Hardware Hierarcy
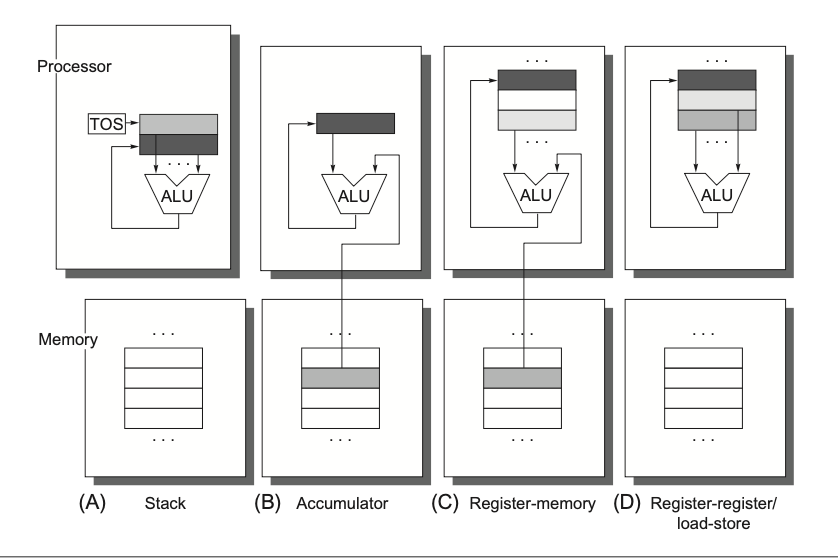
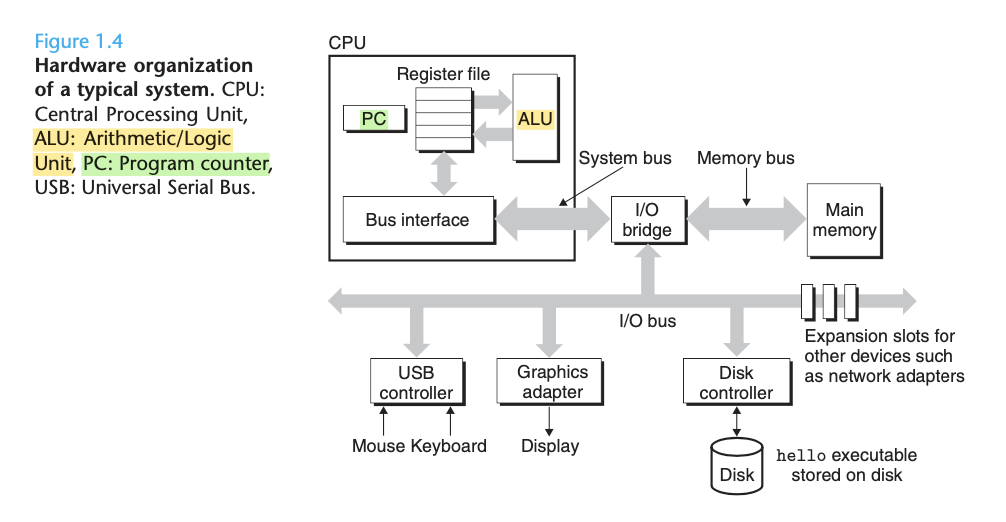
可以看到:
- CPU 的一个核心是 PC(program counter),它是一个仅有 word-sized 大小的 storage device。
- 凡是 word-sized 大小的存储设备都可以叫 register,所以 PC 是一个特殊的 register,它的名称叫做 PC。
- register file 中也包含了多个 register,为了区分彼此,每一个 register 都有一个特定的名称。
- 一般使用 register 时,泛指 register file 中的 register;指定 PC 这个 register 时通常不用 register 来简称,而是直接用 PC 称呼。
- 这个 register 仅能存放 word-sized 大小的数据,即:memory address。
- 从计算机开机到关机,每时每刻 CPU 都在执行 PC 所指向的、存放于 memory 的 instruction:
- 从 PC 所指向的 memory address 读取到相应的 instruction 。
- 按照这个 instruction 在 ALU 中做相应的计算。
- 更新 PC 的值为下一条 instruction 的 memory address(不一定同刚才那条 instruction 连续)。
- register file(上图中 PC 旁边的、多个小长方形组成的矩形):由多个 word-sized 大小的 register 组成的 small storage device。
- 每一个小的长方形,即是一个 register,且它的大小为 word-sized。
- 显然,register file 中的「每个小长方形」跟 PC 是一样大小的。且它们都被称之为 register。由此可见,register 可被当做是一个 word-sized 的、在 CPU 中的存储单位。
- register file 中的每个小长方形,各自都有一个 unique name。
- ALU 可计算出 new data 或者 new address value。
- CPU 支持的 instruction:
- Load:将 memory 中的一个 word-sized 大小的内容,复写到某个 register。
- Store:将 register 中的 word-sized 大小的内容,复写到 memory 中的某个位置。
- Operate:将两个 register 中的内容拷贝到 ALU,对这两个 word-sized 的值做算数运算,将结果复写到一个 register 中。
- Jump:从 instruction 中提取出一个 word-sized 大小的内容,将其复写到 PC。
CPU Register
register file 中的 register 有多个,它们分别有不同的作用,如:
- general purpose register:用于 data movement、arithmetic instructions。
- index register:充当 pointer
- base pointer:data pointer
- stack pointer
- segment register:用于存储 program 的 不同部分,如 code segment、data segment、stack segment、extra segment。
每一条 machine instruction,其实就是一个 number:
- 例如
03 C3表示:将 EAX 和 EBX 这两个 register 中的内容相加,并将结果放到 EAX 中。 - 但这样的 machine instruction 太难记忆,于是引入 assemble language:
- 每一个条 assemble statement 都对应一条 machine instruction;
- 例如上面的
03 C3machine instruction 对应的 assemble statement 为add eax, ebx。
可尝试分析的一段代码是:
int simple(int *xp, int y){int t = *xp + y;*xp = t;return t;}
使用反汇编之后的结果是:
注意:凡是以 . 开头的语句,都是用于 guide the assembler and linker,可暂时忽略。可得到简化版本:
Remarks:
- 在使用
%ebp之前,需要保留它的值到 kernel stack,以便 “结束运行后” 恢复。这个「保存」和「恢复」的过程分别对应为:- 第 2 行:
push1 %ebp,将%ebp的值保存到 kernel stack。 - 第 8 行:
popl %ebp,将 kernel stack 的值弹出,并恢复至%ebp。
- 第 2 行:
- 加载
simple函数的参数列表:- 第 3 行:找到
simple函数参数列表的 memory 起始位置,将这个起始位置从%esp复制到%ebp。 - 第 4 行:从
%ebp做 8 位的 offset,将其值复制到%edx. - 第 5 行:从
%ebp做 12 位(由于前一个变量在%ebp+8,且 int 变量占据 4 byte,所以当前变量的起始位置当然就是%ebp+8+4,即%ebp+12)的 offset,将其值复制到%eax。 - 第 6 行:将上述两步获取的值相加,并将结果复制到
%eax。 - 第 7 行:将刚才获取到的求和结果
%eax的值,复制到%edx,即*xp所在的位置。
- 第 3 行:找到
User/Kernel Mode
https://en.wikipedia.org/wiki/Linux_kernel
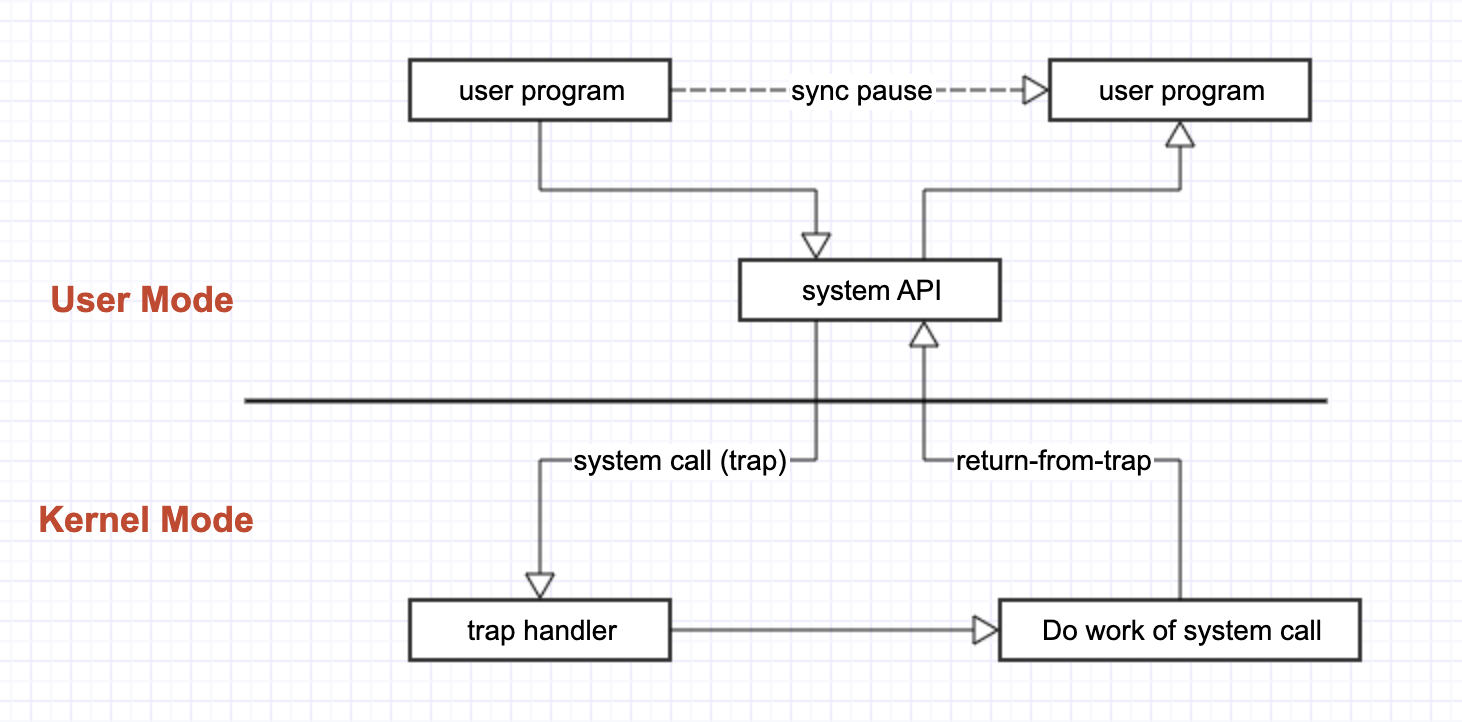
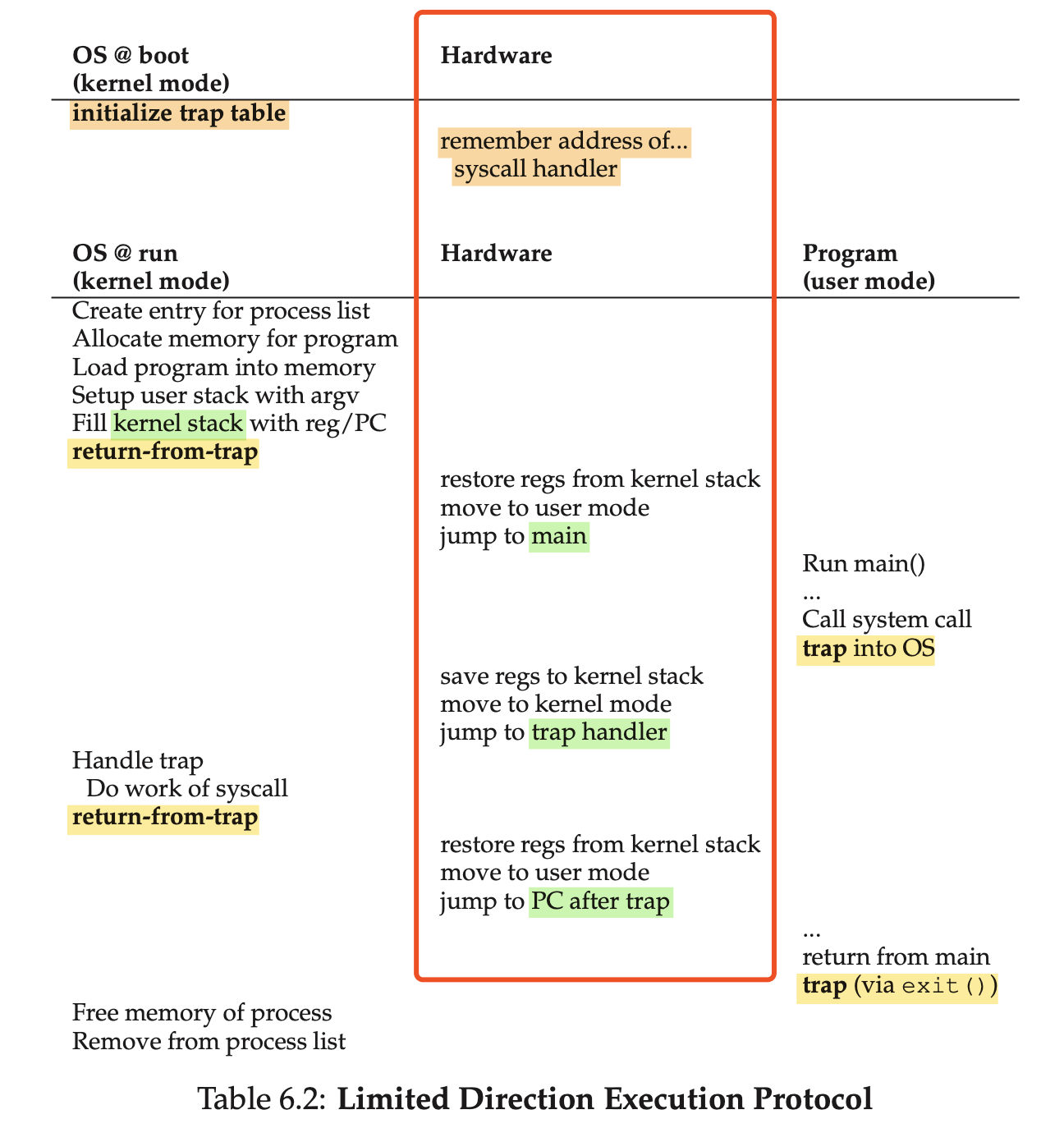
Remarks:
- 这里或许最容易造成误会的是,中间的「Hardware」,所指的并非是 external drive(外部设备),而是 CPU 本身。
- 两侧的 OS 和 Program,其实所指的都是「程序」,而中间才是执行程序的硬件,即:worker。
- 这里之所以容易造成误会,是因为很容易混淆 program、running program、program executor。
下面以 foo.c 编译出来的可执行文件 foo 的运行为例。运行开始的命令是 ./foo :
- 首先,需要为
foo这个执行文件做一些初始化工作,如:process 分配、memory 分配。但这些工作都无法在 user mode 下执行,需要进入 kernel mode。 - 于是,进入 kernel mode 前,需要将当前的 reg/PC 信息保存到 kernel stack 中(对应到第①步)。
- 进行初始化工作:分配 process、分配 process 中的 memory,并将
./foo的指令加载进被分配的 memory 中。 - 完成这些初始化工作后,通过 return-from-trap 返回到 user mode。此时,CPU 从 kernel stack 中取出之前保存的 reg/PC,开始这个 process 的执行,即:从 process 的 memory 中的
main()开始执行(对应到第②步)。 - 执行
main()函数时,遇到了需要调用 system call 的指令。此时,执行 trap instruction(对应到第③步)。- trap instruction 会保存当前的 reg/PC 信息到 kernel stack;
- 通过 trap table 找到相应的 trap handler(对应到第④步)。
- trap handler(kernel mode) 接收这个 trap(exception),并执行对应的 system call 的逻辑(对应到第⑤步)。
- 后续步骤相对显然。
Memory Management
Heap 和 Stack 在 process memory 中的 layout:
可以看到,一根 process 的粗略 memory layout 通常如下图所示:
一个值得思考的问题便是,为什么要如此摆放 stack 和 heap 的位置?可以不可以让 stack 从 low-bit 向 high-bit 增长?
假设 stack 是向下增长、且放于「上图」往上一点的位置,那就意味着当 stack 所用 memory 较少时,其下方会出现一块闲置的 memory。而如果此时 heap 的资源特别紧张,虽然 process 中存在 stack 那块未被使用的闲置 memory,但却无法被 heap 所使用。
由此可知,之所以如此设计和摆放 heap 和 stack 在 memory 中的位置,是为了让 heap 的 free memory 和 stack 的 free memory 变成一块可以「共同使用」的区域,此时,「任何一方」的剩余资源都可以被「另一方」拿来使用,从而降低了 process 中 memory 的浪费。

若有收获,就点个赞吧
0 人点赞
