对应的 GeekArtT 视频讲义,可查看:https://b23.tv/qwSAI6
ElasticSearch 作为开源的搜索引擎,需要依赖的一个重要数据结构就是 inverted index(倒排索引)。inverted index 通常庞大、且建立过程相当耗时,于是,如何存储 inverted index 就变成了一件极为要紧的事情。
显然,inverted index 不能简单地被放在 memory 中,它还必须做对应的持久化,让这些已经建立的 inverted index 可以被复用。ElasticSearch 是基于 Lucene 来构建的,在 Lucene 的世界里,inverted index 就是存放于 disk 的一块 immutable 的 segment。
于是,关于 ElasticSearch inverted index 的存放问题,就转换为了「如何能够高效地存储 disk 文件 segment」。
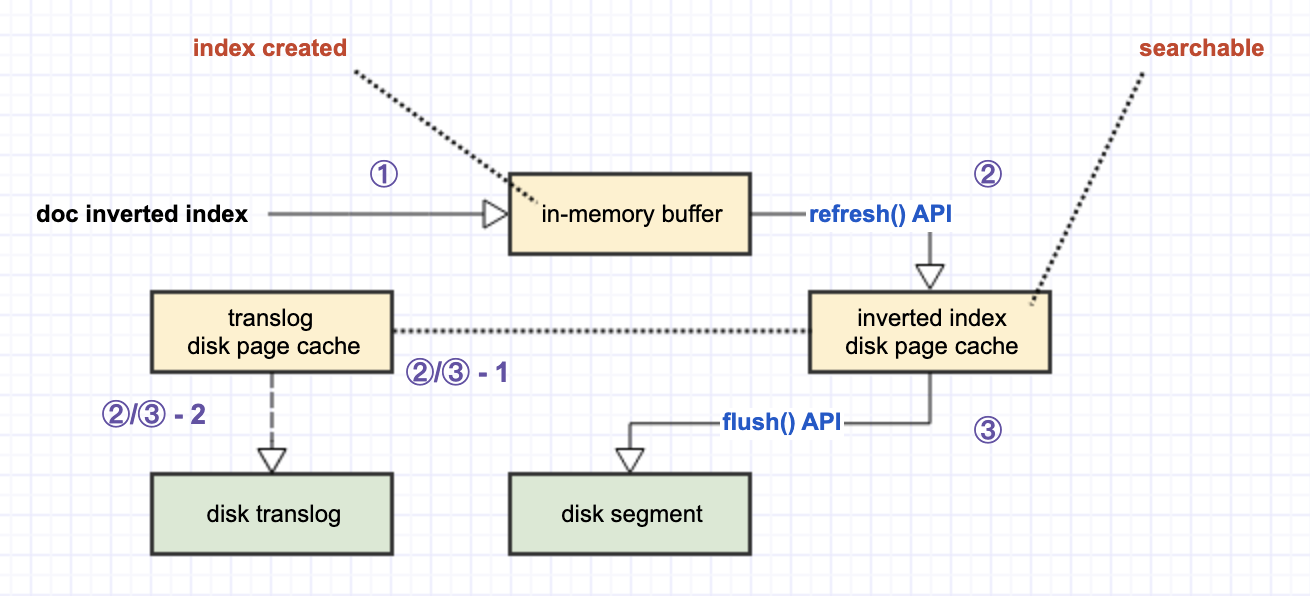
既然是 disk file,那么最直观的优化方式便是使用 memory 来做批量堆积,通过累积 data batch 来节省 disk I/O overhead。于是,ElasticSearch 引入了 in-memory buffer 来暂存每个 doc 对应的 inverted index。当这些 doc inverted index 累积到一定量后,就可以从 in-memory buffer 刷到 disk 了。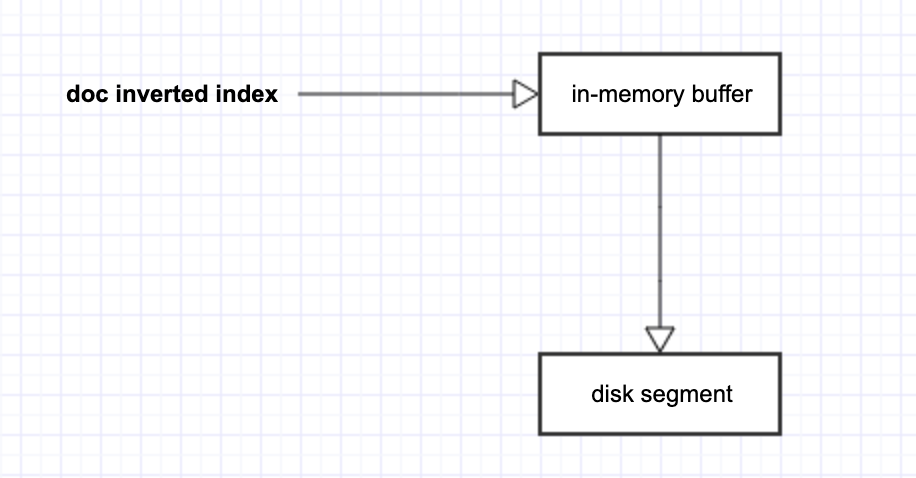
另一方面,在 Lucene 的世界里,一切「搜索」行为,都依赖于 disk segment,没有 disk segment 就没有对应的「可搜索」。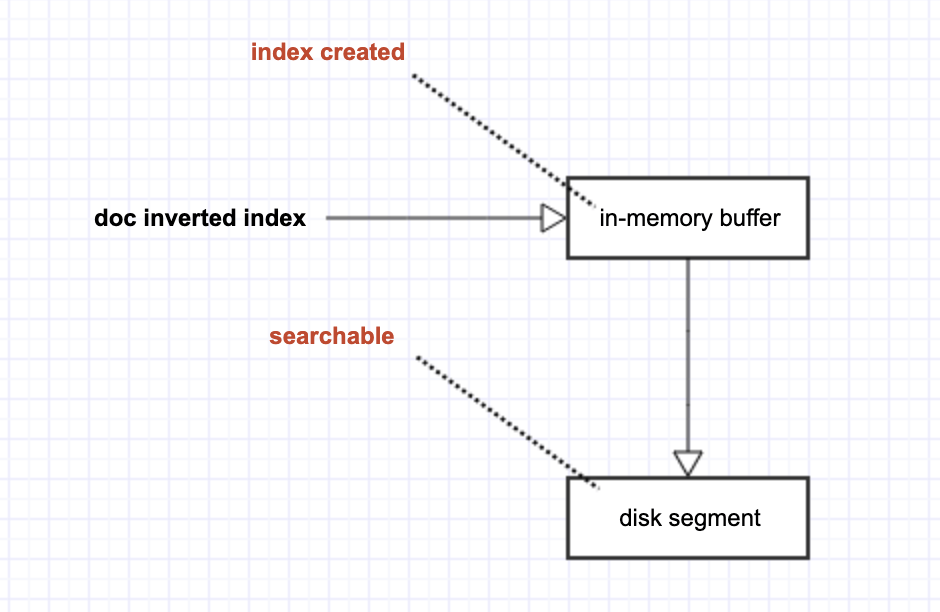
如此,如上图所示,「索引的创建」和「索引的可搜索」之间出现了 time gap(这是 ElasticSearch 被称为 near realtime search engine 的原因)。显然,我们的下一个目标,就是要尽可能地缩短这个 time gap。
一个立刻能被联想到的工具是 OS(operating system)提供的 disk page cache。disk page cache 也是 OS 为了优化 disk I/O 所做出的努力,其指导思想同 ElasticSearch 引入 in-memory buffer 是一样的,都是希望通过 data 的批量累积,来尽可能地减少 disk I/O。
但 disk page cache 不同与用户自己创建的 memory buffer 的地方是,一旦 data 被放入了 disk page cache,它对整个 OS 来讲,从“概念上”就可以被当做是一个真正的 disk file 了(虽然它实际不是,还在 memory 中)。于是,放入 disk page cache 的 inverted index,自然就可以被当做是 disk segment,对于 ElasticSearch 来讲,它就是「可搜索」的!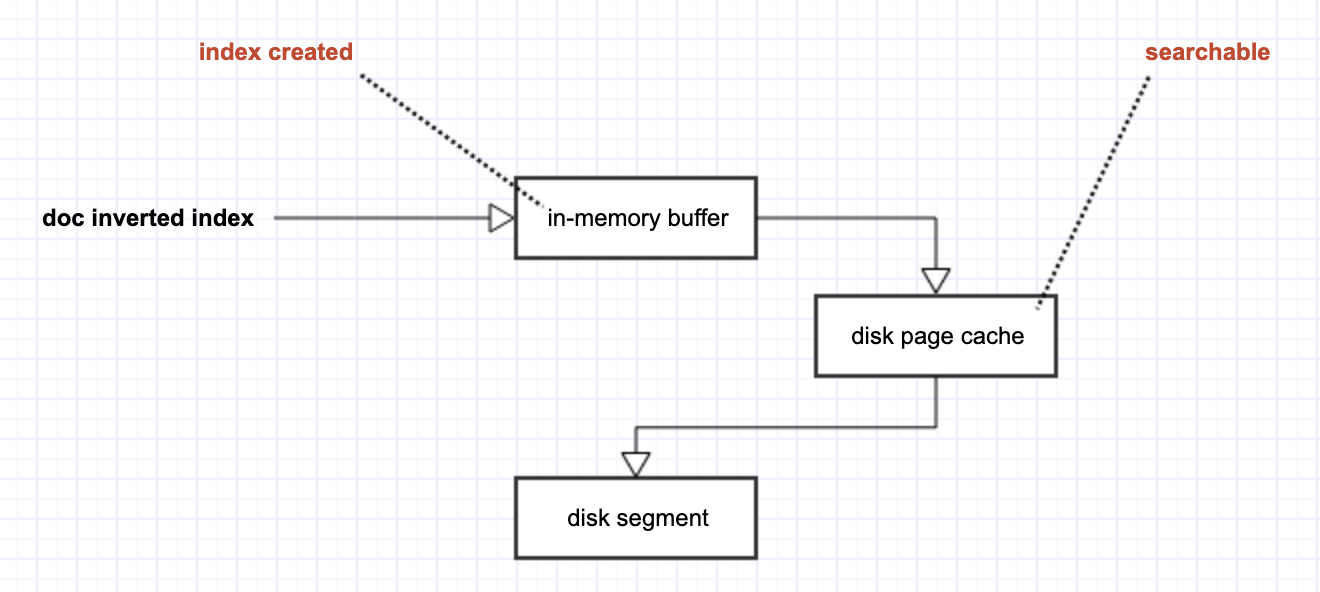
并且,由于 disk page cache 毕竟是在 memory 中,从 in-memory buffer 到 disk page cache 所需要的时间,将会远远少于从 in-memory buffer 到 disk segment 的时间。
于是,通过引入 disk page cache,我们缩短了 ElasticSearch 从「创建索引」到「索引可搜索」的时间,也即是让它更接近于 realtime。引入了 disk page cache 之后的两段 data pipeline,分别对应了 ElasticSearch 的两个重要 API:
- 从 in-memory buffer 到 disk page cache 的过程,对应 ElasticSearch 的
refresh()API,默认 1s 触发一次; - 从 disk page cache 到 disk 的过程,则对应 ElasticSearch 的
flush()API,默认 30min 触发一次。

在这样的结构下,我们不禁要问,如果 disk page cache 的内容还未被 flush 到 disk,而此时所在的 server 出现了 power off 等极端异常情况,那么这部分保存于 disk page cache 的 data 是否会丢失?!
当然是会的!
于是,ElasticSearch 又引入了 disk page cache 的一个临时 disk backup:translog,用于持久化当前 disk page cache 中的内容。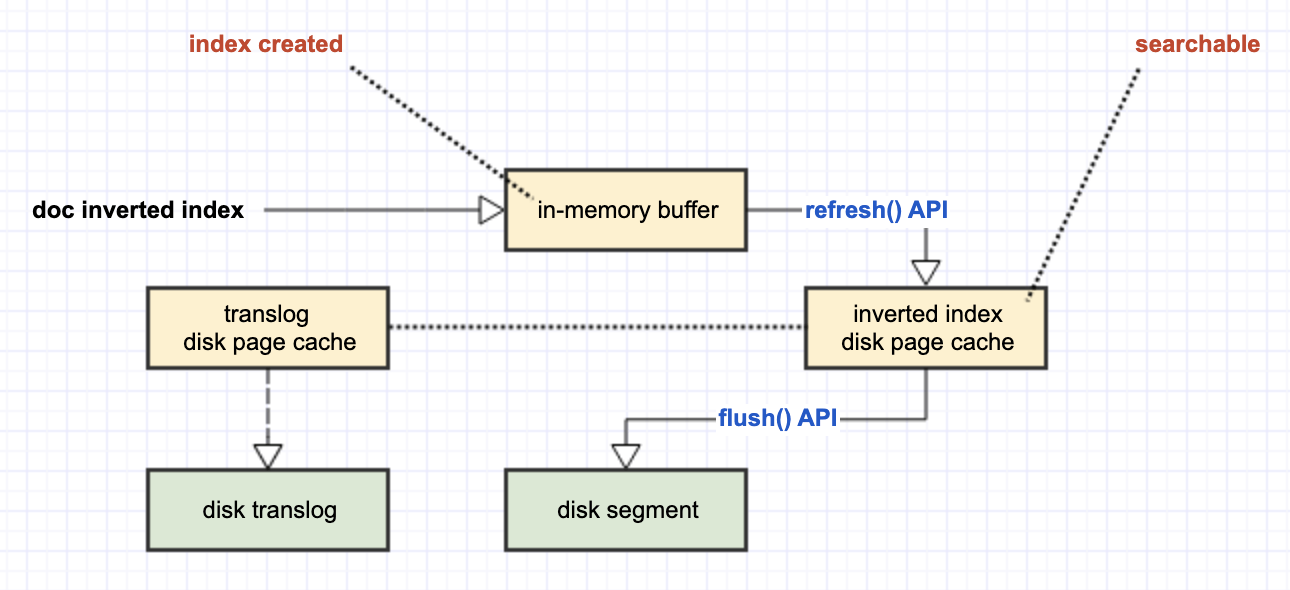
可以看到,虽然 translog 的本意是将 disk page cache 中的 inverted index 做持久化备份,但它自己作为 OS 的 file,同样需要经历 disk page cache(translog 的 disk page cache,而不是 inverted index 的 disk page cache)到 disk 的过程。默认 translog 自己从 disk page cache 到 disk 的持久化,是 5s 一次。
由于 translog 仅仅是 inverted index 在 disk page cache 的临时备份,当 ElasticSearch 触发了 flush() API 时,对应的 translog 就会被清空。因为它临时部分的 data 在此时已经被真正持久化到了 disk,于是就不再需要这个临时的 disk backup 了。
如此,ElasticSearch 就将 data lost 减低到 translog 的 5s,即:最多可能会丢失 5s 的数据。
幸运的是,ElasticSearch 还有 replica node 这样的 data backup,即便是在某个 node 上丢失了 5s 的数据,还能够从其它的 replica node 上将数据取回来。于是这就进一步降低了 data lost 的概率(当然,理论上还是存在 data lost 的可能性,但只要降低到工程上可接纳的概率之下就可以了。工程上永远没有百分之百的保障,只有可接受的精度范围)。
如此,我们便将整个 ElasticSearch 的机制给传串起来了。整个机制围绕着如何高效地存储 disk segment 来展开:
- 为了降低 disk I/O 的 overhead,引入了 in-memory
- 为了降低「创建索引」和「索引可搜索」的 time gap,而引入了 disk page cache。
- 为了对 disk page cache 做临时备份,而引入了 translog
在技术的学习中,我们往往会面临各种繁杂的「知识点」,它们既不容易记忆,也不利于我们掌握其背后的宏观 intuition。于是,探寻出一条满足人类认知规律、以极少的假设推演出其它部分的路径,就成了要诀所在。
Remarks:
1、有的材料说 segment 应该是放在 memory 的,这种说法既是对的,又是错的。segment 作为存放 inverted index 的 data structure,显然是需要被持久化到 disk 的,所以本质上它无疑是 disk file。
但毕竟 ElasticSearch 对 segment 的使用非常频繁,如果一直做 disk I/O 来读取 inverted index 将会是极其低效的。所以 ElasticSearch 使用 mmap 来将 inverted index 映射到 memory 中,以加速对 inverted index 的访问。
2、那为什么不直接使用 mmap 来缩短 create index 到 index searchable 的过程呢?
这个问题就涉及到:mmap 和 disk page cache 都可以加速 disk file 的访问,那么它们各自在什么样的情境下,会更具优势呢?
这个问题要比想象中微妙得多,可参考 GeekArtT 的另一篇文章《mmap 和 disk I/O 在不同情形下的性能分析》。

若有收获,就点个赞吧
0 人点赞
