本文由 简悦 SimpRead 转码, 原文地址 www.cnblogs.com
原文地址:https://blog.fanscore.cn/p/22/
一、背景
公司当前有一个用户群的系统,核心功能是根据不同的条件组去不同的业务线中 get 符合条件的 uid 列表,然后存到 redis 中的 bitmap 中。
举个🌰,如果一个用户群中有两个用户: 3 和 7,即
[3,7],用 bitmap 表示那就是:00010001(下标3和7的位为1)
最后利用 redis 提供的 bitOp 命令: bitOp AND \ bitOp XOR \ bitOp OR对各个条件组对应的 uid 列表 bitmap 做交并差集计算,得出最终的用户群并存储到 redis bitmap 中。
二、问题
对于上面描述的系统,如果用户群人数较多的那我们就需要执行较多次的setBit {uid} 1命令,而且如果用户群中的第一个 uid 是一个特别大的值比如 10 亿的话,就可能会一次 malloc 1000000000/1024/1024/8 ~= 120M 的内存,这可能会导致 redis 卡住一段时间,在高并发的 redis 实例上执行这个操作是相当危险的。而且可以预想到对于两个较大的 bitmap key 执行bitOp也是非常消耗 CPU 的,应该尽量避免在存储型的 redis 实例中做这种十分消耗 CPU 的计算操作。
实际上内存最少只能申请一个字节,即8位,所以上面的计算方式稍有出入,但相差并不大
三、解决方案
针对上述的问题,可以将 bitmap 的计算挪到应用程序中来,只将最终统计出来的 bitmap 存储到 redis 中即可。如果最终结果用户群中的第一个 uid 是一个特别大的值的话,可以设置多个bitmap,如bitmap1存储1千万的uid,bitmap2存储2千万的….;如第一个uid为1亿,1亿/1千万=10,将其放到bitmap10里面,偏移量(下标)也缩小1亿倍,1亿的下标为1;
四、PHP 实现 Bitmap
由于该系统目前是使用的 PHP,所以下面记录下 PHP 实现 Bitmap 的” 心路历程 “。
由于要操作 PHP 变量的某一位,所以就要借助位运算来实现,但是又由于 PHP 的位运算只能作用在整型数上,所以我们无法使用字符串或者浮点数来实现,所以最先考虑的就是使用整型数组来实现。
为什么是数组呢?因为在 64 位机器上一个整型变量最多只能使用 64 位,又由于 PHP 的整型是有符号的,所以最高位无法供我们使用,所以一个整型变量能存储的最大的 uid 就是 63,这真是太鸡肋了 -_-||,所以只能搞个用多个整型变量了实现了。
OK,到此为止貌似找到一个看起来不错的解决方案。但是我们再思考这样一个问题:假设我们系统中最大的 uid 是 63x100 万 = 3.6 千万(对主流互联网公司来说这很正常吧😸),那为了存储所有 uid,我们需要 1 百万个整数才行,即我们需要一个拥有 1 百万个元素的数组,那么如果我在进程中制造了一个这样的数组会占用多少内存呢?会是64 * 1百万 / 1024 / 1024 / 8 ~= 7.6M吗?答案是否定的,因为 php 数组是由HashTable实现的,这是一个复杂的结构体,除了数组元素占用的内存外,还有其他的占用。(这里先不做展开,有兴趣可以自行查看下 php 数组的实现)
眼见为实:
<?phpini_set('memory_limit','4G');var_dump(memory_usage());$arr = [];for ($i = 0; $i < 1000000; $i++){$arr[] = PHP_INT_MAX;}function memory_usage() {$memory = ( ! function_exists('memory_get_usage')) ? '0' : round(memory_get_usage()/1024/1024, 2).'MB';return $memory;}echo "done\n";var_dump(memory_usage());
查看内存占用
五、继续优化
基于上面的经验,如果我们要占用尽可能小的内存,那我们必须能够操作一段近乎无限长的内存且不能产生其他额外占用才可以。幸运的是 PHP 给我们提供了这样一个扩展:GMP,这个扩展可以让我们使用一个任意长度的整数。OK 现在我们拥有了获得一块连续的内存而不会产生其他额外占用的手段,再写一段代码使用下并验证下内存占用情况:
<?php
$gmp = gmp_init(0);
gmp_setbit($gmp, 64 * 1000000, true);
echo "done\n";
while(1){}
Awesome,这次只使用了 15M 的内存。更加兴奋的是这个扩展提供了诸如:gmp_and、gmp_or、gmp_xor这样进行位运算的函数,极大的方便了我们的使用。
到此为止我们似乎找到了一个完美的解决方案,但是真的完美吗?No!其实还可以再优化一下,想象下如果我们有一个用户群,里面只有一个 uid:64000000(表示为数组的话就是:[64000000]),为了存储这个用户我们需要占用 7.6M 内存,而这个用户群中仅仅只有一个元素,这真是极大的浪费啊!
为了优化这个问题可以拥抱上面被我们唾弃的数组😸,一个大的 bitmap (6千4百万位)拆分为一个个小 bitmap 的数组,这一个个小的 bitmap 我们限制大小为 1千万 位。
回到上面的问题,如果我们要存储[64000000]这个用户群的话只需要在数组的第 6 个元素中(6千万开始)设置一个 little bitmap: 1即可。这样我们就由一开始的占用 7.6M 内存优化为了占用 1 位内存。
OK,到此为止我们找到一个还不错的解决方案😸。
后言
为了在 Mac 中安装 GMP 扩展又耗费了很多时间,当然,这又是另外一个故事了。有时间我会分享 Mac 中安装 GMP 扩展的过程中我遇到的问题。
参考资料
例子:PHP实现简单的bitmap
本文由 简悦 SimpRead 转码, 原文地址 blog.csdn.net
作用
大量数据进行排序,查找和去重上可以使用这个策略来降低内存的使用
代码
class BitMap
{
public static $map = [];
public static function setValue($value) {
$index = self::getIndex($value);
if (isset(self::$map[$index])) {
self::$map[$index] |= 1 << ($value & 31);
} else {
self::$map[$index] = 1 << ($value & 31);
}
}
public static function haxValue($value) {
$index = self::getIndex($value);
return isset(self::$map[$index]) ? (self::$map[$index] & (1 << ($value & 31))) == (1 << ($value & 31)) : false;
}
public static function display()
{
$keys = array_keys(self::$map);
foreach ($keys as $key) {
print "map index: {$key}, bit:";
$temp = self::$map[$key];
$bit_str = '';
for ($i = 0; $i <= 31; $i++) {
$bit_str = (1 & $temp) . $bit_str;
$temp >>= 1;
}
echo "{$bit_str}\n";
}
}
// 计算落在哪一个数组的下标中,每个数组中的值占用4字节,能保存32个状态;
//按位右移 5 位 ,就是除 (2^5=32) ,结果取整,和:floor($value / 32)一样
private static function getIndex($value) {
return $value >> 5;
}
}
$list = [1, 3, 3, 7, 25, 88, 0];
foreach ($list as $value) {
BitMap::setValue($value);
}
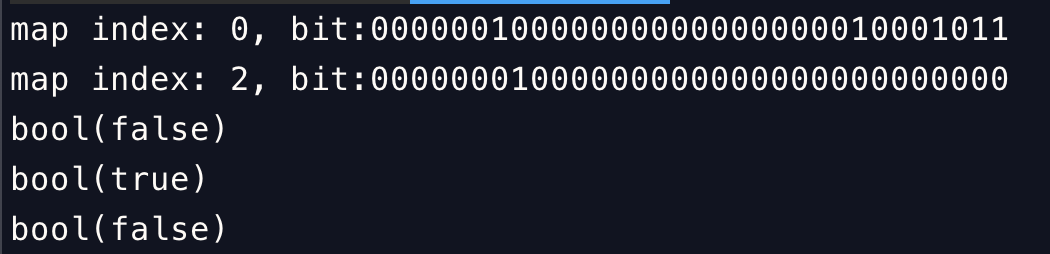
BitMap::display();
var_dump(BitMap::haxValue(87));
var_dump(BitMap::haxValue(88));
var_dump(BitMap::haxValue(89));
策略
1 个 4 字节的整型变量有 32 比特,所以我们用一个 int 来表示 32 个数字是否存在 (哪个数字存在那么那一位上就是 1);
实际上:
$map[0] 表示 [0, 31]
$map[1] 表示 [32, 63]
$map[2] 表示 [64, 95]
整个类包含两个主要的方法: setValue和hasValue。
先描述getIndex()的作用,实际上是将输入值对 32 取模,可以按位右移 5 位 (2^5=32) 的方式或者floor($value / 32)等各种方式,按位操作会快嘛,用这个舒服。
再说setValue()方法,核心代码就 1 行:
self::$map[$index] |= 1 << ($value & 31);
首先$value & 31实际上就是将输入值对 32 取模。31 转换成二进制实际上就是 5 个 1,拿着输入值的后 5 位,来跟这 5 个 1 按位与,得到一个偏移量。记录偏移量实际就是记录了输入值存在。 然后这里有一个按位或的操作,起到了将多个偏移量聚合,且去重的作用。
其次我们来看hasValue()方法,核心代码也就 1 行,暂时没想到更好的写法:
(self::$map[$index] & (1 << ($value & 31))) == (1 << ($value & 31))
在我们完成setValue()的行为后,map 中值的二进制展示大概是这样:
bit:00000010000000000000000010001011
上述值我取的是$map[0], 如果 3 是存在,那么从右往左数 4 位,那一位一定是 1,否则是 0。所以判断的方式是我们构造出来一个二进制的1000, 拿着这个数去和$map[0]按位与。这里有且仅有 2 种可能性:
- 3 存在:那么返回二进制的
1000 - 3 不存在: 那么返回 0
所以这里也可以写成:
(self::$map[$index] & (1 << ($value & 31))) != 0
因为我们构造的操作数有且仅有 1 位是 1。
其他代码没什么好说的,执行一下就完事儿了。

若有收获,就点个赞吧
0 人点赞
