4.1、分区基本概述
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD 时指定。
在代码指定分区数的代码Demo:
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")val sparkContext = new SparkContext(sparkConf)val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4), 4) // 指定RDD分区数为4val fileRDD: RDD[String] = sparkContext.textFile("input", 2) // 指定RDD最小分区数为2fileRDD.collect().foreach(println)sparkContext.stop()第二个参数可以不设置,会有一个默认值,由参数 “spark.default.parallelism” 指定,如果获取不到就指定为totalCoreCount(当前环境最大使用核数)//RDD的计算一个分区内的数据是一个一个执行的,只有前面一个数据执行完毕后才会执行下一个数据(分区内有序)//不同分区内的计算是无序的// 不同分区数设置得到的效果val rdd1: RDD[Int] = ctx.parallelize(1 to 10)val rdd2: RDD[Int] = ctx.parallelize(1 to 10,3)val rdd3: RDD[Int] = ctx.makeRDD(1 to 10)val rdd4: RDD[Int] = ctx.makeRDD(1 to 10,3)val rdd5: RDD[String] = ctx.textFile("input/data.txt")val rdd6: RDD[String] = ctx.textFile("input/data.txt",3)val rdd7: RDD[String] = ctx.textFile("input/dir/")val rdd8: RDD[String] = ctx.textFile("input/dir/",3)val rdd9: RDD[(String, String)] = ctx.wholeTextFiles("input/dir/")val rdd10: RDD[(String, String)] = ctx.wholeTextFiles("input/dir/",3)println("rdd1.partitions.length = "+rdd1.partitions.length)println("rdd2.partitions.length = "+rdd2.partitions.length)println("rdd3.partitions.length = "+rdd3.partitions.length)println("rdd4.partitions.length = "+rdd4.partitions.length)println("rdd5.partitions.length = "+rdd5.partitions.length)println("rdd6.partitions.length = "+rdd6.partitions.length)println("rdd7.partitions.length = "+rdd7.partitions.length)println("rdd8.partitions.length = "+rdd8.partitions.length)println("rdd9.partitions.length = "+rdd9.partitions.length)println("rdd10.partitions.length = "+rdd10.partitions.length)// 结果rdd1.partitions.length = 8 // 默认为cpu核数rdd2.partitions.length = 3 // 手动设置了分区数为3rdd3.partitions.length = 8 // 默认为cpu核数rdd4.partitions.length = 3 // 手动设置了分区数为3rdd5.partitions.length = 3 //rdd6.partitions.length = 4 //rdd7.partitions.length = 10 // 由于该目录下有10个文件,每个文件一个分区,导致有10个分区rdd8.partitions.length = 10 // textFile对小文件读取不友好,每个文件最小一个分区rdd9.partitions.length = 1 // wholeTextFiles 会对小文件进行优化rdd10.partitions.length =1 //
Spark会通过DAG将一个Spark job中用到的所有RDD划分为不同的stage,每个stage内部都会有很多子任务处理数据,而每个stage的任务数是决定性能优劣的关键指标。
Spark job中最小执行单位为task,合理设置Spark job每个stage的task数是决定性能好坏的重要因素之一,但是Spark自己确定最佳并行度的能力有限,这就要求我们在了解其中内在机制的前提下,去各种测试、计算等来最终确定最佳参数配比。
Spark任务在执行时会将RDD划分为不同的stage,一个stage中task的数量跟最后一个RDD的分区数量相同。stage划分的关键是宽依赖,而宽依赖往往伴随着shuffle操作。对于一个stage接收另一个stage的输入,这种操作通常都会有一个参数numPartitions来显示指定分区数。最典型的就是一些ByKey算子,比如groupByKey(numPartitions: Int),但是这个分区数需要多次测试来确定合适的值。首先确定父RDD中的分区数(通过rdd.partitions().size()可以确定RDD的分区数),然后在此基础上增加分区数,多次调试直至在确定的资源任务能够平稳、安全的运行。
对于没有父RDD的RDD,比如通过加载HDFS上的数据生成的RDD,它的分区数由InputFormat切分机制决定。通常就是一个HDFS block块对应一个分区,对于不可切分文件则一个文件对应一个分区。
对于通过SparkContext的parallelize方法或者makeRDD生成的RDD分区数可以直接在方法中指定,如果未指定,则参考spark.default.parallelism的参数配置。下面是默认情况下确定defaultParallelism的源码:
override def defaultParallelism(): Int = {conf.getInt(“spark.default.parallelism”, math.max(totalCoreCount.get(), 2))}
——————————————————————————————————————————
Spark对接不同的数据源,在第一次得到的分区数是不一样的,但都有一个共性:对于map类算子或者通过map算子产生的彼此之间具有窄依赖关系的RDD的分区数,子RDD分区与父RDD分区是一致的。而对于通过shuffle差生的子RDD则由分区器决定,当然默认分区器是HashPartitioner,我们完全可以根据实际业务场景进行自定义分区器,只需继承Parttioner组件,主要重写几个方法即可:
abstract class Partitioner extends Serializable {def numPartitions: Intdef getPartition(key: Any): Int}
以加载hdfs文件为例,Spark在读取hdfs文件还没有调用其他算子进行业务处理前,得到的RDD分区数由什么决定呢?关键在于文件是否可切分!
对于可切分文件,如text文件,那么通过加载文件得到的RDD的分区数默认与该文件的block数量保持一致;
对于不可切分文件,它只有一个block块,那么得到的RDD的分区数默认也就是1。
当然,我们可以通过调用一些算子对RDD进行重分区,如repartition。
这里必须要强调一点,很多小伙伴不理解,RDD既然不存储数据,那么加载过来的文件都跑哪里去了呢?这里先给大家提个引子——blockmanager,Spark自己实现的存储管理器。RDD的存储概念其实block,至于block的大小可以根据不同的数据源进行调整,blockmanager的数据存储、传输都是以block进行的。至于block内部传输的时候,它的大小也是可以通过参数控制的,比如广播变量、shuffle传输时block的大小等。



4.2、文件获取分片数源码
/** Splits files returned by {@link #listStatus(JobConf)} when* they're too big.*/public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException {Stopwatch sw = new Stopwatch().start();FileStatus[] files = listStatus(job);// Save the number of input files for metrics/loadgenjob.setLong(NUM_INPUT_FILES, files.length);long totalSize = 0; // compute total sizefor (FileStatus file: files) { // check we have valid filesif (file.isDirectory()) {throw new IOException("Not a file: "+ file.getPath());}totalSize += file.getLen(); //在这里获取要读取文件总数的大小,单位字节}long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); // 由设置的分区数,计算出每个分片要存放多大字节的内容long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);// generate splitsArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);NetworkTopology clusterMap = new NetworkTopology();for (FileStatus file: files) {Path path = file.getPath();long length = file.getLen();if (length != 0) {FileSystem fs = path.getFileSystem(job);BlockLocation[] blkLocations;if (file instanceof LocatedFileStatus) {blkLocations = ((LocatedFileStatus) file).getBlockLocations();} else {blkLocations = fs.getFileBlockLocations(file, 0, length);}if (isSplitable(fs, path)) {long blockSize = file.getBlockSize();long splitSize = computeSplitSize(goalSize, minSize, blockSize);long bytesRemaining = length;while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { //这里在所有分片分配完成后还有剩余的,如果剩余的大于分片容量的1.1倍则新开一个分片否则不开String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,length-bytesRemaining, splitSize, clusterMap);splits.add(makeSplit(path, length-bytesRemaining, splitSize,splitHosts[0], splitHosts[1]));bytesRemaining -= splitSize;}if (bytesRemaining != 0) {String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length- bytesRemaining, bytesRemaining, clusterMap);splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,splitHosts[0], splitHosts[1]));}} else {String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));}} else {//Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}sw.stop();if (LOG.isDebugEnabled()) {LOG.debug("Total # of splits generated by getSplits: " + splits.size()+ ", TimeTaken: " + sw.elapsedMillis());}return splits.toArray(new FileSplit[splits.size()]);}
4.3、分区数据的分配
在Spark中,RDD(Resilient Distributed Dataset)是其最基本的抽象数据集,其中每个RDD是由若干个Partition组成。在Job运行期间,参与运算的Partition数据分布在多台机器的内存当中。这里可将RDD看成一个非常大的数组,其中Partition是数组中的每个元素,并且这些元素分布在多台机器中。图一中,RDD1包含了5个Partition,RDD2包含了3个Partition,这些Partition分布在4个节点中。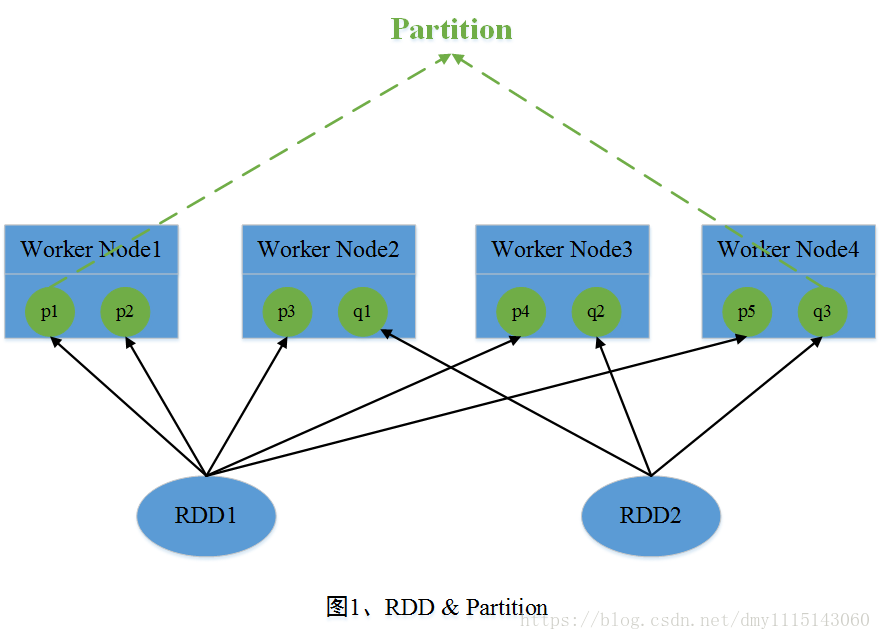
Spark包含两种数据分区方式:HashPartitioner(哈希分区)和RangePartitioner(范围分区)。一般而言,对于初始读入的数据是不具有任何的数据分区方式的。数据分区方式只作用于
4.3.1、HashPartitioner(哈希分区)
1、HashPartitioner原理简介
HashPartitioner采用哈希的方式对
2、HashPartitioner源码详解
class HashPartitioner(partitions: Int) extends Partitioner {require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")/*** 包含的分区个数*/def numPartitions: Int = partitions/*** 获得Key对应的partitionId*/def getPartition(key: Any): Int = key match {case null => 0case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)}override def equals(other: Any): Boolean = other match {case h: HashPartitioner =>h.numPartitions == numPartitionscase _ =>false}override def hashCode: Int = numPartitions}def nonNegativeMod(x: Int, mod: Int): Int = {val rawMod = x % modrawMod + (if (rawMod < 0) mod else 0)}
4.3.2、RangePartitioner(范围分区)
1、RangePartitioner原理简介
Spark引入RangePartitioner的目的是**为了解决HashPartitioner所带来的分区倾斜问题**,也即分区中包含的数据量不均衡问题。HashPartitioner采用哈希的方式将同一类型的Key分配到同一个Partition中,因此当某一或某几种类型数据量较多时,就会造成若干Partition中包含的数据过大问题,而在Job执行过程中,一个Partition对应一个Task,此时就会使得某几个Task运行过慢。RangePartitioner基于抽样的思想来对数据进行分区。图4简单描述了RangePartitioner的数据分区过程。<br />
2、RangePartitioner源码详解
① 确定采样数据的规模:RangePartitioner默认对生成的子RDD中的每个Partition采集20条数据,样本数据最大为1e6条。
// 总共需要采集的样本数据个数,其中partitions代表最终子RDD中包含的Partition个数val sampleSize = math.min(20.0 * partitions, 1e6)
② 确定父RDD中每个Partition中应当采集的数据量:这里注意的是,对父RDD中每个Partition采集的数据量会在平均值上乘以3,这里是为了后继在进行判断一个Partition是否发生了倾斜,当一个Partition包含的数据量超过了平均值的三倍,此时会认为该Partition发生了数据倾斜,会对该Partition调用sample算子进行重新采样。
// 被采样的RDD中每个partition应该被采集的数据,这里将平均采集每个partition中数据的3倍val sampleSizePerPartition = math.ceil(3.0 * sampleSize / rdd.partitions.length).toInt
③ 调用sketch方法进行数据采样:sketch方法返回的结果为<采样RDD的数据量,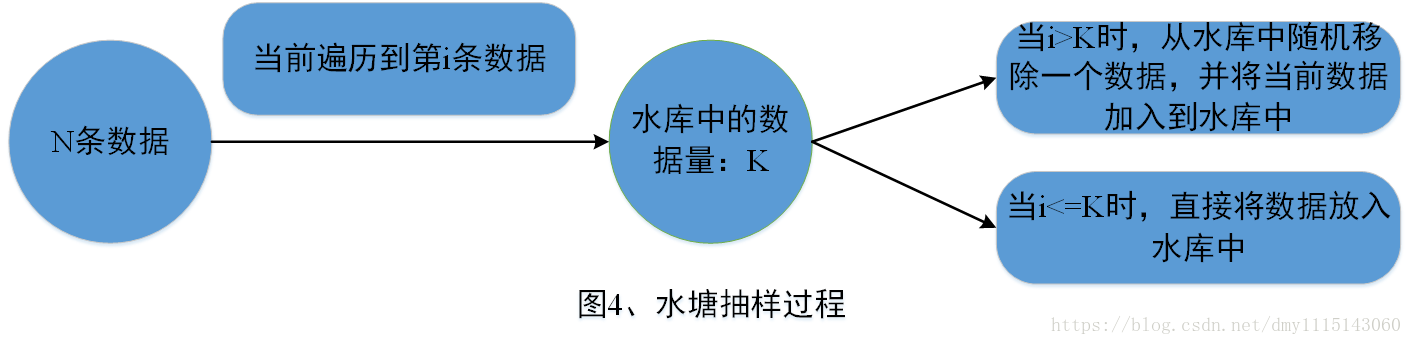
// 使用sketch方法进行数据抽样val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)/*** @param rdd 需要采集数据的RDD* @param sampleSizePerPartition 每个partition采集的数据量* @return <采样RDD数据总量,<partitionId, 当前分区的数据量,当前分区采集的数据量>>*/def sketch[K : ClassTag](rdd: RDD[K],sampleSizePerPartition: Int): (Long, Array[(Int, Long, Array[K])]) = {val shift = rdd.idval sketched = rdd.mapPartitionsWithIndex { (idx, iter) =>val seed = byteswap32(idx ^ (shift << 16))// 使用水塘抽样算法进行抽样,抽样结果是个二元组<Partition中抽取的样本量,Partition中包含的数据量>val (sample, n) = SamplingUtils.reservoirSampleAndCount(iter, sampleSizePerPartition, seed)Iterator((idx, n, sample))}.collect()val numItems = sketched.map(_._2).sum(numItems, sketched)}
④ 数据抽样完成后,需要对不均衡的Partition重新进行抽样,默认当Partition中包含的数据量大于平均值的三倍时,该Partition是不均衡的。当采样完成后,利用样本容量和RDD中包含的数据总量,可以得到整体的一个数据采样率fraction。利用此采样率对不均衡的Partition调用sample算子重新进行抽样。
// 计算数据采样率val fraction = math.min(sampleSize / math.max(numItems, 1L), 1.0)// 存放采样Key以及采样权重val candidates = ArrayBuffer.empty[(K, Float)]// 存放不均衡的Partitionval imbalancedPartitions = mutable.Set.empty[Int]//(idx, n, sample)=> (partition id, 当前分区数据个数,当前partition的采样数据)sketched.foreach { case (idx, n, sample) =>// 当一个分区中的数据量大于平均分区数据量的3倍时,认为该分区是倾斜的if (fraction * n > sampleSizePerPartition) {imbalancedPartitions += idx}// 在三倍之内的认为没有发生数据倾斜else {// 每条数据的采样间隔 = 1/采样率 = 1/(sample.size/n.toDouble) = n.toDouble/sample.sizeval weight = (n.toDouble / sample.length).toFloat// 对当前分区中的采样数据,对每个key形成一个二元组<key, weight>for (key <- sample) {candidates += ((key, weight))}}}// 对于非均衡的partition,重新采用sample算子进行抽样if (imbalancedPartitions.nonEmpty) {val imbalanced = new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)val seed = byteswap32(-rdd.id - 1)val reSampled = imbalanced.sample(withReplacement = false, fraction, seed).collect()val weight = (1.0 / fraction).toFloatcandidates ++= reSampled.map(x => (x, weight))}
⑤ 确定各个Partition的Key范围:使用determineBounds方法来确定每个Partition中包含的Key范围,先对采样的Key进行排序,然后计算每个Partition平均包含的Key权重,然后采用平均分配原则来确定各个Partition包含的Key范围。如当前采样Key以及权重为:<1, 0.2>, <2, 0.1>, <3, 0.1>, <4, 0.3>, <5, 0.1>, <6, 0.3>,现在将其分配到3个Partition中,则每个Partition的平均权重为:(0.2 + 0.1 + 0.1 + 0.3 + 0.1 + 0.3) / 3 = 0.36。此时Partition1 ~ 3分配的Key以及总权重为
/*** @param candidates 未按采样间隔排序的抽样数据* @param partitions 最终生成的RDD包含的分区个数* @return 分区边界*/def determineBounds[K : Ordering : ClassTag](candidates: ArrayBuffer[(K, Float)],partitions: Int): Array[K] = {val ordering = implicitly[Ordering[K]]// 对样本按照key进行排序val ordered = candidates.sortBy(_._1)// 抽取的样本容量val numCandidates = ordered.size// 抽取的样本对应的采样间隔之和val sumWeights = ordered.map(_._2.toDouble).sum// 平均每个分区的步长val step = sumWeights / partitionsvar cumWeight = 0.0var target = step// 分区边界值val bounds = ArrayBuffer.empty[K]var i = 0var j = 0var previousBound = Option.empty[K]while ((i < numCandidates) && (j < partitions - 1)) {val (key, weight) = ordered(i)cumWeight += weight// 当前的采样间隔小于target,继续迭代,也即这些key应该放在同一个partition中if (cumWeight >= target) {// Skip duplicate values.if (previousBound.isEmpty || ordering.gt(key, previousBound.get)) {bounds += keytarget += stepj += 1previousBound = Some(key)}}i += 1}bounds.toArray}
⑥ 计算每个Key所在Partition:当分区范围长度在128以内,使用顺序搜索来确定Key所在的Partition,否则使用二分查找算法来确定Key所在的Partition。
/*** 获得每个Key所在的partitionId*/def getPartition(key: Any): Int = {val k = key.asInstanceOf[K]var partition = 0// 如果得到的范围不大于128,则进行顺序搜索if (rangeBounds.length <= 128) {// If we have less than 128 partitions naive searchwhile (partition < rangeBounds.length && ordering.gt(k, rangeBounds(partition))) {partition += 1}}// 范围大于128,则进行二分搜索该key所在范围,即可得到该key所在的partitionIdelse {// Determine which binary search method to use only once.partition = binarySearch(rangeBounds, k)// binarySearch either returns the match location or -[insertion point]-1if (partition < 0) {partition = -partition-1}if (partition > rangeBounds.length) {partition = rangeBounds.length}}if (ascending) {partition} else {rangeBounds.length - partition}}

若有收获,就点个赞吧
0 人点赞
