体系
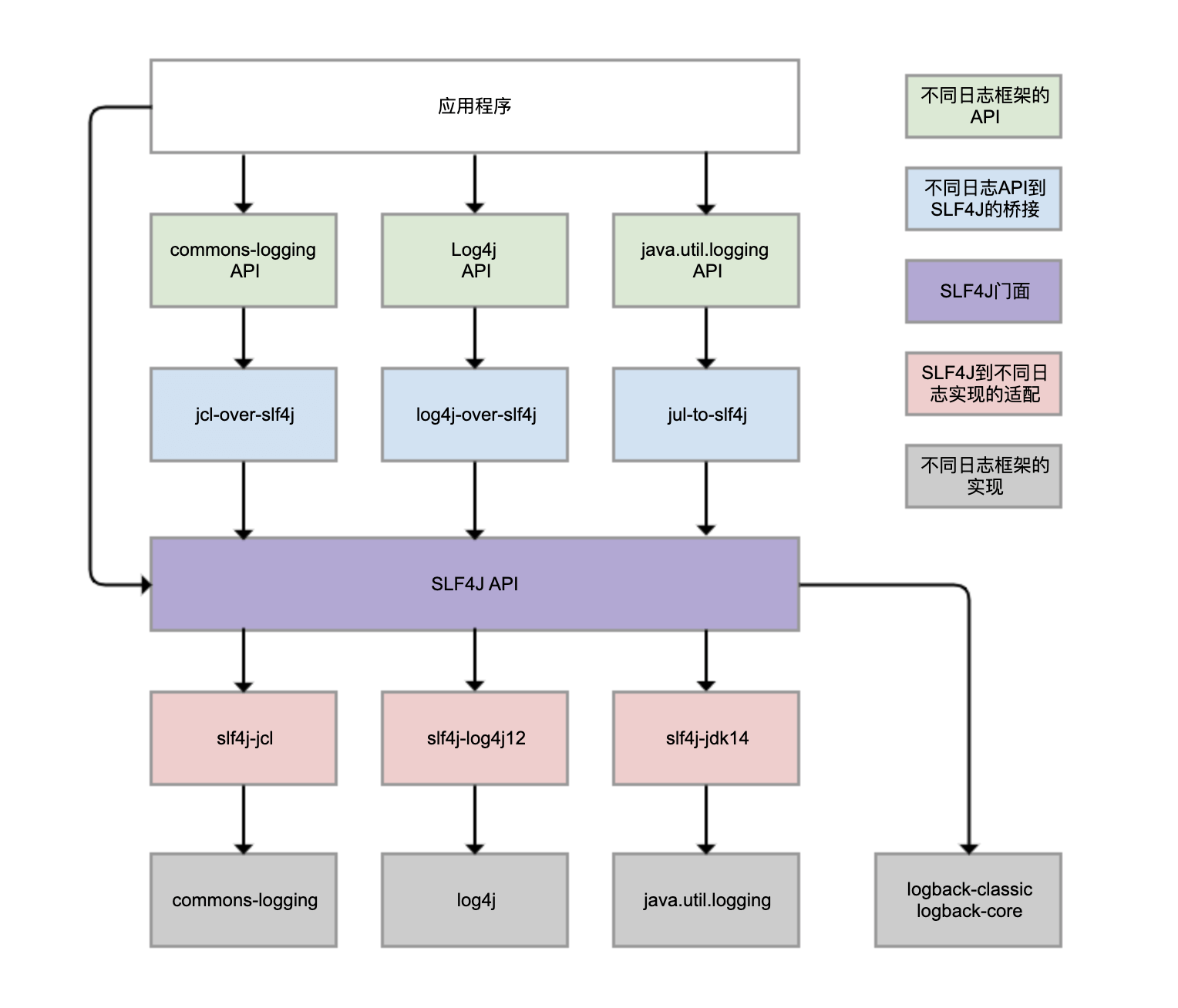
- 使用时避免实现桥接和适配循环
- 比如 log4j-over-slf4j 来实现 Log4j 桥接到 SLF4J, slf4j-log4j12 实现 SLF4J 适配到 Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。
配置问题
重复记录
- logger 配置继承关系导致日志重复记录
- 比如一个 Appender 挂载到多个 Logger 上
- 错误配置 LevelFilter 造成日志重复记录
- 需要配置 onMatch 和 onMismatch 属性,否则这个过滤器是无用的
<!-- LevelFilter --><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level><!-- <level> 中指定的等级,接收 --><onMatch>ACCEPT</onMatch><!-- miss,即不在 <level> 中的等级,全部拒绝 --><onMismatch>DENY</onMismatch></filter>
- 需要配置 onMatch 和 onMismatch 属性,否则这个过滤器是无用的
AsyncAppender 异步日志
配置
includeCallerData用于控制是否收集调用方数据,默认是 false,此时方法行号、方法名等信息将不能显示queueSize用于控制阻塞队列大小,使用的 ArrayBlockingQueue 阻塞队列,默认大小是 256,即内存中最多保存 256 条日志。discardingThreshold是控制丢弃日志的阈值,主要是防止队列满后阻塞。默认情况下,队列剩余量低于队列长度的 20%,就会丢弃 TRACE、DEBUG 和 INFO 级别的日志。neverBlock用于控制队列满的时候,加入的数据是否直接丢弃,不会阻塞等待,默认是false,使用 put 方法queueSize设置得特别大,就可能会导致 OOM。queueSize设置得比较小(默认值就非常小),且 discardingThreshold 设置为大于 0 的值(或者为默认值),当队列剩余容量少于 discardingThreshold 的配置就会丢弃 <=INFO 的日志- 因为 discardingThreshold 的存在,即使设置 queueSize 很大,也容易丢日志
- discardingThreshold 参数容易有歧义,它不是百分比,而是日志条数。对于总容量 10000 的队列,如果希望队列剩余容量少于 1000 条的时候丢弃,需要配置为 1000。
neverBlock默认为 false,意味着总可能会出现阻塞- 如果 discardingThreshold 为 0,那么队列满时再有日志写入就会阻塞
如果 discardingThreshold 不为 0,也不会丢弃 <=INFO 级别的日志,那么出现大量错误日志时,还是会阻塞程序
取舍
如果考虑绝对性能为先,那就设置 neverBlock 为 true,永不阻塞。
- 如果考虑绝对不丢数据为先,那就设置 discardingThreshold 为 0,即使是 <=INFO 的级别日志也不会丢,但最好把 queueSize 设置大一点,毕竟默认的 queueSize 显然太小,太容易阻塞。
- 如果希望兼顾两者,可以丢弃不重要的日志,把 queueSize 设置大一点,再设置一个合理的discardingThreshold
配置优化
- EvaluatorFilter + marker,过滤指定标记的日志
<!-- EvaluatorFilter + marker --><filter class="ch.qos.logback.core.filter.EvaluatorFilter"><evaluator class="ch.qos.logback.classic.boolex.OnMarkerEvaluator"><marker>time</marker></evaluator><onMismatch>DENY</onMismatch><onMatch>ACCEPT</onMatch></filter>
进行日志级别判断
- 日志框架提供的参数化日志记录方式不能完全取代日志级别的判断。
- 使用
{}占位符语法不能通过延迟参数值获取,来解决日志数据获取的性能问题
- 使用
- 如果你的日志量很大,获取日志参数代价也很大,就要进行相应日志级别的判断,避免不记录日志也要花费时间获取日志参数的问题
extra
打印 mapper 执行结果
# 让目标 mapper 目录显示 trace 等级logging.level.<目录>.mapper: trace

若有收获,就点个赞吧
0 人点赞
