Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
- RDD : 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
一、RDD概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性:
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD 里面封装计算逻辑
- 可分区、并行计算
Driver将RDD转换成Task发送给Executer执行 流程图: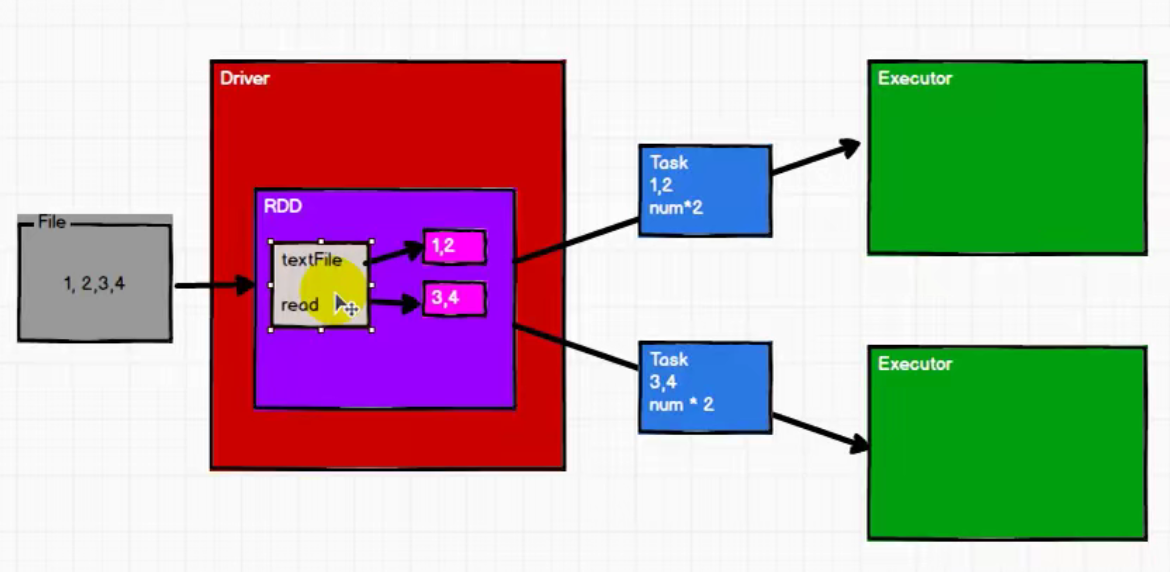
RDD的数据只有在最后调用collect时,才会正在执行业务逻辑操作,之前的操作都是功能的扩展。
RDD和IO之间的关系,类似于装饰者模式,每一层功能递进关系。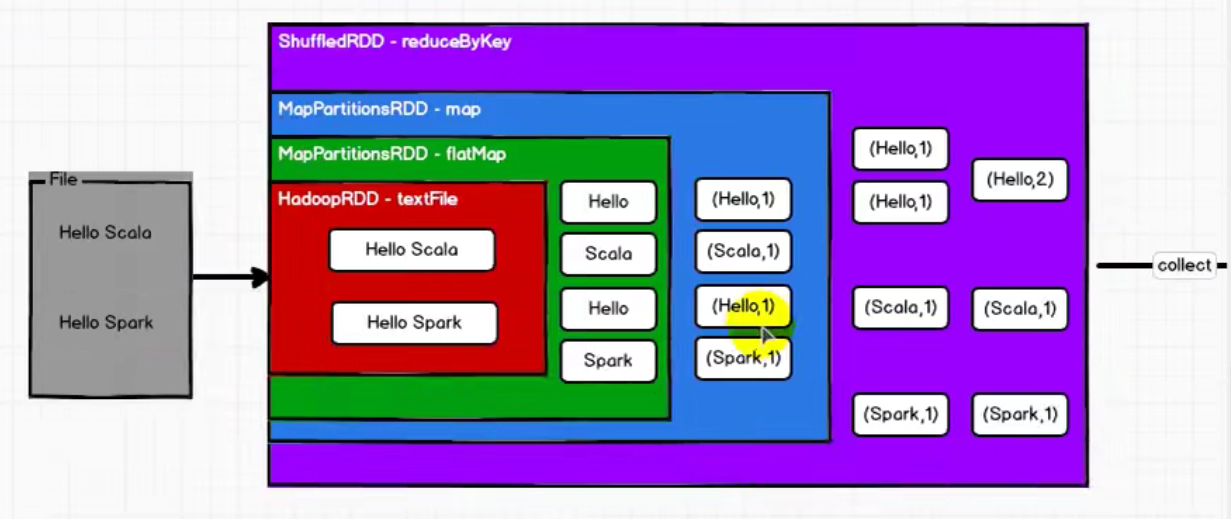
二、RDD五大特性
- A list of partitions:RDD有很多partition构成;
解析:在spark计算中,有多少个partition就会对应有多少个task来执行;对于RDD 来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD 时指定RDD 的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
- A function for computing each split:对RDD做计算,相当于对RDD的每个split或partition做计算(Spark 中RDD 的计算是以分片为单位的)
解析:partition == split
例如:rdda.map(_ 2)等价于rdda.map(x => x 2),因为rdd有多个分片/分区,对rdd操作其实底层就是对每个分区/分片操作
- A list of dependencies on other RDDs:RDD之间存在一系列的依赖关系
解析:RDD 的每次转换都会生成一个新的RDD,所以RDD 之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark 可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD 的所有分区进行重新计算
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,比如可以按key的hash值分区;
Spark 中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value 的RDD , 才会有Partitioner, 非key-value 的RDD 的Parititioner 的值是None。Partitioner 函数不但决定了RDD 本身的分片数量, 也决定了parent RDD Shuffle 输出时的分片数量。
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file)
对于每个计算分片有用最佳计算位置;
对于一个HDFS 文件来说,这个列表保存的就是每个Partition 所在的块的位置。按照“移动数据不如移动计算”的理念,Spark 在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
2.1、源码解读
RDD:
abstract class RDD[T: ClassTag](@transient private var _sc: SparkContext,@transient private var deps: Seq[Dependency[_]]) extends Serializable with Logging{ ... }1)抽象类:不能直接使用,具体是实现该抽象类的子类完成2)T:泛型,里面可以装任意类型的元素3)logging:日志记录,2.0版本后不自带,需要自己写一个4)序列化:在分布式计算框架里,序列化框架性能的好坏直接影响整个框架性能的优劣
特性一:通过子类来实现rdd中包含了分区的集合是哪些,这个方法仅仅会被调用一次,所以用来实现耗时计算是安全的。
/*** Implemented by subclasses to return the set of partitions in this RDD. This method will only* be called once, so it is safe to implement a time-consuming computation in it.** The partitions in this array must satisfy the following property:* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`*/protected def getPartitions: Array[Partition]
特性二:通过子类来实现计算给定的分区。
/*** :: DeveloperApi ::* Implemented by subclasses to compute a given partition.*/@DeveloperApidef compute(split: Partition, context: TaskContext): Iterator[T]
特性三:通过子类来是实现此rdd的父RDD
/*** Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only* be called once, so it is safe to implement a time-consuming computation in it.*/protected def getDependencies: Seq[Dependency[_]] = deps
特性四:
/** Optionally overridden by subclasses to specify how they are partitioned. */@transient val partitioner: Option[Partitioner] = None
特性五:Nil:空List
/*** Optionally overridden by subclasses to specify placement preferences.*/protected def getPreferredLocations(split: Partition): Seq[String] = Nil
三、基础编程
3.1、RDD创建
1、从集合(内存)中创建 RDD:从集合中创建RDD,Spark 主要提供了两个方法:parallelize 和 makeRDDval sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")val sparkContext = new SparkContext(sparkConf)val rdd1 = sparkContext.parallelize( List(1,2,3,4) )val rdd2 = sparkContext.makeRDD( List(1,2,3,4) )rdd1.collect().foreach(println)从底层代码实现来讲,makeRDD 方法其实就是parallelize 方法2、从外部存储(文件)创建RDD:由外部存储系统的数据集创建RDD,包括:本地的文件系统、所有Hadoop支持的数据集,比如HDFS、HBase 等。val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")val sparkContext = new SparkContext(sparkConf)val fileRDD: RDD[String] = sparkContext.textFile("input")fileRDD.collect().foreach(println)sparkContext.stop()但是textFile最好不要用来读取小文件,会导致分区数多大,一般一个文件一个分区。3、专门用来读取小文件的,按照整个文件进行读取,而不是一行一行地读ctx.wholeTextFiles("hdfs://usr/local/data/file.txt")

若有收获,就点个赞吧
0 人点赞
