- 一、Spark Streaming + Kafka集成
- 二、kafka和spark stream集成的两种方式
- 三、如何管理Spark Streaming消费Kafka的偏移量
四、kafka分区,sparkStreaming的excutor,RDD分区的关系:">
四、kafka分区,sparkStreaming的excutor,RDD分区的关系:
一、Spark Streaming + Kafka集成
Apache Kafka将发布 - 订阅消息传递重新视为分布式的,分区的,复制的提交日志服务。在这里我们解释如何配置Spark Streaming以接收来自Kafka的数据。有两种方法 - 使用Receivers和Kafka的高级API的旧方法,以及不使用Receivers的新实验方法(在Spark 1.3中引入)。它们具有不同的编程模型,性能特征和语义保证,请阅读以获取更多详细信息。
1.1、方法1:基于接收者的方法
这种方法使用Receiver来接收数据。Receiver是使用Kafka高级消费者API实现的。与所有接收方一样,通过Receiver从Kafka接收的数据存储在Spark执行程序中,然后由Spark Streaming启动的作业处理数据。
但是,在默认配置下,这种方法可能会在失败时丢失数据(请参阅接收器的可靠性)。为确保零数据丢失,您必须另外启用Spark Streaming中的预写日志(在Spark 1.2中引入),同时保存所有收到的Kafka数据写入分布式文件系统(例如HDFS)的预先写入日志中,以便在发生故障时恢复所有数据。有关预写日志的更多详细信息,请参阅流编程指南中的部署。
要记住的要点:
1.Kafka中的主题分区与Spark Streaming中生成的RDD分区不相关。因此,增加主题专用分区KafkaUtils.createStream()的数量只会增加单个接收器中使用哪些主题的线程数量。在处理数据时不会增加Spark的并行性。有关更多信息,请参阅主文档。
2.多个Kafka输入DStream可以用不同的组和主题创建,用于使用多个接收器并行接收数据。
3.如果您使用HDFS等复制文件系统启用了写入日志,则接收到的数据已在日志中复制。因此,输入流到存储级别的存储级别StorageLevel.MEMORY_AND_DISK_SER(即使用 KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER))。
部署:与任何Spark应用程序一样,spark-submit用于启动您的应用程序。但是,Scala / Java应用程序和Python应用程序的细节略有不同。
对于Scala和Java应用程序,如果您使用SBT或Maven进行项目管理,那么将spark-streaming-kafka_2.10其及其依赖项打包到应用程序JAR中。确保spark-core_2.10并spark-streaming_2.10标记为provided依赖关系,因为这些已经存在于Spark安装中。然后使用spark-submit启动您的应用程序。
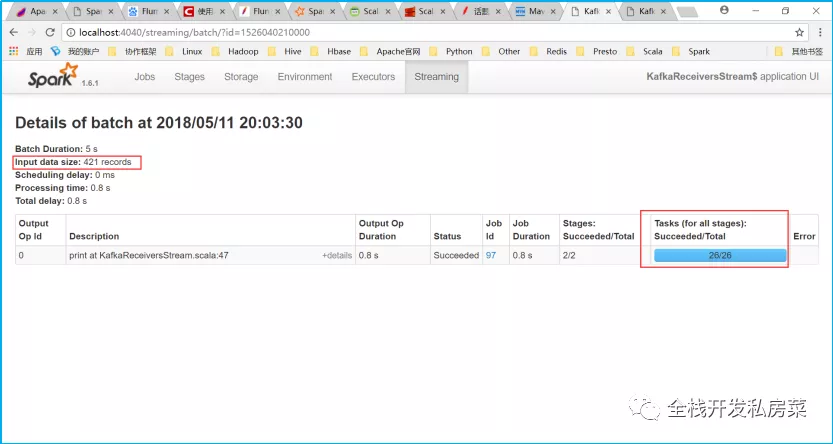
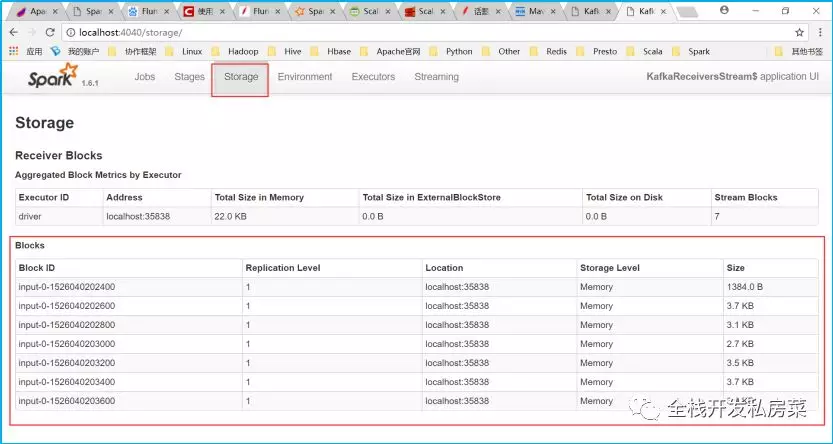
Spark Streaming(基于接收器)的工作流程
通过Receiver连接zookeeper从Kafka接收的数据并存储在Spark内存中(可对该缓存的方式进行设置),然后由SparkStreaming启动的作业,按照auto.offset.reset设置的参数开始消费处理数据。
1.2、方法2:直接法(无接收者)
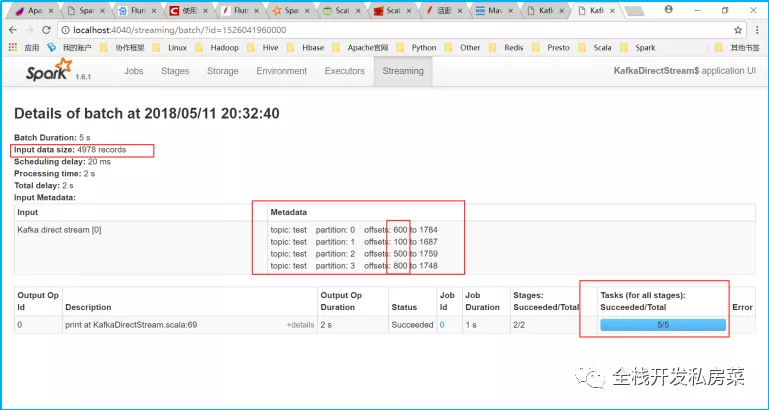
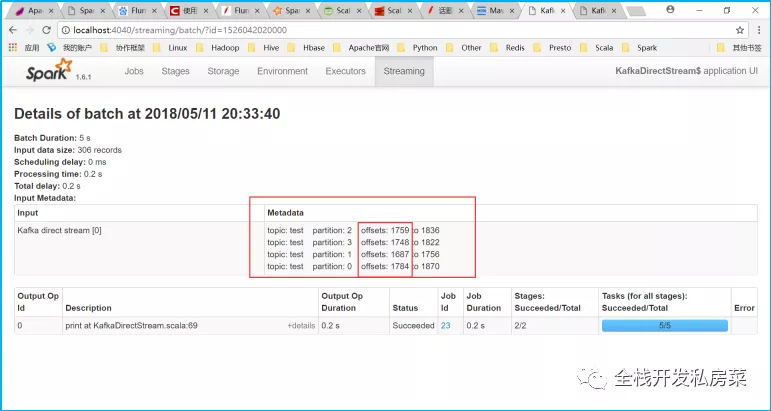
这种新的无接收器“直接”方法已在Spark 1.3中引入,以确保更强大的端到端保证。此方法不是使用接收器接收数据,而是定期查询Kafka每个主题+分区中的最新偏移量,并相应地定义要在每批中处理的偏移量范围。当处理数据的作业启动时,Kafka简单的使用者API用于从Kafka中读取定义的偏移范围(类似于从文件系统读取文件)。请注意,这是Spark 1.3中为Scala和Java API引入的实验性功能,适用于Python API的Spark 1.4。
这种方法比基于接收机的方法具有以下优点(即方法1)。
- 简化的并行性:无需创建多个输入Kafka流并将其合并。与此同时directStream,Spark Streaming将创建尽可能多的RDD分区,因为要使用Kafka分区,这将全部从Kafka并行读取数据。因此,Kafka和RDD分区之间有一对一的映射关系,这更易于理解和调整。
- 效率:在第一种方法中实现零数据丢失需要将数据存储在预写日志中,这会进一步复制数据。这实际上是效率低下的,因为数据被有效地复制了两次 - 一次是由Kafka(Kafka)进行的,而另一次是通过预先写入日志(Write Ahead Log)。因为没有接收器,所以第二种方法消除了这个问题,因此不需要预先写入日志。只要您拥有足够的Kafka保留,就可以从Kafka恢复信息。
- 正好一次语义:第一种方法使用Kafka的高级API在Zookeeper中存储消耗的偏移量。传统上这是从Kafka消费数据的方式。虽然这种方法(结合提前写入日志)可以确保零数据丢失(即至少一次语义),但在某些失败情况下,某些记录可能会消耗两次的可能性很小。发生这种情况是因为Spark Streaming可靠接收的数据与Zookeeper跟踪的偏移之间不一致。因此,在第二种方法中,我们使用了不使用Zookeeper的简单Kafka API。在其检查点内,Spark Streaming跟踪偏移量。这消除了Spark Streaming和Zookeeper / Kafka之间的不一致性,因此Spark Streaming每次记录都会在发生故障时有效地收到一次。为了实现完全一次的语义输出结果,主编程指南中输出操作的语义以获取更多信息)。
请注意,这种方法的一个缺点是它不会更新Zookeeper中的偏移量,因此基于Zookeeper的Kafka监控工具不会显示进度。但是,您可以在每个批次中访问由此方法处理的偏移量,并自己更新Zookeeper(请参见下文)。在Kafka参数中,您必须指定metadata.broker.list或者bootstrap.servers。默认情况下,它将从每个Kafka分区的最新偏移开始消耗。如果您将auto.offset.reset参数中的配置设置为smallest,则它将从最小偏移量开始消耗。
二、kafka和spark stream集成的两种方式
2.1、第一种(接收者)
package com.spark.streamingimport kafka.serializer.StringDecoderimport org.apache.spark.storage.StorageLevelimport org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}import org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.{SparkConf, SparkContext}/*** 基于接收者的方法*/object KafkaReceiversStream{def main(args:Array[String]):Unit={val conf=new SparkConf().setAppName(getClass.getSimpleName).setMaster("local[2]")val sc=SparkContext.getOrCreate(conf)val ssc=new StreamingContext(sc,Seconds(5))val zkQuorum="learn01.com:2181"val groupId="StreamingTest"val kafkaParams:Map[String,String]=Map[String,String]("zookeeper.connect"->zkQuorum,"group.id"->groupId,"auto.offset.reset"->"smallest","zookeeper.connection.timeout.ms"->"10000")val topics:Map[String,Int]=Map[String,Int]("test"->4)val stream=KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics,storageLevel=StorageLevel.MEMORY_ONLY)val count=stream.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)count.print()ssc.start()ssc.awaitTermination()}}
2.2、第二种(无接收者)
package com.spark.streamingimport com.spark.streaming.KafkaReceiversStream.getClassimport kafka.common.TopicAndPartitionimport kafka.message.MessageAndMetadataimport kafka.serializer.StringDecoderimport org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.streaming.kafka.KafkaUtils/*** 直接法(无接收者)*/object KafkaDirectStream {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName(getClass.getSimpleName).setMaster("local[2]")val sc = SparkContext.getOrCreate(conf)val ssc = new StreamingContext(sc, Seconds(5))/*** 要求使用的实际上是生产者的配置信息,因此连的不是zookeeper,* 而是kafka的broker.list,这种api要求消费者自己给定offset,自己保存offset*/val kafkaParams: Map[String, String] = Map[String, String]("metadata.broker.list" -> "learn01.com:9092,learn01.com:9093,learn01.com:9094,learn01.com:9095")//消费者自己给定offsetval fromOffsets: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long](TopicAndPartition("test",0) -> 600,TopicAndPartition("test",1) -> 100,TopicAndPartition("test",2) -> 500,TopicAndPartition("test",3) -> 800)/*** 其实就是消费者数据* 包含了记录所属的topic;* 记录所属的topic的对应分区;* 记录所属的topic的对应分区中的偏移量offset* 记录数据的key* 记录数据的value*/val messageHandler: MessageAndMetadata[String, String] => String = {msg:MessageAndMetadata[String, String] =>{// msg.topic //获取该条记录所属的topic// msg.partition //获取该条记录所属的topic的对应分区// msg.offset //获取该条记录所属的topic的对应分区中的偏移量offset// msg.key()msg.message()}}val stream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder,String](ssc,kafkaParams,fromOffsets,messageHandler)val count = stream.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)count.print()ssc.start()ssc.awaitTermination()}}
2.3、二者的区别
接收者:
1. 需要连接zookeeper,从zookeeper中获取Kafka消费者的偏移量offset
2. 接收到消费者的数据需缓存在Spark内存中(缓存方式可设置)
3. 一般要求对数据进行备份,防止在失败时丢失数据,为确保零数据丢失,必须另外启用SparkStreaming中的预写日志,一定程度上造成了性能的降低
非接收者:
1. 直接从Kafka中消费数据,无需缓存,并且Kafka和RDD分区之间有一对一的映射关系
2. 偏移量offset由SparkStreaming保存并更新
3. 不需要预先写入日志对数据进行备份,SparkStreaming会跟踪偏移量offset,每次记录都会在发生故障时有效地收到一次,有效的提升了性能
三、如何管理Spark Streaming消费Kafka的偏移量
如何处理其偏移量的问题,由于spark streaming自带的checkpoint弊端非常明显,所以一些对数据一致性要求比较高的项目里面,不建议采用其自带的checkpoint来做故障恢复。
在spark streaming1.3之后的版本支持direct kafka stream,这种策略更加完善,放弃了原来使用Kafka的高级API自动保存数据的偏移量,之后的版本采用Simple API也就是更加偏底层的api,我们既可以用checkpoint来容灾,也可以通过低级api来获取偏移量自己管理偏移量,这样以来无论是程序升级,还是故障重启,在框架端都可以做到Exact One准确一次的语义。
手动管理offset的注意点:
- 第一次项目启动的时候,因为zk里面没有偏移量,所以使用KafkaUtils直接创建InputStream,默认是从最新的偏移量开始消费,这一点可以控制。
- 如果非第一次启动,zk里面已经存在偏移量,所以我们读取zk的偏移量,并把它传入到KafkaUtils中,从上次结束时的偏移量开始消费处理。
- 在foreachRDD里面,对每一个批次的数据处理之后,再次更新存在zk里面的偏移量
注意上面的3个步骤,1和2只会加载一次,第3个步骤是每个批次里面都会执行一次。
/****** @param ssc StreamingContext* @param kafkaParams 配置kafka的参数* @param zkClient zk连接的client* @param zkOffsetPath zk里面偏移量的路径* @param topics 需要处理的topic* @return InputDStream[(String, String)] 返回输入流*/def createKafkaStream(ssc: StreamingContext,kafkaParams: Map[String, String],zkClient: ZkClient,zkOffsetPath: String,topics: Set[String]): InputDStream[(String, String)]={//目前仅支持一个topic的偏移量处理,读取zk里面偏移量字符串val zkOffsetData=KafkaOffsetManager.readOffsets(zkClient,zkOffsetPath,topics.last)val kafkaStream = zkOffsetData match {case None => //如果从zk里面没有读到偏移量,就说明是系统第一次启动log.info("系统第一次启动,没有读取到偏移量,默认就最新的offset开始消费")//使用最新的偏移量创建DirectStreamKafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)case Some(lastStopOffset) =>log.info("从zk中读取到偏移量,从上次的偏移量开始消费数据......")val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key, mmd.message)//使用上次停止时候的偏移量创建DirectStreamKafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, lastStopOffset, messageHandler)}kafkaStream//返回创建的kafkaStream}
主要是针对第一次启动,和非首次启动做了不同的处理。
然后看下第三个步骤的代码:主要是更新每个批次的偏移量到zk中。
/***** 保存每个批次的rdd的offset到zk中* @param zkClient zk连接的client* @param zkOffsetPath 偏移量路径* @param rdd 每个批次的rdd*/def saveOffsets(zkClient: ZkClient, zkOffsetPath: String, rdd: RDD[_]): Unit = {//转换rdd为Array[OffsetRange]val offsetsRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges//转换每个OffsetRange为存储到zk时的字符串格式 : 分区序号1:偏移量1,分区序号2:偏移量2,......val offsetsRangesStr = offsetsRanges.map(offsetRange => s"${offsetRange.partition}:${offsetRange.untilOffset}").mkString(",")log.debug(" 保存的偏移量: "+offsetsRangesStr)//将最终的字符串结果保存到zk里面ZkUtils.updatePersistentPath(zkClient, zkOffsetPath, offsetsRangesStr)}
四、kafka分区,sparkStreaming的excutor,RDD分区的关系:
首先要明确数据的流向:项目中的数据从kafka——>sparkStreaming————>RDD
(1) kafka中的 topic 的 patition 分区的设置,kafka 的 partition 分区数 ,sparkStreaming 直连方式从kafka中拉数据的话,sparkStreaming 创建的 RDD 的分区数和 kafka partitions分区数是一致的 ,而RDD的分区数对应着集群中的task的数量,也就是对应着 excutor 的数量和其核数。
(2)sparkStreaming 的 excutor 数决定着集群并发执行 task 的数量,task用来执行 RDD 的 patition 的数据的,一个task 跑一个RDD 分区数据,因此kafka patition数量设置好了的前提下,尽量让其一批执行完毕。
(3)RDD分区,在直连方式下,创建的RDD partitions数与kafka partitions数一致。

若有收获,就点个赞吧
0 人点赞
