networks 中充满了复杂的 protocol,以及这些 protocol 的各种含糊不清的实现细节。大部分的 networks 书籍会告诉你,「实现细节」不重要,只要能满足 protocol 就行。而 OS 的书籍一般也会告诉你,networks 部分的 TCP/IP stacks 只是一个应用分支,对 OS 这个主流来讲无关紧要,只需了解相应的 protocol 就行。于是,networks 部分的代码和运行的位置,就成了相互推诿的漏洞,无法准群知晓它到底在哪。
事实上,我们并不需要知晓 networks protocol stacks 的全部实现细节,我们需要知道的仅仅是它在 OS 架构的哪个位置,同 socket API 所在的位置又什么关系,同 network card driver 的位置有什么关系。只要知晓了它运行所在的位置、在具体的位置所充当的具体职能,即便不知道具体的实现细节,我们也能准确地定位问题、分析问题。
xv6 的 lab6 无疑是弥补了这样一个重要的细节缺失。它给出的一张 architecture 图例,理清了那些含混不清的「位置」部分,以及由此而来的对 networks 考察视角的修正。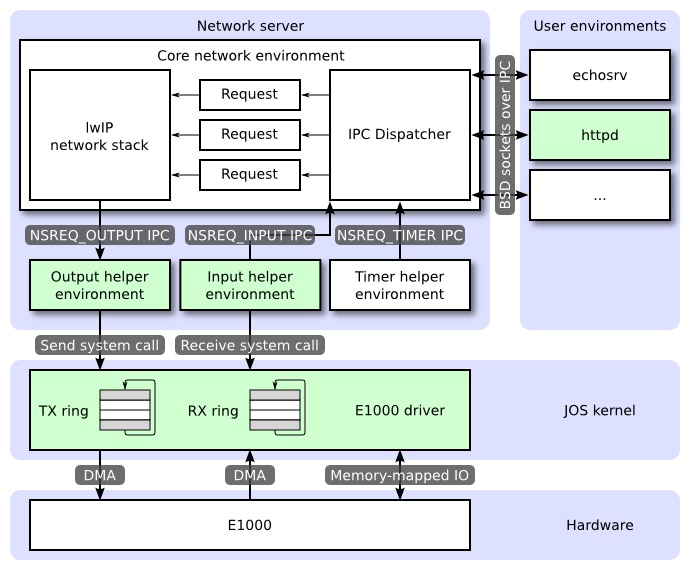
出自 xv6 2018:https://pdos.csail.mit.edu/6.828/2018/labs/lab6/
可以看到,左上角的「lwIP」是开源项目 lightweight TCP/IP stacks,它是整个 TCP/IP stacks 的实现。但 xv6 Lab6 的这张图清晰展示了,TCP/IP stacks 只是作为一个数据的「打包/拆包」的数据转换层而存在,具体的数据发送、网卡 driver 调用其实都和 TCP/IP stacks 无关。
关于「打包/拆包」,大部分材料的实例可能都是给出 header、content 的各种方块叠加图:
出自:《深入理解计算机网络》
但或许更容易的理解方式是使用 json 来展示:
{'link_layer_header': 'link_layer_header_msg','data': {'network_layer_header': 'network_layer_header_msg','data': {'transport_layer_header': 'transport_layer_header_msg','data': {'session_layer_header': 'session_layer_header_msg','data': {'presentation_layer_header': 'presentation_layer_header_msg','data': {'application_layer_header': 'application_layer_header_msg','data': 'application_contents'}}}}},'link_layer_tailer': 'link_layer_tailer_msg'}
所谓的「打包」,就是不断地把「这一层」的数据作为一个整体挂到「下一层」的 data 字段上,而「拆包」就是递归地把每一层的 data 字段读取出来。
notes:
- 当然,用 json 表达「概念」对人的「认知」来讲是更容易的,但对于计算机的效率来讲,则差很多。为了让其高效,可以省略每一层的「字段名」,然后将其压缩到每个 bit 去顺序存储。
- 打包时,有可能遇到某一层的数据量过大,于是可以将其「某一层」作为一个大 string 拆分为多个部分,每个 substring 部分作为「下一层」的 data 字段继续打包。
初次接触 TCP/IP stacks 的五层 protocol 都会让人不知所措、眼花缭乱,因为你无从知晓为何要设计这么多层?为什么不可以简化为更直观的两层:一个 physical layer 用来统一不同的物理介质,一个 network 层用来描述不同节点的通用传输?或者将问题换一种提法,在这个简单的两层模型中,存在哪些 motivation 导致了需要不断地增加 layer 来构建出最终的 TCP/IP stacks ?
一层 physical layer,一层 data link layer(TCP/IP stacks 的 bottom 2 layers),其实就已经构成了「局域网」(local area network,LAN)的解决方案。只要涉及到的数据传输没有「跨网段」、在同一个网段中,它就是一个 LAN 的传输。如果用「快递」做比喻,LAN 就是一个「同城配送」。对于「同城配送」来讲,它仅仅需要 physical 和 data link 这两层。
那么,如果跨网段呢?也即是:如果你的数据传输是「跨城市快递」呢?
这个时候,就是 network layer 登场的时候了。network layer 是为「跨网段」而服务的通讯协议,它并非服务于「同网段」的通讯(它已经由 physical layer 和 data link layer 所支持了)。如果对应到「快递」来讲,「跨城市快递」所涉及到的传输方式,应该是由「跨城高速公路」规则所描述的,而不是「同城」的「城市交通」规则来描述。
在这个模型下,为了唯一标识某个「网段」/「城市」,就需要引入 id 标识符,即:IP 地址。很多材料都会说,IP 是唯一的。但这种描述并不准确,所谓的「唯一」是有范围的唯一。IP 只是在「网段」/「城市」这一级是唯一的,而再进一步到某个 LAN 中的具体节点,它们都会共享一个 IP。就像居住在同一个城市的居民,都会共享这个城市的某个「高速公路出口」。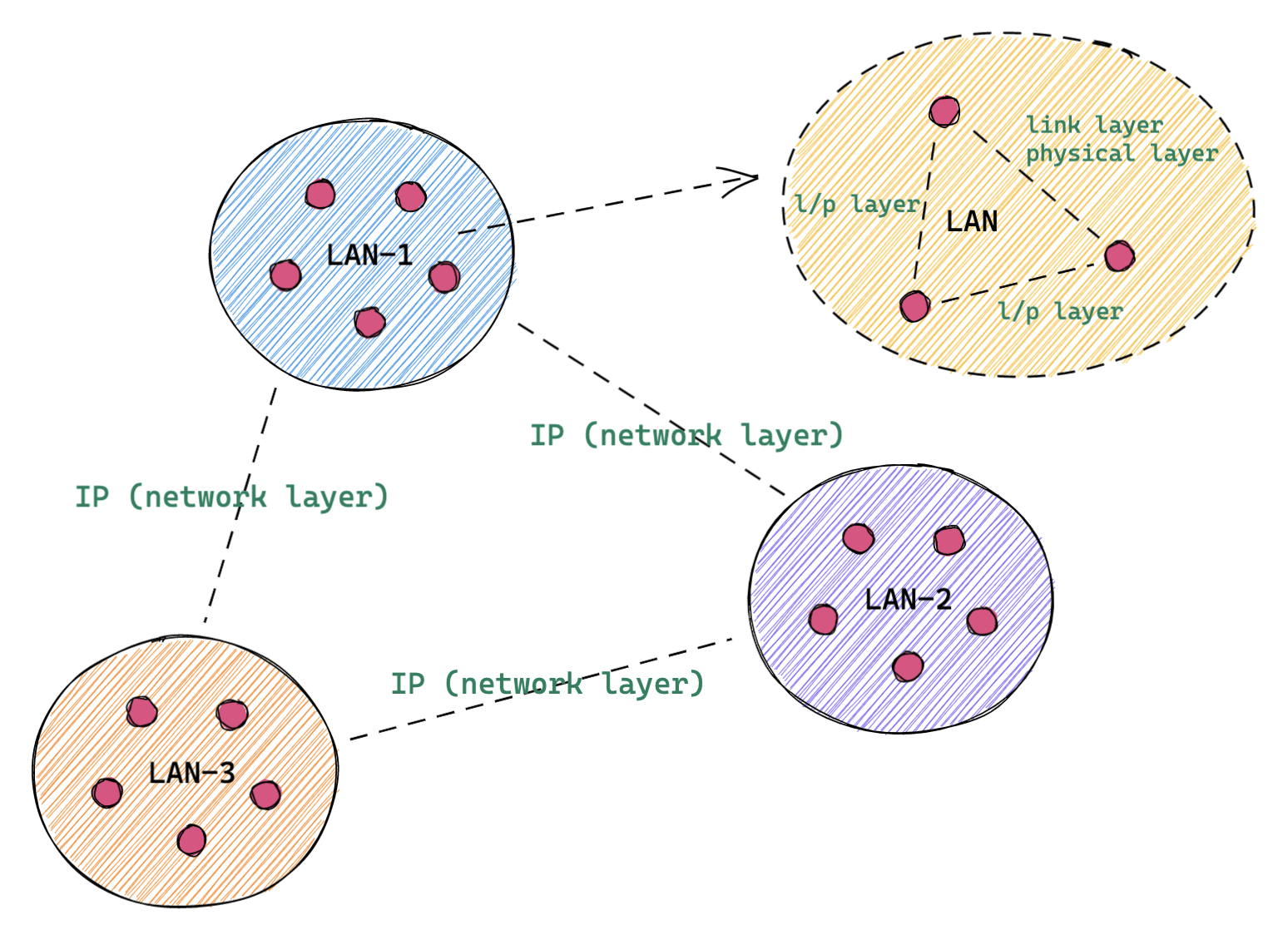
出自:Terence Xie
可以看到,「link/physical」两层 layer 的直观设计存在于各个 LAN 中,在每一个 LAN 中根本不会涉及到 network layer,因为它是「同网段」/「同城」的传输。而一旦发生「跨网段」,则自然需要借助 IP,通过 network layer 的 protocol 来完成「跨网段」/「跨城市」的传输。
由此,有了 physical layer、data link layer 以及 network layer,就已经实现网络中各个节点之间的数据传输了,我们不禁要问,为什么还需要引入 transport control layer 呢?
这就涉及到我们如何理解「传输」这件事了。本质来讲,我们希望传输的是有其特殊业务含义的 information 本身。而在网络中将 information 给拆分为可传输的「单元」,我们可以称之为 data。而在实际的物理介质中,是以各种 signal 的形式来将 data(bit 形式)传播出去的。
那么,虽然「physical layer、data link layer 和 network layer」构成了可以触达的「通路」,但对于「传输」这件事情本身,我们其实对它有相应的业务要求(需求/feature)的。例如,我们希望 information 被拆分成 data 传输后,在接受端能够有序地将这些 data 组合重新拼凑出原始的 information;我们当然还希望组成 information 的 data 是完整无丢失的,而如果存在丢失,也能够有相应的「重试机制」;我们还希望对 information 的传输是高效的,让每个当前带传输的 data 能够避过「阻塞」的路径,从更加通畅的路径做传输。
如此重重的关于「传输」本身的业务诉求,都不是「传输通道存在」就天然解决的。这就是引入传输层(TCP layer)的必要性,你需要单独的 layer 来实现这些「传输」本身的诉求/需求。
如此,有了 TCP layer 来实现「传输」的业务诉求,有了「physical layer、data link layer 和 network layer」来支持「通路」,整个关于信息「传输功能」就已经完全被实现了。此时再回过头去看最上面的「应用层」就可以知晓,它其实是作为「传输功能」的 user 而存在的。严格来讲,它已经不是在讨论「如何传输」这件事了,它关心的是「如何『使用』传输」。
而一旦涉及「使用」,最好的方式无外乎提供一层抽象的 API 来做支持。而这层包含了「TCP/network/data link/physical layers」、提供「传输功能」的 APIs,就是著名的 Socket APIs。它将「传输功能的实现」同「传输功能的使用」彻底分离,以便支持更好的解耦和 feature 变化的应对。
而从 xv6 lab6 的图也可以看出,类似于 httpd 这些应用层的东西,也都自然而然地被划归到了 user environment 中,而不再掺和到 OS 的非 kernel 部分。这同样也展示了为什么一谈及 network programming 就几乎等价于在谈论 socket programming。因为类似于 lwIP 的整个 TCP/IP stacks,它完全实现了「传输功能」、且嵌入在了各个网络设备(OS、router 等)中。即便你自身可以使用不同于 TCP/IP stacks 的 protocol 来做传输,但你能强制修改外部千千万的网络设备吗?在这样的语境和现实下,TCP/IP stacks 这部分的 protocol 几乎只能是被利用而不能被改变。能够有所调整的,只能是基于 socket API 而做出的各种 application layer(广义的)的东西。
有了这样的关于网络的视角后,接下来让我们考察一些推论。
例如,由于我们知晓了「网段间」的通信只需要 IP,于是我们很容易推导出,对于传输的「中转站」,如:router、交换机 等,它只需要使用到 network layer 的信息就够了,它本身其实是不关心 TCP layer 及其以上的部分的: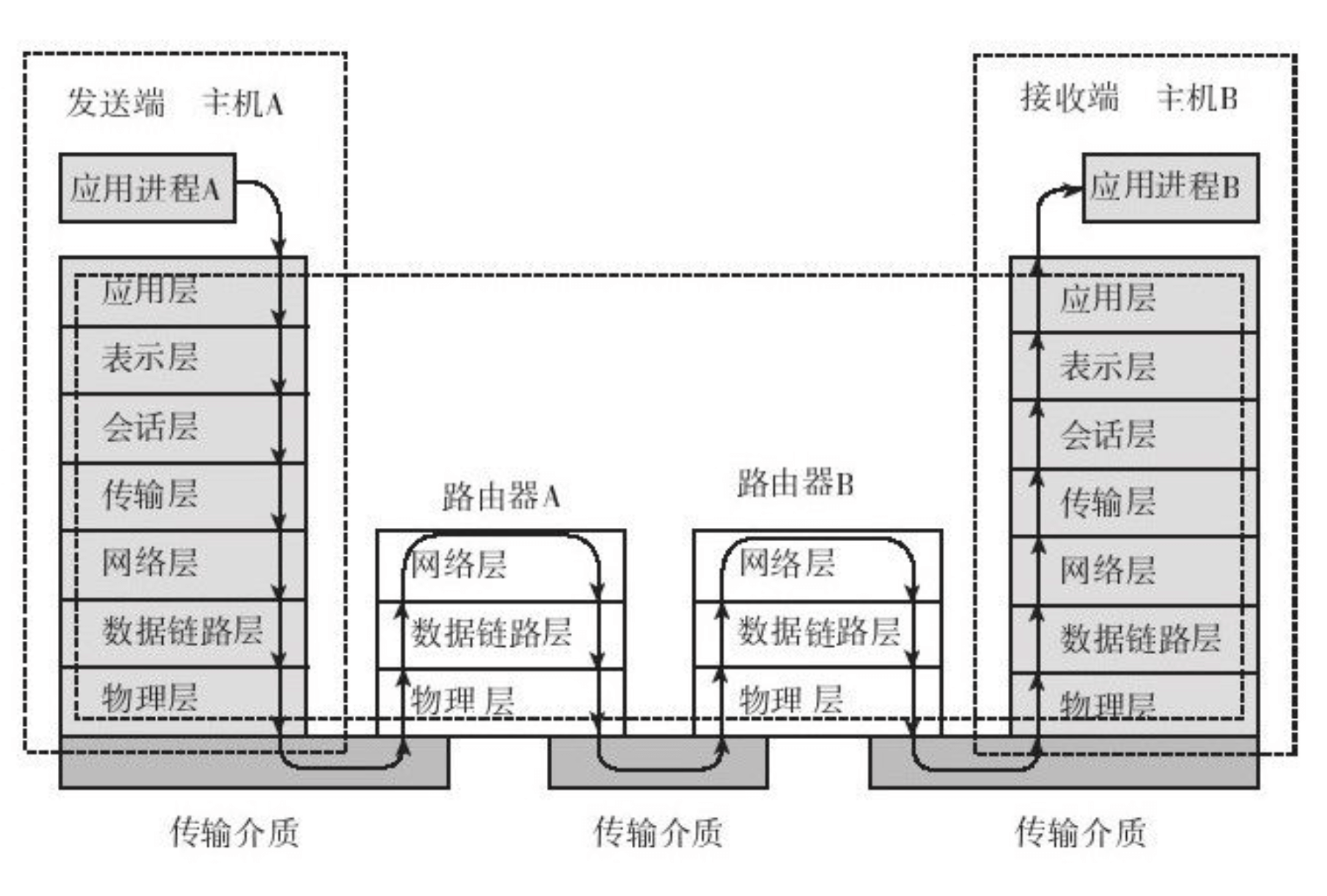
出自:《深入理解计算机网络》
这是因为这些「中转站」只要能够提供「城际间传输」的功能就够了,它不需要、也不能够知晓这些被它中转的 data 所对应的原始 information 是什么。既然不涉及到原始 information 的拼装和管理,那自然用不着 TCP layer 的东西。而从这个角度来讲,真正关心原始 information 的就只有两端:「发送端」和「接收端」,因此也只有这两端关心 TCP layer 的信息。对于传输路径所经历的「中转站」而言,它们仅需知道简单的三层「network/data link/physical layers」就足够了。也即是:虽然 TCP/IP stacks 轰轰烈烈地搞了这么多的「打包/拆包」,但最上面的 TCP layer 只会被两端使用(用来控制「传输」的业务诉求)。
另一个有意思的推论,是考虑 LAN 中的数据传输。
如上面的例子所考虑的,既然是 LAN 之间的传输,那么显然不涉及「城际间通信」,那么这就和 network layer 沾不上边,只需要 link layer 和 physical layer 就够了。那么自然,既然 network layer 不需要了(这里的「不需要」不是指没有 network layer 的数据,而是说这层 network layer 的数据发挥不了它真正的「跨网段」的作用),那么其上的 TCP layer、application layer 是不是也不需要了呢?
其实不是的,虽然 network layer 不发挥任何作用(因为不涉及到「网段间」传输),但 TCP layer 对 information 的拆解、有序组装、丢失重试这些「机制」的实现却依旧是有意义的。那么虽然是在不涉及 IP 的 LAN 中做传输,TCP layer 却依旧能够发光发热、提供相应的必不可少的、有意义的功能。
总之,弄清楚了 IP(network layer)仅为「跨网段」/「城际通信」而存在、而 LAN 这样的「同网段」/「同城通信」并不需要 IP 的介入,就能为你提供的正确的考察繁复 network protocols 的视角。再进一步梳理清楚 TCP layer 的作用、socket APIs 所起到的角色,以及整个 TCP/IP stacks 与 OS 的结构关系,基本上就能确定下来整个 networks 领域的核心框架。有了这个核心框架,才能将那些琳琅满目的 network technique details 有的放矢地挂在对应的正确位置上。
Appendix
繁多的 network protocol 催生了繁多的 network device。要理清楚 network device 之间的关系,就需要顺着「城际快递」和「同城快递」的思路去考察它们所处的位置。
| 两个端口 | 多端口 | |
|---|---|---|
| physical layer | 中继器(repeater) | 集线器(hub) |
| data link layer | 网桥(bridge) | 交换机(switch) |
中继器(repeater)恐怕是最简单的网络设备,它处于 physical layer,只有一个功能:放大 signal。因为 signal 会随着距离的变长而衰减,于是需要 repeater 来延长 signal 的传输范围。对于 repeater 来讲,它只有两个端口,当它接收到某一端的 signal 之后,就会无脑地向两个端口一起发送由它放大了的 signal,即:广播放大了的 signal。
一个自然而然的问题是:为什么 repeater 要无脑地向两个端口广播?为什么不能判断一下哪边是入口、哪边是出口?
首先,由于 repeater 要同时兼顾两个方向的 signal,所以它没办法单纯地去固定指定哪一端是入口,哪一端是出口。于是,它只能根据 destination 来确定传输的方向。可是,由于在 physical layer,它能知晓的就只是 electric signal 本身,它只是一个物理波,没有任何实质性的 information。
而要理解实质性的 information,就必须把相关的 signal 拼凑到一起,形成 information。可是,一旦它开始拼装 signal 形成 information,这就自然而然地跑到了 data link layer 的职责范围了,而这个举措也就自然而然地变成了 data link layer device 的功能了。对于 repeater 这样只处于 physical layer 的 device 来讲,是无法实现的。
再来是集线器(hub),它其实就有多个口的 repeater 罢了。于是,hub 中每个端口的 signal 在被放大后,都会无脑地发送给 hub 上的所有端口。容易想见,hub 是多么容易引起网络风暴。
从网桥(bridge)开始,其工作范围终于上升到了 data link layer 了,于是它能知晓、解析出 device 相关的信息,如:标识 device 的 MAC id。bridge 同 repeater 一样只有两个端口,每个端口连接一个属于同一个 subnet 的「物理网段」。bridge 的每个端口(假设为 A、B 端口)都会维护一张 MAC 表。假设端口 A 收到了数据(frame),它就会直接解析 frame 中 destination MAC 是什么,然后根据 A、B 端口的 MAC 表来判断是发送给 A 端口还是发送给 B 端口。
显然,在这种有了 MAC 表参与的模式下, bridge 中不会有像 hub 那样会无脑地向每个端口广播信息,这就大大提高了传输效率。
而交换机(switch,这里指「二层交换机」)则是具有多个端口的 bridge,每个端口都能够连接一个属于同一 subnet 的不同「物理网段」,而每个端口也都会维护一个 MAC 表。通常,由于 switch 上的端口众多,于是每个端口可能只会维护一个 MAC id,这就大大提升了 switch 转发数据的效率。

若有收获,就点个赞吧
0 人点赞
