Consumer Group
- Kafka 仅仅使用 Consumer Group 这一种机制,却同时实现了传统消息引擎系统的两大模型
- 如果所有实例都属于同一个 Group,那么它实现的就是消息队列(点对点)模型
- 如果所有实例分别属于不同的 Group,那么它实现的就是发布 / 订阅模型。
理想情况下,
Consumer 实例的数量应该 = 该 Group 订阅 topic 的 partition 总数新版本 (0.9 之后) 的 Consumer Group 将位移保存在 Broker 端的内部主题 __consumer_offsets 中
- 见之前那版
Coordinator
- 由于 Coordinator 协调者协助 Consumer Group 进行 Rebalance
- 所有 Broker 都有各自的 Coordinator 组件
- Consumer Group 通过 Kafka 内部位移主题 __consumer_offsets 确定为它服务的 Coordinator 在哪台 Broker
- 第 1 步:确定由位移主题的哪个分区来保存该 Group 数据:
partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)- groupId 是 Consumer Group 的 id
- offsetsTopicPartitionCount,__consumer_offsets 的分区数,默认 50
- 第 2 步:找出该分区 Leader 副本所在的 Broker,该 Broker 即为对应的 Coordinator。
- 获悉该算法容易定位当 Consumer group 出错时,是哪个 Broker 出问题
- 第 1 步:确定由位移主题的哪个分区来保存该 Group 数据:
Rebalance
- Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区
Rebalance 通知机制
- 每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求
- 0.10.1之前是在调用 poll 方法时发送的,0.10.1之后 consumer 使用单独的心跳线程来发送
- 当 Coordinator 决定开启新一轮重平衡后,它会将 “
REBALANCE_IN_PROGRESS“ 封装进心跳请求的响应中,发还给消费者实例
- 所以 Consumer 端的
heartbeat.interval.ms心跳发送间隔参数,更多的是用于 Rebelance 的通知频率
Rebalance 原理
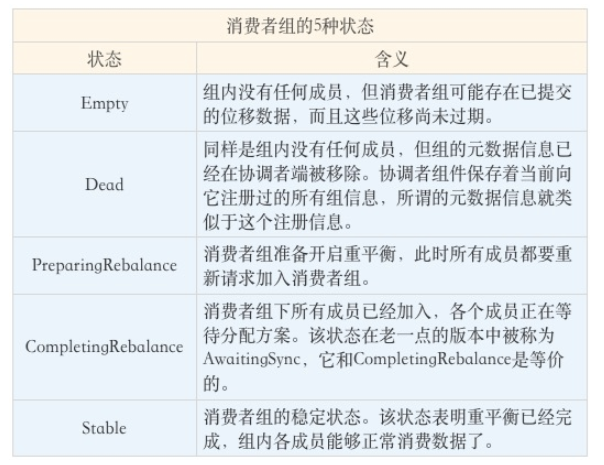
状态机
 <br />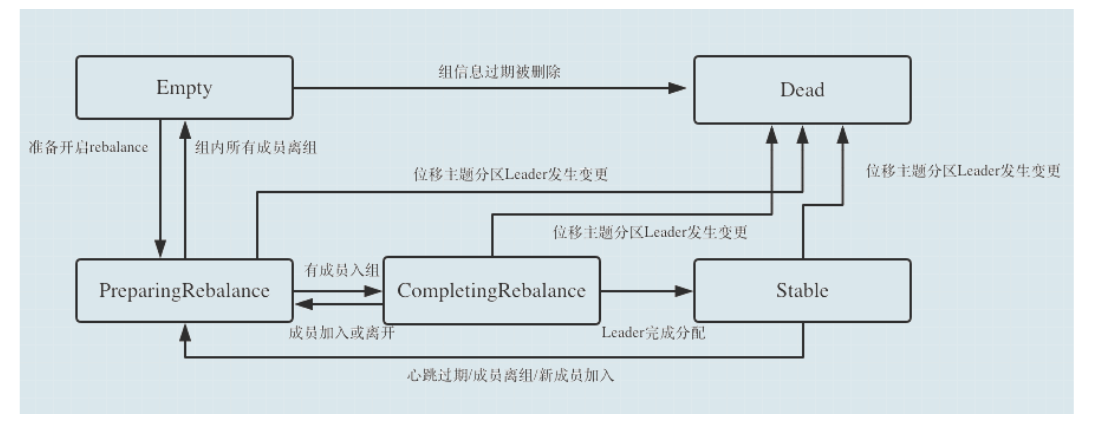
- Kafka 定期自动删除过期位移的条件就是,组要处于 Empty 状态
Consumer 角度 Rebalance 流程
- 当各个 Consumer 从 Coordinator 获得的心跳响应包含 “
REBALANCE_IN_PROGRESS“时候,会发送包含自己订阅的主题的JoinGroup请求给 Coordinator,后者可以收集 Consumer Group 各个实例的发送的订阅信息 - 一般 Coordinator 会选取接收到的第一个
JoinGroup请求的 Consumer 成为 Consumer Group 的 Leader Consumer- 其他 JoinGroup 请求仅仅响应成功进组
- Coordinator 会将确认 Leader Consumer 的信息和 Consumer Group组订阅信息封装进
JoinGroup请求的 Response 中,然后发给 Leader Consumer- 后者也知道了自己是 Leader Consumer ,并且获得消费者组订阅信息
- 由 Leader Consumer 统一做出分配方案
- Leader Consumer 向 Coordinator 发送
SyncGroup请求,将刚刚做出的分配方案发给 Coordinator- 值得注意的是,其他成员也会向协调者发送
SyncGroup请求,只不过请求体中并没有实际的内容 - 这一步的主要目的是让 Coordinator 接收完 Leader Consumer 的分配方案后,然后统一以
**SyncGroup**响应的方式分发给所有成员,这样组内所有成员就都知道自己该消费哪些分区了
- 值得注意的是,其他成员也会向协调者发送
- 当所有 Consumer 实例 都成功接收到分配方案后,Consumer Group 进入到 Stable 状态,即开始正常的消费工作
Coordinator 角度 Rebalance 流程
新成员进组
- 特指 Stable 状态 Consumer Group 有新的 Consumer 进组
- 新 Consumer 会发送
JoinGroup请求给 Coordinator - Coordinator 发现组的成员要增加,于是会在其余组内发送心跳的时候,封装 “
REBALANCE_IN_PROGRESS"进心跳响应,要求进行 Rebalance - 由于新 Consumer 是第一个发送
JoinGroup请求的,所以它会被认为是 Leader Consumer - 其余操作和之前一样
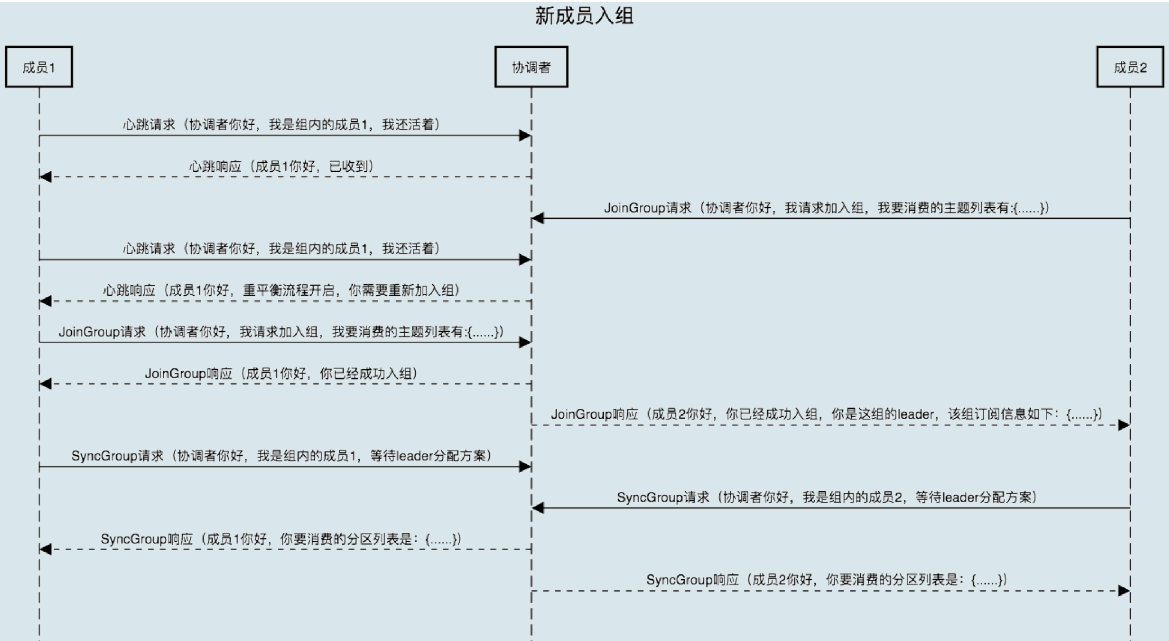
- 图中应该是 Leader Consumer 分配方案,而不是等待
组成员主动离组
- Consumer 所在线程或进程调用
close()方法主动通知 Coordinator 它要退出 - 主动退出的 Consumer 会发送
LeaveGroup请求 - 其他一致
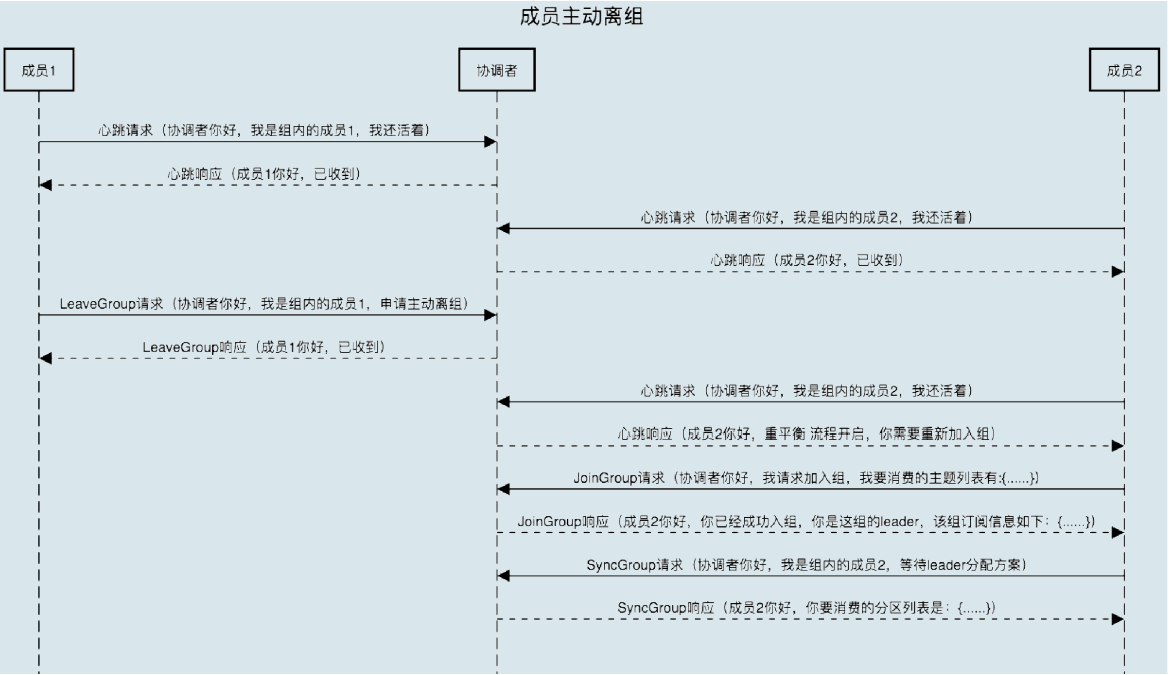
- 图中应该是 Leader Consumer 分配方案,而不是等待
**
组成员崩溃离组
- 崩溃离组是指 Consumer 出现严重故障,突然宕机导致的离组
- Coordinator 通常需要等待一段时间才能感知到,这段时间一般是由 Consumer 参数
session.timeout.ms控制
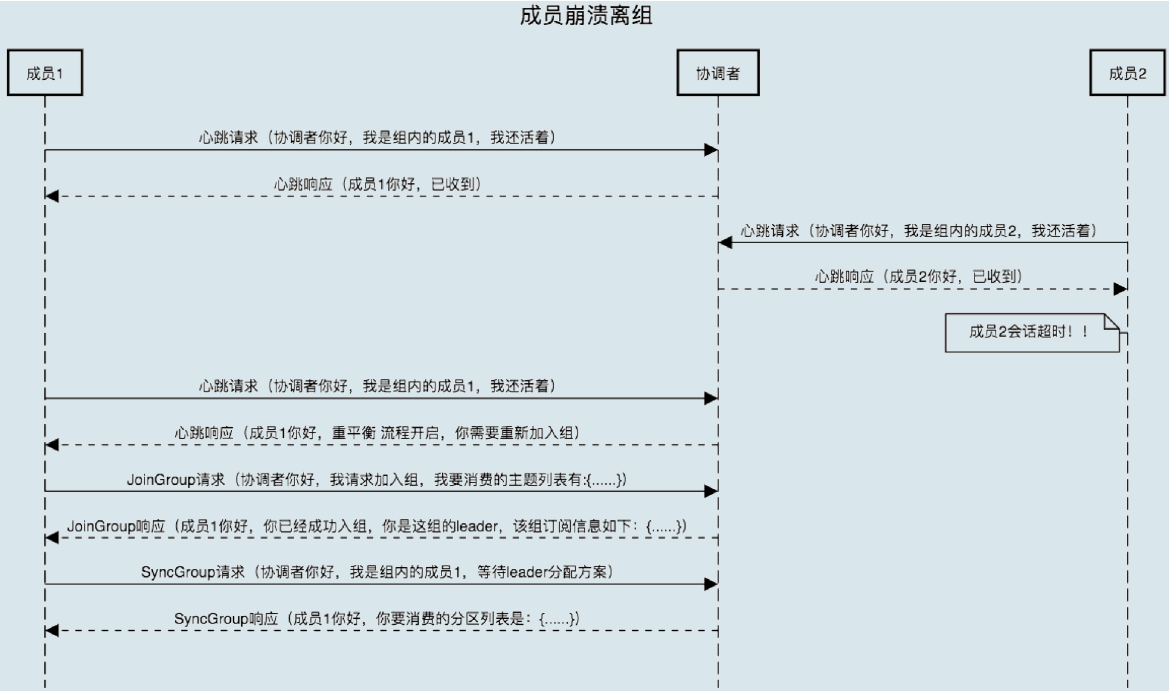
- 图中应该是 Leader Consumer 分配方案,而不是等待
重平衡时 Coordinator 对组内成员提交位移的处理
- 正常情况下,每个组内成员都会定期汇报位移给 Coordinator
- 当 Rebalance 开启时,协调者会给予成员一段缓冲时间,要求每个成员必须在这段时间内快速地上报自己的位移信息,然后再开启正常的 JoinGroup/SyncGroup 请求发送
Rebalance 发生的情况
- 组成员数发生变更。
- 订阅主题数发生变更。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一个主题的分区数。
规避不必要的 Rebalance
- Rebalance 性能不好,尽量不要 Rebalance
- Rebalance 发生的情况,主要集中在 组成员变化 上
- 增加 Consumer 一般是计划内的,是有必要的 Rebalance
- 不必要的 Rebalance 主要集中在 Consumer 被踢出
- Rebalance 发生的情况,主要集中在 组成员变化 上
Consumer 未能及时发送心跳而被剔除
Consumer 端参数
session.timeout.ms,控制每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求的时间间隔- 该参数的默认值是 10 秒,即如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了
- 0.10.1之前是在调用 poll 方法时发送的,0.10.1之后 consumer 使用单独的心跳线程来发送
Consumer 还提供了一个允许你控制发送心跳请求频率的参数,就是 heartbeat.interval.ms。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源
设置
设置 session.timeout.ms = 6s。
- 设置 heartbeat.interval.ms = 2s。
- 要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
Comsumer 未能及时消费 poll 下来的消息而被剔除
- Consumer 端的
max.poll.interval.ms参数。它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟, - 表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起“离开组”的请求,造成 rebalance
-
设置
设成业务处理逻辑可能的最大值
Consumer端的 GC
- Consumer 端的 GC 表现不如人意,gc 的停摆导致上述两种情况都出现

若有收获,就点个赞吧
0 人点赞
