回顾
列属性: 主键, 自增长, 唯一键
关系: 一对一,一对多和多对多
范式: 三层范式
1NF: 字段设计必须符合原子性
2NF: 不存在部分依赖(没有复合主键)
3NF: 不存在传递依赖(实体单独建表)
逆规范化: 效率与磁盘空间的博弈
高级数据操作
新增操作: 主键冲突(更新和替换), 蠕虫复制
更新操作: 限制更新数量: limit
删除操作: 限制删除数量: limit, 清空表(truncate)
查询操作: select选项, 字段别名, 数据源(单表,多表和子查询[别名]),where子句(条件判断:从磁盘),groupby子句(分组统计,统计函数,分组排序, 多字段分组, 回溯统计), having子句(判断结果, 针对分组统计结果), orderby子句(排序, 多字段排序),limit子句(限制记录数,分页)
连接查询
连接查询: 将多张表(可以大于2张)进行记录的连接(按照某个指定的条件进行数据拼接): 最终结果是: 记录数有可能变化, 字段数一定会增加(至少两张表的合并)
连接查询的意义: 在用户查看数据的时候,需要显示的数据来自多张表.
连接查询: join, 使用方式: 左表 join 右表
左表: 在join关键字左边的表
右表: 在join关键字右边的表
连接查询分类
SQL中将连接查询分成四类: 内连接,外连接,自然连接和交叉连接
交叉连接
交叉连接: cross join, 从一张表中循环取出每一条记录, 每条记录都去另外一张表进行匹配: 匹配一定保留(没有条件匹配), 而连接本身字段就会增加(保留),最终形成的结果叫做: 笛卡尔积.
基本语法: 左表 cross join 右表; ===== from 左表,右表;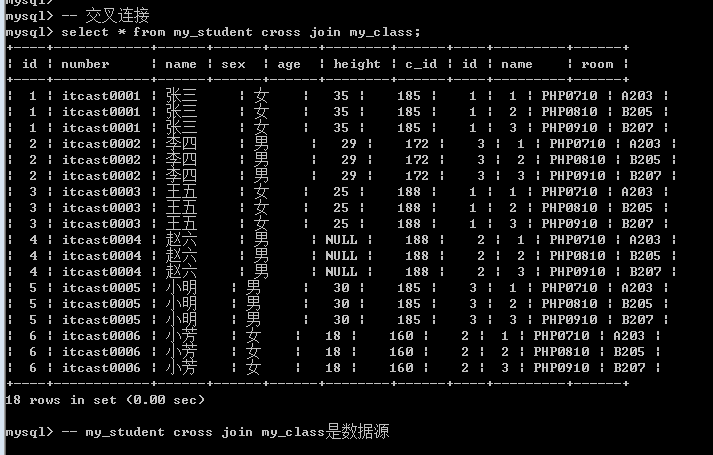
笛卡尔积没有意义: 应该尽量避免(交叉连接没用)
交叉连接存在的价值: 保证连接这种结构的完整性
内连接
内连接: [inner] join, 从左表中取出每一条记录,去右表中与所有的记录进行匹配: 匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
基本语法
左表 [inner] join 右表 on 左表.字段 = 右表.字段; on表示连接条件: 条件字段就是代表相同的业务含义(如my_student.c_id和my_class.id)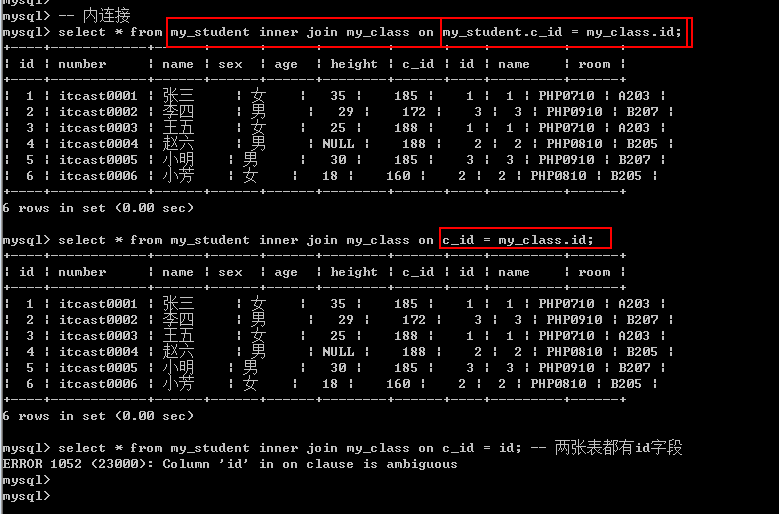
字段别名以及表别名的使用: 在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分, 而表名太长, 通常可以使用别名.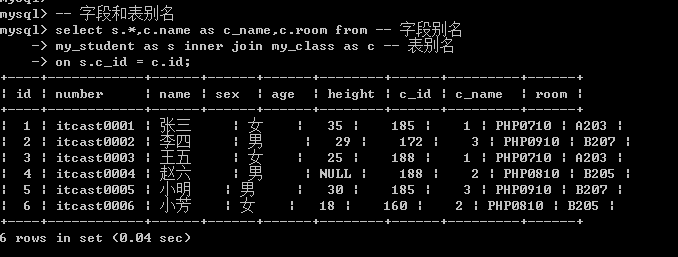
内连接可以没有连接条件: 没有on之后的内容,这个时候系统会保留所有结果(笛卡尔积)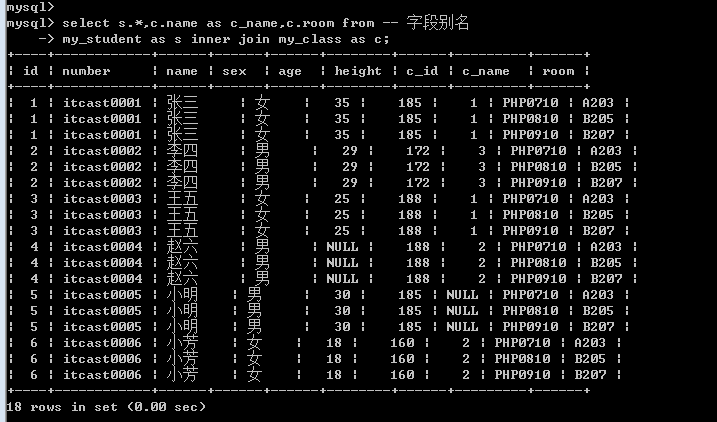
内连接还可以使用where代替on关键字(where没有on效率高)
Where是先形成所有的结果之后再进行过滤。而on是符合条件的才形成结果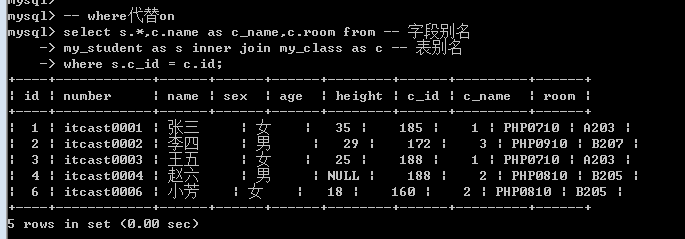
外连接
外连接: outer join, 以某张表为主,取出里面的所有记录, 然后每条与另外一张表进行连接: 不管能不能匹配上条件,最终都会保留: 能比配,正确保留; 不能匹配,其他表的字段都置空NULL.
外连接分为两种: 是以某张表为主: 有主表
Left join: 左外连接(左连接), 以左表为主表
Right join: 右外连接(右连接), 以右表为主表
基本语法: 左表 left/right join 右表 on 左表.字段 = 右表.字段;
左连接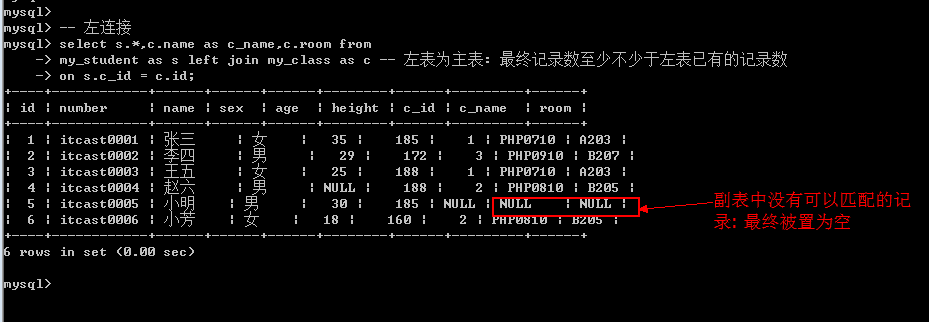
右连接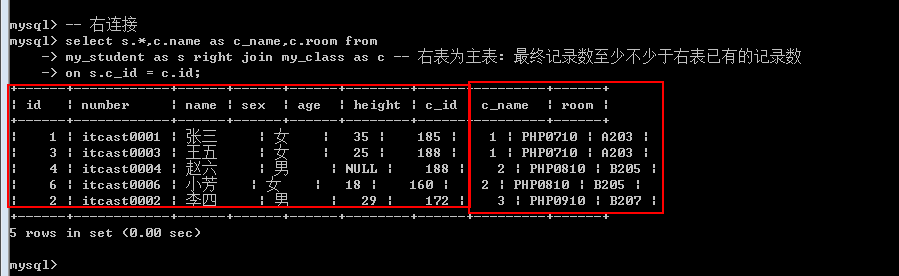
虽然左连接和右连接有主表差异, 但是显示的结果: 左表的数据在左边,右表数据在右边.
左连接和右连接可以互转.
自然连接
自然连接: natural join, 自然连接, 就是自动匹配连接条件: 系统以字段名字作为匹配模式(同名字段就作为条件, 多个同名字段都作为条件).
自然连接: 可以分为自然内连接和自然外连接.
自然内连接: 左表 natural join 右表;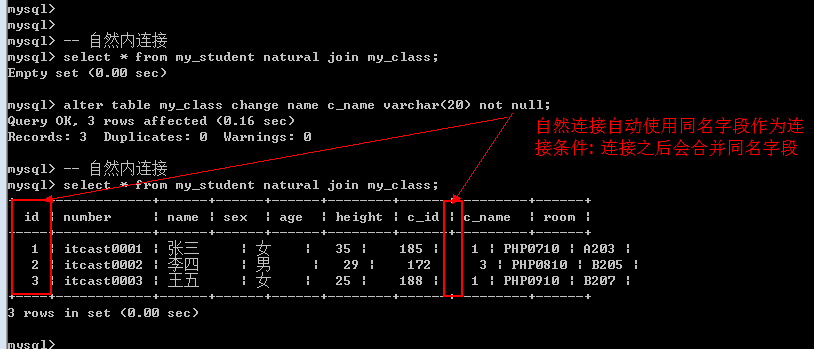
自然外连接: 左表 natural left/right join 右表;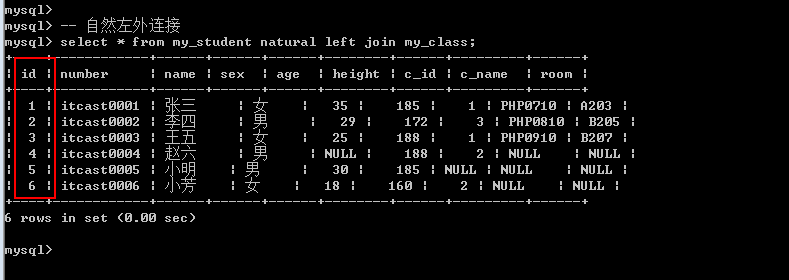
其实, 内连接和外连接都可以模拟自然连接: 使用同名字段,合并字段
左表 left/right/inner join 右表 using(字段名); — 使用同名字段作为连接条件: 自动合并条件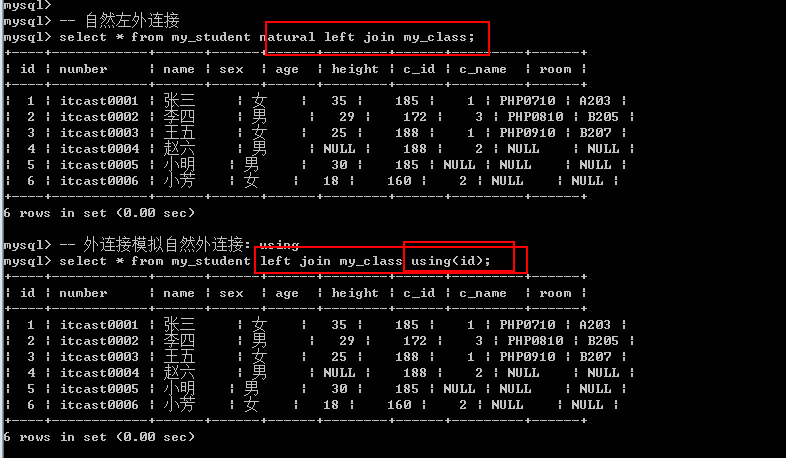
多表连接: A表 inner join B表 on 条件 left join C表 on条件 …
执行顺序: A表内连接B表,得到一个二维表, 左连接C表形成二维表…
PHP操作mysql
事实上: PHP本身不能操作mysql, 但是PHP有扩展可以实现操作mysql: PHP借助扩展来实现操作mysql.
PHP操作mysql的扩展还挺多: mysql, mysqli和PDO扩展.
Mysql扩展: 纯面向过程, 里面都是函数,加载扩展后可以调用函数.(当前只能使用面向过程)
Mysqli扩展: 面向过程+面向对象,里面有函数也有类, 加载扩展后可以选择调用函数或者调用类操作.
PDO: 纯面向对象,只有类, 加载后只能调用类.
Mysql扩展在搭建服务器的时候就已经加载开启.不再进行扩展加载.
PHP操作mysql
当PHP来对mysql进行操作之后: PHP的角色是mysql的一个客户端.
客户端操作服务端有必要的流程
1. 连接认证: 连接和认证
数据库连接资源 Mysql_connect(服务器地址包含端口, 用户名, 用户密码);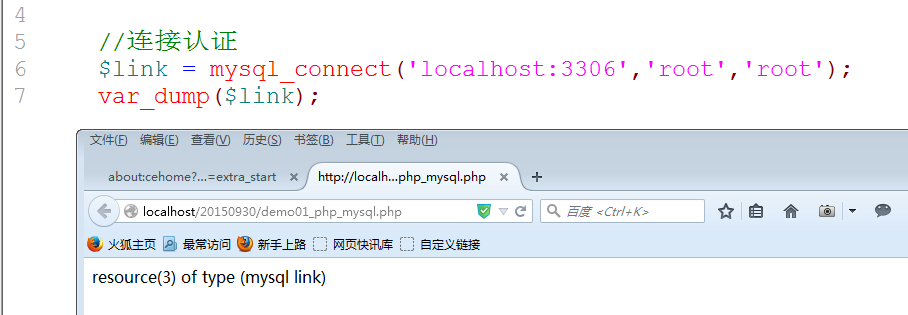
默认的: mysql_connect会产生一个连接资源,即便是重新连接,也会返回原有的连接资源.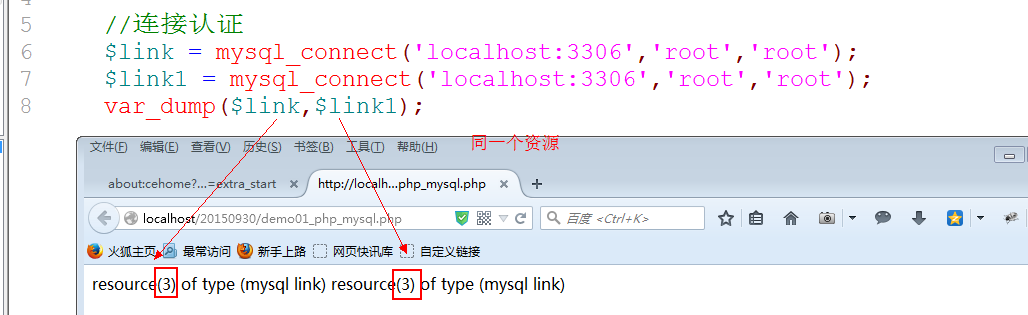
如果真的想产生多一个连接: 是新的,可以在mysql_connect函数的第四个参数控制: true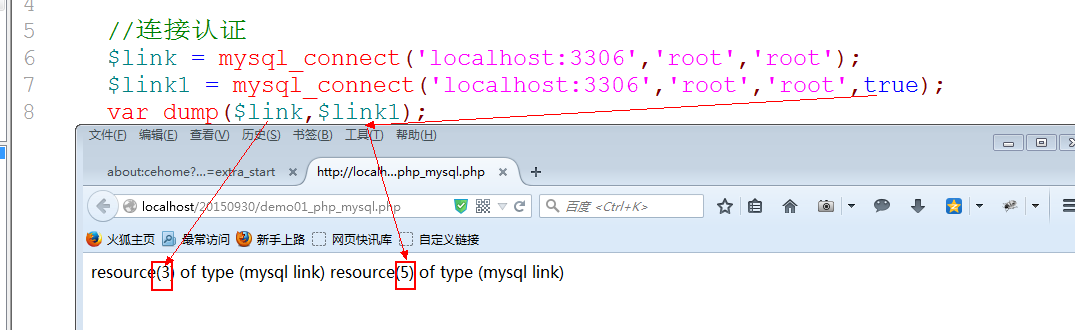
其实,根本不需要多个连接: 严重的资源浪费
2. PHP发送SQL指令(等待执行结果)
3. Mysql服务端接收指令,执行指令,返回结果
4. PHP接收结果
Mixed Mysql_query(sql指令);
Boolean结果: SQL指令没有返回值, 布尔结果只能代表SQL语句没有语法错误, false就代表是SQL语句有语法错误: 主增删改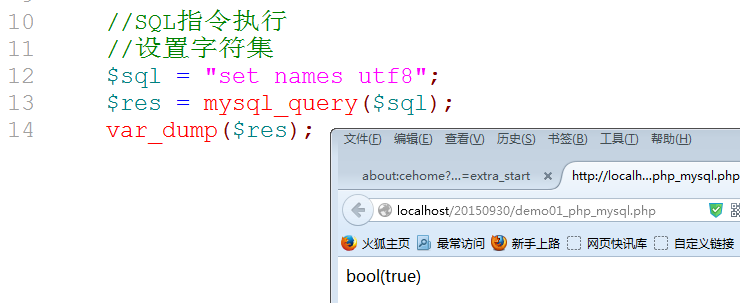
Resource结果: 结果集资源, SQL指令有结果返回(show, select),结果集永远为true: 主查询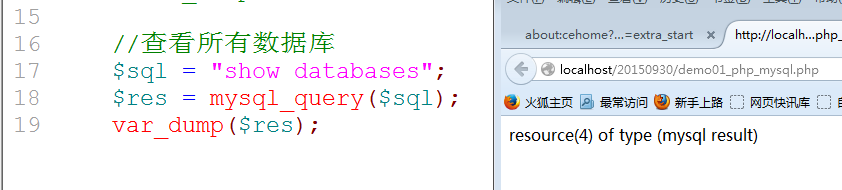
5. PHP没有办法直接使用结果集: 需要解析结果集.mysql扩展提供了一系列函数: mysql_fetch系列: 任何操作都是指针操作: 操作完就会指针下移
Mysql_fetch_array: 默认获取混合数组,有一组关联,有一组索引.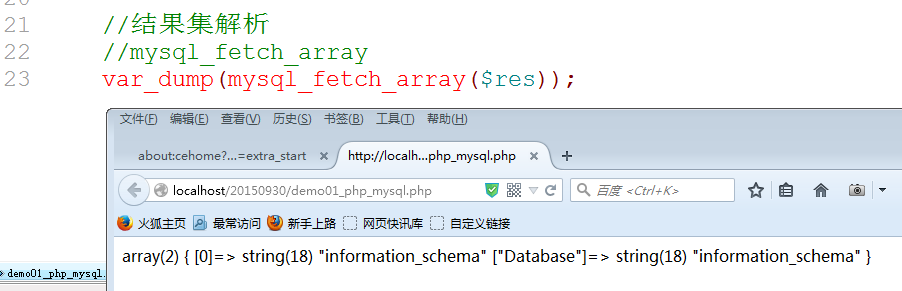
当前函数可以实现: 只获取关联数组或者索引数组,通过第二个参数限制: MYSQL_BOTH是默认的,MYSQL_ASSOC是关联数组,MYSQL_NUM是索引数组.
关联数组获取: MYSQL_ASSOC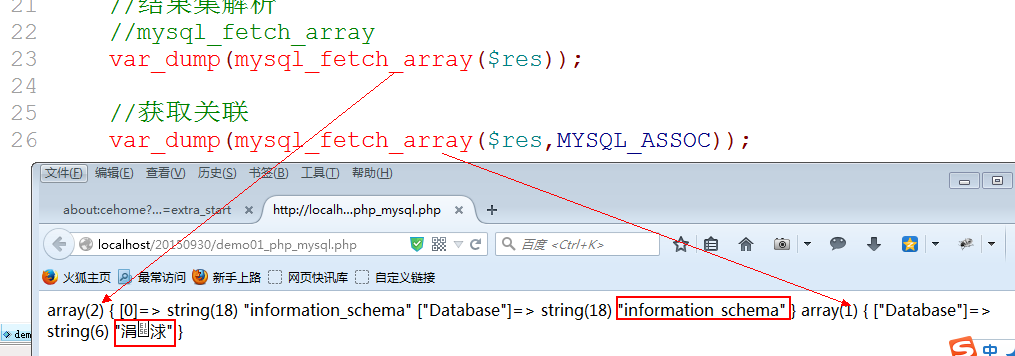
索引数组获取:MYSQL_NUM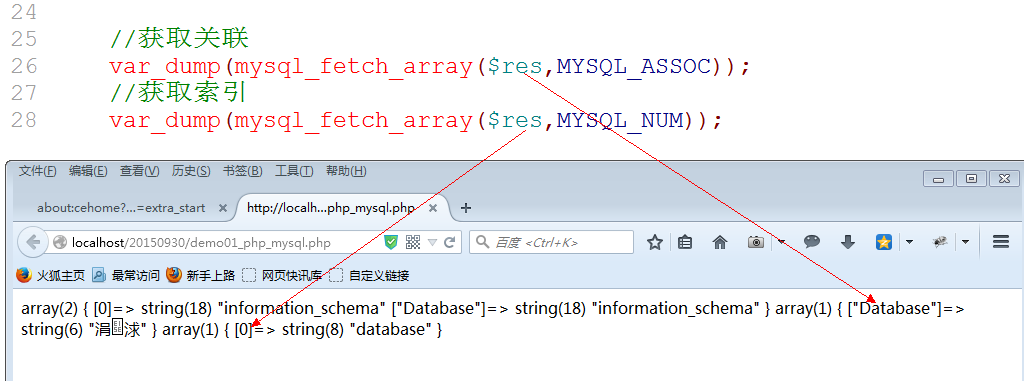
Mysql_fetch_assoc: 直接获取关联数组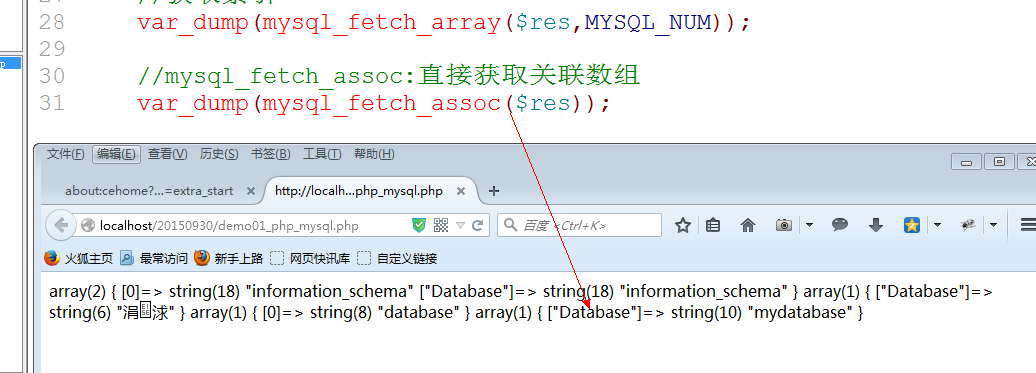
Mysql_fetch_row: 获取索引数组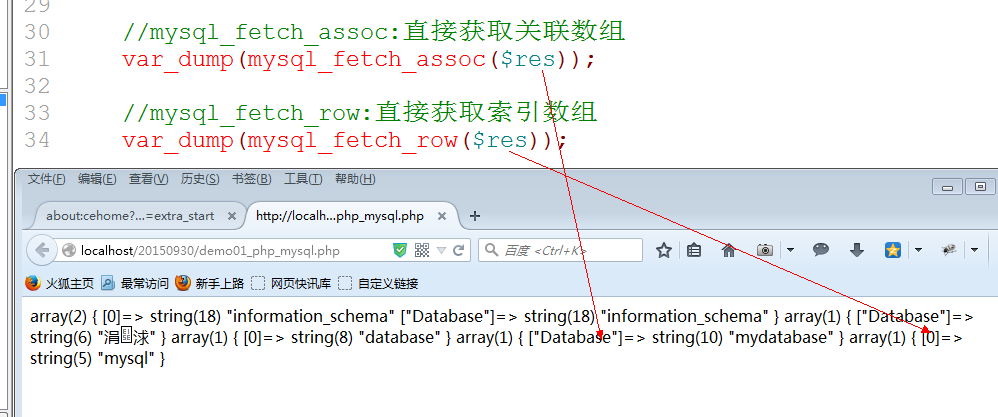
不管是哪个fetch: 最终如果结果集指针移动到最后,返回都是false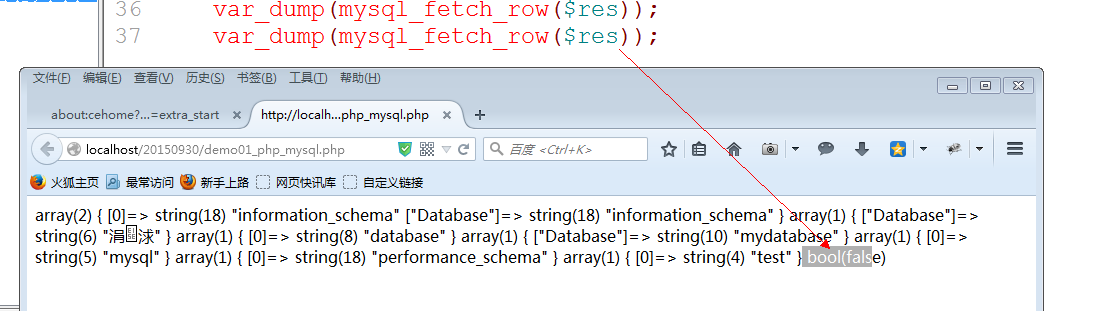
6. 如果指针已经移动到最后,那么需要重置指针实现其他操作.
Mysql_data_seek(结果集资源,位置从0开始);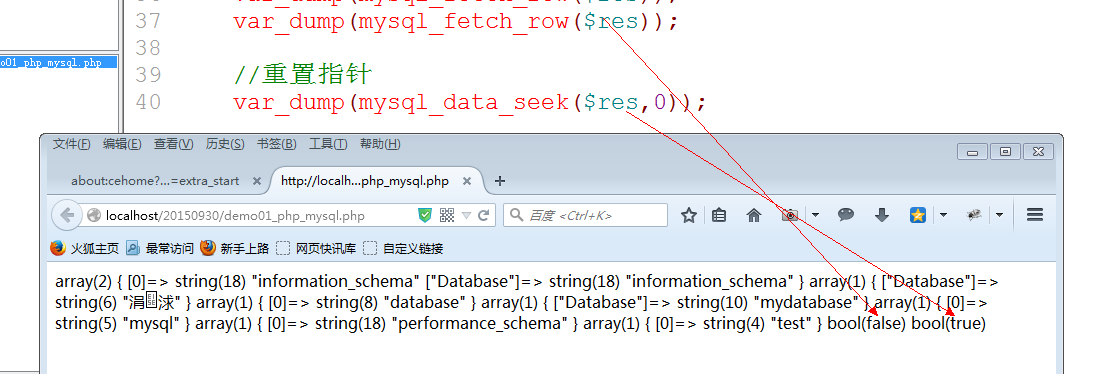
7. 获取的数据往往只有一行: 实际上查多少是为了显示全部: 解析全部: 循环遍历来实现.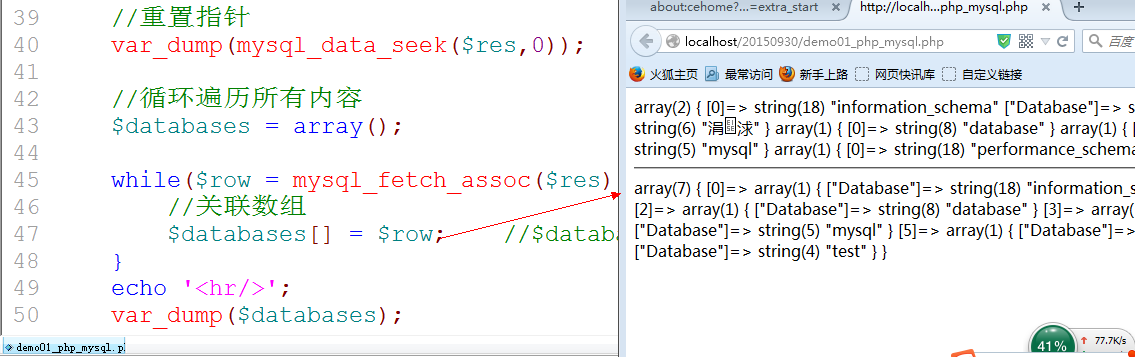
8. 释放资源: mysql资源通常不需要释放(脚本执行周期不会太长,但是数据库的操作是贯穿整个脚本的)
Mysql_close(资源变量);
增删改查
写操作
连接认证: 不一定连成功, 需要对结果进行判断: 可以直接使用三目运算(逻辑或)来进行处理, 但是无法获取错误信息. 如果要获取错误信息,那么需要使用mysql提供的获取错误的函数: mysql_errno()获取错误编号, mysql_error()获取错误信息.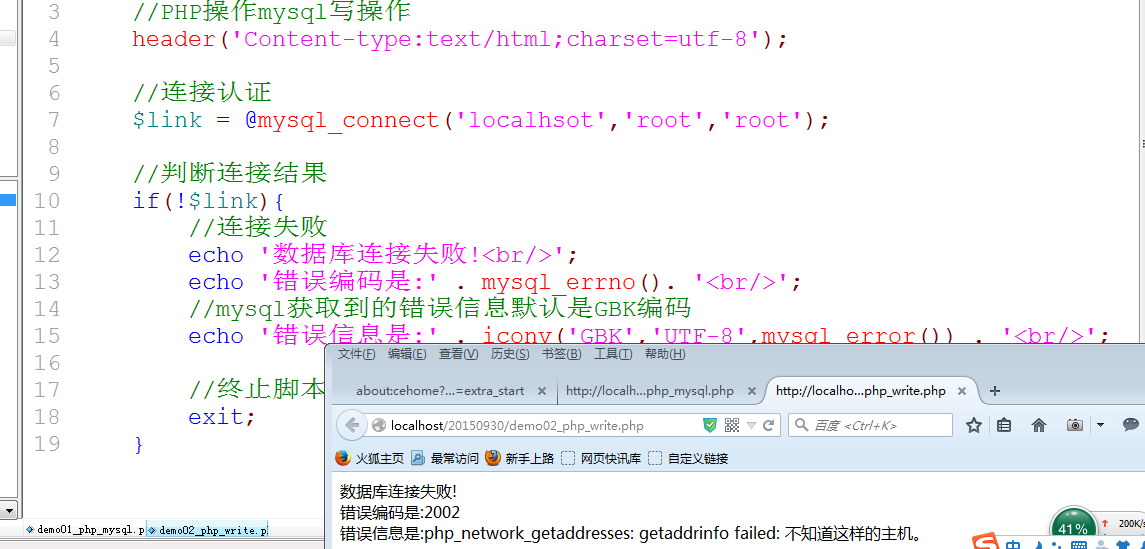
在操作数据库之前要进行相关初始化: 设置字符集,选择数据库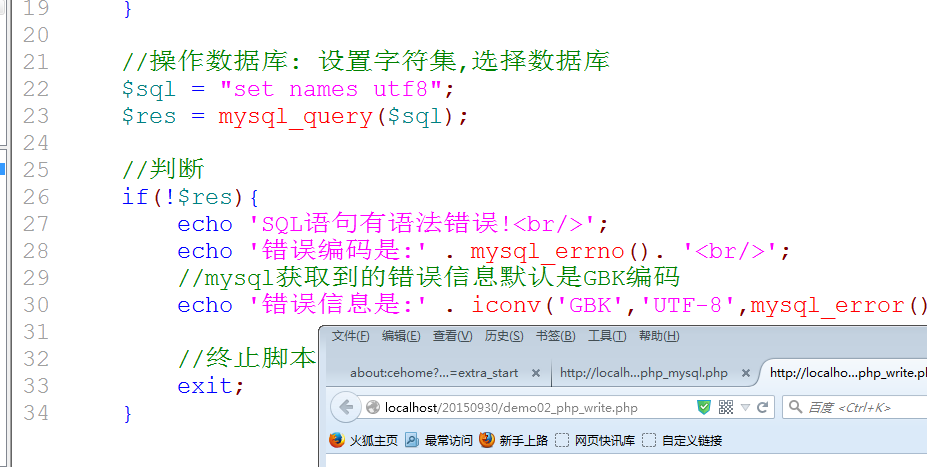
发现: 其实所有的SQL语句都有可能出错: 将执行SQL语句,判断错误信息的代码进行封装: 封装成错误处理函数.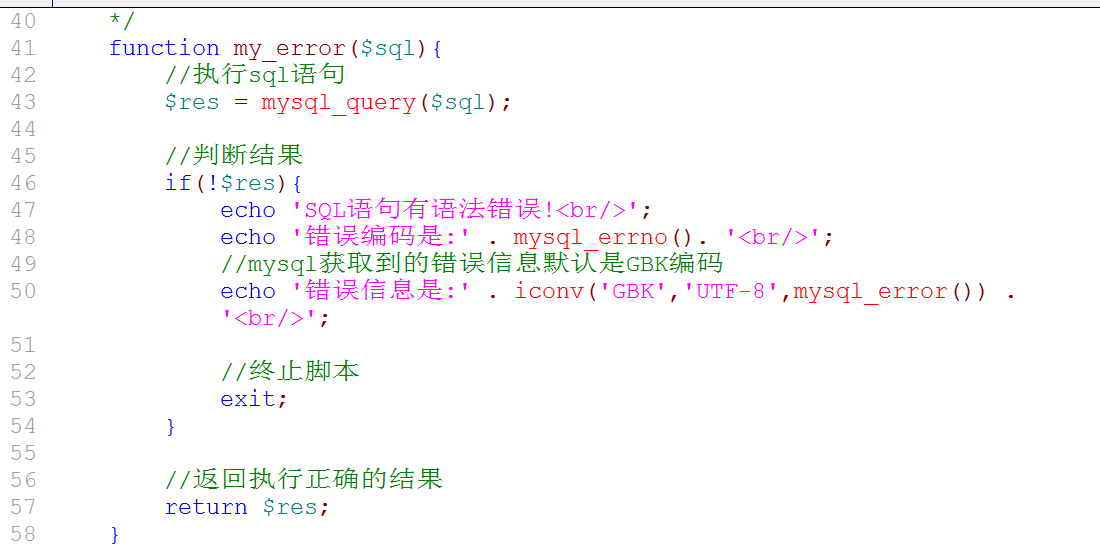
任何SQL语句的执行,都应该由my_error自定义函数来执行: 检查错误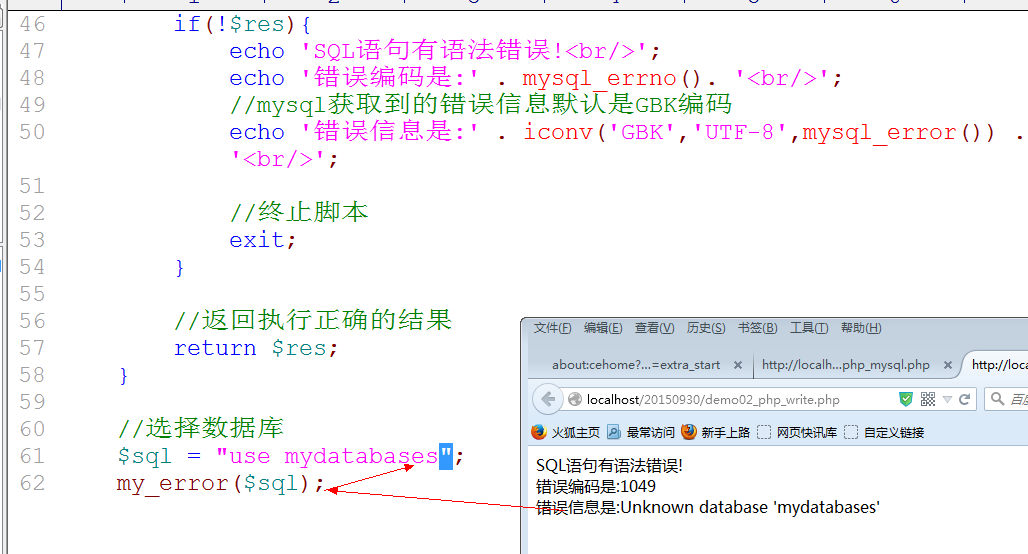
写操作: 不符合人类的判断意识: 根据人的需求, 对进行进行分类操作: 增和删改
新增操作: 通常会获取当前新增记录的自增长id: mysql_insert_id(),直接获取上次新增操作的自增长ID, 如果没有自增长id获得0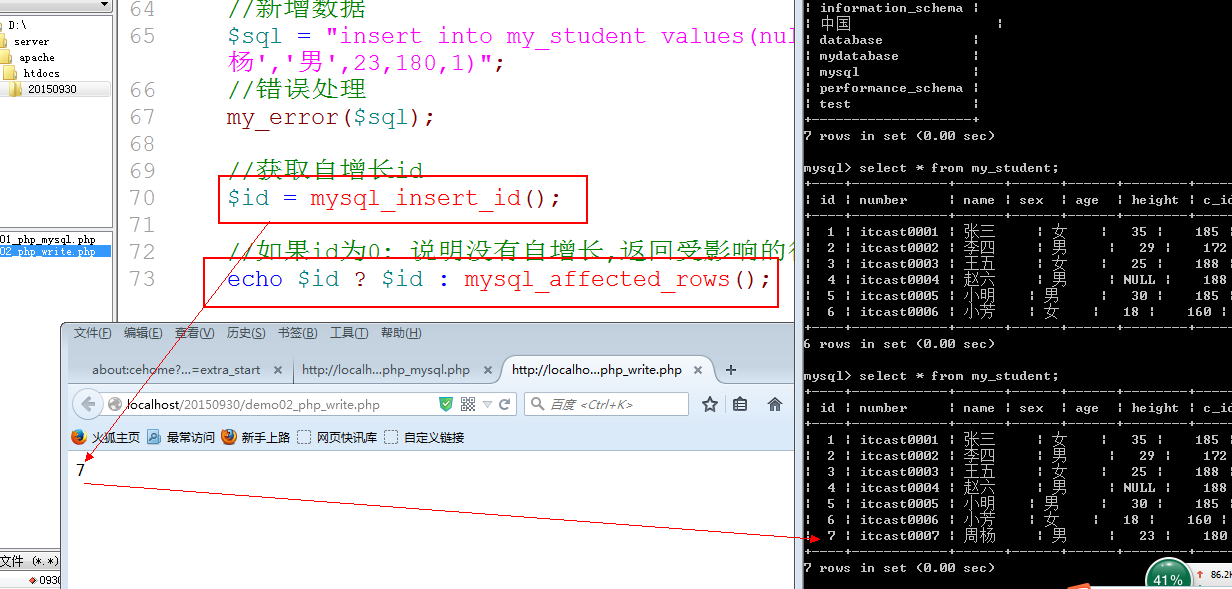
删改操作: 通常都不能直接通过mysql_query的结果true来进行判断: true不代表执行成功,只代表SQL语句没有语法错误: 通过受影响的行数来判断是否成功: mysql_affected_rows()获取上次操作的受影响的行数(新增也有)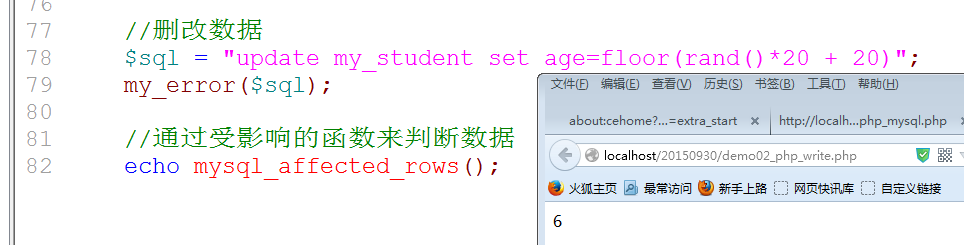
读操作
无外乎从数据库中查出所有数据, 最后在html里面显示.
在HTML显示数据
综合应用
Mysql+PHP进行一个实际案例的综合应用.(HTML+CSS)
需求: 学生信息管理系统, 是一个后台管理系统, 显示学生的信息(管理:增删改), 分页功能. 需要用户登录之后才能查看数据信息.
功能: 登录功能, 分页显示数据功能
指导方针: 从用户角度出发, 顺着用户的操作步骤逐步进行.
登录功能
1. 从用户角度来说: 用户需要看到一个登录页面: 登录表单是HTML文件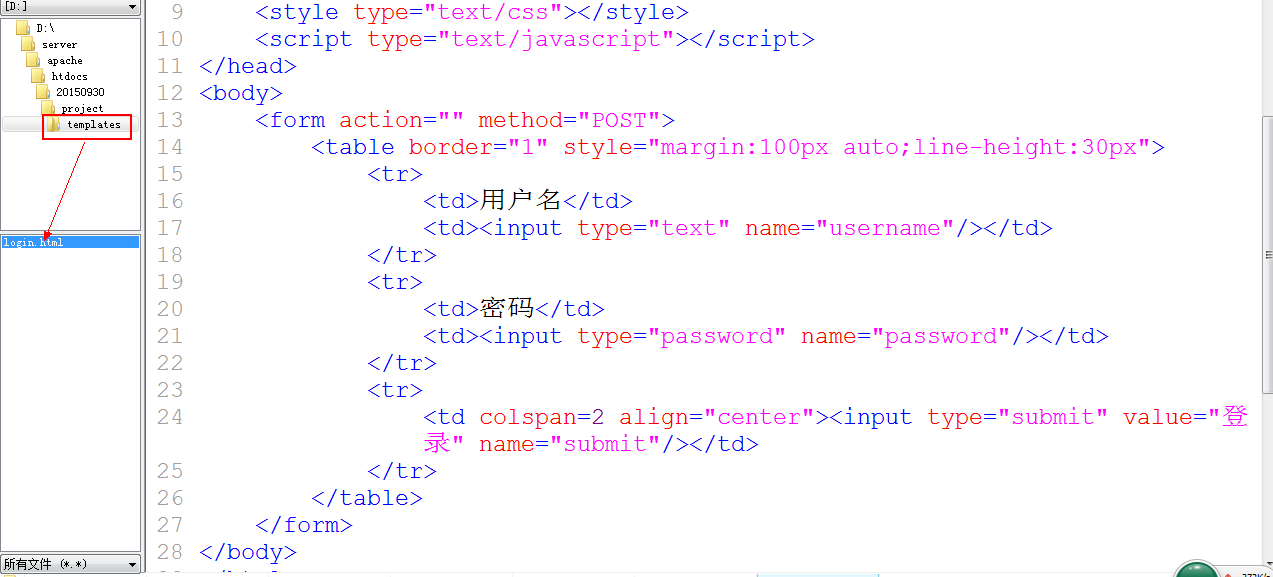
所有的html文件都是放在project/templates/文件夹下: 所有的html文件,浏览器都不允许直接访问, 只允许访问PHP文件.
2. 给用户增加一个可以访问的链接: 是php文件, 能够显示登录表单信息.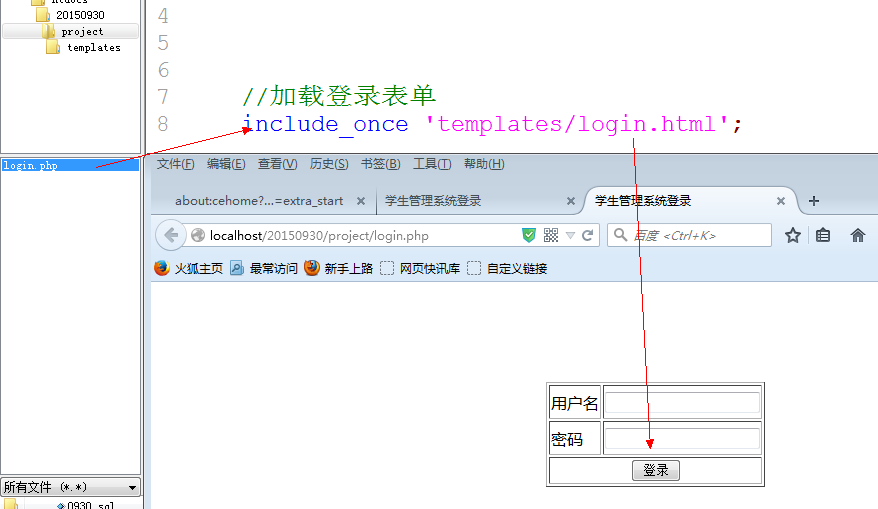
3. 用户会选择输入用户信息,提交: 确定表单提交对象./project/templates/login.html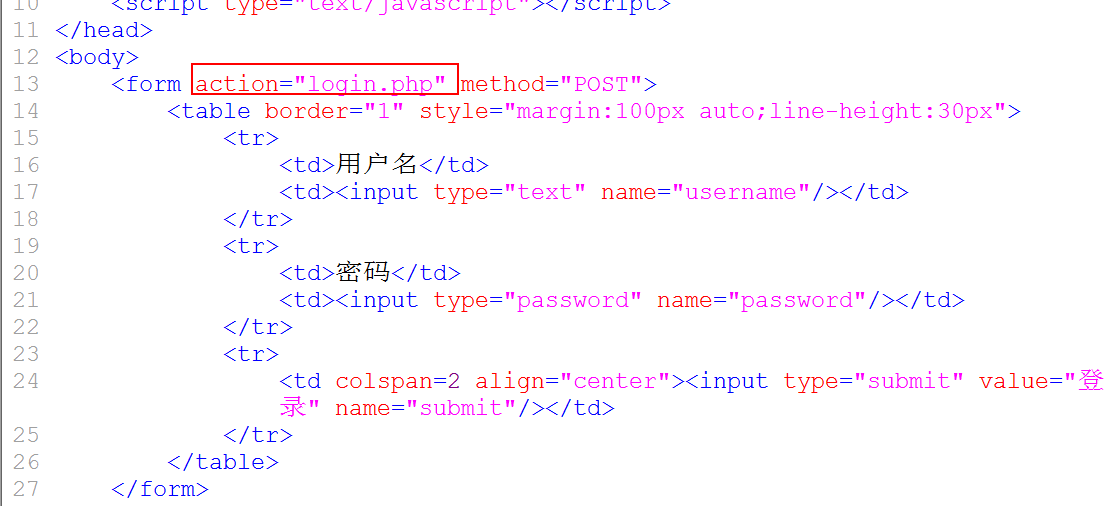
4. 用户输入信息之后,就会选择提交: 提交之后都是由服务器的login.php进行处理: login.php应该选择性进行处理: 做出不同的响应.
5. 获取用户提交的数据.
6. 合法性验证: 验证数据是否满足验证的基本条件: 用户名和密码都不能为空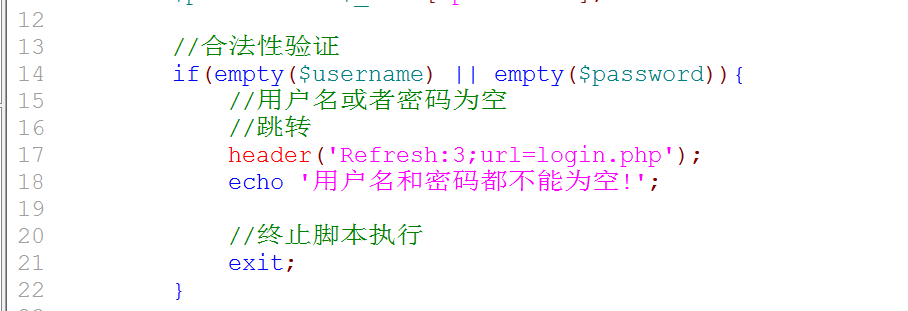
7. 存在乱码: 中文问题: header解决.
8. 用户在输入的过程很有可能输入了空格且不是真实需求: 所以应该获取用户信息的时候就去掉空格: trim
9. 合理性验证: 合法的数据是否最终与数据库的数据匹配: 搭建数据库环境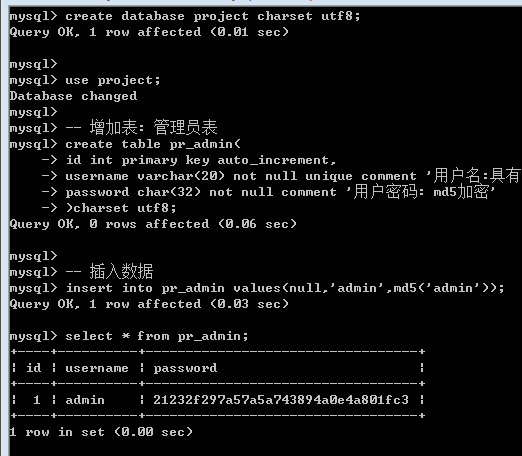
10. 操作数据库: 进入到数据库admin表中,查询用户名和密码对应是否存在. 操作数据库的位置很多,都需要进行初始化操作: 将数据库的初始化封装到一个单独的文件中: mysql.php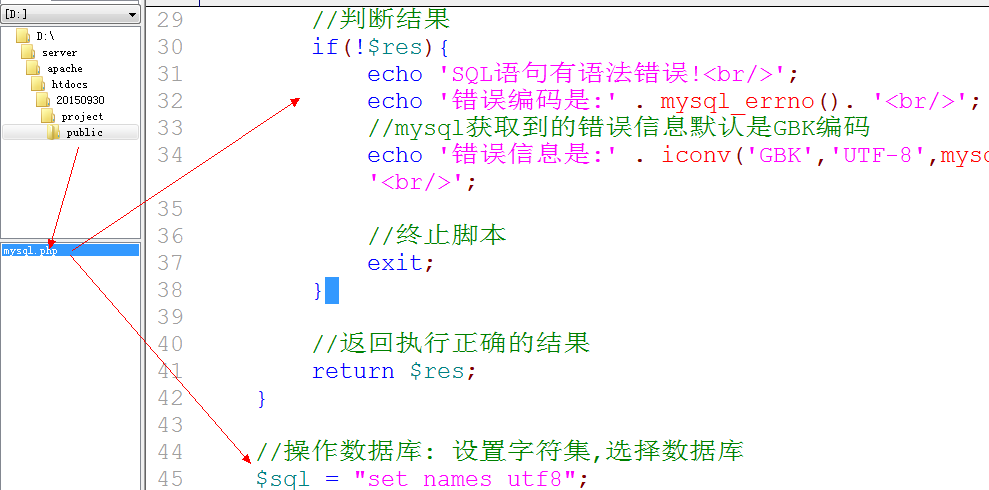
11. 在登录验证用户信息的时候,调用公共数据库文件: 然后操作数据库/project/login.php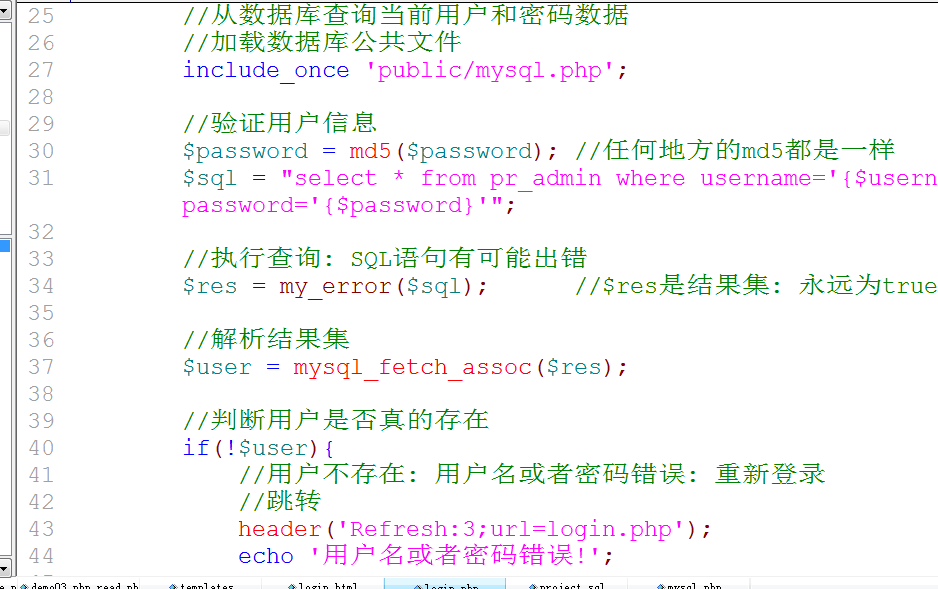
12. 跳转代码是重复代码: 封装成独立的函数来实现: 在公共文件夹中创建一个新的公共文件: public.php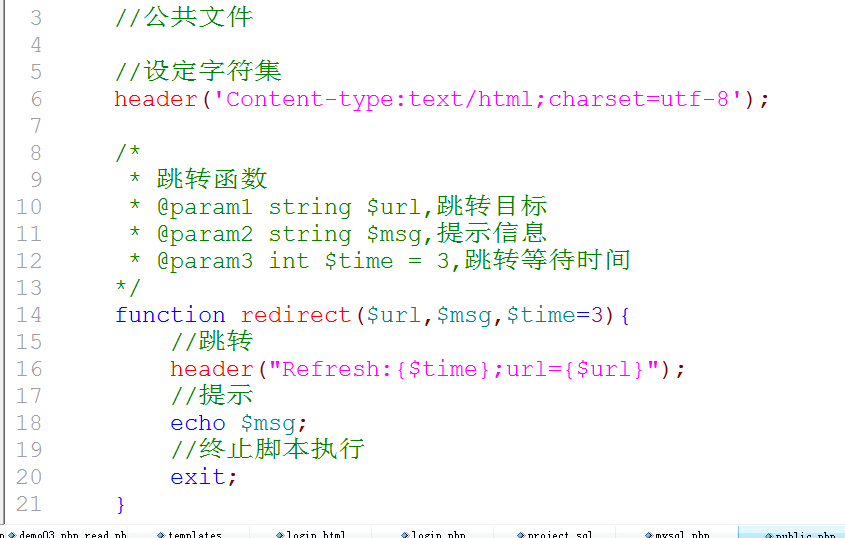
13. 任何一个被用户请求的php文件都应该加载public.php文件.
14. 在任何需要跳转的地方,调用跳转函数
15. SQL注入问题: 用户通过程序的漏洞(程序直接拼凑用户输入的信息到SQL语句), 输入一些特殊字符(引号’)来改变原来的SQL语句执行的机制: 如何防止? 想办法组织引号: addslashes()增加转义符号.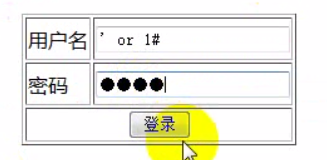
 典型的sql注入方法,前半部分select * from pr_admin where username=’’
典型的sql注入方法,前半部分select * from pr_admin where username=’’
’ or 1,前面的单引号组成username=‘’,or 1,永远为真,#号表示注释,将后半部分sql注释。直接通告验证。

使用addslashes转义特殊字符,这里讲 ’ or 1# 单引号转义,使得’ or 1# 为一个字符串进行验证。
15. 用户登录成功,应该进入后台首页
分页显示数据功能
用户登录之后: 可以直接看到结果.
1. 增加一个显示数据的表单
2. 首页是登录之后跳转过去: 跳转到index.php文件.
3. 获取数据: 设计数据库
4. 调用数据库初始化文件: 从数据表获取所有的学生信息.
5. 在模板中显示所有的数据
分页功能
- 给用户增加一个可以点击的上一页,下一页,首页,末页的功能.

2. 确定a链接的href对象. 请求对象是index.php
3. 分页效果: 点击上一页,应该是在当前页的基础上减掉一页, 如果是首页应该是第一页: 要传一个页码参数.
4. 想办法取出一些跟分页相关的数据.
5. 求出上一页的页码以及下一页的页码.
6. 获取总记录数,求出总页码.
7. 将求出来的数据放到对应的页码位置.

若有收获,就点个赞吧
0 人点赞
