无法解释的部分是:既然 client/server 端是同所在 Python 环境是否安装 pyflink 包息息相关,为什么 word_count.py 总是能运行成功?
我们只能猜测:虽然 word_count.py 与 sample.py 都使用了 import pyflink ,但它们的执行路径是不是并不相同?
比较两份官方示例代码发现,一个明显的不同可能在于:sample.py 使用了 UDF,而 word_count.py 并未使用 UDF。
如此,进一步搜寻关于 pyflink 对 UDF 的支持的信息可以发现,在文档 Python Support for UDFs in Flink 1.10 中提及了如下清晰的 architecture 示例图: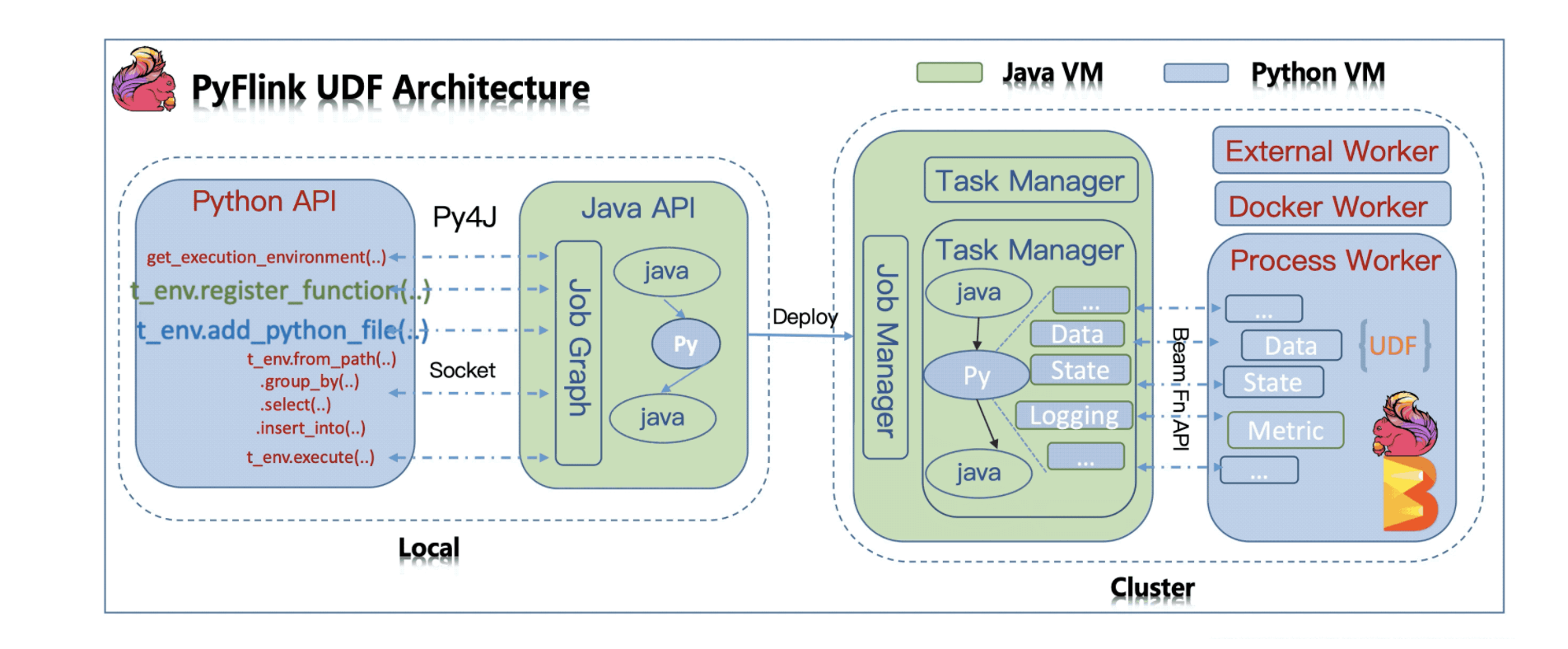
并且,根据文档中这张图下面的解释可知:
- local 端的 Python API(运行于 python VM)调用都会通过 Py4J 被映射为 Java API(运行于 VM),最终生成 Java JobGraph(运行于 JVM)然后提交到 cluster。
- server 端:直接执行被提交的 Job Graph。但如果涉及的 task 包含 Python UDF,则必须通过一系列的 gRPC service 来完成 JVM 和 Python VM 之间的通信。
如此,我们可以解释为什么 wordcount.py 在 flink server 端总是可以成功:因为 word_count.py 并不涉及 Python UDF,因此不需要通过 Beam Fn API(注意到图中的右边 JVM 同 Python VM 的交互部分,以及 0x02 的 remark「4」的论述_)在 server 端产生 Python VM 和 JVM 的通信,进而也就不会触发 Java 调用语句 import pyflink 。
基于以上新获取的信息,我们可以再次考察 0x02 中的日志详情。可以发现,日志 log_client_has_pyflink 其实包含了太多隐藏的、容易误解的信息,重新整理该日志所反映的执行路径:
- sample.py 中成功使用了 pyflink.zip 来运行
import pyflink....等语句。 - 在 pyflink 相关的执行指令中,涉及到了 py4j 的调用,将相关执行转换为 o0.execute 的执行(见 11 行)。
- 而 o0.execute 的执行,即是执行相关的 java 代码(从 12 行开始可以看到,均是 java stack 的日志)。
- 在 java 代码中调用了 Beam Fn API(见 20 行),而 Beam Fn API 由触发了
python -c import pyflink; ...的调用。
乍一看,「4」中的 Python 语句 import pyflink 似乎是直接来自于「1」的。这就容易让人陷入困惑:明明就在 pyflink.zip 中,为什么还说找不到 pyflink 呢?
这其实是因为「4」的 Python 语句并不来自于「1」,而是来自于 Beam Fn API 单独触发的 Python 命令!对于它来讲,这里的 Python 命令显然是当前 OS 下的 Python 命令,它并不知晓 flink server 目录的存在,自然也不知道 pyflink.zip 的存在,当然就会在 no_pyflink 环境下的 import pyflink 语句上报错。
0x04
如果 sample.py 同 word_count.py 的区别仅仅是在 Python UDF 的问题,那为什么 sample.py 在 client 端的 no_pyflink 环境会报错的时候,word_count.py 为什么不报错呢?
这只能说,两份代码的不同不仅仅是 Python UDF!
再次经过一系列“徒劳而繁琐”的尝试后发现,sample.py 还执行如下的 .map() 操作:
ds = ds.map(lambda a: Row(a % 4, 1), output_type=Types.ROW([Types.LONG(), Types.LONG()]))
并且,我们可以通过在 wordcount.py 仅添加这行代码(以及相关定义代码_)、而不添加 sample.py 的 UDF 部分的代码发现,修改后的 word_count.py 会在 no_pyflink 的 client 端报错 No module named ‘google’!
如此,我们就能断言:.map() 操作引起了 import google 操作。
进一步,我们猜测:pyflink.zip 并不包含这个 google 包(回顾 0x02 remark「2」的推测),但 pip -m pip install apache-flink 操作却能附带安装这个 google 包。
为验证这个猜测,只需通过 conda 分别到 no_pyflink 和 pyflink 环境,分别在其 Python 中执行 import google 即可。测试结果显示,在 no_pyflink 中执行报错,而在 pyflink 中执行成功,完全符合我们的推测。
0x05
综上所述,我们可以得出的一些 notes 是:
- 根据文档 Python Support for UDFs in Flink 1.10 的论述可知,pyflink 直到 1.10 才引入 UDF,这在不经意间造成了之前的官方示例 word_count.py 同后来关于 UDF 的官方示例 sample.py 的不同。特别是,它们各自在不同环境下的表现不同。
- 使用 flink 自带的 pyflink.zip 并不等同于使用
pip -m pip install apache-flink的安装结果,这表现于如下几点:- 通过 pip 的安装方式顺带安装了 google 这个包,以便让
import google生效; - 虽然在 flink 中使用
import pyflink是成功的(否则 word_count.py 也不会运行成功),但在 Beam Fn API 使用import pyflink时,却无法使用 flink 携带的 pyflink.zip 包。- 这是因为:从 log_client_has_pyflink 日志可知,Beam Fn API 是通过 Java 代码来调用 Python VM 来运行
import pyflink的。 - 在这种方式下,其 Python package 路径只能是 Python 环境所在路径。对于通用的 Python VM 来讲,它不可能知晓有 flink server 路径的存在,因而更不能确定 pyflink.zip 的位置。
- 这是因为:从 log_client_has_pyflink 日志可知,Beam Fn API 是通过 Java 代码来调用 Python VM 来运行
- 这个表面「相同」而实际「不同」的差别,在“通过日志排查问题”的过程中,造成了许多对真实执行过程的误解,进而在这些误解中陷入逻辑矛盾的困惑。
- 通过 pip 的安装方式顺带安装了 google 这个包,以便让
- flink 提交 job 的client 端与执行 job 的 server 端使用不同的 Python 环境,这只能通过人为的方式进行保证(这也是为什么提供
_-pyexec_参数的原因)。 - sample.py 运行结果的不同源自两方面:
- client 端:使用
.map()导致对import google的执行。而它依赖于 pip 安装 pyflink 时顺便安装的 google 包。它不同于不包含 google 包的、由 flink server 自带的 pyflink.zip。 - server 端:使用了 Python UDF,导致了 Beam Fn API 的调用,进而导致 Java 调用
import pyflink语句的失败。Java 调用 Python 语句时显然只能使用 OS 的 Python 环境,无法知晓 flink server 的存在,进而无法使用 flink server 所携带的 pyflink.zip 包。
- client 端:使用
- 在不熟悉某项技术相关「原理与机制」的情况下,极为容易“误读”其运行日志。因为你无法在「原理」的指导下,正确地“划分”日志的结构,进而在正确的结构下获得正确的理解。
- 当出现明显的测试逻辑矛盾时,只能归因为其背后一定有更复杂、更细微的运转机制,需要通过进一步搜索相关「底层信息」才能揭开矛盾。
Appendix
(Flink 的安装与相关测试环境的构建)
可通过 curl -O [https://archive.apache.org/dist/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.12.tgz](https://archive.apache.org/dist/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.12.tgz) 下载 flink-1.13 并解压。
运行 flink server 前,需要保证宿主机的如下环境:
- Java version 需要保证为 8 或者 11(可通过
java -version来确认)。个人的测试结果是,Java 8 可能更为稳定(如果所在环境有多个 java 版本,可通过重新定义JAVA_HOME及PATH环境变量来切换 java 版本)。 - Python version 需要保证为 3.6, 3.7, 3.8 中的一个,可通过
python --version来确认。如有多个版本的 python,可通过 conda(linux 服务器上可通过安装 Miniconda 来快速使用 conda)来切换 Python 环境。
确认好宿主机环境后,可通过 <flink_dir>/bin/start-cluster.sh (注意,不要在前面添加 sh ,sh <flink_dir>/bin/start-cluster.sh 会失败)来启动 flink server,通过 <flink_dir>/bin/stop-cluster.sh 来停止 flink-server。
使用 pyflink 还需要通过 pip -m pip install apache-flink 来为相应的环境安装 pyflink package。
通过 conda 构件通过 pip “安装/未安装” pyflink Python package 的环境:
# 安装 python 3.8 环境,但并不安装 pyflink packageconda create -n no_pyflink python=3.8# ---------------------------------------------# 创建 pyflink 环境conda create -n pyflink python=3.8# 并在 pyflink 环境下安装 pyflink packageconda activate pyflinkpip -m pip install apache-flink# 查看当前 env 列表conda env list

若有收获,就点个赞吧
0 人点赞
