本文由 简悦 SimpRead 转码, 原文地址 www.it610.com
解决数据丢失的问题
Redis配置文件设置:两个配置可以减少异步复制和脑裂导致的数据丢失问题。
# 要求至少一个salve,完成数据同步,才认为数据写入成功min-slaves-to-write 1# 配置复制和不同延迟不能超过10秒min-slaves-max-lag 10
异步复制导致数据丢失
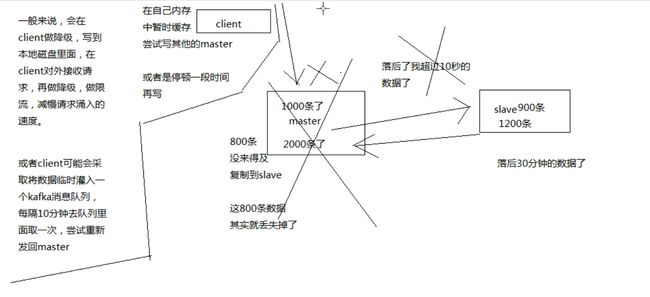
因为 master -> slave 的复制都是异步的,所以有可能出现 master 内存中的部分数据来不及复制到 slave 上,master 就宕机了,随后通过哨兵执行主备切换,导致这部分数据丢失。

解决办法
添加了 min-slaves-max-lag 配置之后,就可以确保,一旦 slave 复制数据和 ack 延时太长,就认为可能 master 宕机后损失的数据过多,那么就拒绝写请求(或者将数据先写入到kalfa中),这样就可以把 master 宕机时由于部分数据未同步到 slave 导致的数据丢失降低到可控范围。
脑裂导致的数据丢失
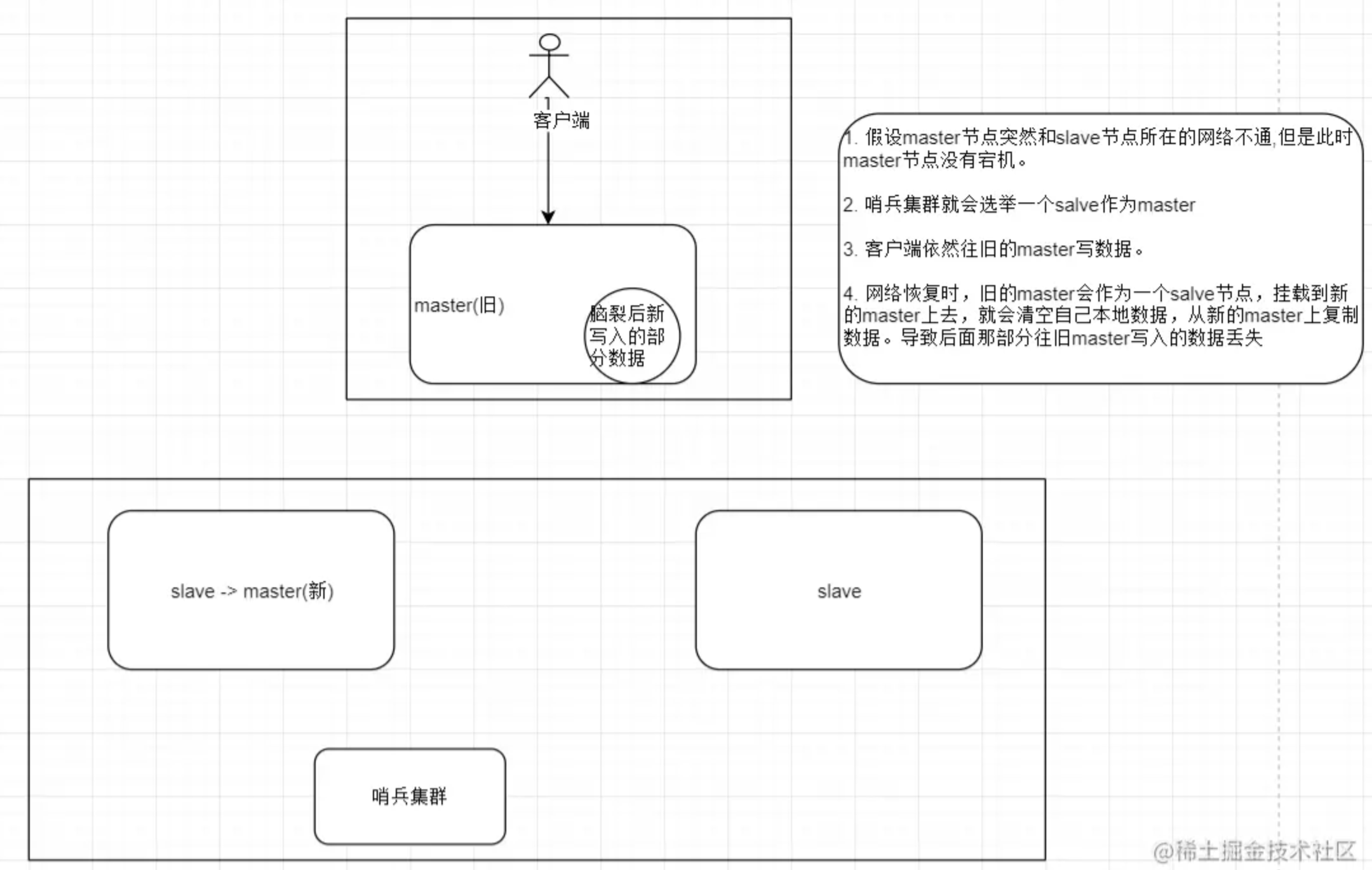
脑裂:某个 master 所在的机器突然脱离了正常的网络,跟其他 slave 节点不能连接。但实际上 master 是正常运行的。但哨兵就有可能认为 master 宕机了,然后开始从剩下的哨兵中选举出一个哨兵执行故障转移,将 salve 切换成 master。 此时集群中就会出现两个 master,也就是所谓的脑裂,此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的 master,还继续往旧的 master 中写数据。因此旧的 master 再次恢复的时候,会被作为一个 slave 挂到新的 master 上去,自己的数据就会被清空,重新从 master 上面复制数据,导致后面那部分往旧 master 写入的数据就丢失了。
减少脑裂的数据丢失
脑裂问题就是因为旧的master由于网络连接问题,和其他节点失去了连接,但是master还是可以正常访问的,client 还没来得及切换到新的 master,还继续往旧的 master 中写数据;所以需要配置 master至少需要一个salve完成数据同步,且延迟不能超过十秒。旧的master由于不能和其它节点通信了,所以十秒之后就会阻止Client继续写入到旧的master中;只会造成10秒内数据的丢失;
如果一个 master 出现了脑裂,即 master 跟其他 slave 丢失了连接,那么上面两个配置就可以确保说,不能给指定数量的 slave 发送数据,且 slave 超过 10s 没有给 master ack 消息,那么就直接拒绝客户端的写请求。
这样脑裂后的旧 master 就不会接收 client 的写请求,也就避免了数据丢失。
上面的配置确保了,如果个任何一个 salve 丢失了连接,master 在 10s 内没有接收到 slave 的 ack 响应,那么就会拒绝新的写请求。因此在脑裂场景下,最多就丢失了 10 秒的数据。

参考 石衫老师 《亿级流量教程》课程笔记

若有收获,就点个赞吧
0 人点赞
