1️⃣ 进一步限制 loader 的应用范围
思路是:对于某些库,不使用 loader
例如:babel-loader 可以转换 ES6 或更高版本的语法,可是有些库本身就是用 ES5 语法书写的,不需要转换,使用 babel-loader 反而会浪费构建时间
lodash 就是这样的一个库
lodash是在ES5之前出现的库,使用的是ES3语法
通过 **module.rule.exclude** 或 **module.rule.include**,排除或仅包含需要应用loader的场景
module.exports = {module: {rules: [{test: /\.js$/,exclude: /lodash/, // 排除 lodash 库 有些会设置排除 /none_modules/use: "babel-loader"}]}}
如果暴力一点,甚至可以排除掉**node_modules**目录中的模块,或仅转换**src**目录的模块
module.exports = {module: {rules: [{test: /\.js$/,exclude: /node_modules/,// 或 include: /src/,use: "babel-loader"}]}}
这种做法是对loader的范围进行进一步的限制,和noParse不冲突,想想看,为什么不冲突
1️⃣ 缓存 loader 的结果
我们可以基于一种假设:如果某个文件内容不变,经过相同的 loader 解析后,解析后的结果也不变
于是,可以将 loader 的解析结果保存下来,让后续的解析直接使用保存的结果**cache-loader** 可以实现这样的功能
module.exports = {module: {rules: [{test: /\.js$/,use: ['cache-loader', ...loaders]},],},};
有趣的是,**cache-loader** 放到最前面,却能够决定后续的 loader 是否运行
实际上,loader 的运行过程中,还包含一个过程,即 **pitch**
cache-loader 还可以实现各自自定义的配置,具体方式见文档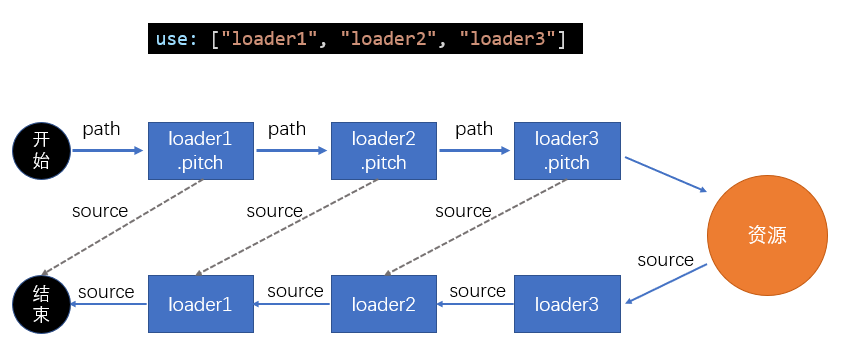
1️⃣ 为 loader 的运行开启多线程
**thread-loader**会开启一个线程池,线程池中包含适量的线程
它会把后续的 loader 放到线程池的线程中运行,以提高构建效率
由于后续的 loader 会放到新的线程中,所以,后续的 loader 不能:
1. 使用 webpack api 生成文件2. 无法使用自定义的 plugin api3. 无法访问 webpack options
在实际的开发中,可以进行测试,来决定
thread-loader放到什么位置
特别注意,开启和管理线程需要消耗时间,在小型项目中使用**thread-loader**反而会增加构建时间

若有收获,就点个赞吧
0 人点赞
