一、分类
RDD中两种算子:
- transformation算子,是延迟加载的,功能的补充和封装,将旧的RDD转换成新的RDD
- 常用的transformation:
- map、flatMap、filter、distinct:去重
- intersection求交集、union求并集:注意类型要一致
- join:类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
- groupByKey:在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD但是效率reduceByKey较高,因为有一个本地combiner的过程。
- cartesian笛卡尔积
- 行动算子,触发任务的调度和任务的执行
- collect()、count()
- reduce:通过func函数聚集RDD中的所有元素
- take(n):取前n个;top(2):排序取前两个
- takeOrdered(n),排完序后取前n个
RDD根据数据处理方式的不同,把算子分为Value类型、双Value类型、Key-Value类型。
其他教程:https://blog.csdn.net/leen0304/article/details/78836073?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link
二、Value转换算子
2.1、map、mapPartitions、mapPartitionsWithIndex算子
将原来 RDD 的每个数据项通过 map 中的用户自定义函数 f 映射转变为一个新的元素。源码中 map 算子相当于初始化一个 RDD, 新 RDD 叫做 MappedRDD(this, sc.clean(f))。
图 1中每个方框表示一个 RDD 分区,左侧的分区经过用户自定义函数 f:T->U 映射为右侧的新 RDD 分区。但是,实际只有等到 Action算子触发后,这个 f 函数才会和其他函数在一个stage 中对数据进行运算。在图 1 中的第一个分区,数据记录 V1 输入 f,通过 f 转换输出为转换后的分区中的数据记录 V’1。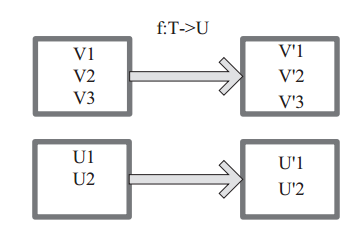
import org.apache.spark.{SparkConf, SparkContext}/*** Spark所有RDD中的算子都在Executor中执行** 非算子类型的计算在Driver中执行,所以如果在Driver定义了在Execuotr的变量,需要该变量 可序列化 和 网络IO传输**/object MapRDDDemo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)val intRDD = ctx.makeRDD(1 to 10)/*** 由于map算子是一个接着一个处理的,所以有多少个元素就是发多少次到Executor,这样可能带宽、IO会消耗多点** 在于数据每一个的变化*/def mapfunction(num:Int): Int ={num * 2}//逐步简化写法intRDD.map(mapfunction)intRDD.map((num:Int)=>{num*2})intRDD.map((num:Int)=>num*2)intRDD.map((num)=>num*2)intRDD.map(num=>num*2)val round2RDD = intRDD.map(_*2)/*** 下面每一个算子执行一次map都会打印一次创建链接的信息*/intRDD.map(e => {println("使用map创建数据库链接 = "+e)println("使用map关闭数据库链接 = "+e)}).collect()println("-----------------------------------")round2RDD.collect().foreach(println(_))println("-----------------------------------")/*** mapPartitions会将待处理的数据以分区为单位发送到计算节点。* mapPartitions 是一个按照分区数来 map 的算子,所以有多少个分区就往Executor发多少次* 但是由于是一整个分区的数据,所以可能会造成内存溢出。** mapPartitions 参数是传入一个迭代器,返回一个迭代器* 下面示例会根据分区数据决定打印多少条println*/intRDD.mapPartitions(iter => {println("使用mapPartitions创建数据库链接")while (iter.hasNext){println(iter.next())}println("使用mapPartitions关闭数据库链接")null}).collect()println("-----------------------------------")/*** 带有分区信息的 map 算子* 不同的分区发给不同的Executor执行* 与mapPartitions类似,但需要提供一个表示分区索引值的整型值作为参数,* 因此function必须是(int, Iterator<T>)=>Iterator<U>类型的。*/intRDD.mapPartitionsWithIndex{//index表示分区号、datas表示数据case (index,datas)=>{datas.map((_ , "分区号 : " + index)) // 返回值}}.collect().foreach(println)}}
2.2、flatMap算子
map是对RDD中元素逐一进行函数操作映射为另外一个RDD,而flatMap操作是将函数应用于RDD之中的每一个元素,将返回的迭代器的所有内容构成新的RDD。而flatMap操作是将函数应用于RDD中每一个元素,将返回的迭代器的所有内容构成RDD。
flatMap与map区别在于map为“映射”,而flatMap“先映射,后扁平化”,map对每一次(func)都产生一个元素,返回一个对象,而flatMap多一步就是将所有对象合并为一个对象。
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object FlatMapRDDDemp {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)val intRDD:RDD[List[Int]] = ctx.makeRDD(Array(List(1,2,3),List(5,6,7,8)))/*** 这里的 initRDD 其实只有两个元素,类型为 List 的值*/intRDD.collect().foreach(println)println("-------------------------------------")/*** flatMap 可以将里面的每一个元素打散*/intRDD.flatMap(data => {data}).collect().foreach(println)}}
2.3、glom算子
glom函数将同一个分区内的数据转换为相同类型的数组进行处理,分区不变。内部实现是返回的GlommedRDD。 图4中的每个方框代表一个RDD分区。图4中的方框代表一个分区。 该图表示含有V1、 V2、 V3的分区通过函数glom形成一数组Array[(V1),(V2),(V3)]。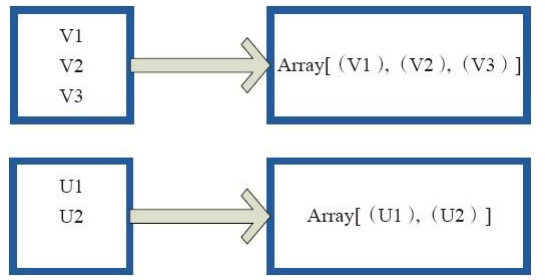
import org.apache.spark.{SparkConf, SparkContext}object GlomRDDDemo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)/*** 创建4个分区的数据*/val intRDD = ctx.makeRDD(1 to 20 , 4)/*** glom算子可以把一个分区的数据放到一个数组中*/val glomRDD = intRDD.glom()glomRDD.collect().foreach(println)println("--------------------------------------")/*** 分别输出每个分区的数据*/glomRDD.collect().foreach(arr => {arr.foreach(println)println("++++++++++")})}}
2.4、groupBy算子
groupBy :将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
函数实现如下:
1)将用户函数预处理:
val cleanF = sc.clean(f)
2)对数据 map 进行函数操作,最后再进行 groupByKey 分组操作。
this.map(t => (cleanF(t), t)).groupByKey(p)
其中, p 确定了分区个数和分区函数,也就决定了并行化的程度。
图7 中方框代表一个 RDD 分区,相同key 的元素合并到一个组。例如 V1 和 V2 合并为 V, Value 为 V1,V2。形成 V,Seq(V1,V2)。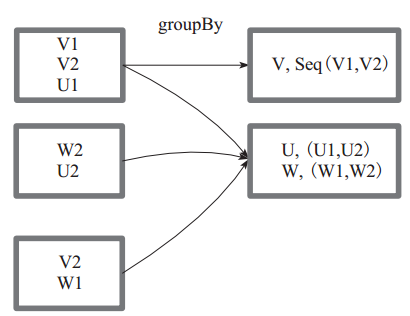
groupby操作会将数据打乱,重新组合,但是分区默认不变,这种情况叫做shuffle。
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object GroupByRDDDemo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)val intRDD = ctx.makeRDD(1 to 10)/*** groupBy:表示按照指定的规则进行分组(把数据分成几组)* 分组后的数据形成了对偶元组(K-V), K表示分组的key, V表示分组后的数据集合* 分组和分区之间没有必然的联系*/val groupRDD :RDD[(Int,Iterable[Int])] = intRDD.groupBy(e => {e % 2})groupRDD.collect().foreach(println)println("-------------------------------------")/*** 过滤算子,符合表达式为true的为过滤后的结果*/intRDD.filter(x=>{x % 2 == 0}).collect().foreach(println)}}
2.5、filter算子
filter 函数功能是对元素进行过滤,对每个 元 素 应 用 f 函 数, 返 回 值 为 true 的 元 素 在RDD 中保留,返回值为 false 的元素将被过滤掉。 内 部 实 现 相 当 于 生 成 FilteredRDD(this,sc.clean(f))。
下面代码为函数的本质实现:deffilter(f:T=>Boolean):RDD[T]=newFilteredRDD(this,sc.clean(f))
图 8 中每个方框代表一个 RDD 分区, T 可以是任意的类型。通过用户自定义的过滤函数 f,对每个数据项操作,将满足条件、返回结果为 true 的数据项保留。例如,过滤掉 V2 和 V3 保留了 V1,为区分命名为 V’1。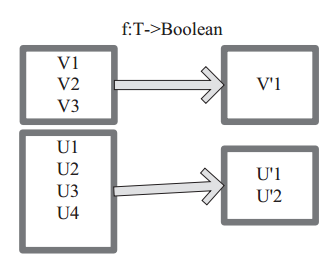
当数据进行筛选过滤后,分区不变,但是分区内的数据可能出现不均衡,在生产环境下可能会造成数据倾斜。
[
](https://blog.csdn.net/qq_32595075/article/details/79918644)
2.6、sample、takeSample算子
sample 将 RDD 这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。内部实现是生成 SampledRDD(withReplacement, fraction, seed)。
函数参数设置:
‰withReplacement=true,表示有放回的抽样,即每条数据可以被多次抽取。
‰ withReplacement=false,表示无放回的抽样,丢弃,即每条数据只能被抽取一次。
图 11中 的 每 个 方 框 是 一 个 RDD 分 区。 通 过 sample 函 数, 采 样 50% 的 数 据。V1、 V2、 U1、 U2、U3、U4 采样出数据 V1 和 U1、 U2 形成新的 RDD。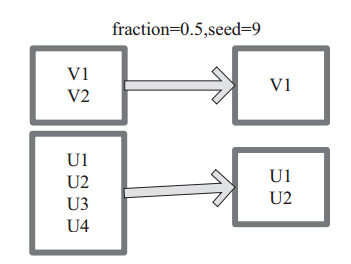
import org.apache.spark.{SparkConf, SparkContext}/*** 采样* 采样变换根据给定的随机种子,从RDD中随机地按指定比例选一部分记录,创建新的RDD。采样变换 在机器学习中可用于进行交叉验证。*/object SampleRDDDemo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)val intRDD = ctx.makeRDD(1 to 20)/*** 参数:* withReplacement : Boolean , True表示进行替换采样,False表示进行非替换采样* fraction : Double, 在0~1之间的一个浮点值,表示要采样的记录在全体记录中的比例* seed :随机种子,决定随机抽取的基准值;如果不指定,会默认为当前系统时间** 下面的示例从原RDD中随机选择20%的记录,构造一个新的RDD,然后返回新RDD的记录数:*/val result = intRDD.sample(true,0.2)result.collect().foreach(println)//takeSample:返回一个Array[T];该方法仅在预期结果数组很小的情况下使用,因为所有数据都被加载到driver的内存中。//参数:1、withReplacement:元素可以多次抽样(在抽样时替换);// 2、num:返回的样本的大小;// 3、seed:随机数生成器的种子val r2: Array[Int] = intRDD.takeSample(true,3,1)r2.foreach(println)}}
[
](https://blog.csdn.net/qq_32595075/article/details/79918644)
2.7、distinct算子
distinct将RDD中的元素进行去重操作。图9中的每个方框代表一个RDD分区,通过distinct函数,将数据去重。 例如,重复数据V1、 V1去重后只保留一份V1。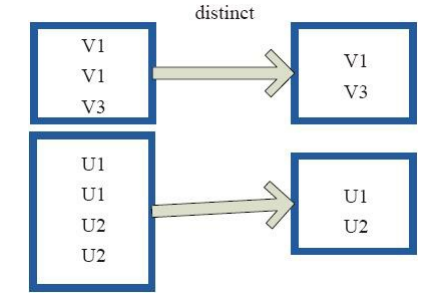
import org.apache.spark.{SparkConf, SparkContext}object DistinctRDDDemo {def main(args: Array[String]): Unit = {System.setProperty("hadoop.home.dir","D:\\hadoop")val conf = new SparkConf().setAppName("Save").setMaster("local[*]")val ctx = new SparkContext(conf)val intRDD = ctx.makeRDD(List(9,9,6,1,1,2,3,4,5,4,5,6))/*** 去重RDD* distinct 算子有 shuffle 阶段,源分区的数据会被打乱*/intRDD.distinct().collect().foreach(println)// 指定distinct分区后的分区数为 2 个// intRDD.distinct(2).collect().foreach(println)println("==================="+intRDD.partitions.size)println("==================="+intRDD.distinct().partitions.size)println("==================="+intRDD.distinct(2).partitions.size)/*** coalesce 算子可以缩减分区的数量,相当于合并分区,分区数只能比之前的小而不能比之前的大*/println("==================="+intRDD.distinct(2).coalesce(1).partitions.size)/*** sortBy 可以指定排序的字段*/intRDD.sortBy(e=>e).collect().foreach(println)/*** sortBy 第二个参数可以指定是否升降序*/intRDD.sortBy(e=>e,false).collect().foreach(print(_,""))}}
2.8、coalesce、repartition算子
coalesce重新分区,该算子可以实现对父RDD进行重分区,并且可以指定重分区时是否要Shuffle,当重分区数大于父RDD分区数,并且指定Shuffle为false时,重分区无效。repartition只是coalesce接口中shuffle为true的简易实现。
作用:当spark程序中,存在过多的小任务的时候,可以通过 RDD.coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本,避免Shuffle导致,这比使用RDD.repartition效率提高不少。
coalesce源码:
/*** 返回一个新的RDD,它将分区个数减少到“numPartitions”个分区。* 这是一个窄依赖操作;* 如果从1000个分区合并成100各分区,将不会有Shuffle操作,100个新分区中的每一个将占据当前分区的10个。* 如果要求更多的分区个数,将保持为当前的分区个数。** 但是,当我们进行一个剧烈的合并,设置numPartitions = 1* 这可能导致你的计算比你想要的节点少,当numPartitions = 1时,只会在一个节点上合并;* 为了避免这种情况的发生,可以设置shuffle = true,这样将会添加一个shuffle操作,* 意味着当前的上游partitions将并行执行,无论当前的分区是几个** @note* 当shuffle = true,实际上,你可以合并到更多的分区。* 如果您有少量的分区,比如100个,可能有几个分区异常大,这个时候这种方法很有用。* 调用 coalesce(1000,shuffle = true) 将会生成1000个分区,数据分布使用散列分区(hash partitioner)。* 可选分区合并器必须是可序列化的。*/def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T] = withScope {require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")//1. 如果shuffle=trueif (shuffle) {// 将元素均匀地分布在输出分区上,从一个随机分区开始。val distributePartition = (index: Int, items: Iterator[T]) => {var position = (new Random(index)).nextInt(numPartitions)items.map { t =>// Note that the hash code of the key will just be the key itself.// The HashPartitioner will mod it with the number of total partitions.position = position + 1(position, t)}} : Iterator[(Int, T)]// 包含一个shuffle步骤,这样我们的上游tasks仍然是分布式的new CoalescedRDD(new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition),new HashPartitioner(numPartitions)),numPartitions,partitionCoalescer).values} else {//2. 如果shuffle=falsenew CoalescedRDD(this, numPartitions, partitionCoalescer)}}
repartition源码:
/*** 可以在此RDD中增加或降低并行度。在内部,这使用一个shuffle来重新分配数据。* 如果您正在减少这个RDD中的分区数量,考虑使用`coalesce`,这可以避免进行shuffle。*/def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)}
总结:
假设RDD有N个分区,需要重新划分成M个分区:
- N < M:一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true。
- N > M:并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false;在shuffl为false的情况下,如果M>N时,coalesce为无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系。
- N > M:并且两者相差悬殊,这时如果将shuffle设置为false,父子RDD是窄依赖关系,他们同处在一个Stage中,就可能造成spark程序的并行度不够,从而影响性能,如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
总之:如果shuff为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的。
Spark优化涉及点:
(1) 使用filter之后进行coalesce操作
通常对一个RDD执行filter算子过滤掉RDD中较多数据后(比如30%以上的数据),建议使用coalesce算子,手动减少RDD的partition数量,将RDD中的数据压缩到更少的partition中去。因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,而且此时处理的task越多,可能速度反而越慢。因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition。在某些场景下,对于性能的提升会有一定的帮助。
[
](https://blog.csdn.net/leen0304/article/details/78656269)
2.9、sortByKey、sortBy算子
sortBy是对标准的RDD进行排序。[在scala语言中,RDD与PairRDD没有太严格的界限。
/*** 源码* RDD.scala* Return this RDD sorted by the given key function.*/def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {this.keyBy[K](f).sortByKey(ascending, numPartitions).values}该函数最多可以传三个参数:第一个参数是一个函数,该函数的也有一个带T泛型的参数,返回类型和RDD中元素的类型是一致的;第二个参数是ascending,从字面的意思大家应该可以猜到,是的,这参数决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序;第三个参数是numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等,即为this.partitions.size。从sortBy函数的实现可以看出,第一个参数是必须传入的,而后面的两个参数可以不传入。而且sortBy函数函数的实现依赖于sortByKey函数,关于sortByKey函数后面会进行说明。keyBy函数也是RDD类中进行实现的,它的主要作用就是将将传进来的每个元素作用于f(x)中,并返回tuples类型的元素,也就变成了Key-Value类型的RDD了。例子1:def sortBy(): Unit = {val conf = new SparkConf().setMaster("local").setAppName("sortBy")val sc = new SparkContext(conf)val rdd = sc.makeRDD(List(("a",0),("d",5),("d",2),("c",1),("b",2),("b",0)),4)// 按照tuple2的第二个元素降序排列val res =rdd.sortBy(_._2,false,2)res.foreach(x=> print(x+ " "))}// 结果:(d,5) (d,2) (b,2) (c,1) (a,0) (b,0)
sortByKey函数是对PairRDD进行排序,也就是有Key和Value的RDD。
//源码def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] = self.withScope{val part = new RangePartitioner(numPartitions, self, ascending)new ShuffledRDD[K, V, V](self, part).setKeyOrdering(if (ascending) ordering else ordering.reverse)}从函数的实现可以看出,它主要接受两个函数,含义和sortBy一样,这里就不进行解释了。该函数返回的RDD一定是ShuffledRDD类型的,因为对源RDD进行排序,必须进行Shuffle操作,而Shuffle操作的结果RDD就是ShuffledRDD。其实这个函数的实现很优雅,里面用到了RangePartitioner,它可以使得相应的范围Key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中数据的排序用到了标准的sort机制,避免了大量数据的shuffle。例子:def sortByKey(): Unit = {val conf = new SparkConf().setMaster("local").setAppName("sortBy")val sc = new SparkContext(conf)val rdd = sc.makeRDD(List((11,0),(10,5),(4,2),(6,1),(20,2),(8,0)))val res =rdd.sortByKey(true,1)res.foreach(x => print(x + " "))}// 结果:(4,2) (6,1) (8,0) (10,5) (11,0) (20,2)
2.10、union、cartesian 笛卡尔、intersection 交集、subtract 差集、zip拉链
val rdd1 = sc.parallelize(List(“a”,”b”,”b”,”c”))
val rdd2 = sc.parallelize(List(“c”,”d”,”e”))
1、union:返回一个新的数据集,该数据集包含源数据集和参数中的元素的联合,不去重。要求两个RDD数据类型一致。
scala> val unionRdd = rdd1.union(rdd2)scala> unionRdd.collectres2: Array[String] = Array(a, b, b, c, c, d, e)
2、cartesian 笛卡尔:cartesian(otherDataset) 当调用类型T和U的数据集时,返回(T,U)对的数据集(所有对元素)。
scala> val cartesainRdd = rdd1.cartesian(rdd2)scala> cartesainRdd.collectres5: Array[(String, String)] = Array((a,c), (a,d), (a,e),(b,c), (b,d), (b,e),(b,c), (b,d), (b,e),(c,c), (c,d), (c,e))
3、intersection 交集:intersection(otherDataset) 返回一个新的RDD,它包含源数据集中元素和参数的交集,去重。要求两个RDD数据类型一致。
scala> val intersectionRdd = rdd1.intersection(rdd2)scala> intersectionRdd.collectres6: Array[String] = Array(c)
4、subtract 差集:rdd1.subtract (rdd2,2) 返回在rdd1中出现,但是不在rdd2中出现的元素,不去重。要求两个RDD数据类型一致。
scala> val subtractRdd = rdd1.subtract(rdd2)scala> subtractRdd.collectres7: Array[String] = Array(b, b, a)
5、zip拉链:zip函数用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
scala> var rdd1 = sc.makeRDD(1 to 5,2)scala> var rdd2 = sc.makeRDD(Seq("A","B","C","D","E"),2)scala> var rdd3 = sc.makeRDD(Seq("A","B","C","D","E"),3)scala> rdd1.zip(rdd2).collectres0: Array[(Int, String)] = Array((1,A), (2,B), (3,C), (4,D), (5,E))scala> rdd2.zip(rdd1).collectres1: Array[(String, Int)] = Array((A,1), (B,2), (C,3), (D,4), (E,5))scala> rdd1.zip(rdd3).collectjava.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions//如果两个RDD分区数不同,则抛出异常 , rdd2.zip(rdd3)也会报错
2.11、reduce算子
reduce(func) 是对JavaRDD的操作
使用函数func聚合rdd的元素(它需要两个参数并返回一个参数)。这个函数应该是可交换的,并且是相关联的,这样它就可以并行地计算出来。
val rdd1 = sc.parallelize(List("a","b","b","c"))scala> val res = rdd1.reduce(_+"-"+_)res: String = b-c-a-b
三、Key-Value转换算子
3.1、partitionBy算子
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
该函数根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区。
scala> var rdd1 = sc.makeRDD(Array((1,"A"),(2,"B"),(3,"C"),(4,"D")),2)rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[23] at makeRDD at :21scala> rdd1.partitions.sizeres20: Int = 2//查看rdd1中每个分区的元素scala> rdd1.mapPartitionsWithIndex{| (partIdx,iter) => {| var part_map = scala.collection.mutable.Map[String,List[(Int,String)]]()| while(iter.hasNext){| var part_name = "part_" + partIdx;| var elem = iter.next()| if(part_map.contains(part_name)) {| var elems = part_map(part_name)| elems ::= elem| part_map(part_name) = elems| } else {| part_map(part_name) = List[(Int,String)]{elem}| }| }| part_map.iterator|| }| }.collectres22: Array[(String, List[(Int, String)])] = Array((part_0,List((2,B), (1,A))), (part_1,List((4,D), (3,C))))//(2,B),(1,A)在part_0中,(4,D),(3,C)在part_1中//使用partitionBy重分区scala> var rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(2))rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[25] at partitionBy at :23scala> rdd2.partitions.sizeres23: Int = 2//查看rdd2中每个分区的元素scala> rdd2.mapPartitionsWithIndex{| (partIdx,iter) => {| var part_map = scala.collection.mutable.Map[String,List[(Int,String)]]()| while(iter.hasNext){| var part_name = "part_" + partIdx;| var elem = iter.next()| if(part_map.contains(part_name)) {| var elems = part_map(part_name)| elems ::= elem| part_map(part_name) = elems| } else {| part_map(part_name) = List[(Int,String)]{elem}| }| }| part_map.iterator| }| }.collectres24: Array[(String, List[(Int, String)])] = Array((part_0,List((4,D), (2,B))), (part_1,List((3,C), (1,A))))//(4,D),(2,B)在part_0中,(3,C),(1,A)在part_1中
注意:如果转换前的分区器 和 分区数 相同,使用partitionBy不会产生新的RDD。
3.2、reduceByKey算子
reduceByKey(func, [numTasks]) 是对JavapairRDD的操作;
针对(K, V) 的rdd,使用给定的reduce函数func聚合每个K的值,返回(K, V);可通过第二个参数定义Tasks个数。
val scoreList = Array(
Tuple2("class1", 90),
Tuple2("class1", 60),
Tuple2("class2", 60),
Tuple2("class2", 50)
)
val scoreRdd = sc.parallelize(scoreList)
val resRdd = scoreRdd.reduceByKey(_ + _)
// val resRdd = scoreRdd.reduceByKey((x:Int , y:Int) => {x+y}) // x,y代表value
resRdd.foreach(res => println(res._1 + ":" + res._2))
# ----------------- 结果
class1:150
class2:110
3.3、groupByKey算子
在一个PairRDD或(k,v)RDD上调用,返回一个(k,Iterable
@note groupByKey很消耗资源,如果要对每个Key的values进行聚合(比如求和或平均值),
* 用 aggregateByKey 或者 reduceByKey 代替,将会更节省性能。
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey不应该使用map side combine ,mapSideCombine = false
// 因为map side combine 并不会减少数据的shuffle次数,
// 并且要求将map side 的数据放入一张hash表中,导致 old gen中有更多的对象;
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
3.3.1、reduceByKey和groupByKey的不同点

3.4、aggregateByKey算子
rdd.aggregateByKey(3, seqFunc, combFunc) :可以根据规则将分区内的计算和分区间的计算区分开,而reduceByKey和groupByKey则不行。
其中第一个函数是初始值,3代表每次分完组之后的每个组的初始值。
seqFunc:代表combine的聚合逻辑,每一个mapTask的结果的聚合成为combine,即是分区内的计算规则。
combFunc:reduce端大聚合的逻辑,即是分区间的计算规则。
ps:aggregateByKey默认分组
object AggregateByKeyRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("AggregateByKeyRDD")
val ctx = new SparkContext(sparkConf)
val rdd: RDD[(Int, Int)] = ctx.makeRDD(List((1,1),(1,2),(2,1),(2,3),(2,4),(1,7)),2)
val mrdd = rdd.mapPartitionsWithIndex{
case (index,iter) => {
iter.map((_,"分区号为:"+index))
}
}
mrdd.collect.foreach(println)
val result = rdd.aggregateByKey(0) (
(x,y)=>{
math.max(x,y) // 先求出每个分区的最大值
},(e,k)=>{
e+k // 再把每个分区的计算出来的结果(最大值)进行相加
})
result.collect().foreach(println)
ctx.stop()
}
}
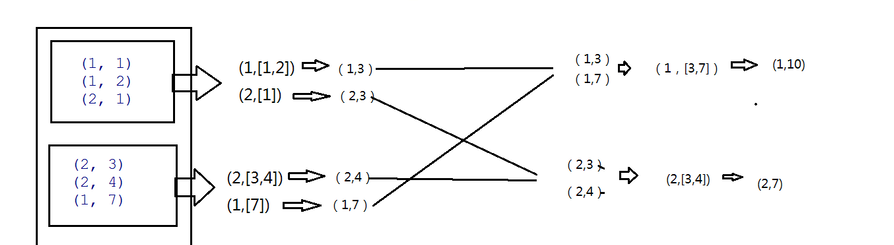
求每个key对应的平均值:
//def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
val aggRDD: RDD[(String,(Int,Int))] = intRDD.aggregateByKey((0,0))(
(x,y)=>{ //需要了解x、y代表的值,这里x表示初始值(这里为tupple类型),y表示每个key对应的value(这里为Int类型)
(x._1+y,x._2+1)
},
(x,y)=>{
(x._1+y._1,x._2+y._2) //x、y代表seqOp函数的返回值
}
)
//def mapValues[U](f: V => U): RDD[(K, U)]
val res: RDD[(String, Int)] = aggRDD.mapValues(x => {x._1/x._2})
3.5、foldByKey算子
如果 aggregateByKey 分区内和分区间的计算逻辑相同,则可以使用foldByKey算子进行代替,简化了操作。
rdd.foldByKey(1)(_+_)
3.6、combineByKey算子
/**
* @see [[combineByKeyWithClassTag]]
*
* 具体实现在combineByKeyWithClassTag中
*/
def combineByKey[C](
createCombiner: V => C, //组合器函数,输入参数为RDD[K,V]中的V
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C, //合并组合器函数,对多个节点上的数据合并
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners,
partitioner, mapSideCombine, serializer)(null)
}
参数:
createCombiner:组合器函数,用于将V类型转换成C类型,输入参数为RDD[K,V]中的V,输出为C
mergeValue:合并值函数,将一个C类型和一个V类型值合并成一个C类型,输入参数为(C,V),输出为C
mergeCombiners:合并组合器函数,用于将两个C类型值合并成一个C类型,输入参数为(C,C),输出为C
numPartitions:结果RDD分区数,默认保持原有的分区数
partitioner:分区函数,默认为HashPartitioner
mapSideCombine:是否需要在Map端进行combine操作,类似于MapReduce中的combine,默认为true
求每个key对应的平均值:
val intRDD = ctx.makeRDD(List(("a",5),("a",2),("b",1),("c",1),("c",5),("d",8),("a",2)),2)
val aggRDD: RDD[(String,(Int,Int))] = intRDD.combineByKey(
x => (x,1), // 这里是类型转换函数,把Int类型的value转换为tupple类型的值,也可以想当于aggregateByKey的初始值
(x,y)=>{
(x._1+y,x._2+1)
},
(x,y)=>{
(x._1+y._1,x._2+y._2)
}
)
val res: RDD[(String, Int)] = aggRDD.mapValues(x => {x._1/x._2})
res.collect().foreach(println)
3.7、countByKey 和 count 算子
count() 返回rdd中的元素个数。
countByKey() 只有对类型(K,V)类型的RDDs上才可用。返回一个Map(K,Long)对每个键的计数。
val rdd1 = sc.parallelize(List("a","b","b","c"))
scala> val res = rdd1.count
res: Long = 4
-------------------------------------------------------------
val scoreList = Array(
Tuple2("class1", 90),
Tuple2("class1", 60),
Tuple2("class2", 60),
Tuple2("class2", 50)
)
val scoreRdd = sc.parallelize(scoreList)
scala> val res = scoreRdd.countByKey
res: scala.collection.Map[String,Long] = Map(class2 -> 2, class1 -> 2)
3.8、cogroup算子
groupByKey是对单个 RDD 的数据进行分组,
cogroup() 是对多个共享同一个键的 RDD 进行分组
例如 :
RDD1.cogroup(RDD2) 会将RDD1和RDD2按照相同的key进行分组,得到(key,RDD[key,Iterable[value1],Iterable[value2]])的形式
cogroup也可以多个进行分组
例如RDD1.cogroup(RDD2,RDD3,…RDDN), 可以得到(key,Iterable[value1],Iterable[value2],Iterable[value3],…,Iterable[valueN])
注:如果连接的RDD之间的分区数不相同,会有shuffle出现,造成效率比较低。
3.9、mapValues算子
针对于(K,V)形式的类型只对V进行操作,类似map。
object oper {
def main(args: Array[String]): Unit = {
val config:SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount")
// 创建上下文对象
val sc = new SparkContext(config)
// mapValues算子
val arrayRdd = sc.makeRDD(Array((4,"刘六"),(2,"李四"),(3,"王五"),(1,"张三")))
val mapRdd = arrayRdd.mapValues(_+"?")
mapRdd.collect().foreach(println)
}
}
输入
(4,"刘六") (2,"李四") (3,"王五") (1,"张三")
输出
(4,"刘六?")
(2,"李四?")
(3,"王五?")
(1,"张三?")
四、RDD实战
4.1、统计出每个省份每个广告点击率TOP3
/**
* 需求:
* 从 agent.log 获取数据进行分析,统计出每个省份每个广告点击率TOP3
* 数据格式:时间戳 省份 城市 用户 广告,以空格分隔
*/
object CountAdDemo {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","D:\\hadoop")
val conf = new SparkConf().setAppName("CountAdDemo").setMaster("local[*]")
val ctx = new SparkContext(conf)
// 获取原始数据
val inputRDD: RDD[String] = ctx.textFile("./data/agent.log")
// 转换数据结构,组合的数据结构结构为 ((城市,广告),1)
val mapRDD = inputRDD.map(line => {
val arr: Array[String] = line.split(" ")
((arr(1),arr(4)),1)
})
// 聚合,相同key的次数相加
val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_+_)
//再次转换结构,为 (城市 , (广告,广告数))
val mapRDD2: RDD[(String, (String, Int))] = reduceRDD.map(x => {
(x._1._1, (x._1._2, x._2))
})
// mapRDD2.collect().foreach(println)
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD2.groupByKey()
/*val res: Array[(String, Iterable[(String, Int)])] = groupRDD.sortBy(x => {
x._2
}).take(3)
res.foreach(println)*/
//最后通过mapValues对tupple里面的List进行排序,取前3条数据
val res2: RDD[(String, List[(String, Int)])] = groupRDD.mapValues(iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
})
res2.collect().foreach(println)
ctx.stop()
}
}
[
](https://blog.csdn.net/u013384984/article/details/79443545)

若有收获,就点个赞吧
0 人点赞
