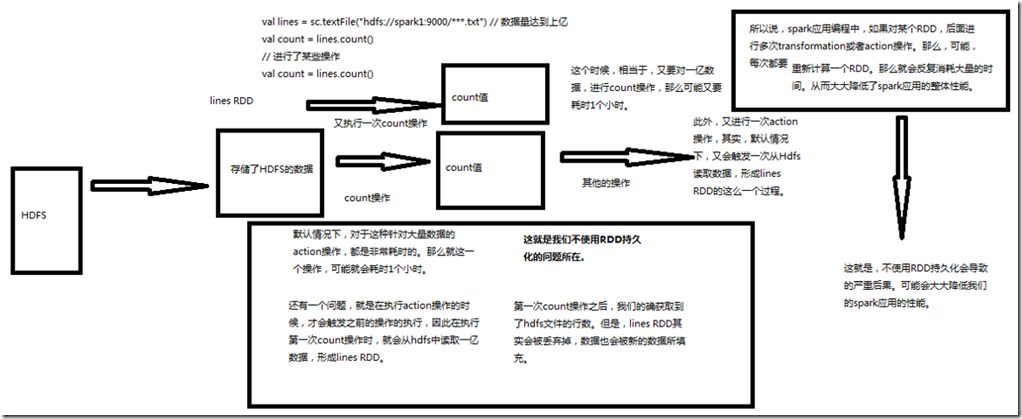
一、不使用持久化原因
二、持久化原理
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对 该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不 需要反复计算多次该RDD。
巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该RDD 将会被缓存在计算节点的内存中,并供后面重用。而且Spark的持久化机制还是自动容错的, 如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存 中。如果需要从内存中清除缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。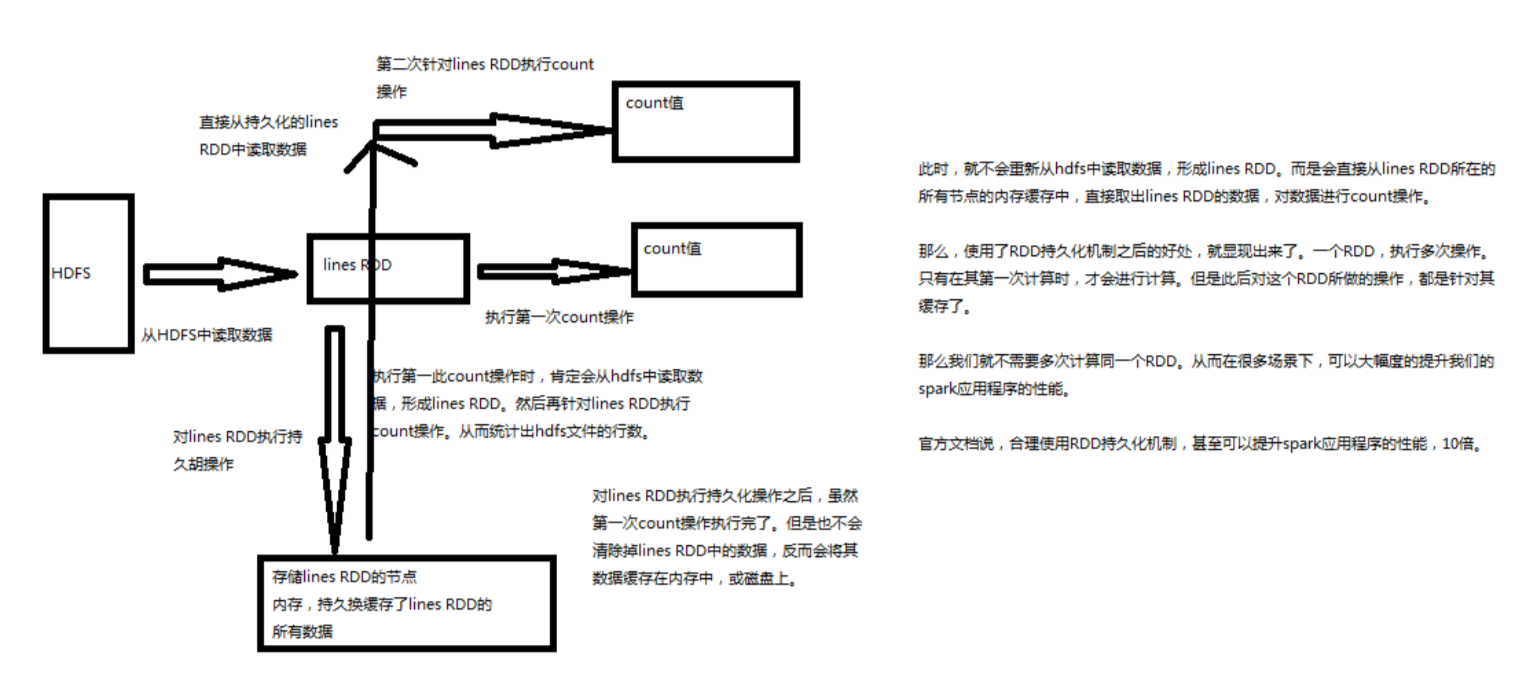
三、RDD持久化策略
RDD持久化是可以手动选择不同的策略的。比如可以将RDD持久化在内存中、持久化到磁盘上、使用序列化的方式持久化,多持久化的数据进行多路复用。
只要在调用persist()时传入对应的StorageLevel即可。
case "NONE" => NONEcase "DISK_ONLY" => DISK_ONLYcase "DISK_ONLY_2" => DISK_ONLY_2case "MEMORY_ONLY" => MEMORY_ONLYcase "MEMORY_ONLY_2" => MEMORY_ONLY_2case "MEMORY_ONLY_SER" => MEMORY_ONLY_SERcase "MEMORY_ONLY_SER_2" => MEMORY_ONLY_SER_2case "MEMORY_AND_DISK" => MEMORY_AND_DISKcase "MEMORY_AND_DISK_2" => MEMORY_AND_DISK_2case "MEMORY_AND_DISK_SER" => MEMORY_AND_DISK_SERcase "MEMORY_AND_DISK_SER_2" => MEMORY_AND_DISK_SER_2case "OFF_HEAP" => OFF_HEAP
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。 |
| MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 |
如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。 |
四、如何选择RDD持久化策略
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
五、持久化容错
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD 的一系列转换,丢失的数据会被重算,由于RDD 的各个Partition 是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部Partition。
Spark 会自动对一些Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist 或cache。
六、RDD的checkpoint
6.1、基本概述
RDD的数据可以持久化,但是持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的,例如磁盘损坏、机器出现故障重新启动时需要根据血缘关系进行数据恢复,这样效率就比较低了。
Checkpoint(检查点,相当于快照)的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在HDFS上,这就借助了HDFS天生的高容错、高可靠实现数据最大程度的安全。当下次出现故障时可以从checkpoint的RDD直接恢复数据,比之前的效率高了不少。
spark中的checkpoint机制主要有两种作用,一是对RDD做checkpoint,可以将该RDD触发计算并将其数据保存到hdfs目录中去,可以斩断其RDD的依赖链,这对于频繁增量更新的RDD或具有很长lineage的RDD具有明显的效果。另一种用途是用于Spark Streaming用于保存DStreamGraph及其配置,以便Driver崩溃后的恢复。
6.2、基本使用
sc.setCheckpointDir(checkpointDir.toString) //设置checkpoint的路径,一般为hdfs;如果为本地文件系统,涉及到多个分区时,每个executor只能把属于自己分区的数据保存起来,做数据恢复时只能恢复属于自己那部分的,而不是全部的数据!val rdd = sc.makeRDD(1 to 20, numSlices = 1)rdd.checkpoint() //直接在RDD上调用checkpoint的方法即可
6.3、checkpoint写流程
可以看到checkpoint使用非常简单,设置checkpoint目录,然后调用RDD的checkpoint方法。针对checkpoint的写入流程,主要有以下四个问题:
- Q1:RDD中的数据是什么时候写入的?是在rdd调用checkpoint方法时候吗?
- Q2:在做checkpoint的时候,具体写入了哪些数据到HDFS了?
- Q3:在对RDD做完checkpoint以后,对做RDD的本省又做了哪些收尾工作?
- Q4:实际过程中,使用RDD做checkpoint的时候需要注意什么问题?
弄清楚了以上四个问题,我想对checkpoint的写过程也就基本清楚了。接下来将一一回答上面提出的问题。
A1:首先看一下RDD中checkpoint方法,可以看到在该方法中是只是新建了一个ReliableRDDCheckpintData的对象,并没有做实际的写入工作。实际触发写入的时机是在runJob生成改RDD后,调用RDD的doCheckpoint方法来做的。
A2:在经历调用RDD.doCheckpoint → RDDCheckpintData.checkpoint → ReliableRDDCheckpintData.doCheckpoint → ReliableRDDCheckpintData.writeRDDToCheckpointDirectory后,在writeRDDToCheckpointDirectory方法中可以看到:将作为一个单独的任务(RunJob)将RDD中每个parition的数据依次写入到checkpoint目录(writePartitionToCheckpointFile),此外如果该RDD中的partitioner如果不为空,则也会将该对象序列化后存储到checkpoint目录。所以,在做checkpoint的时候,写入的hdfs中的数据主要包括:RDD中每个parition的实际数据,以及可能的partitioner对象(writePartitionerToCheckpointDir)。
A3:在写完checkpoint数据到hdfs以后,将会调用rdd的markCheckpoined方法,主要斩断该rdd的对上游的依赖,以及将paritions置空等操作。
A4:通过A1,A2可以知道,在RDD计算完毕后,会再次通过RunJob将每个partition数据保存到HDFS。这样RDD将会计算两次,所以为了避免此类情况,最好将RDD进行cache。即1.1中rdd的推荐使用方法如下:
sc.setCheckpointDir(checkpointDir.toString)val rdd = sc.makeRDD(1 to 20, numSlices = 1)rdd.cache() //先进行cacherdd.checkpoint()
6.4、checkpoint 读流程
在做完checkpoint后,获取原来RDD的依赖以及partitions数据都将从CheckpointRDD中获取,而不需要再根据rdd的依赖关系去重新计算,这样节省了很多计算。也就是说获取原来rdd中每个partition数据以及partitioner等对象,都将转移到CheckPointRDD中(可以从RDD的血缘依赖看出)。
在CheckPointRDD的一个具体实现ReliableRDDCheckpintRDD中的compute方法中可以看到,将会从hdfs的checkpoint目录中恢复之前写入的partition数据。而partitioner对象(如果有)也会从之前写入hdfs的paritioner对象恢复。
总的来说,checkpoint读取过程是比较简单的。
6.5、checkpoint流程分析源码
https://zhuanlan.zhihu.com/p/87115691
七、缓存和检查点区别
1) Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2) Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在HDFS 等容错、高可用的文件系统,可靠性高。
3) 建议对checkpoint()的RDD 使用Cache 缓存,这样checkpoint 的job 只需从Cache 缓存中读取数据即可,否则需要再从头计算一次RDD。

若有收获,就点个赞吧
0 人点赞
