1. 二叉树
1.1 不同的存储结构
- 数组存储方式
- 优点:通过下标方式访问元素,速度快。如果是有序数组,还可以通过二分查找等方法进行检索,效率高。
- 缺点:如果要检索某个具体的数(并且非有序数组),或者是插入某个值,效率低。(数组的特点,添加元素效率低(插入一个值后面的数据整体移动一位),并且可能面临数组扩容的问题(数组容量是固定的,如果超出上限,需要进行新建数组,并实现拷贝))
- 链式存储方式
- 优点:增、删、插入效率都高
-
1.2 概念
每个节点最多只能有两个子节点
- 完全二叉树
- 假设k层,除k层外所有节点的子节点都达到了饱和(都拥有两个子节点),k层所有节点连续集中排列在左边。
满树
前序
- 中序
-
1.4 实现
```java /**
- 参数:
- data
- 左右节点
- 方法:
- 构造器
- 前序遍历
- 中序遍历
- 后序遍历
- 遍历查找
- 删除节点 */ public class TreeNode { public int id; public String name; public TreeNode left; public TreeNode right;
// 1. 构造器 public TreeNode(int id, String name) {
this.id = id;this.name = name;
}
// 2. 前序遍历 public void preList() {
System.out.println(this); if (this.left != null) this.left.preList(); if (this.right != null) this.right.preList();}
// 3. 中序遍历 public void midList() {
if (this.left != null) this.left.midList(); System.out.println(this); if (this.right != null) this.right.midList();}
// 4. 后序遍历 public void postList() {
if (this.left != null) this.left.postList(); if (this.right != null) this.right.postList(); System.out.println(this);}
// 5. 前序遍历查找 public TreeNode preSearch(int id) {
if (id == this.id) { return this; } TreeNode res; if (this.left != null) { res = this.left.preSearch(id); if (res!=null){ return res; } } if (this.right != null) { res = this.right.preSearch(id); if (res!=null){ return res; } } return null;}
// 6. 中序遍历查找 public TreeNode midSearch(int id) {
TreeNode res; if (this.left != null) { res = this.left.midSearch(id); if (res!=null){ return res; } } if (id == this.id) { return this; } if (this.right != null) { res = this.right.midSearch(id); if (res!=null){ return res; } } return null;}
// 7. 后序遍历查找 public TreeNode postSearch(int no) {
TreeNode res; if (this.left != null) { res = this.left.postSearch(id); if (res!=null){ return res; } } if (this.right != null) { res = this.right.postSearch(id); if (res!=null){ return res; } } if (id == this.id) { return this; } return null;}
// 8. 删除节点 public void delete(int id) {
if (this.left != null && id == this.left.id) { this.left = null; return; } if (this.right != null && id == this.right.id) { this.right = null; return; } if (this.left != null) { this.left.delete(id); } if (this.right != null) { this.right.delete(id); }}
@Override public String toString() {
return "TreeNode{" + "id=" + id + ", name='" + name + '\'' + '}';} }
/**
- 属性:
- 根节点
- 方法:
- 构造器
- 前序遍历
- 后序遍历
- 中序遍历
- 删除节点
- 前序遍历查找
- 后序遍历查找
中序遍历查找 */ public class BinaryTree { private TreeNode root;
// 1. 构造器 public BinaryTree(TreeNode root) { this.root = root; }
// 2. 前序遍历 public void preList() { if (root != null) {
root.preList();} else {
System.out.println("二叉树为空,无法遍历!");} }
// 3. 中序遍历 public void midList() { if (root != null) {
root.midList();} else {
System.out.println("二叉树为空,无法遍历!");} }
// 4. 后序遍历 public void postList() { if (root != null) {
root.postList();} else {
System.out.println("二叉树为空,无法遍历!");} }
// 5. 前序遍历查找 public TreeNode preSearch(int id) { if (root != null) {
return root.preSearch(id);} return null; }
// 6. 中序遍历查找 public TreeNode midSearch(int id) { if (root != null) {
return root.midSearch(id);} return null; }
// 7. 后序遍历查找 public TreeNode postSearch(int id) { if (root != null) {
return root.postSearch(id);} return null; }
// 8. 删除节点 public void del(int id) { if (root == null) {
System.out.println("树为空,无法执行删除!"); return;} if (root.id == id) {
root = null;} else {
root.delete(id);2. 顺序二叉树
2.1 介绍
顺序二叉树,数组与树存储结构的相互转换
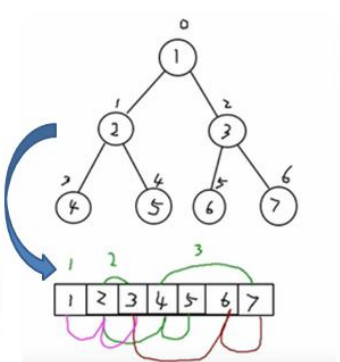
2.2 特点
- 顺序二叉树一般只考虑完全二叉树
- 第n个元素的左子节点为2*n+1
- 第n个元素的右子节点为2*n+2
- 同理,第n个元素的父节点为(n-1)/2
-
2.3 实现
只需要考虑树空以及左右子节点与当前节点的关系即可
补充:每次递归需要传入索引位置
/** * 属性: * 数组 * 方法: * 1. 构造器 * 2. 前序遍历 * 3. 中序遍历 * 4. 后序遍历 */ public class ArrBinaryTree { private int[] arr; // 1. 构造器 public ArrBinaryTree(int[] arr) { this.arr = arr; } // 2. 前序遍历 public void preList(int index) { if (arr == null && arr.length == 0) { System.out.println("树空,不可遍历!"); return; } System.out.println(arr[index]); if (2 * index + 1 < arr.length) { preList(index * 2 + 1); } if (2 * index + 2 < arr.length) { preList(index * 2 + 2); } } // 3. 中序遍历 public void midList(int index) { if (arr == null && arr.length == 0) { System.out.println("树空,不可遍历!"); return; } if (2 * index + 1 < arr.length) { midList(index * 2 + 1); } System.out.println(arr[index]); if (2 * index + 2 < arr.length) { midList(index * 2 + 2); } } // 4. 后序遍历 public void postList(int index) { if (arr == null && arr.length == 0) { System.out.println("树空,不可遍历!"); return; } if (2 * index + 1 < arr.length) { postList(index * 2 + 1); } if (2 * index + 2 < arr.length) { postList(index * 2 + 2); } System.out.println(arr[index]); } }3. 线索化二叉树
3.1 介绍
为了让二叉树的节点得到更该校的利用,线索化二叉树诞生。对于一个普通的二叉树,其会存在n+1个空指针域,将这些空指针域指向某种遍历方法对应的上一个或者下一个节点,这样实现了线索化。
3.2 特点
未线索化的二叉树对应n+1个空指针域
- 线索化二叉树的前一个结点称为前驱结点,后一个结点称为后继结点
根据性质不同,线索化二叉树分为前序二叉树,中序二叉树和后序二叉树
3.3 实现
```java public class ThreadNode { public int id; public String name; public ThreadNode left; public ThreadNode right; public int leftType; public int rightType;
public ThreadNode(int id,String name){
this.id = id; this.name = name;}
// 1. 删除 public void delNode(int id){
if (this.left!=null && this.left.id==id){ this.left = null; return; } if (this.right!=null && this.right.id==id){ this.right = null; return; } if (this.left!=null){ this.left.delNode(id); } if (this.right!=null){ this.right.delNode(id); }}
@Override public String toString() {
return "ThreadNode{" + "id=" + id + ", name='" + name + '\'' + '}';} }
/**
- 属性:
- 根节点
- 上一个节点
- 方法:
- 构造器
- 遍历线索化二叉树
- 执行中序线索化
- 删除节点 */ public class ThreadBinaryTree { private ThreadNode root; private ThreadNode pre;
// 1. 构造器 public ThreadBinaryTree(ThreadNode root){ this.root = root; }
// 2. 遍历线索化二叉树(中序遍历) public void threadList(){ ThreadNode temp = root; while(temp!=null){
while(root.left!=null){ temp = temp.left; } System.out.println(temp); while(temp.rightType==1){ temp = temp.right; System.out.println(temp); } temp = temp.right;} }
public void threadList2(){ ThreadNode temp = root; while(temp!=null){
while(temp!=null){ temp = temp.left; } System.out.println(temp); while(temp.rightType==1){ temp = temp.right; System.out.println(temp); } temp = temp.right;} }
// 3. 中序线索化方法 public void thread(ThreadNode node){ if (node==null){
return;} thread(node.left); if (node.left==null){
node.left = pre; node.leftType = 1;} if (pre!=null && pre.right==null){
pre.right = node; pre.rightType = 1;} pre = node; thread(node.right); }
// 4. 删除 public void del(int id){ if (root==null){
System.out.println("树空,不可执行删除!"); return;} if (root.id==id){
root = null;}else{
root.delNode(id);} } } ```
4. 赫夫曼树
4.1 介绍
SQLite面对复杂场景尚有不足
SQLite的优点亮眼,但对于复杂应用场景时还是有些缺点。
Java应用可能处理的数据源多种多样,比如csv文件、RDB、Excel、Restful,但SQLite只处理了简单情况,即对csv等文本文件提供了直接可用的命令行加载程序:
.import —csv —skip 1 —schema temp /Users/scudata/somedata.csv tab1
对于其他大部分数据源,SQLite都没有提供方便的接口,只能硬写代码加载数据,需要多次调用命令行,整个过程很繁琐,时效性也差。
以加载RDB数据源为例,一般的做法是先用Java执行命令行,把RDB库表转为csv;再用JDBC访问SQLite,创建表结构;之后用Java执行命令行,将csv文件导入SQLite;最后为新表建索引,以提高性能。这个方法比较死板,如果想灵活定义表结构和表名,或通过计算确定加载的数据,代码就更难写了。
类似地,对于其他数据源,SQLite也不能直接加载,同样要通过繁琐地转换过程才可以。
SQL接近自然语言,学习门槛低,容易实现简单的计算,但不擅长复杂的计算,比如复杂的集合计算、有序计算、关联计算、多步骤计算。SQLite采用SQL语句做计算,SQL优点和缺点都会继承下来,勉强实现这些复杂计算的话,代码会显得繁琐难懂。
比如,某只股票最长的上涨天数,SQL要这样写:

若有收获,就点个赞吧
0 人点赞
