MySQ索引的原理和数据结构
索引,是MySQL存储某一列数据的的一种数据结构。当需要查找某一列时,就从索引中进行查找该列数据,从而找到目标行的物理地址,避免全表扫描。
原理
底层实现是 b+ 树
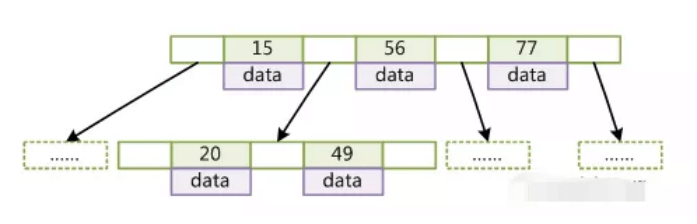
- 看下 b- 树
- 索引值 和 对应数据的物理地址绑定在一起
- 利用三个值区分四个维度
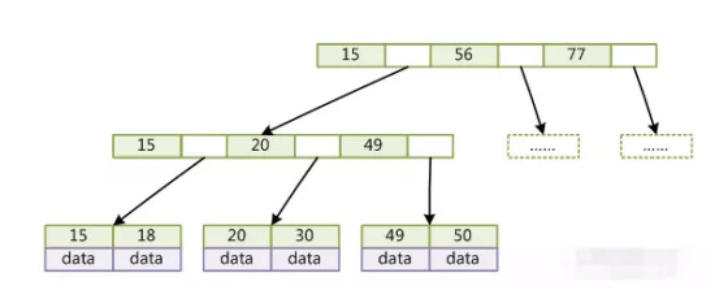
- b+ 树
- 具体的数据存放在叶子节点上(比如这里的15,要一层层下去到叶子节点才有 data)
- 三个值区分三个维度
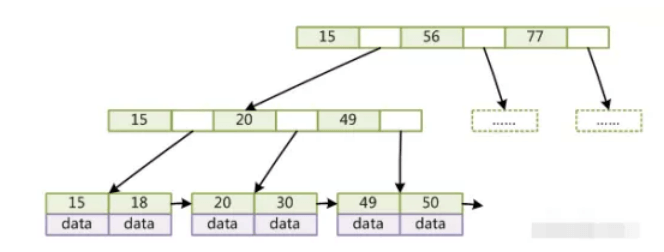
- 但是数据库一般会对 b+ 树进行优化
- 将叶子节点加了顺序访问的指针,方便范围查找
mysim 存储引擎索引的实现
- 在myisam存储引擎的索引中,每个叶子节点的data存放的是数据行的物理地址
最大的特点是数据文件和索引文件是分开
Innodb 存储引起要求表都有一个主键
Innodb 存储引擎会根据主键建立一个默认索引,叫做聚簇索引,并且innodb的数据文件本身同时也是个索引文件。所以聚簇索引中叶子节点的 data 的结构类似
主键 物理地址 具体的值
主键注意项
- 为啥innodb下不要用UUID生成的超长字符串作为主键?因为导致索引会变得过大,浪费很多磁盘空间。
- 一般innodb表里,建议统一用
auto_increment自增值作为主键值,因为这样可以保持聚簇索引直接加记录就可以,如果用那种不是单调递增的主键值,可能会导致b+树分裂后重新组织,会浪费时间。
join 注意事项
- 尽可能减少 join 语句中的 nestedloop 的循环总次数
- 小结果集驱动大结果集
- 优先优化 nestedloop 的内层循环
- 保证 join 语句中被驱动表上 join 条件字段被索引到
- 比如使用 left join 时, left join 右表做索引
- 当无法保证被驱动表的 join 条件字段被索引,切内存资源充足时,不要吝啬 join buffer 的设置
索引原则


若有收获,就点个赞吧
0 人点赞
