一、Spark streaming的概述
- Spark Streaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理
- Spark Streaming类似于Apache Storm,用于流式数据的处理。
- 根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。
- Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。
- 数据输入后可以用Spark的高度抽象操作如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。
另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
二、Spark streaming的原理
一个应用Application由一个任务控制节点Driver和若干个作业Job构成,一个作业由多个阶段Stage构成,一个阶段由多个任务Task组成TaskSet。
- 当执行一个应用时,任务控制节点会向集群管理器ClusterManager申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行task
- Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理(微批次),当批处理间隔缩短到秒级时,便可以用于处理实时数据流。其实就是把流式计算当作一系列连续的小规模批处理来对待!其实就是用批处理(小批次)的思想来做流处理
- 通过上面的学习我们知道了Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是还是SparkCore
三、Spark Streaming 不足
3.1、Processing Time 而不是 Event Time
首先解释一下,Processing Time 是数据到达 Spark 被处理的时间,而 Event Time 是数据自带的属性,一般表示数据产生于数据源的时间。比如 IoT 中,传感器在 12:00:00 产生一条数据,然后在 12:00:05 数据传送到 Spark,那么 Event Time 就是 12:00:00,而 Processing Time 就是 12:00:05。我们知道 Spark Streaming 是基于 DStream 模型的 micro-batch 模式,简单来说就是将一个微小时间段,比如说 1s,的流数据当前批数据来处理。如果我们要统计某个时间段的一些数据统计,毫无疑问应该使用 Event Time,但是因为 Spark Streaming 的数据切割是基于 Processing Time,这样就导致使用 Event Time 特别的困难。
3.2、Complex, low-level api
这点比较好理解,DStream (Spark Streaming 的数据模型)提供的 API 类似 RDD 的 API 的,非常的 low level。当我们编写 Spark Streaming 程序的时候,本质上就是要去构造 RDD 的 DAG 执行图,然后通过 Spark Engine 运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别。这样导致开发者的体验非常不好,也是任何一个基础框架不想看到的(基础框架的口号一般都是:你们专注于自己的业务逻辑就好,其他的交给我)。这也是很多基础系统强调 Declarative 的一个原因。
3.3、reason about end-to-end application
这里的 end-to-end 指的是直接 input 到 out,比如 Kafka 接入 Spark Streaming 然后再导出到 HDFS 中。DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证。而这个语义保证写起来也是非常有挑战性,比如为了保证 output 的语义是 exactly-once 语义需要 output 的存储系统具有幂等的特性,或者支持事务性写入,这个对于开发者来说都不是一件容易的事情。
3.4、批流代码不统一
尽管批流本是两套系统,但是这两套系统统一起来确实很有必要,我们有时候确实需要将我们的流处理逻辑运行到批数据上面。关于这一点,最早在 2014 年 Google 提出 Dataflow 计算服务的时候就批判了 streaming/batch 这种叫法,而是提出了 unbounded/bounded data 的说法。DStream 尽管是对 RDD 的封装,但是我们要将 DStream 代码完全转换成 RDD 还是有一点工作量的,更何况现在 Spark 的批处理都用 DataSet/DataFrame API 了。
四、Spark streaming中的数据抽象DStream
DStream(Discretized Stream,离散化数据流,连续不断的数据流)是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。
DStream本质上就是一系列时间上连续的RDD
五、Structured Streaming的概述
5.1、曲折发展史
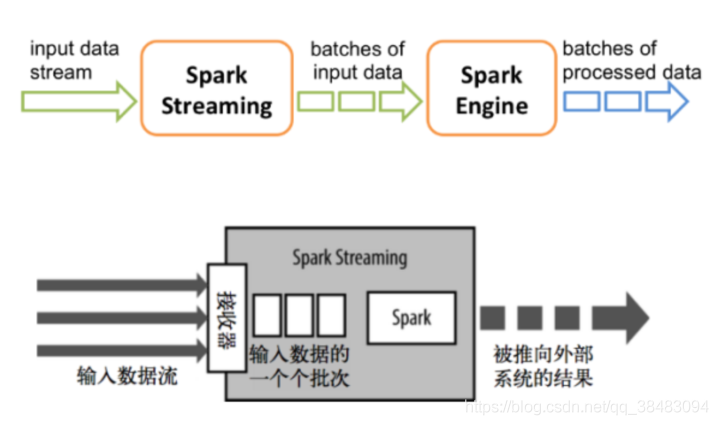
在2.0之前,Spark Streaming作为核心API的扩展,针对实时数据流,提供了一套可扩展、高吞吐、可容错的流式计算模型。
Spark Streaming会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。
本质上,这是一种micro-batch(微批处理)的方式处理,这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
其实在流计算发展的初期,市面上主流的计算引擎本质上都只能处理特定的场景:
storm作为起步非常早的流计算引擎,大部分用于one-by-one式无状态的数据处理场景(虽然提供了Trident API用于有状态的聚合计算,但依然有局限),
而spark streaming这种构建在微批处理上的流计算引擎,比较突出的问题就是处理延时较高(无法优化到秒以下的数量级),以及无法支持基于event_time的时间窗口做聚合逻辑。
在这段时间,流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年google发表了The Dataflow Model的论文。
5.2、设计核心
Structured Streaming 的关键思想是将持续不断的数据当做一个不断追加的表。这使得流式计算模型与批处理计算引擎十分相似。使用类似对于静态表的批处理方式来表达流计算,然后 Spark 以在无限表上的增量计算来运行。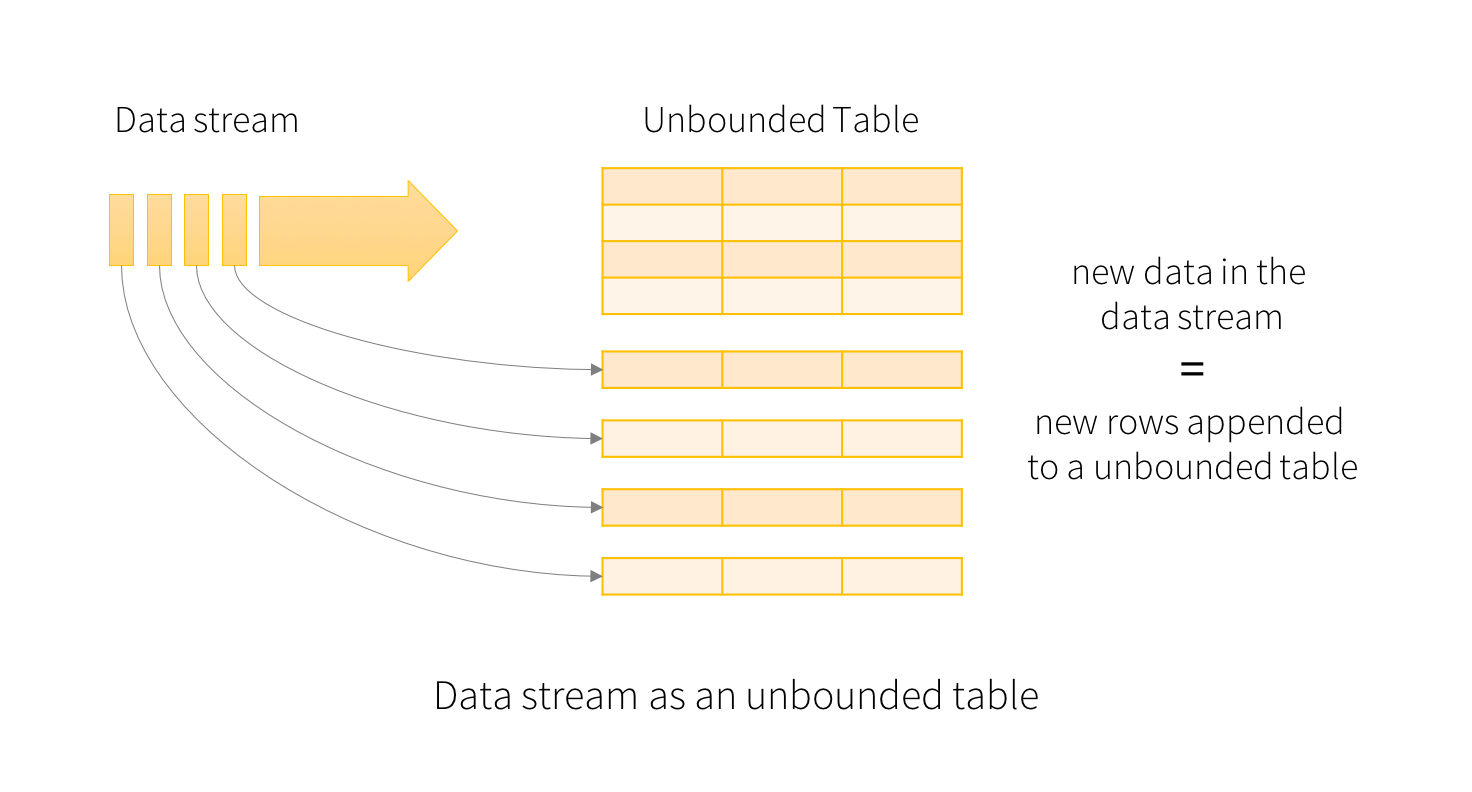
- Input and Output: Structured Streaming 内置了很多 connector 来保证 input 数据源和 output sink 保证 exactly-once 语义。而实现 exactly-once 语义的前提是:Input 数据源必须是可以 replay 的,比如 Kafka,这样节点 crash 的时候就可以重新读取 input 数据。常见的数据源包括 Amazon Kinesis, Apache Kafka 和文件系统。
- Output sink 必须要支持写入是幂等的。这个很好理解,如果 output 不支持幂等写入,那么一致性语义就是 at-least-once 了。另外对于某些 sink, Structured Streaming 还提供了原子写入来保证 exactly-once 语义。
- API: Structured Streaming 代码编写完全复用 Spark SQL 的 batch API,也就是对一个或者多个 stream 或者 table 进行 query。query 的结果是 result table,可以以多种不同的模式(append, update, complete)输出到外部存储中。另外,Structured Streaming 还提供了一些 Streaming 处理特有的 API:Trigger, watermark, stateful operator。Execution: 复用 Spark SQL 的执行引擎。Structured Streaming 默认使用类似 Spark Streaming 的 micro-batch 模式,有很多好处,比如动态负载均衡、再扩展、错误恢复以及 straggler (straggler 指的是哪些执行明显慢于其他 task 的 task)重试。除了 micro-batch 模式,Structured Streaming 还提供了基于传统的 long-running operator 的 continuous 处理模式。
Operational Features: 利用 wal 和状态存储,开发者可以做到集中形式的 rollback 和错误恢复。还有一些其他 Operational 上的 feature,这里就不细说了。
5.3、Structured Streaming 优势
相对的,来看下Structured Streaming优势(虽然上面已经看出来了):
简洁的模型。Structured Streaming 的模型很简洁,易于理解。用户可以直接把一个流想象成是无限增长的表格。
- 一致的 API。由于和 Spark SQL 共用大部分 API,对 Spaprk SQL 熟悉的用户很容易上手,代码也十分简洁。同时批处理和流处理程序还可以共用代码,不需要开发两套不同的代码,显著提高了开发效率。
- 卓越的性能。Structured Streaming 在与 Spark SQL 共用 API 的同时,也直接使用了 Spark SQL 的 Catalyst 优化器和 Tungsten,数据处理性能十分出色。此外,Structured Streaming 还可以直接从未来 Spark SQL 的各种性能优化中受益。
- 多语言支持。Structured Streaming 直接支持目前 Spark SQL 支持的语言,包括 Scala,Java,Python,R 和 SQL。用户可以选择自己喜欢的语言进行开发。
六、Dataflow模型
在日常商业运营中,无边界、乱序、大规模数据集越来越普遍(例如,网站日志,手机应用统计,传感器网络)。同时,对这些数据的消费需求也越来越复杂,比如说按事件发生时间序列处理数据,按数据本身的特征进行窗口计算等等。同时人们也越来越苛求立刻得到数据分析结果。
作为数据工作者,不能把无边界数据集(数据流)切分成有边界的数据,等待一个批次完整后处理。
相反地,应该假设永远无法知道数据流是否终结,何时数据会变完整。唯一确信的是,新的数据会源源不断而来,老的数据可能会被撤销或更新。由此,google工程师们提出了Dataflow模型,从根本上对从前的数据处理方法进行改进。
●Dataflow模型的核心思想
对无边界,无序的数据源,允许按数据本身的特征进行窗口计算,得到基于事件发生时间的有序结果,并能在准确性、延迟程度和处理成本之间调整。
●论文中构建模型的四个维度
抽象出四个相关的维度,通过灵活地组合来构建数据处理管道,以应对数据处理过程中的各种复杂的场景
what 需要计算什么
where 需要基于什么时间(事件发生时间)窗口做计算
when 在什么时间(系统处理时间)真正地触发计算
how 如何修正之前的计算结果
论文的大部分内容都是在说明如何通过这四个维度来应对各种数据处理场景。

若有收获,就点个赞吧
0 人点赞
