可用性测试 | 测试度量方法 (文末福利)
原创 ASAK ASAK设计 2022-06-30 08:30 发表于广东
目录
01 将用户表现转化为定量数据
02 使用标准化量表
03 制定优先级标准
01 将用户表现转化为定量数据
任务完成率
可记录完成任务的用户数,从而得出任务完成率。
一般性任务的完成条件比较明晰,但也可以给部分任务定义成功标准,比如增加事件限制等
EXAMPLE / 实例
|
| 用户1 | 用户2 | 用户3 | 用户4 | 用户5 | 完成率 | |
|---|---|---|---|---|---|---|
| 任务1 | 1 | 1 | 0 | 1 | 1 | 80% |
| 任务2 | 1 | 0 | 1 | 0 | 1 | 80% |
任务完成时间
任务时间即用户花费在一个任务上的时间,以往我们一般以均值的方式报告。可以配合任务完成率一起用
对于小样本量(样本量小于25),计算均值使用几何平均值最佳,比中位数和平均值有更少的错误和偏差
EXAMPLE / 实例
|
| 用户1 | 用户2 | 用户3 | 用户4 | 用户5 | 几何 平均值 |
|
|---|---|---|---|---|---|---|
| 任务1 | 198s | 220s | 136s | 162s | 143s | 168.85s |
其他评估指标
1)评估有效性
02 使用标准化量表
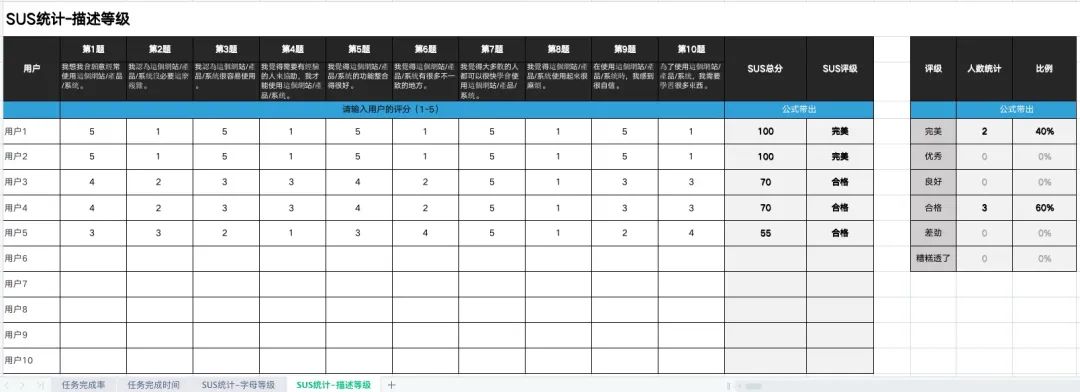
使用标准化问卷测量用户的主观满意度,推荐使用 (SUS System Usability Scale)软件可用性量表,适用于小样本量的场景。量表内容如下: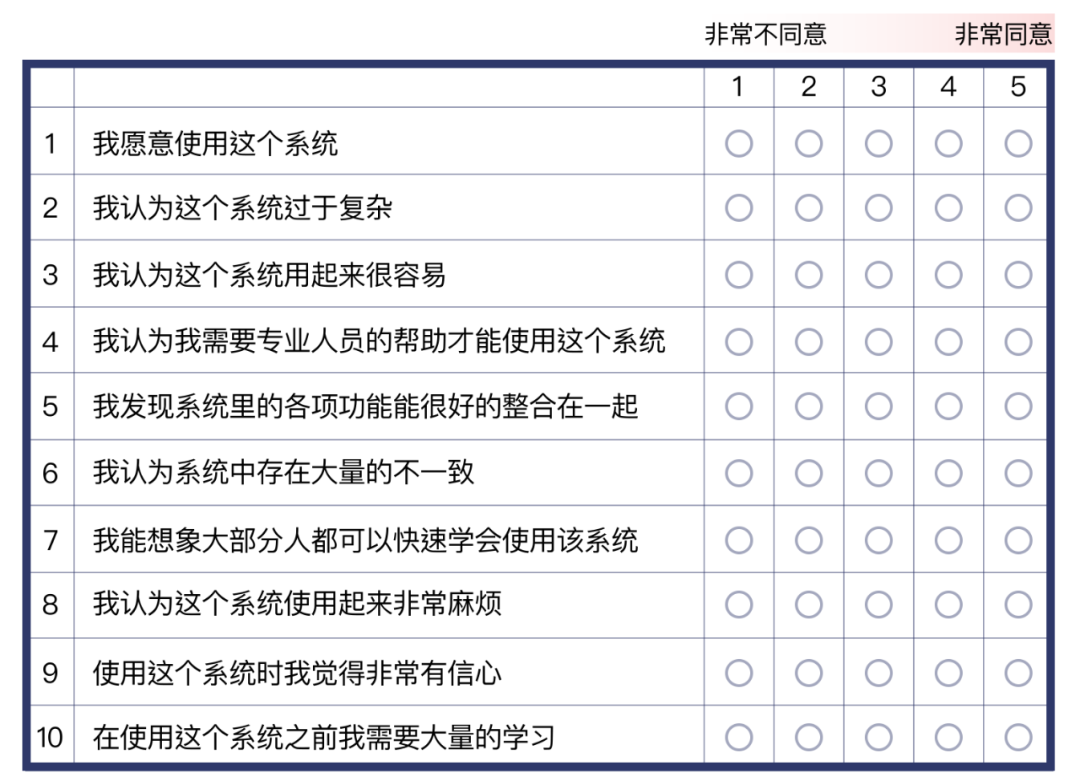
SUS分数计算方法
1)分值转化:
奇数项(正面描述题),分值转化=原始分-1
偶数项(反面描述题),分值转化=5-原始分
2)SUS量表总分=所有转化后的得分相加X2.5(乘2.5之后变为百分值)
(ps:文末可获取自动统计工具, 就不用自己计算啦)
就不用自己计算啦)
注意事项:
1)在使用产品之后填写
2)如果用户因为某些原因无法完成某个题目,那就视为用户在该题上选择了中间值
3)不要更改用词,但‘系统’这个词除外,“系统”替换成“网站、产品”或产品自身的名字等,对最后的分值没有影响
4)不收费,但任何公开出版的报告要对这个方法的来源致谢
5)10为易学性,信度系数0.7;1、2、3、5、6、7、8、9为可用性,信度系数0.91。 所以也可以变为简版,去掉4,10
SUS分数可以用来做什么?
1)用于评级
对应下图,可得出字母等级评级、描述性评级和可接受范围与SUS分数之间的关系,可助于向非专业人士解释SUS分数的结果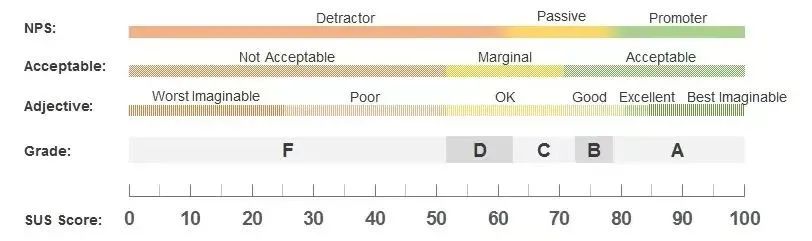
① 字母等级:A级: ≥90分 ; B级: ≥80分;C级: ≥70分;D级: ≥60分;F级: <60分
② 描述性评级:完美(Best Imaginable): 100分; 优秀(Excellent): 85-99分; 良好(Good): 73-84分;合格(OK):52-72分; 差劲(Poor): 39-51分; 糟糕透了(Worst Imaginable): 39分以下
③ 可接受范围:可以接受(Acceptable): 70分以上; 中立(Marginal): 50-70分;不可以接受(Not Acceptable): 50分以下
2)百分制等级
除此之外,也可以将SUS分数换算成百分等级来解释,百分等级的意思是指测量的产品或系统相对于总数据库里其他产品或系统的可用性程度。比如SUS得分是73分,其百分等级大约为67,意味着比大约66%的产品可用性更好
SUS分数的曲线分级范围
| SUV分数等级 | 评级 | 百分等级 |
|---|---|---|
| 80.8-84 | A | 96-100 |
| 80.8-84 | A | 90-95 |
| 78.9-80.7 | A- | 85-89 |
| 77.2-78.8 | B+ | 80-84 |
| 74.1-77.1 | B | 70-79 |
| 72.6-74 | B- | 65-69 |
| 71.1-72.5 | C+ | 60-64 |
| 65-71 | C | 41-59 |
| 62.7-64.9 | C- | 35-40 |
| 51.7-62.6 | D | 15-34 |
| 0-51.7 | F | 0-14 |
*这个表格是Jeff Sauro(2011)通过446个研究,超过5000个用户的SUS反馈的数据库。这个基准数据也可以由内部团队制定。
03 制定优先级标准
量化过程可分为三步:
1. 问题严重性评定
2. 问题发生频率评定
3. 计算优先级
问题严重性评定:
列出测试中出现的问题,并分别打分——4分制,评定标准见下表(例:用户在某页找不到某功能的入口,这个问题导致了一个严重的挫折,严重性分值为3分)
问题严重性评定表
| 严重程度评定标准 | 分值 |
|---|---|
| 这个问题是否妨碍任务完成: 1.用户放弃了任务 2.使用户产生了消极情绪 3.用户尝试5次及以上才完成 4.用户尝试10秒及以上才完成 |
4 |
| 这个问题是否导致了一个严重的延迟或挫折: 1.用户尝试了3-4次才完成 2.用户尝试了5-9秒才完成 |
| 3 | | 这个问题对任务绩效的影响是否相当小 | 2 | | 这个问题是否属于建议 | 1 |
*当多个用户表现得不一致时,若程度分最高的比例大于等于25%则按最高分计算,小于25%则按低级的分数计算。(例:某问题在2/5用户上体现为4分,在2/5用户上体现为2分,那就按4分算;如果在1/5用户上体现为4分,在2/5用户上体现为2分,那就按2分算)
问题发生频率评定:
评估每个问题在总样本中发生了几次——4分制,评定标准见下表
问题发生频率评定表
统计表格格式参考: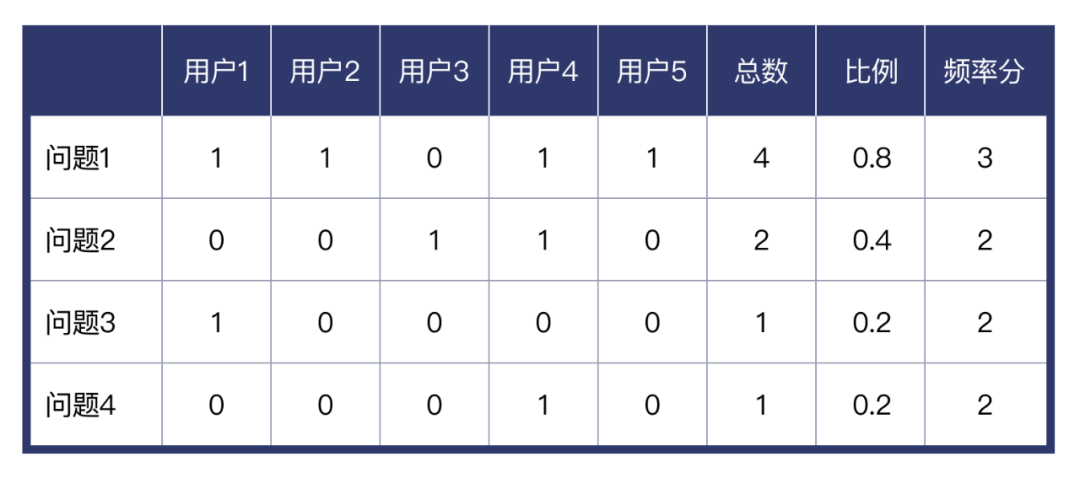
优先级评分计算:
优先级分数=严重程度分+频率程度分
故最高8分,最低2分
优先级评定表
|
| 影响程度评分 | 频率程度评分 | 优先级评分 | |
|---|---|---|---|
| 问题1 | 4 | 3 | 7 |
| 问题2 | 3 | 2 | 5 |
| 问题3 | 2 | 2 | 4 |
| 问题4 | 1 | 2 | 3 |
当然,文中介绍的是一种处理思路,大家可适当调整测试标准,使其更适用于实际情况。如进行加权处理,或是增加新的评定指标~
通过这些方法,可以将我们观察到的用户表现,转成量化的数据,使测试结果更加直观、具有说服力。快来试试吧
作者|皮皮 编辑|楠楠 封面|Jace
🎁 🎁 🎁
/ 本期福利 /
在本公众号后台回复 统计工具
即可获得 测试量表自动统计工具
↓ ↓ ↓
Hi, 我们是网易互娱ASAK设计团队
Astro x Akira

若有收获,就点个赞吧
0 人点赞
