设置
集群恢复和故障转移
- 前提,节点 a b 组成镜像队列
- a 先停,b后停
- 该场景下B是Master,只要先启动B,再启动A即可。或者先启动A,再30秒之内启动B即可恢复镜像队列
- a、b 同时停
- 该场景可能是由于机房掉电等原因造成的,只需在30秒之内连续启动A和B即可恢复镜像
- a先停,b后停,且 a 无法恢复
- 因为 B 是 Master,所以等B起来以后,在B节点上调用控制台命令:
rabbitmqctl forget_cluster node A解除与 A 的 Cluster 关系,再将新的 Slave 节点加入B即可重新恢复镜像队列
- 因为 B 是 Master,所以等B起来以后,在B节点上调用控制台命令:
- a先停,b后停,b无法恢复
- 因为Master节点无法恢复,早在3.1.x时代之前没有什么好的解决方案,但是现在已经有解决方案了,在3.4.2以后的版本。因为B是主节点,所以直接启动A是不行的,当A无法启动的时候,也就没办法在A节点上调用之前的
rabbitmqctl forget_cluster_node B命令了。新版本中,forget cluster node 支持--offline参数 - 这就意味着允许 rabbitmqctl 在理想节点上执行该命令,迫使 RabbitMQ 在未启动 Slave 节点中选择一个节点作为 Master。当在A节点执行
rabbitmqctl forget cluster_node-offline B时,RabbitMQ会 mock一个节点代表A,执行forget cluster node命令将 B 剔除 cluster,然后A就可以正常启动了,最后将新的 Slave 节点加入A即可重新恢复镜像队列
- 因为Master节点无法恢复,早在3.1.x时代之前没有什么好的解决方案,但是现在已经有解决方案了,在3.4.2以后的版本。因为B是主节点,所以直接启动A是不行的,当A无法启动的时候,也就没办法在A节点上调用之前的
- A 先停、B 后停,且 A、B 均无法恢复,但是能得到 A 或 B 的磁盘文件
- 这种场景更加难处理,只能通过恢复数据的方式去尝试恢复,将A或B的数据库文件默认在$RABBIT_HOME/var/lib/目录中,把它拷贝到新节点的对应 mulxia ,再将新节点的 hostname 改成A或B的hostname,如果是A节点(Slave)的磁盘文件,则按照场景4处理即可,如果是B节点(Master)的磁盘文件,则按照场景3处理,最后将新的Slave加入到新节点后完成恢复
- A先停、B后停,且A、B均无法恢复,且得不到A或B的磁盘文件
- 凉凉
架构
迅速消息发送
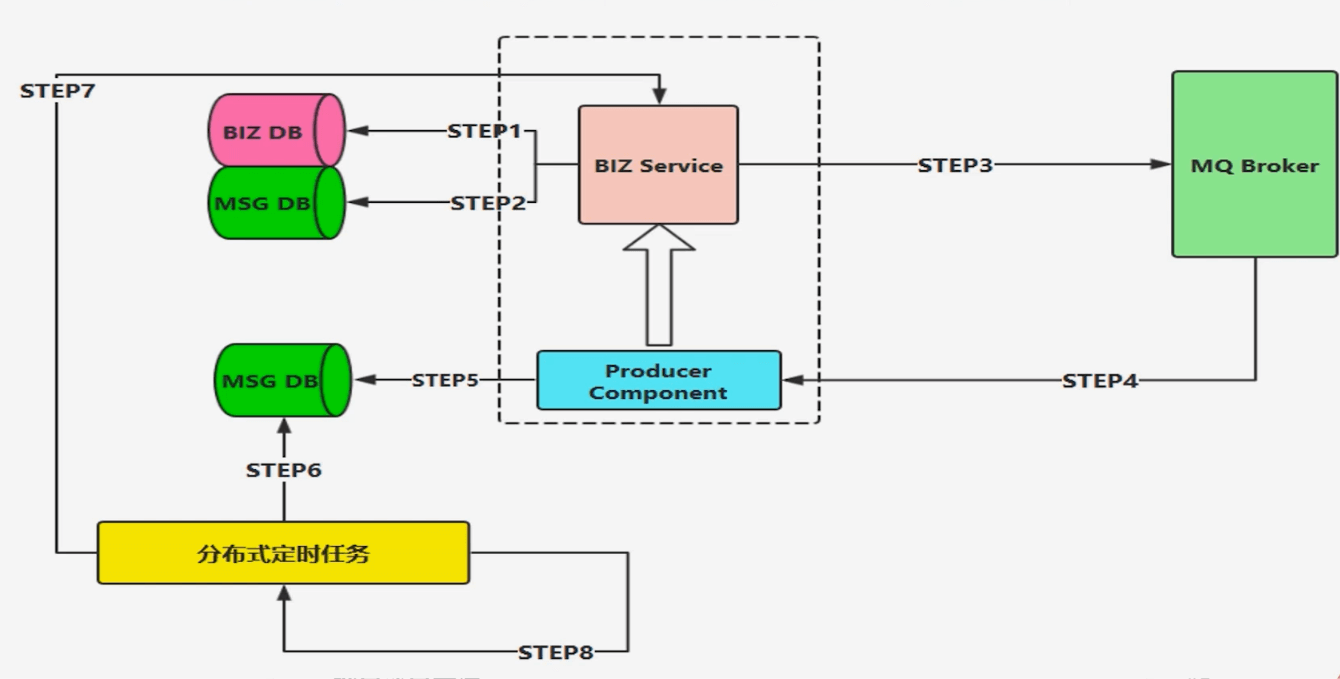
- 迅速消息是指消息不进行落库存储,不做可靠性的保障
- 在一些非核心消息、日志数据、或者统计分析等场景下比较合适
- 迅速消息的优点就是性能最高,吞吐量最大
确认消息发送
延迟消息发送
- 延迟消息相对简单,就是我们在Message封装的时候添加delayTime属性即可
- 需要插件
- 场景
- 在电商平台买到的商品签收后,不点击确认支付,那么系统自动会在7天(一定时间)去进行支付操作。
- 自动超时作废的场景,你的优惠券/红包有使用时间限制,也可以用延迟消息机制。
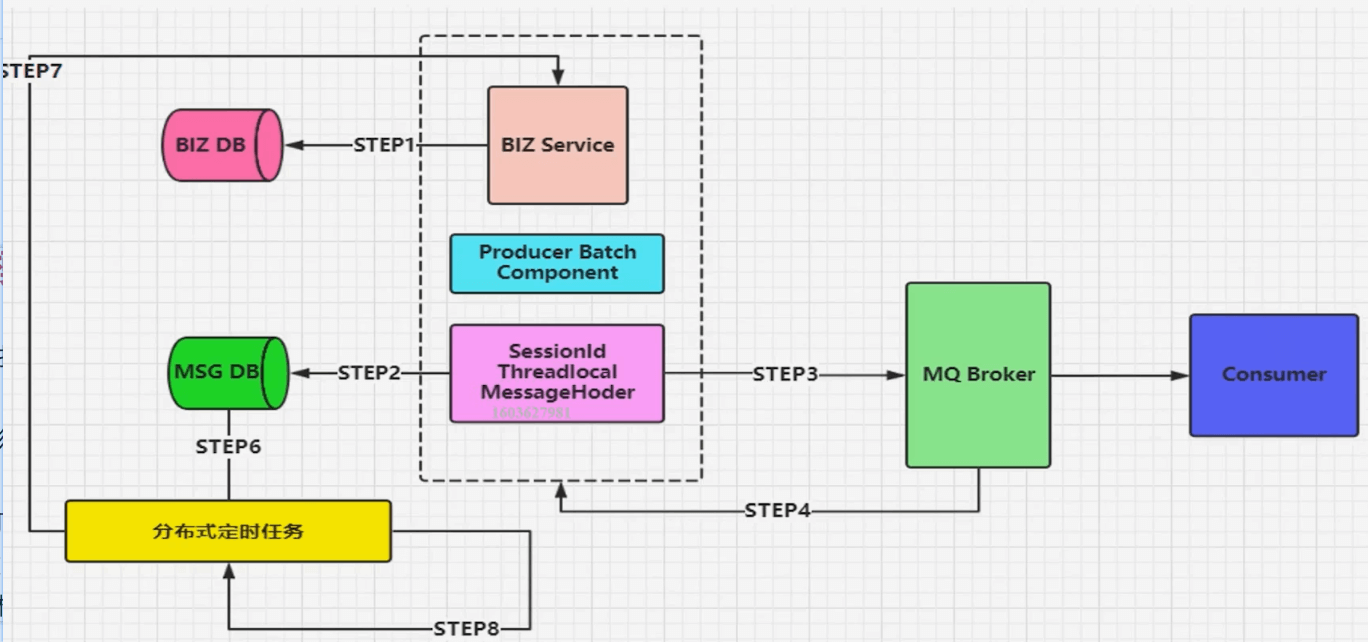
批量消息发送
- 批量消息是指我们把消息放到一个集合里统一进行提交,这种方案设计思路是期望消息在一个会话里,比如投掷到threadlocal里的集合,然后拥有相同会话ID,并且带有这次提交消息的SIZE等相关属性,最重要的一点是要把这批消息进行合并。
- 对于Channel而言,就是发送一次消息。这种方式也是希望消费端在消费的时候,可以进行批量化的消费,针对于某一个原子业务的操作去处理,但是不保障可靠性,需要进行补偿机制。
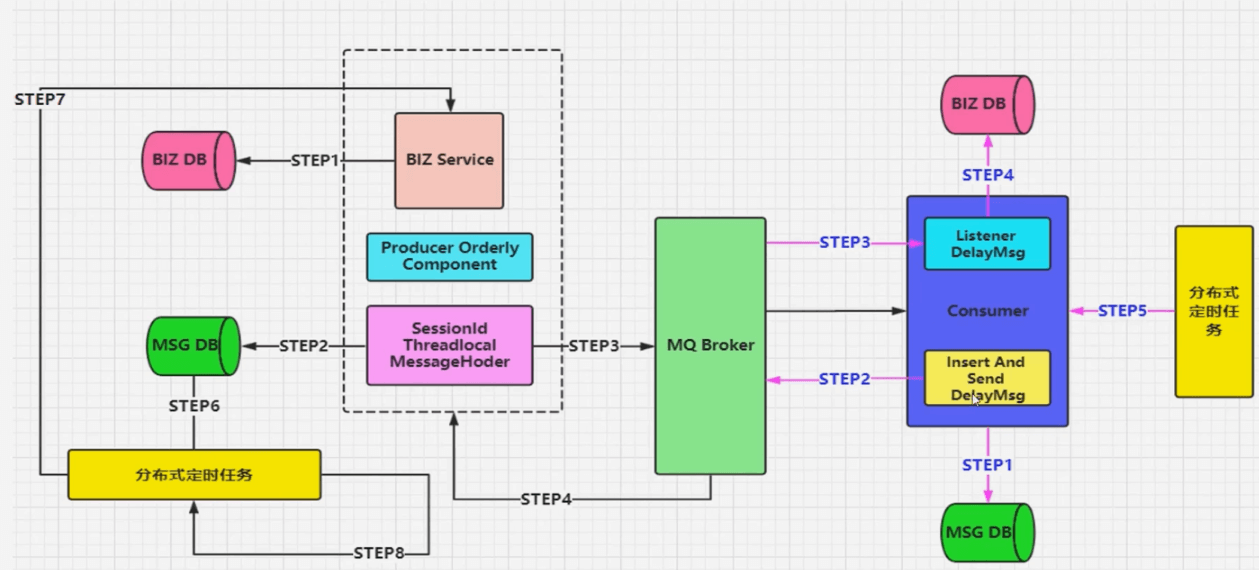
顺序消息发送
- 顺序消息,比较类似于批量消息的实现机制,但是也有些不同。
- 要保障以下几点:
- 发送的顺序消息,必须保障消息投递到同一个队列,且这个消费者只能有一个(独占模式)
- 然后需要统一提交(可能是合并成一个大消息,也可能是拆分为多个消息),并且所有消息的会话ID一致
- 添加消息属性:顺序标记的序号、和本次顺序消息的SIZE属性,进行落库操作
- 并行进行发送给自身的延迟消息(注意带上关键属性:会话ID、SIZE)进行后续处理消费
- 当收到延迟消息后,根据会话ID、SIZE抽取数据库数据进行处理即可
- 定时轮训补偿机制,对于异常情况
- 比如生产端消息没有完全投递成功、或者消费端落库异常导致消费端落库后缺少消息条目的情况
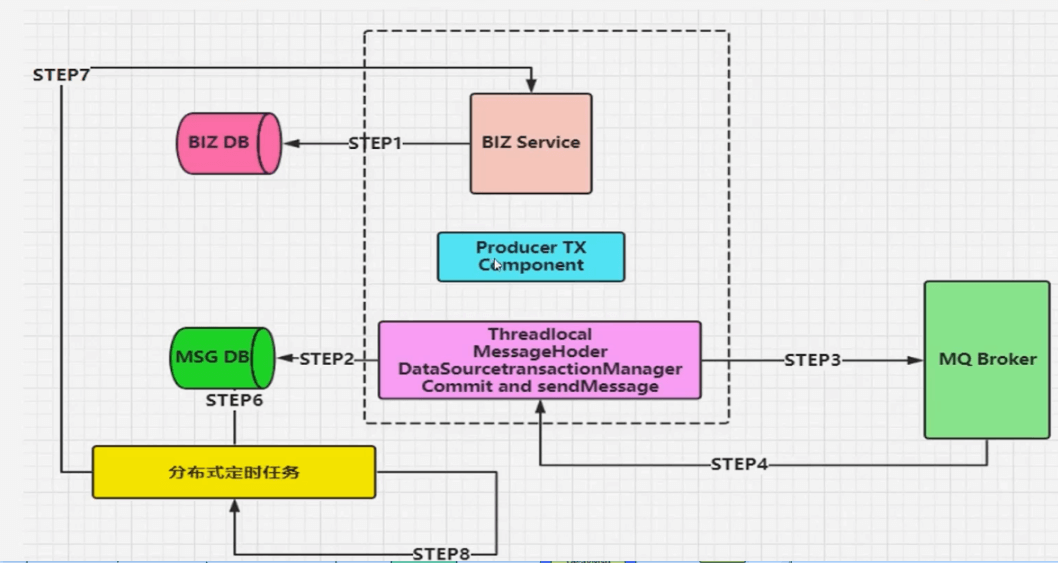
事务消息发送
- 可以用以下解决方案取代 rabbitmq 自身事务消息
- 采用类似可靠性投递的机制,也就是补偿机制。
- 要求的数据源必须是同一个,也就是业务操作DB1数据库和消息记录DB2数据库使用同一个数据源
- 然后利用重写
Spring DataSource TransactionManager,在本地事务提交的时候进行发送消息,但是也有可能事务提交成功但是消息发送失败,这个时候就需要进行补偿了。
幂等
- 可能导致消息出现非幂等的原因:
- 可靠性消息投递机制
MQ Broker服务与消费端传输消息的过程中的网络抖动
- 消费端故障或异常

若有收获,就点个赞吧
0 人点赞
