原文发布于「2018年09月08日」:https://mp.weixin.qq.com/s/dWvaHPexzR1bjID3Mx8ugw
对于通常的 developer(特别是那些具备并行计算/多线程背景知识的 developer)来讲,js 的异步处理着实称得上诡异。而这个诡异从结果上讲,是由 js 的“单线程”这个特性所导致的。
我曾尝试用“先定义后展开”的教科书方式去讲解这一块的内容,但发现极其痛苦。因为要理清楚这个东西背后的细节,并将其泛化、以更高的视角来看问题,着实涉及非常多的基础知识。等到我把这些知识讲清楚、讲完,无异于逼迫读者抱着操作系统、计算机网络这样的催眠书看上好个几章节,着实沉闷而乏味。
并且更关键的是,在走到那一步的时候,读者的精力早已消耗殆尽,完全没有心力再去关心这个最开始的问题——js的异步处理为何诡异。
所以,我决定反过来,让我们像一个初学者那样,从一无所知开始:
先使用“错误的理念” 去开始我们的讨论,然后用代码去发现和理念相违背的地方。
再做出一些修正,再考察一些例子,想想是否还有不大满意和清楚的地方,再调整。如此往复,我们会像侦探那样,先从一个不大正确的假设开始,不断寻找证据,不断修正假设,一步步追寻下去,直到抵达最后完整的真相。
我想,这样的写作方式,更符合一个人真正的求知和研究过程,并能够为你带来更多关于“探索问题”的启发。我想,这样的思维方式和研究理念,比普通的知识更为重要。它能够让你成为知识的猎人,有能力独立地觅食,而不必被迫成为婴孩,只能坐等他人喂食。
好了,让我们先从一块 js 代码,开始我们的探索之旅:
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 5000);console.log('No. 2');
输出结果是:
No. 1No. 2setTimeout callback
这块代码中几乎没什么复杂的东西,全是打印语句。唯一的特别是函数 setTimeout ,根据粗略的网上资料显示,它接受两个参数:
- 第一个参数是 callback 函数,就是让它执行完之后,回过头来调用的函数。
- 另一个是时间参数,用于指定多少微妙之后,执行 callback 函数。这里我们使用了5000微妙,也即是5秒钟。
另一个重点是,setTimeout 是一个异步函数,意思是我的主程序不必去等待 setTimeout 执行完毕,将它的运行过程扔到别的地方执行,然后主程序继续往下走。也即是,主程序是一个步调、setTimeout 是另一个步调,即是“异步”的方式跑代码。
如果你有一些并行计算或者多线程编程的背景知识,那么上面的语句就再熟悉不过了。如果在多线程环境,无非是另起一根线程去运行打印语句 console.log('setTimeout callback') 。然后主线程继续往下走,新线程去负责打印语句,清晰明了。
所以综合起来,这段代码的意思是,主线程执行到语句 setTimeout 时,就把它交给“其它地方”,让这个“其它地方”等待5秒钟之后运行。而主线程继续往下走,去执行“No. 2”的打印。所以,由于其它部分要等待5秒钟之后才运行,而主线程立刻往下运行了“No. 2”的打印,最终的输出结果才会是先打印“No. 2”,再打印“setTimeout callback”。
嗯,so far so good。一切看来都比较美好。
如果我们对上述程序做一点变动呢?例如,我可不可以让“setTimeout callback”这个信息先被打印出来呢?因为在并行计算中,我们经常遇到的问题便是,由于你不知道多个线程之间谁执行得快、谁执行得慢,所以我们无法判定最终的语句执行顺序。这里我们让“setTimeout callback”停留了5秒钟,时间太长了,要不短一点?
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 1);console.log('No. 2');
我们将传递给 setTimeout 的参数改成了1毫秒。多次运行后会发现,结果竟然没有改变?!似乎有点反常,要不再改小一点?改成0?
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 0);console.log('No. 2');
多次运行后,发现依旧无法改变。这其实是有点奇怪了。因为通常的并行计算、多线程编程中,通过多次运行,你其实是可以看到各种无法预期的结果的。在这里,竟然神奇地得到了相同的执行顺序结果。这就反常了。
但我们还无法完全下一个肯定的结论,可不可能因为是 setTimeout 的启动时间太长,而导致“No. 2”这条语句先被执行呢?为了做进一步的验证,我们可以在“No. 2”这条打印语句之前,加上一个 for 循环,给 setTimeout 充分的时间去启动。
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 0);for (let i = 0; i < 10e8; i++) { }console.log('No. 2');
运行这段代码,我们发现,”No. 1”这条打印语句很快地显示到了浏览器命令行,等了一秒钟左右,接着输出了:
No. 2setTimeout callback
诶?!这不就更加奇怪了吗?!setTimeout 不是等待0秒钟后立刻运行吗,就算启动再慢,也不至于等待一秒钟之后,还是无法正常显示吧?况且,在加入这个 for 循环之前,“setTimeout callback”这条输出不是立刻就显示了吗?
综合这些现象,我们有理由怀疑,似乎“setTimeout callback”一定是在“No. 2”后显示的,也即是:setTimeout 的 callback 函数,一定是在 console.log('No. 2') 之后执行的。为了验证它,我们可以做一个危险一点的测试,将这个 for 循环,更改为无限 while 循环:
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 0);while {} // dangerouse testingconsole.log('No. 2');
如果 setTimeout 的 callback 函数是按照自己的步调做的运行,那么它就有可能在某个时刻打印出“setTimeout callback”。而如果真的是按照我们猜测的那样,“setTimeout callback”必须排在“No. 2”之后,那么浏览器命令行就永远不会出现“setTimeout callback”。
运行后发现,在浏览器近乎要临近崩溃、达到内存溢出的情形下,“setTimeout callback”依旧没有打印出来。这也就证明了我们的猜测!
这里,我们第一次出现了理念和现实的矛盾。按照通常并行计算的理念,被扔到“其它地方”的 setTimeout callback 函数,应该被同时运行。可事实却是,这个“其它地方”并没有和后一条打印“No. 2”的语句共同执行。这时候,我们就必须要回到基础,回到 js 这门语言底层的实现方式上去追查,以此来挖掘清楚这后面的猫腻。
js 的特性之一是“单线程”,也即是从头到尾,js 都在同一根线程下运行。或许这是一个值得调查深入的点。想来,如果是多线程,那么 setTimeout 也就该按照我们原有的理念做执行了,但事实却不是。而这两者的不同,便在于单线程和多线程上。
找到了这个不同点,我们就可以更深入去思考一些细节。细想起来,所谓“异步”,就是要开辟某个“别的地方”,让“别的地方”和你的主运行路线一起运行。可是,如果现在是单线程,也就意味着计算资源有且只有一份,请问,你如何做到“同时运行”呢?
这就好比是,如果你去某个办事大厅,去缴纳水费、电费、天然气。那么,我们可以粗略地将它们分为水费柜台、电费柜台、天然气柜台。那么,如果我们依次地“先在水费柜台办理业务,等到水费的明细打印完毕、缴纳完费用后;再跑去电费柜台打印明细、加纳费用;再跑去天然气柜台打印明细、加纳费用”,这就是一个同步过程,必须等待上一个步骤做完后,才能做下一步。
而异步呢,就是说我们不必在某个环节浪费时间瞎等待。比如,我们可以在“打印水费明细”的空闲时间,跑到电费和天然气柜台去办理业务,将“电费明细、天然气明细的打印”这两个任务提前启动起来。再回过头去缴纳水费、缴纳电费、缴纳天然气费用。其实,这就是华罗庚推广优选法的时候举的例子,烧水、倒茶叶、泡茶,如何安排他们的顺序为高效。
显然,异步地去做任务更高效。但这要有一个前提,就是你做任务的资源,也即是干活的人或者机器,得有多份才行。同样按照上面的例子来展开讨论,虽然有水费、电费、天然气这三个柜台,可如果这三个柜台背后的办事人员其实只有一个呢?比如你启动了办理水费的业务,然后想要在办理水费业务的等待期,去电费柜台办理电费业务。表面上,你去电费柜台下了申请单,请求办理电费业务,可却发现根本没有办事员去接收你的这个业务!为何?因为这有且只有一个的办事员,还正在办理你的水费业务啊!这时候,你的这个所谓的“异步”,有何意义?!
所以从这个角度来看,当计算资源只有一份的时候,你做“异步”其实是没什么意义的。因为干活的资源只有一份,就算在表面做了名义上的“异步”,可最终就像上面的多柜台单一办事员那样,到了执行任务层面,还是会一个接一个地完成任务,这就没有意义了。
那么,js的特性是”单线程“+”异步“,不就正是我们讨论的“没有意义”的情况吗?!那又为何要多次一举,干一些没有意义的事情呢?
嗯……事情变得越来越有趣了。
通常来讲,如果一个事件出现了神奇和怪异的地方,基本上都是因为我们忽略了某个细节,或者对某个细节存在误解或是错误理解。要想把问题解决,我们就必须不断地回顾已有材料,在不断地重复检验中,发现那几根我们忽略的猫腻。
让我们回顾一下关于js异步的宣传片。通常为了说明js异步的必要性,会举出浏览器的资源加载和页面渲染这个矛盾:
渲染,可以比较粗糙地理解为将“画面”画出来的过程。例如,浏览器要将页面上的按钮、图片显示出来,就必须有一个将“图片”在网页上画出来的动作。又或是,操作系统要将“桌面”这个图形界面显示在显示器上,就必须要把它相应的这个“画面”在显示器上画出来的动作。归结起来,这个“画出来”的过程,就被称之为“渲染”。
例如,你点击页面上的一个 button,让浏览器去后端数据库将数据报表取出来,在网页上把数字显示出来。而如果 js 不支持异步的话,整个网页的就会停留,也即是“卡”,在鼠标点击按钮这一个动作上,页面无法完成后续的渲染工作。一直要等到后端把数据返回到了前端,程序流才能够继续跑下去。
所以这里,js 的“异步”其实是为了让浏览器将“加载”这个任务分给“其它地方”,让“加载过程”和“渲染过程”同步进行下去。
等等,又是这个“其它地方”?!!
我擦,不是说 js 是单线程而么,计算资源不是只有一份么,怎么又可以“一边加载、一边渲染”了?!WTF,你这是在逗我玩儿么?!
艹,到底这里面哪句话是真的?!到底js是单线程是真的?还是说浏览器可以同时做“一边加载、一边渲染”这个事情是真的?!
如何才能解决这个疑惑?!很显然,我们必须要深入到浏览器的内部,去看一看它到底是怎么样被设计的。
在搜索引擎中,做一些关于浏览器和js的搜索,我们不难得到一些基本信息。js 并不是浏览器的全部,浏览器要掌管的事情太多了,掌管 js 的只是浏览器的一个组件,叫做 js 引擎。而最出名的、并在 Chrome 中使用的,就是大名鼎鼎的 V8 引擎,它负责 js 的解析和运行。
另一方面我们还知道,使用js的一个很大原因,是因为它能够自由地去操控 DOM 元素、去执行 Ajax 异步请求、能够像我们最开始举的例子那样,使用 setTimeout 做异步任务分配。这些都是 js 优秀特性。
可令人惊讶的事情来了,当我们去探索这个掌管 js 一切的 V8 引擎的时候,我们却发现,它并不提供 DOM 的操控、Ajax 的执行以及 setTimeout 的特性:
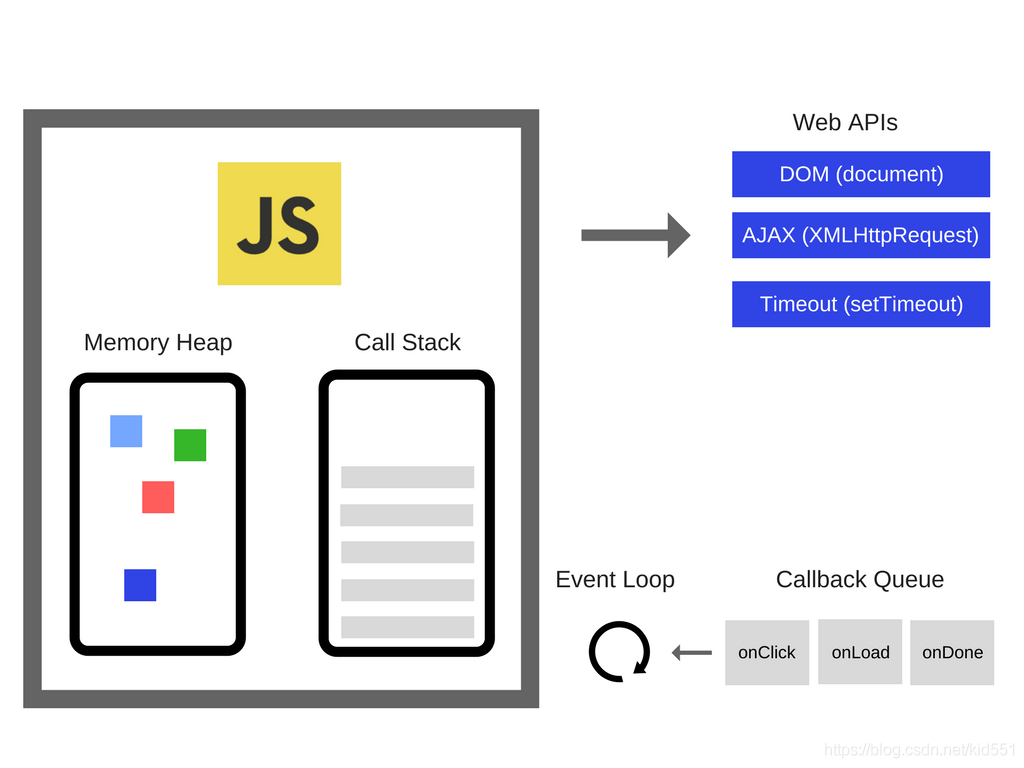
上图来自 Alexander Zlatkov,它的结构是:
- JS引擎
- Memory Heap
- Call Stack
- Web APIs
- DOM (Document)
- Ajax (XMLHttpRequest)
- Timeout (setTimeout)
- Callback Queue
- Event Loop
明明是 js 的特性,为什么这些职能却不是由 js 的引擎来掌管呢?嗯,interesting~~~
诶!不是“单线程”么,不是加载过程被扔到其它地方么?!js 是单线程,也即是 js 在 js 引擎中是单线程、只能够分到一份计算资源,可是,加载数据的 Ajax 这个 feature 不是没有被放到 js 引擎么?!
艹!真TM是老狐狸啊!还以为“单线程”和“一边加载、一边渲染”这两种说法只有一种是对的,可结果是,都对!为什么呢?因为只说了 js 是单线程,可没说浏览器本身是单线程啊!所以咯,渲染相关的 js 部分可以和数据加载的 Ajax 部分是可以同时进行的,因为它们根本就在两个模块,即两个线程嘛!所以当然可以并行啊!WTF!
诶~等等,让我们再仔细看看上面这张图呢?!Ajax 不在 js 引擎里,可是 setTimeout 也不在 js 引擎里面啊!!如果 Web APIs 这部分是在不同于 js 引擎的另外一根线程里,它们不就可以实现真正意义上的并行吗?!那为何我们开头的打印信息“setTimeout callback”,无法按照并行的方式,优先于“No. 2”打印出来呢?
嗯……真是 interesting……事情果然没有那么简单。
显然,我们需要考察更多的细节,特别是,每一条语句在上图中,是按照什么顺序被移动、被执行的。
谈到语句的执行顺序,我们需要再一次将关注点放回到 js 引擎上。再次回看上面这幅结构图,JS 引擎包含了两部分:一个是 memory heap,另一个是 call stack。前者关于内存分配,我们可以暂时放下。后面即是函数栈,嗯,它就是要进一步理解执行顺序的东西:
函数栈(call stack)为什么要叫做“栈(stack)”呢?为什么不是叫做函数队列或者别的神马?这其实可以从函数的执行顺序上做一个推断。
函数最开始被引进,其实就是为了代码复用和模块化。我们期望一段本该出现的代码,被单独提出来,然后只需要用一个函数调用,就可以将这段代码的执行内容给插入进来。
所以,如果当我们执行一段代码时,如果遇到了函数调用,我们会期望先去将函数里面的内容执行了,再跳出来回到主程序流,继续往下执行。
所以,如果把一个函数看作函数节点的话,整个执行流程其实是关于函数节点的“深度优先”遍历,也即是从主函数开始运行的函数调用,整个呈深度优先遍历的方式做调用。而结合算法和数据结构的知识,我们知道,要实现“深度遍历”,要么使用递归、要么使用stack这种数据结构。而后者,无疑更为经济使用。
所以咯,既然期望函数调用呈深度优先遍历,而深度优先遍历又需要stack这种数据结构做支持,所以维护这个函数调用的结构就当然呈现为stack的形式。所以叫做函数栈(stack)。
当然,如果再发散思考一下,操作系统的底层涌来维护函数调用的部分也叫做函数栈。那为何不用递归的方式来实现维护呢?其实很简单,计算机这么个啥都不懂的东西,如何知道递归和返回?它只不过会一往无前的一直执行命令而已。所以,在没有任何辅助结构的情况下,能够一往无前地执行的方式,只能是stack,而不是更为复杂的递归概念的实现。
另一方面,回到我们最开头的问题,矛盾其实是出现在 setTimeout 的 callback 函数上。而上面的结构图里,还有一部分叫做“callback queue”。显然,这一部分也是我们需要了解的东西。
结合 js 的 call stack 和 callback queue 这两个关键词,我们不难搜索到一些资料,来展开讨论这两部分是如何同具体的语句执行相结合的。
先在整体上论述一下这个过程:
- 正常的语句执行,会一条接一条地压入 call stack,执行,再根据执行的内容继续压入 stack。
- 而如果遇到有 Web APIs 相关的语句,则会将相应的执行内容扔到 Web APIs 那边。
- Web APIs 这边,可以独立于 js 引擎,并行地分配给它的语句,如 Ajax 数据加载、
setTimeout的内容。 - Web APIs 这边的 callback function,会在在执行完相关语句后,被扔进“callback queue”。
- Event loop 会不断地监测“call stack”和“callback queue”。当“call stack”为空的时候,event loop 会将“callback queue”里的语句压入到 stack 中,继续做执行。
- 如此循环往复。
以上内容比较抽象,让我们用一个具体的例子来说明。这个例子同样来自于 Alexander Zlatkov。使用它的原因很简单,因为 Zlatkov 在 blog 中使用的说明图,实在是相当清晰明了。而目前我没有多余的时间去使用 PS 绘制相应的结构图,就直接拿来当作例子说明了。
让我们考察下面的代码片段:
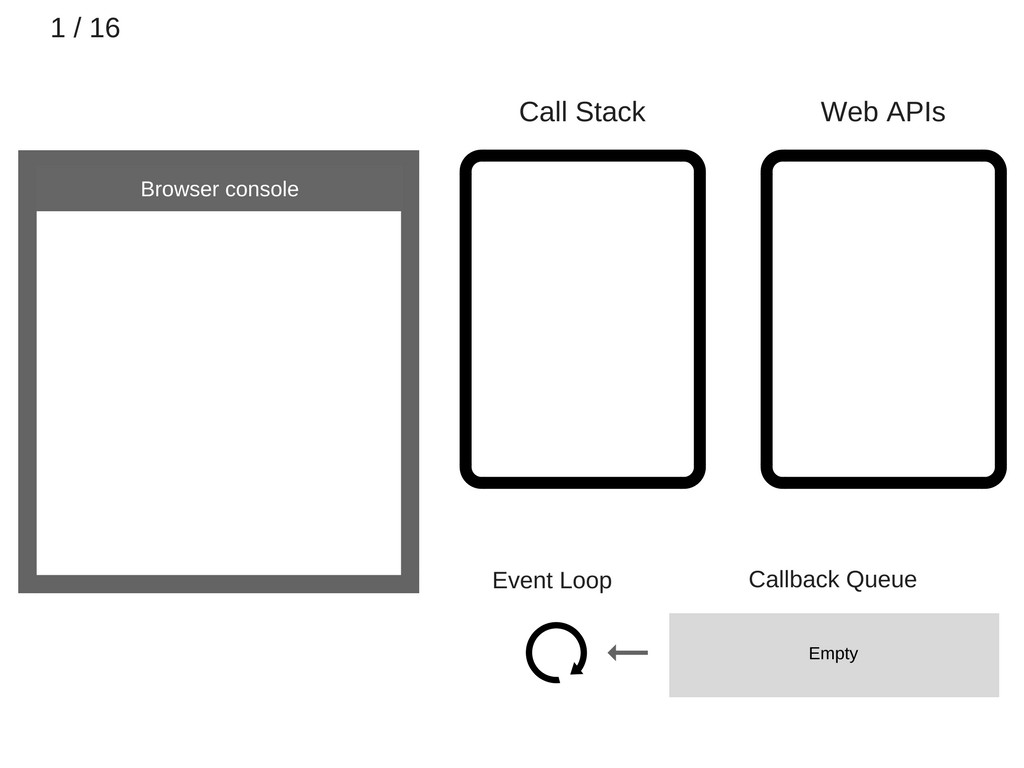
console.log('Hi');setTimeout(function cb1() {console.log('cb1');}, 5000);console.log('Bye');
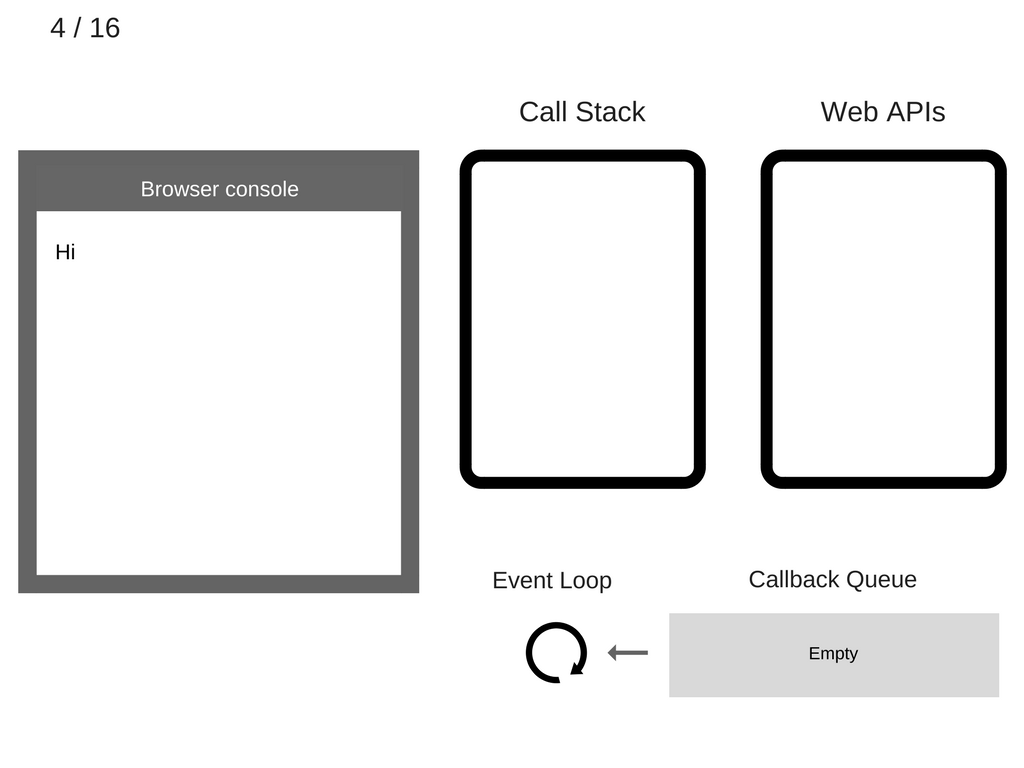
哈哈,其实和我们使用的代码差不多,只是打印的内容不同。此时,在运行之前,整个底层的结构是这样的:
然后,让我们执行第一条语句 console.log('Hi'),也即是将它压入到 call stack 中:
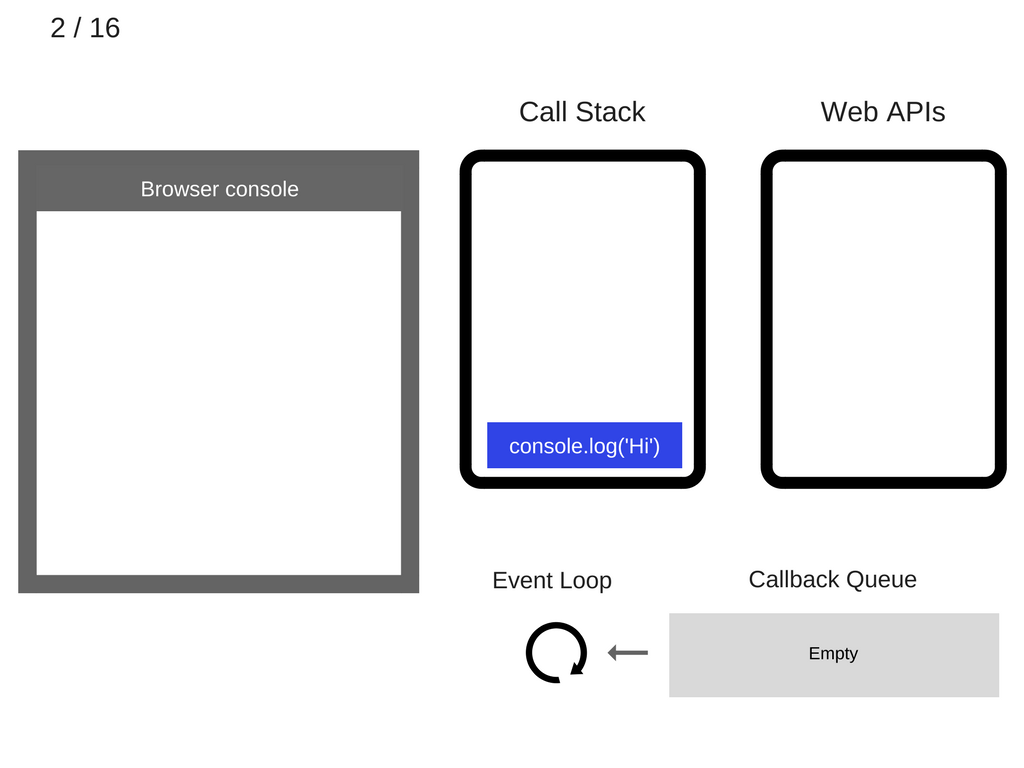
然后 js 引擎执行 stack 中最上层的这条语句。相应的,浏览器的控制台就会打印出信息“Hi”:
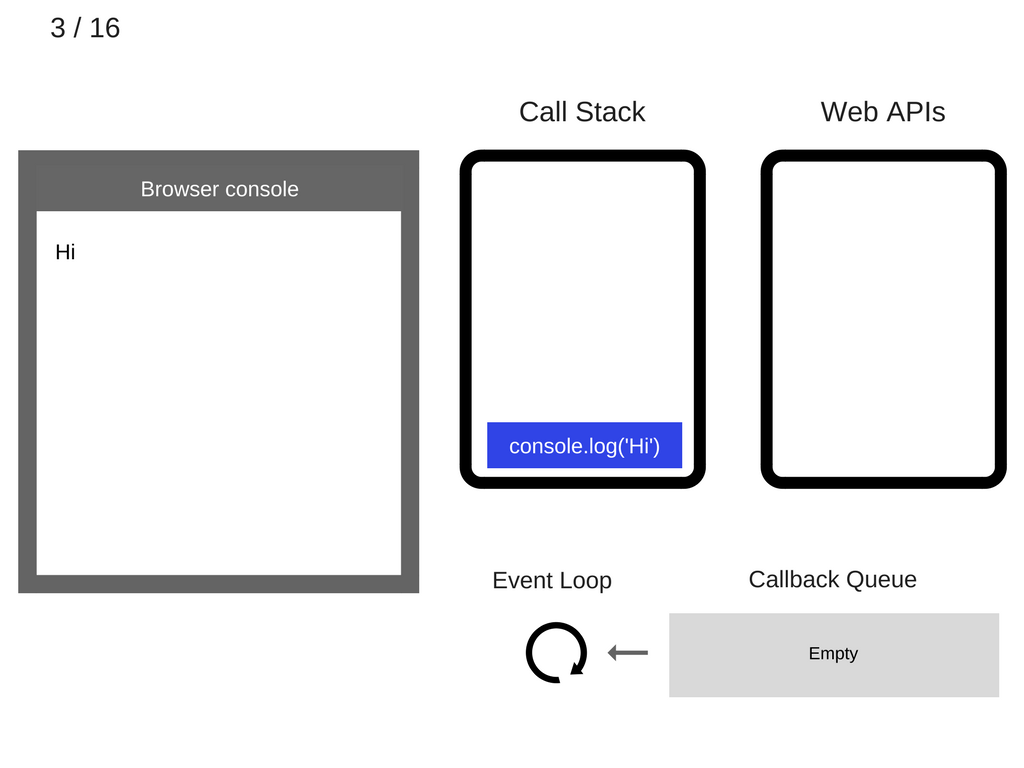
由于这条语句被执行了,所以它也从 stack 中消失:
再来压入第二条语句 setTimeout:
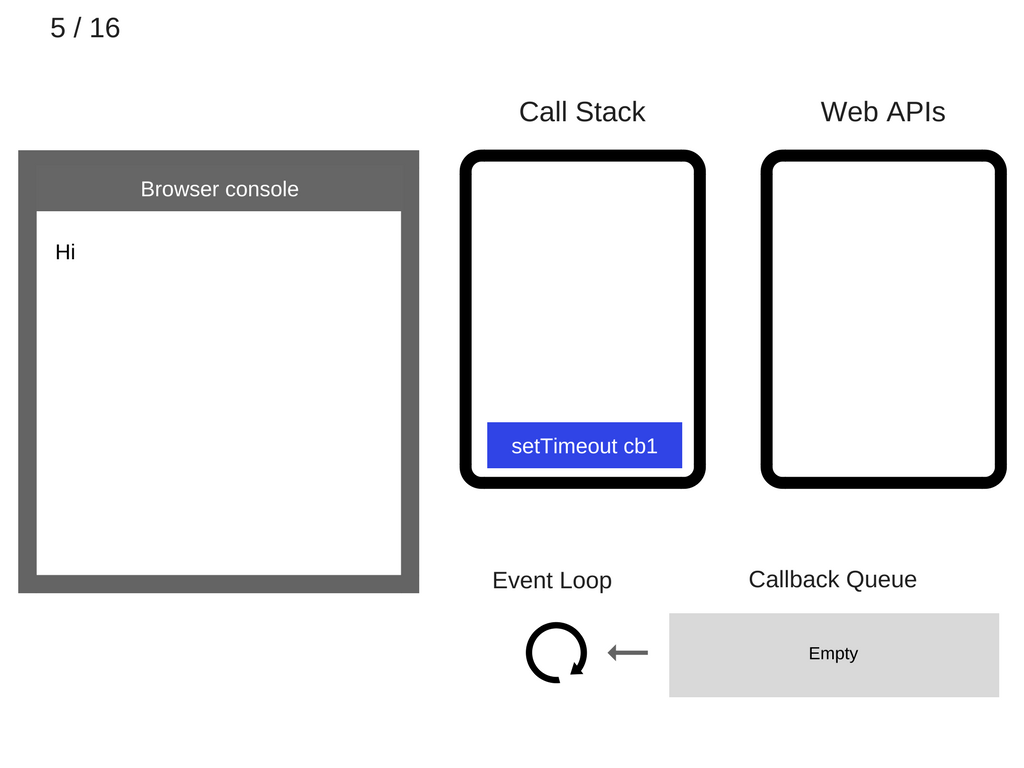
执行 setTimeout(function cb1() { console.log('cb1'); }, 5000);:
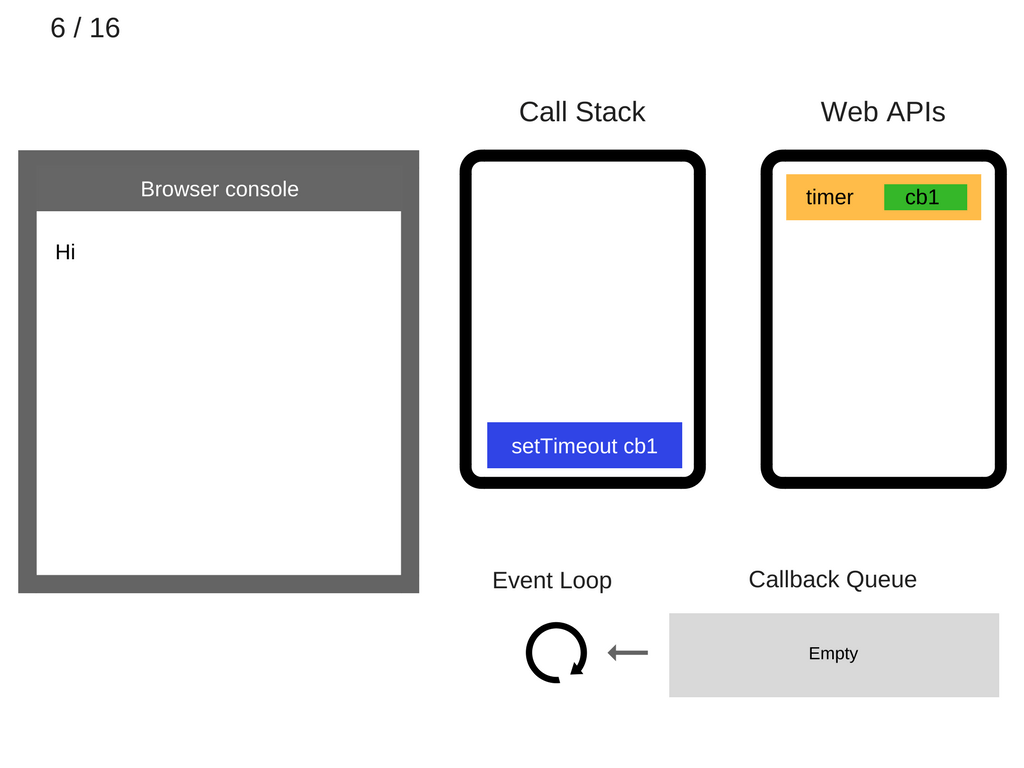
注意,由于 setTimout 部分并没有被包含在 js 引擎中,所以它就直接被扔给了 Web APIs 的 Timeout 部分。这里,stack 中的蓝色部分起到的作用,就是将相应的内容“timer、等候时间5秒、回调函数cb1”扔给 Web APIs。然后这条语句就可以从 stack 中消失了:
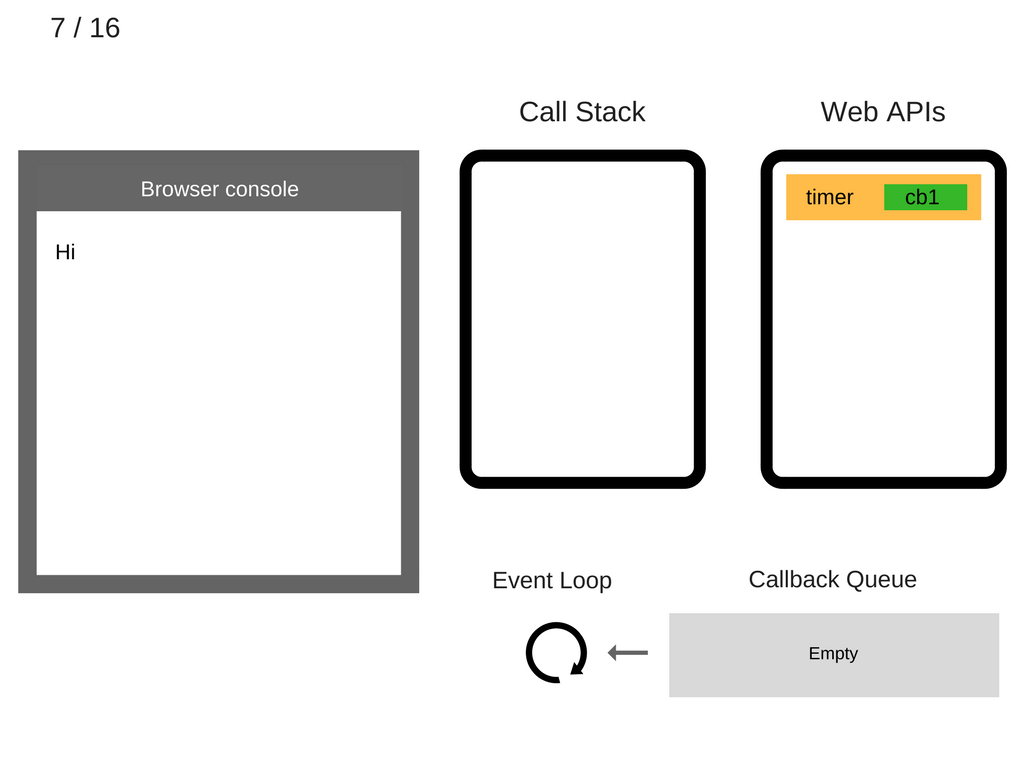
继续压入下一条语句 console.log('Bye'):
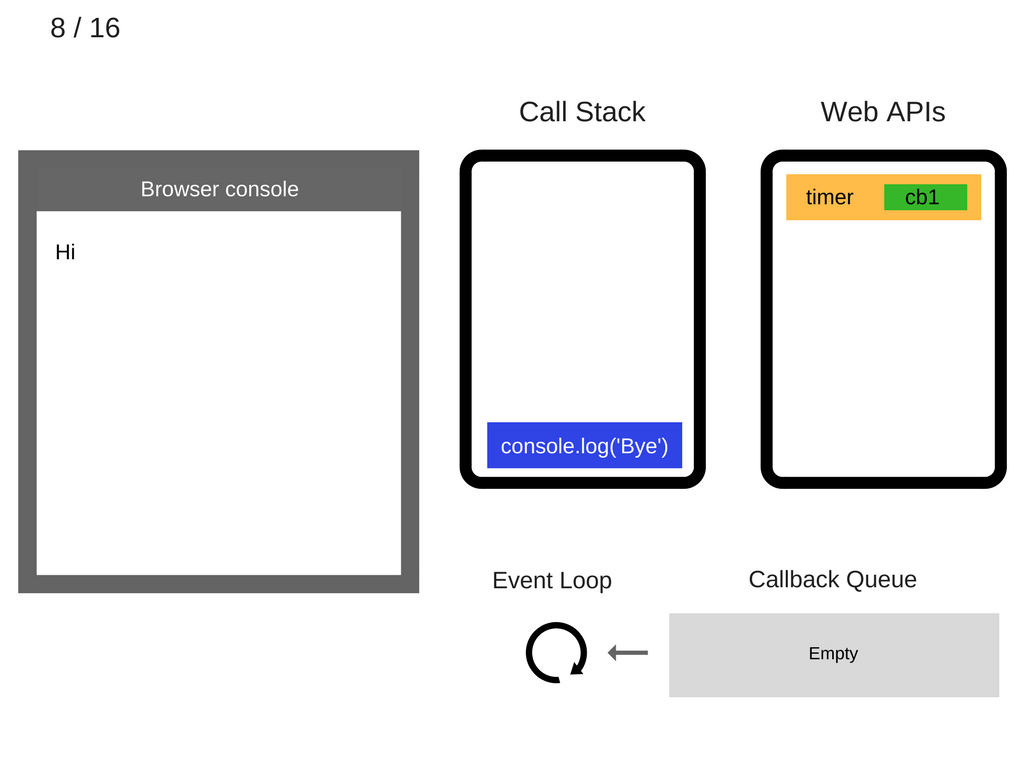
注意,此时在 Web APIs 的部分,正在并行于 js 引擎执行相应的语句,即:等候5秒钟。Okay,timer 继续它的等待,而 stack 这边已经有语句了,所以需要把它执行掉:
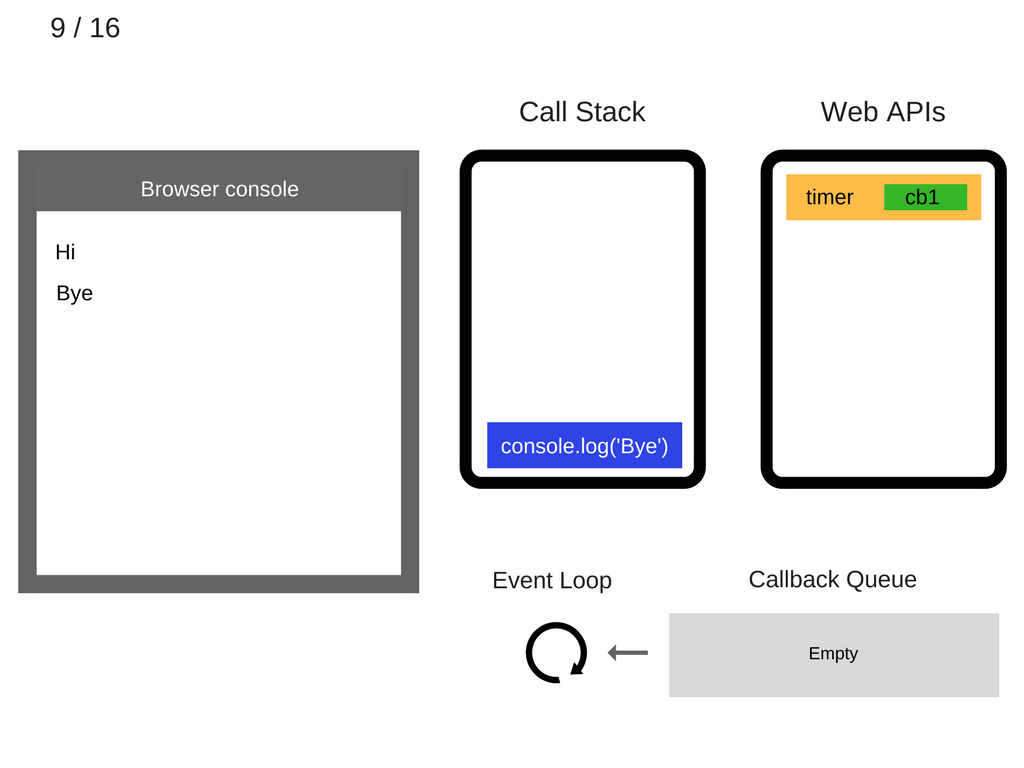
相应的浏览器控制台,就会显示出“Bye”的信息。而 stack 中运行后的语句,就该消失:
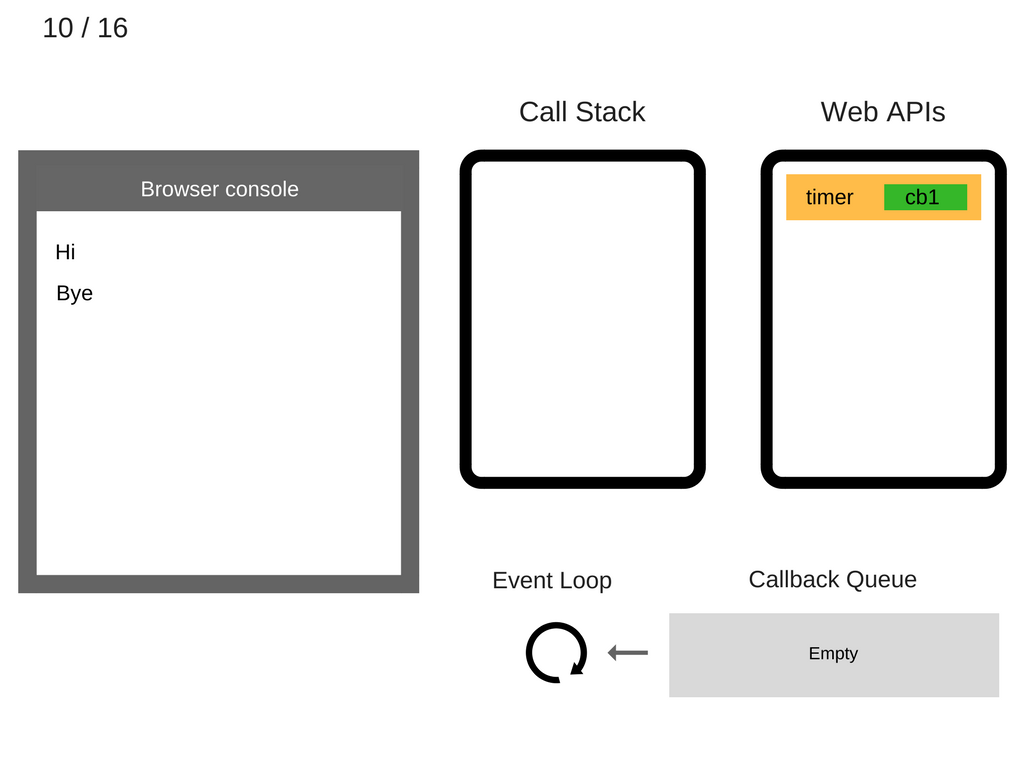
此时,stack 已经为空。Event loop 检测到 stack 为空,自然就想要将 callback queue 中的语句压入到 stack 中。可此时,callback queue 中也为空,于是 Event loop 只好继续循环检测。
另一方面,Web APIs 这边的 timer,并行地在5秒钟后开始了它的执行——什么也不做。然后,将它相应的回调函数 cb1(),放到 callback queue 中:
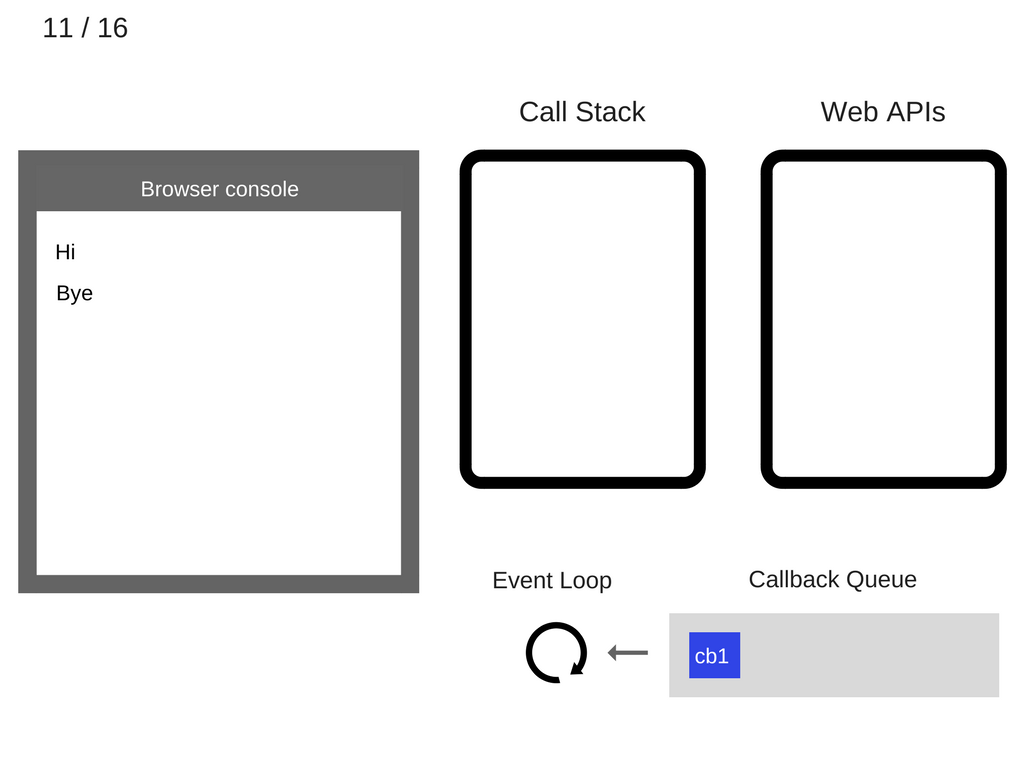
Event loop 由于一直在循环检测,此时,看到 callback queue 有了东西,就迅速将它从 callback queue 中取出,然后将其压入到 stack 里:
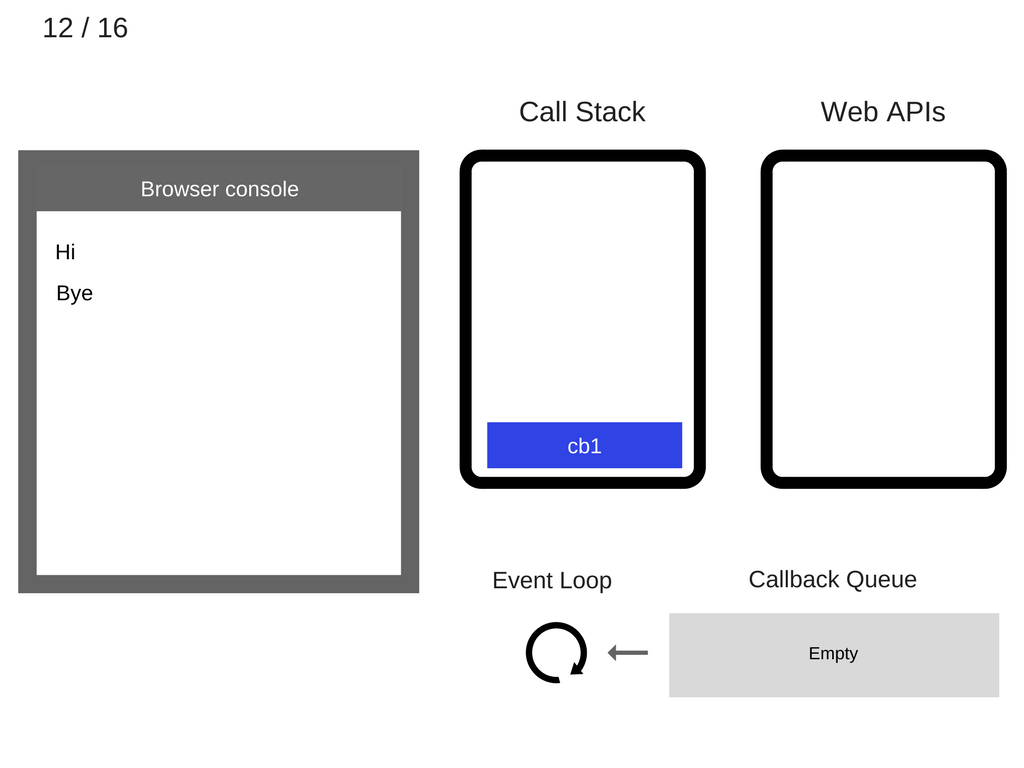
现在 stack 里有了东西,就需要执行回调函数 cb1()。而 cb1() 里面调用了 console.log('cb1') 这条语句,所以需要将它压入 stack 中:
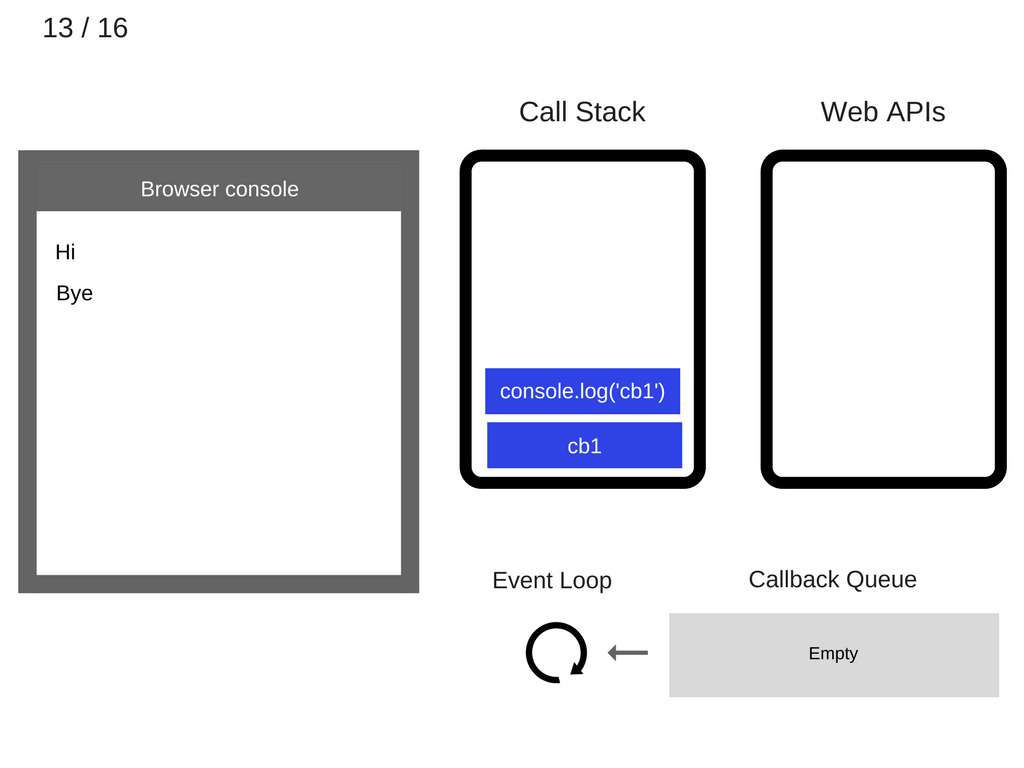
stack 继续执行,现在它的最上层是 console.log('cb1'),所以需要先执行它。于是浏览器的控制它打印出相应的信息“cb1”:
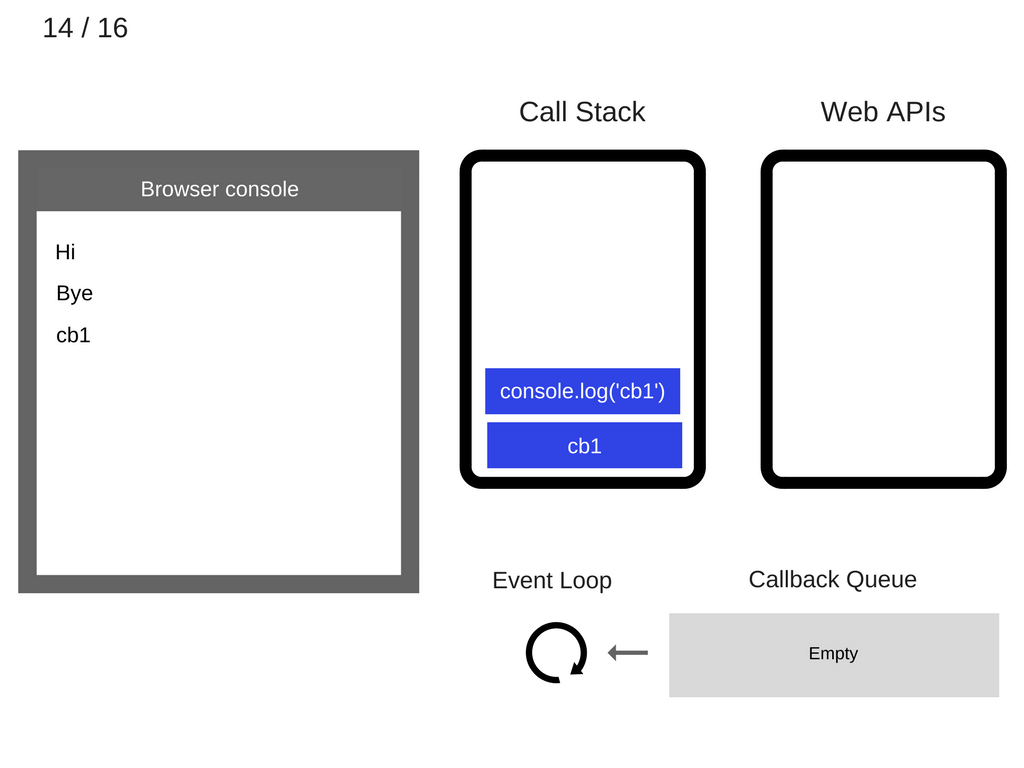
将执行了的 console.log('cb1') 语句弹出栈:
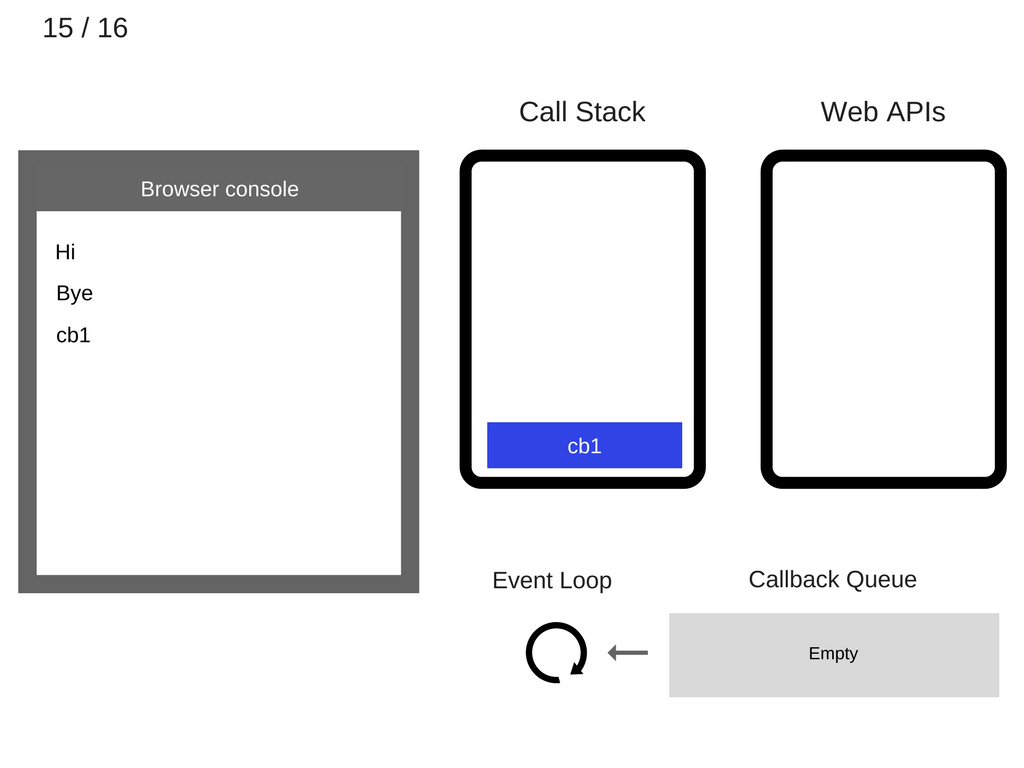
继续执行 cb1() 剩下的语句。此时,cb1() 已经没有其它需要执行的语句了,也即是它被运行完毕,所以,将它也从 stack 中弹出:
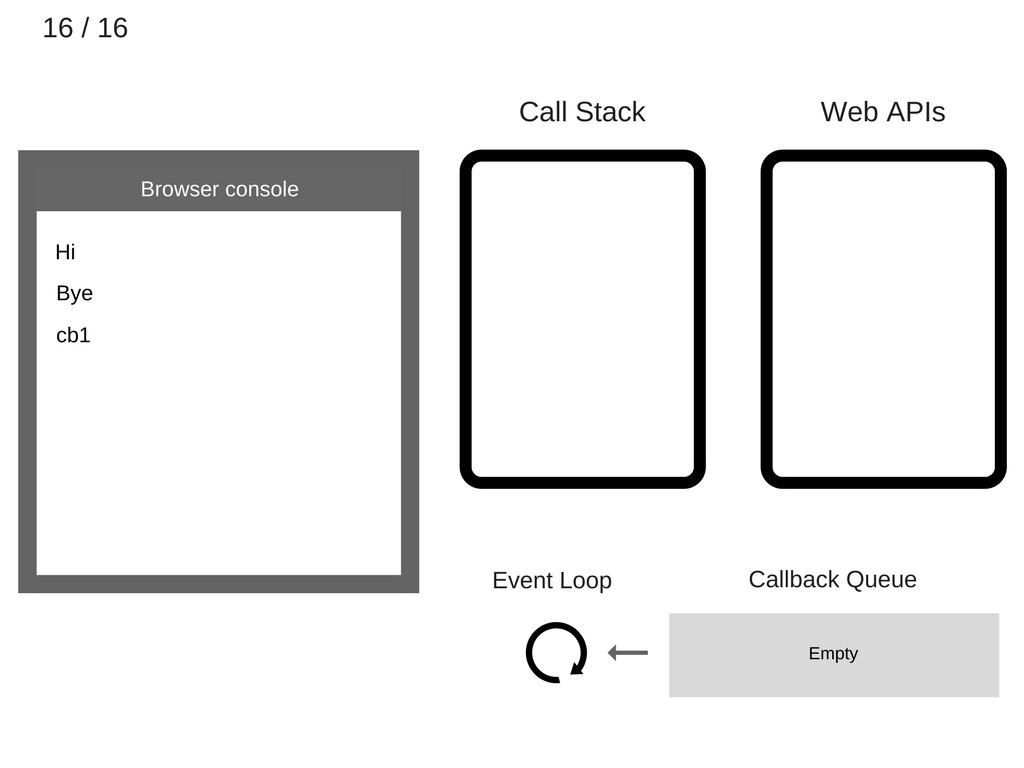
整个过程结束!如果从头到尾看一遍的话,就是下面这个 gif 图了:
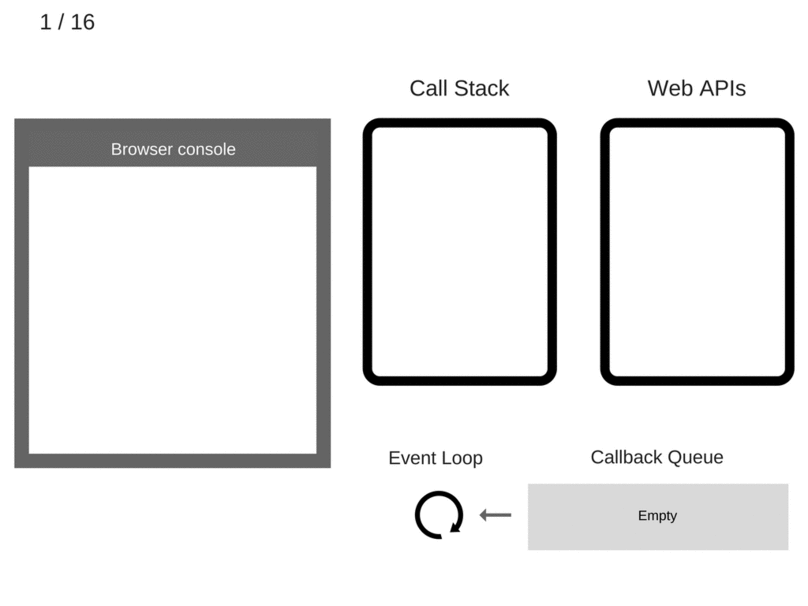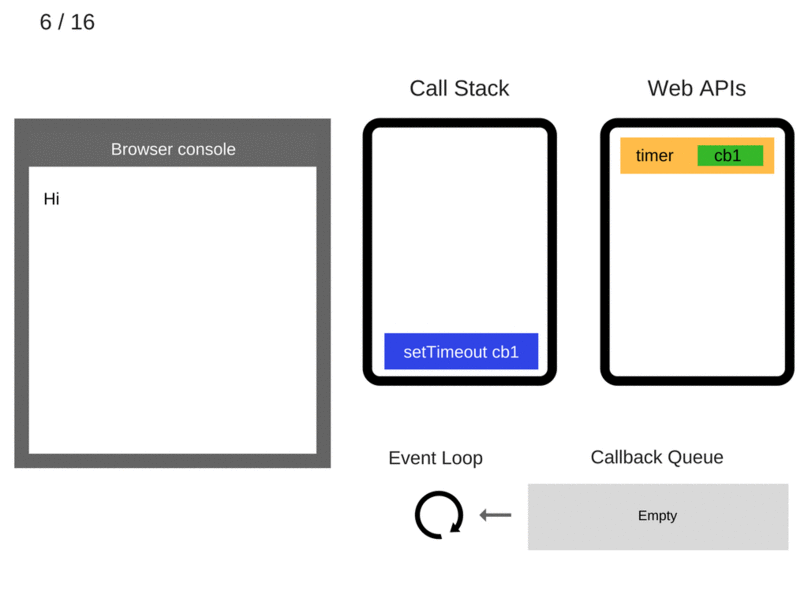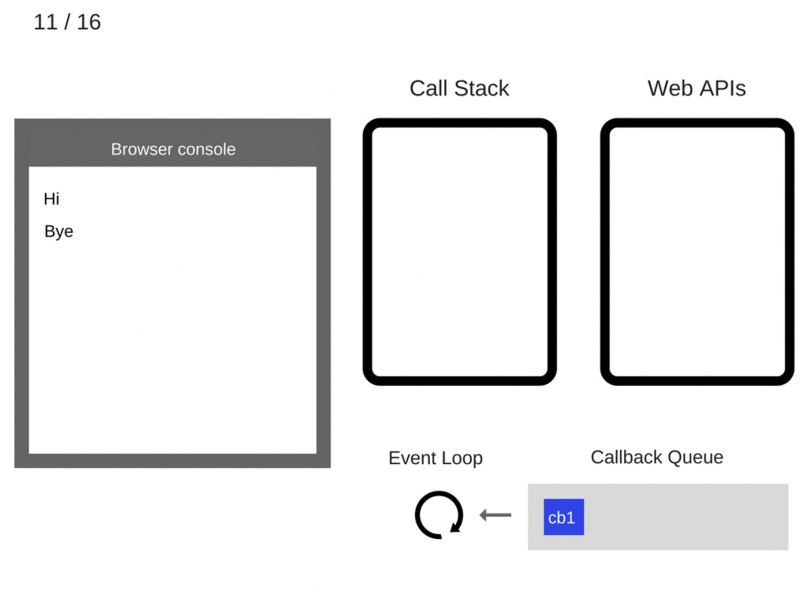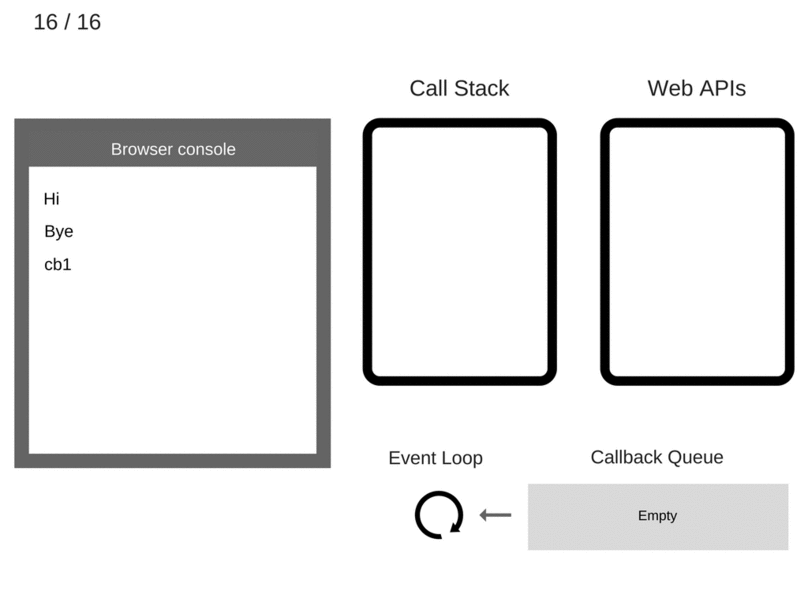
相当清晰直观,对吧!
如果你想进一步地把玩 js 的语句和 call stack、callback queue 的关系,推荐 Philip Roberts 的一个 GitHub 的开源项目:Loupe,里面有他 online 版本供你做多种尝试。
有了这些知识,现在我们回过头去看开头的那段让人产生疑惑的代码:
console.log('No. 1');setTimeout(function () {console.log('setTimeout callback');}, 0);console.log('No. 2');
按照上面的 js 处理语句的顺序,第一条语句 console.log('No. 1') 会被压入 stack 中,然后被执行的是 setTimout。
根据我们上面的知识,它会被立刻扔进 Web APIs 中。可是,由于这个时候我们给它的等待时间是0,所以,它的 callback 函数 console.log('setTimeout callback') 会立刻被扔进“Callback Queue”里面。所以,那个传说中的“其它地方”指的就是 callback queue。
那么,我们能够期望这一条 console.log('setTimeout callback') 先于“No. 2”被打印出来吗?
其实是不可能的!为什么?因为要让它被执行,首先它需要被压入到 call stack 中。可是,此时 call stack 还没有将程序的主分支上的语句执行完毕,即还有 console.log('No. 2') 这条语句。所以,event loop 在 stack 还未为空的情况下,是不可能把 callback queue 的语句压入 stack 的。所以,最后一条“setTimeout callback”的信息,一定是会排在“No. 2”这条信息后面被打印出来的!
这完全符合我们之前加入无限 while 循环的结果。因为主分支一直被 while 循环占有,所以 stack 就一直不为空,进而,callback queue 里的打印“setTimeout callback”的语句就更不可能被压入 stack 中被执行。
探索到这里,似乎该解决的问题也都解决了,好像就可以万事大吉,直接封笔走人了。可事实却是,这才是我们真正的泛化讨论的开始!
做研究和探索,如果停留于此,就无异于小时候自己交作业给老师,目的仅仅是完成老师布置的任务。在这里,这个老师布置的任务就是文章开头所提出的让人疑惑的代码。可是,解决这段代码并不是我们的终极目的。我们需要泛化我们的所学和所知,从更深层次的角度去探索,为什么我们会疑惑,为什么一开始无法发现这些潜藏在表面之下不同。我们要继续去挖掘,我们到底在哪些最根本的问题上出现了误解和错误认识,从而导致我们一路如此辛苦,无法在开头看到事情的真相。
回顾我们的历程,一开始让我们载跟斗的,其实就是对“异步”和“多线程”的固定假设。多线程了,就是异步,而异步了,一定是多线程吗?我们潜意识里是很想做肯定回答的。这是因为如果异步了,但却是单线程,整个异步就没有意义了(回忆那个多柜台、单一办事员的例子)。可js却巧妙地运用了:使用异步单线程去分配任务,而让真正做数据加载的 Ajax、或者时间等待的 setTimeout 的工作,扔给浏览器的其它线程去做。所以,本质上 js 虽然是单线程的,可在做实际工作的时候,却利用了浏览器自身的多线程。这就好比是,虽然是多柜台、单一办事员,可办事员将缴纳电费、水费的任务,外包给其它公司去做,这样,虽然自己仍然是一个办事员,但却由于有了外包服务的支持,依旧可以一起并行来做。
另一方面,js 的异步、单线程的特性,逼迫我们去把并行计算中的“同步/异步、阻塞/非阻塞”等概念理得更清楚。
“同步”的英文是 synchronize,但在中文的语境下,却很容易和“同时”挂钩。于是,在潜意识里有可能会有这样一种联想,“同步”就是“同时”,所以,一个同步(synchronize)的任务就被理解为“可以一边做 A,一边做 B”。而这个潜意识的印象,其实完全是错误的(一般做 A一边做 B,其实是“异步”+“并行”的情况)。
但在各类百科词典上,确实有用“同时”来作为对“同步”的解释。这是为什么呢?其实这是对”同步“用作”同时“的一个混淆理解。如果仔细考虑”同时“的意思,细分起来,其实是有两种理解:
- 同一个时刻(at the same time),例如在 9:00 a.m 这个时间点,我们既在做 A 也在做 B。
- 另一个是同一个时间参考系,也就是所谓的 clock on the wall 是同一个。
前者很容易理解,这里我重点解释一下后者。例如,我在中国大陆同美国的一个同学开微信语音聊天,我这边是22:00,他那边是9:00。我们做聊天这件事情的时候,是同一时刻(at the same time),但却不在同一个时间参考体系(clock on the wall)。而在计算机中讨论的同步,其实讨论的是后者的”同一参考系“,同步,就是让我们的参考系统一起来,放到同一个体系之下。
又比如,我们在生活中很容易说,同步你的电脑、同步你的手机通讯录、同步你的相册,说的是什么呢?就是让你的各个客户端:PC、手机,同 server 端服务器的内容都保持一致,也即是大家都被放到一个一致的参考系里面。不要说,你在 PC 里有照片 A,而在手机里没有 A 却有 B,这个时候,谈论 PC 里信息人与谈论手机里信息的人,就是在鸡同鸭讲。究其原因,就是没有把大家放到同一个参考系里面。
所以,同步 synchronize 所指的”同时“,是大家把墙上的时钟都调整到一致、调整为同一个步调,也即是同时、同一时间参考系的意思。而不是说,让事情在同一时刻并列发生。自然的,什么是异步(asynchronize)呢,异步就是大家的时间参考系是不同的,例如我在中国大陆、你在美国,我们的时间参考体系是不同的,这就是异步,不在同一个步调、频段上。
事实上,每一个独立的人、每一块独立的计算资源,它都代表了一个各自的参考体系。只要你将任务分发给了其他人或是其它计算资源,此时,就出现了两个参考体系:一个是原有主分支的参考体系,另一个是新的计算资源的参考体系。在并行计算中,有一个同步机制是使用语句 barrier,目的是让所有的计算分支在这一个位置节点都完成了计算。为什么说它是一种同步机制?按照我们统一参考体系的理解,就是保证其他所有计算分支完成计算,也就保证了其它分支的消失,从而只剩下主分支这一个参考体系。于是大家可以谈论同样的东西,说同样的话,不会有误解。
另一方面,如果要更深入地理解 js 的设计,我认为还需要回到计算机历史的初期,例如那个只有单核的分时系统的时代。在那样一个时代,操作系统所受到的硬件上的限制,不亚于 js 引擎在浏览器中所受到的限制。在同样的限制下,曾经的操作系统会如何去巧妙运用那极为有限的计算资源,让整个操作系统给人以平滑、顺畅和功能强大的错觉?我想,js 的这些设计必定和操作系统早期的设计紧密相关。
所以在这个层面上,它将再一次回到操作系统这样的基础知识上。能否吃透现代的技术,其实很大层面上取决于你是否吃透了设计的历史,是否理解在那些资源枯竭的年代,各路大神是如何巧妙地逢山开路,遇水搭桥。无论现代的计算机硬件资源有多么丰富,它必定会因为目标的主次关系、业务的主次关系受到限制。而如何在限制中跳舞和创造,这是能够贯穿整个历史的共同性问题。
Reference__:
- How JavaScript works: Event loop and the rise of Async programming + 5 ways to better coding with async/await
- asynchronous vs non-blocking
- 非同步(Asynchronous)與同步(Synchronous)的差異
- Philip Roberts: What the heck is the event loop anyway? | JSConf EU
如果你喜欢我的文章或分享,请长按下面的二维码关注我的微信公众号,谢谢!

更多信息交流和观点分享,可加入知识星球:

若有收获,就点个赞吧
0 人点赞
