回顾
连接查询: 多张表连接到一起, 不管记录数如何,字段数一定会增加.
分类: 内连接,外连接,自然连接和交叉连接
交叉连接: cross join(笛卡尔积)
内连接: inner join, 左右两张表中有连接条件匹配(不匹配的忽略)
外连接: outer [left/right] join, 主表有的记录一定会存在, 匹配了就保留副表字段数据,没匹配到副表字段置空
自然连接: natural join, 自动匹配条件(相同的字段名), using关键字
PHP操作mysql
PHP充当客户端: 开启mysql扩展
连接认证:mysql_connect; 发送SQL获取结果: mysql_query; 解析结果集: mysql_fetch系列; 释放资源: mysql_free_result和mysql_close
错误处理: mysql_errno和mysql_error
**
外键
外键: foreign key, 外面的键(键不在自己表中): 如果一张表中有一个字段(非主键)指向另外一张表的主键,那么将该字段称之为外键.
增加外键
外键可以在创建表的时候或者创建表之后增加(但是要考虑数据的问题).
一张表可以有多个外键.
创建表的时候增加外键: 在所有的表字段之后,使用foreign key(外键字段) references 外部表(主键字段)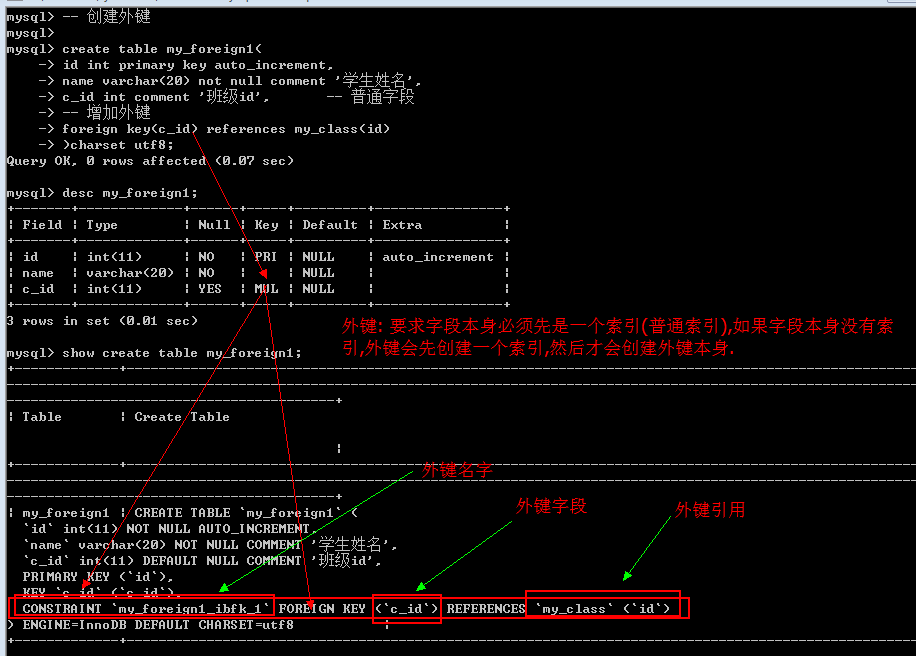
在新增表之后增加外键: 修改表结构
Alter table 表名 add [constraint 外键名字] foreign key(外键字段) references 父表(主键字段);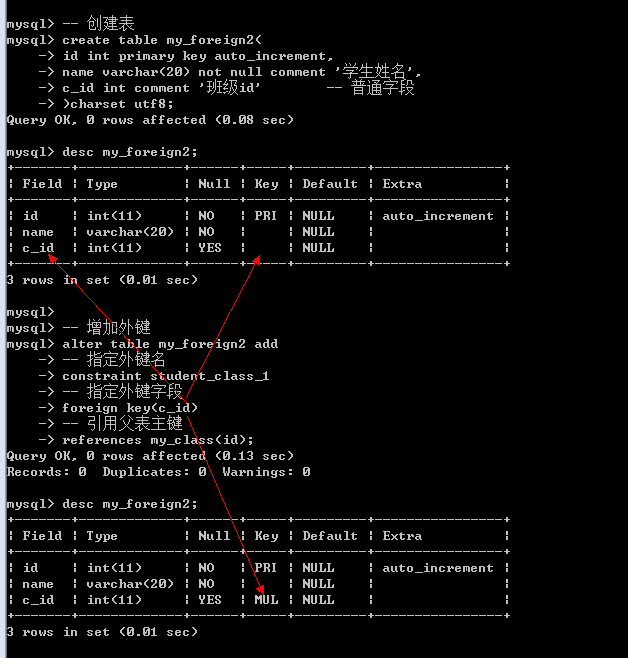
修改外键&删除外键
外键不可修改: 只能先删除后新增.
删除外键语法
Alter table 表名 drop foreign key 外键名; — 一张表中可以有多个外键,但是名字不能相同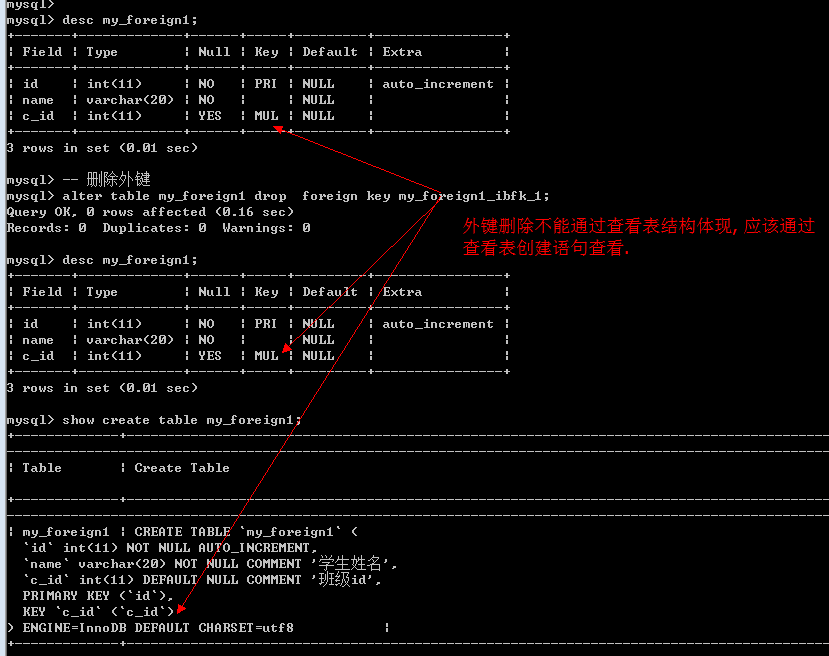
外键作用
外键默认的作用有两点: 一个对父表,一个对子表(外键字段所在的表)
对子表约束: 子表数据进行写操作(增和改)的时候, 如果对应的外键字段在父表找不到对应的匹配: 那么操作会失败.(约束子表数据操作)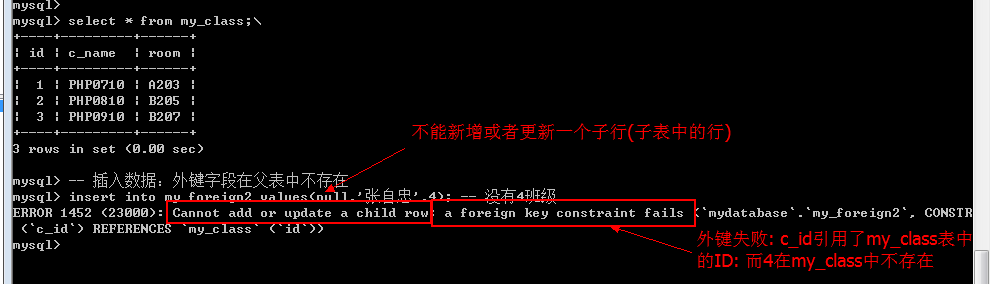
对父表约束: 父表数据进行写操作(删和改: 都必须涉及到主键本身), 如果对应的主键在子表中已经被数据所引用, 那么就不允许操作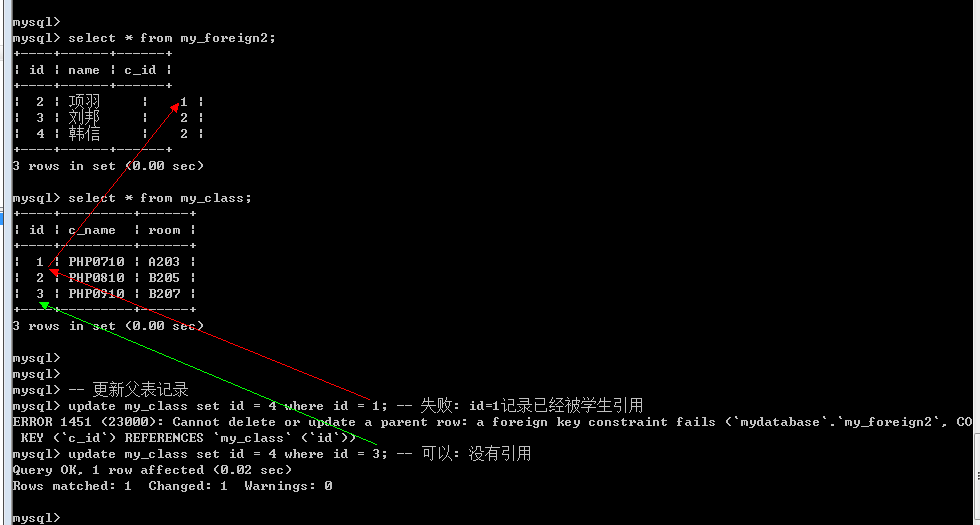
外键条件
1. 外键要存在: 首先必须保证表的存储引擎是innodb(默认的存储引擎): 如果不是innodb存储引擎,那么外键可以创建成功,但是没有约束效果.
2. 外键字段的字段类型(列类型)必须与父表的主键类型完全一致.
3. 一张表中的外键名字不能重复.
4. 增加外键的字段(数据已经存在),必须保证数据与父表主键要求对应.
外键约束
所谓外键约束: 就是指外键的作用.
之前所讲的外键作用: 是默认的作用; 其实可以通过对外键的需求, 进行定制操作.
外键约束有三种约束模式: 都是针对父表的约束
District: 严格模式(默认的), 父表不能删除或者更新一个已经被子表数据引用的记录
Cascade: 级联模式: 父表的操作, 对应子表关联的数据也跟着被删除(如删除主表id为3的数据,子表外键是3的所有记录都会自动被一起删除,更新主表id为3的数据,子表外键也会一同修改)
Set null: 置空模式: 父表的操作之后,子表对应的数据(外键字段)被置空(如删除主表id为3的数据,子表外键是3的所有值都变为空)
通常的一个合理的做法(约束模式): 删除的时候子表置空, 更新的时候子表级联操作
指定模式的语法
Foreign key(外键字段) references 父表(主键字段) on delete set null on update cascade;
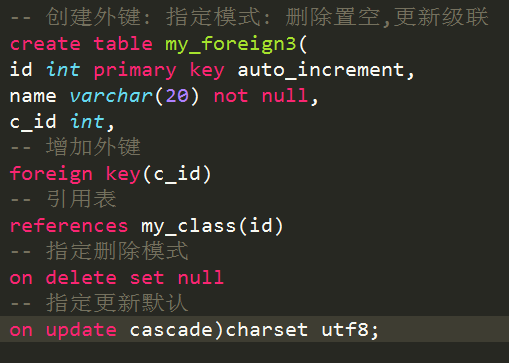
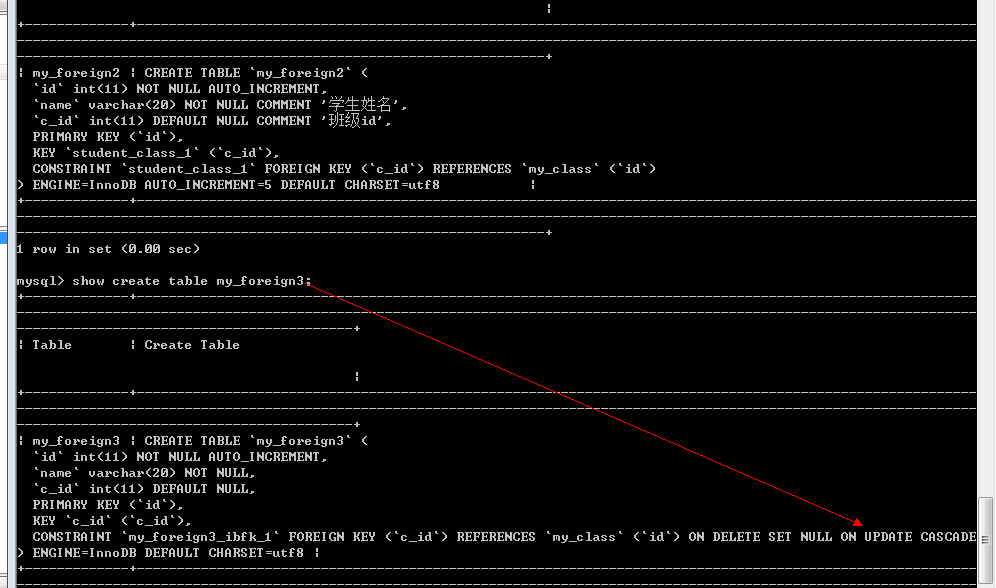
更新操作: 级联更新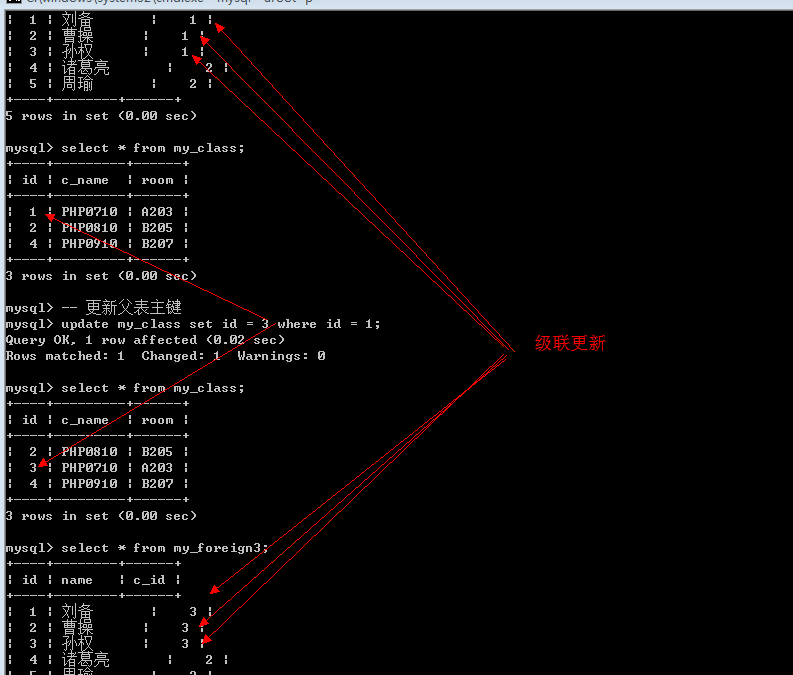
删除操作: 置空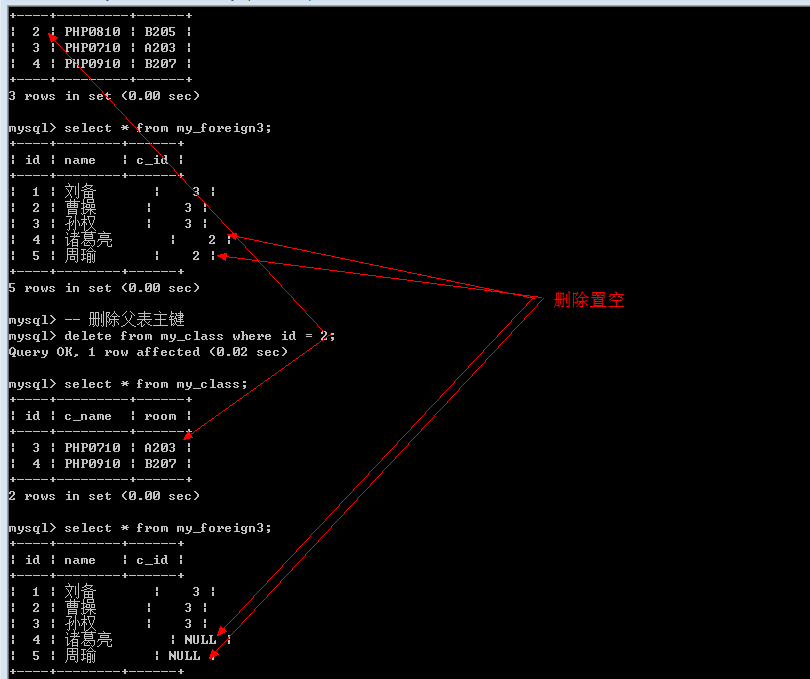
删除置空的前提条件: 外键字段允许为空(如果不满足条件,外键无法创建)
外键虽然很强大, 能够进行各种约束: 但是对于PHP来讲, 外键的约束降低了PHP对数据的可控性: 通常在实际开发中, 很少使用外键来处理.
联合查询
联合查询: 将多次查询(多条select语句), 在记录上进行拼接(字段不会增加)
基本语法
多条select语句构成: 每一条select语句获取的字段数必须严格一致(但是字段类型无关)
Select 语句1
Union [union选项]
Select语句2…
Union选项: 与select选项一样有两个
All: 保留所有(不管重复)
Distinct: 去重(整个重复): 默认的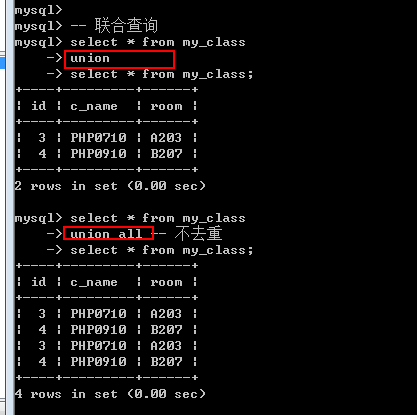
联合查询只要求字段一样, 跟数据类型无关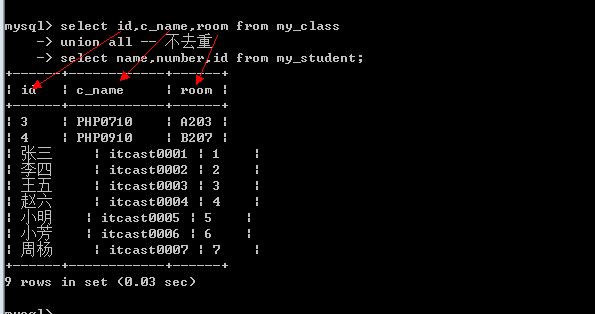
意义
联合查询的意义分为两种:
1. 查询同一张表,但是需求不同: 如查询学生信息, 男生身高升序, 女生身高降序.
2. 多表查询: 多张表的结构是完全一样的,保存的数据(结构)也是一样的.(如分表的数据,表结构都是一样的,进行统计的时候就可以使用联合查询)
Order by使用
在联合查询中: order by不能直接使用,需要对查询语句使用括号才行
若要orderby生效: 必须搭配limit: limit使用限定的最大数即可.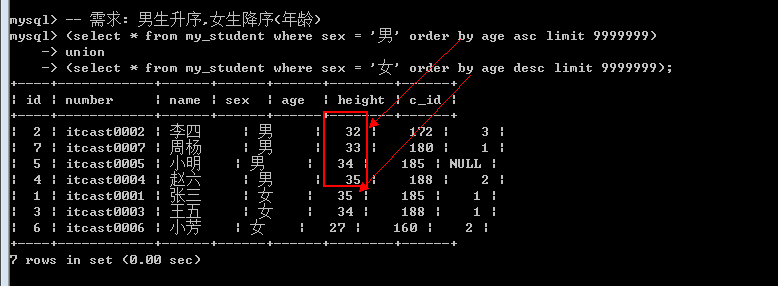
子查询
子查询: sub query, 查询是在某个查询结果之上进行的.(一条select语句内部包含了另外一条select语句)
子查询分类
子查询有两种分类方式: 按位置分类; 按结果分类
按位置分类: 子查询(select语句)在外部查询(select语句)中出现的位置
From子查询: 子查询跟在from之后
Where子查询: 子查询出现where条件中
Exists子查询: 子查询出现在exists里面
按结果分类: 根据子查询得到的数据进行分类(理论上讲任何一个查询得到的结果都可以理解为二维表)
标量子查询: 子查询得到的结果是一行一列
列子查询: 子查询得到的结果是一列多行
行子查询: 子查询得到的结果是多列一行(多行多列)
上面几个出现的位置都是在where之后
表子查询: 子查询得到的结果是多行多列(出现的位置是在from之后)
标量子查询
需求: 知道班级名字为PHP0710,想获取该班的所有学生.
1. 确定数据源: 获取所有的学生
Select * from my_student where c_id = ?;
2. 获取班级ID: 可以通过班级名字确定
Select id from my_class where c_name = ‘PHP0710’; — id一定只有一个值(一行一列)
第二个select,也就是where后面的子查询的结果肯定是一行一列。就是标量子查询
标量子查询实现
列子查询
需求: 查询所有在读班级的学生(班级表中存在的班级)
1. 确定数据源: 学生
Select * from my_student where c_id in (?);
2. 确定有效班级的id: 所有班级id
Select id from my_class;
子查询的结果是一列多行就是列子查询
列子查询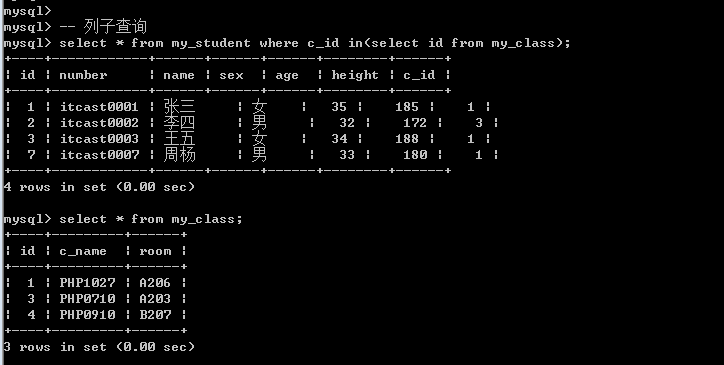
列子查询返回的结果会比较: 一列多行, 需要使用in作为条件匹配: 其实在mysql中有还有几个类似的条件: all, some, any
=Any ==== in; — 其中一个即可
Any ====== some; — any跟some是一样
=all ==== 为全部
肯定结果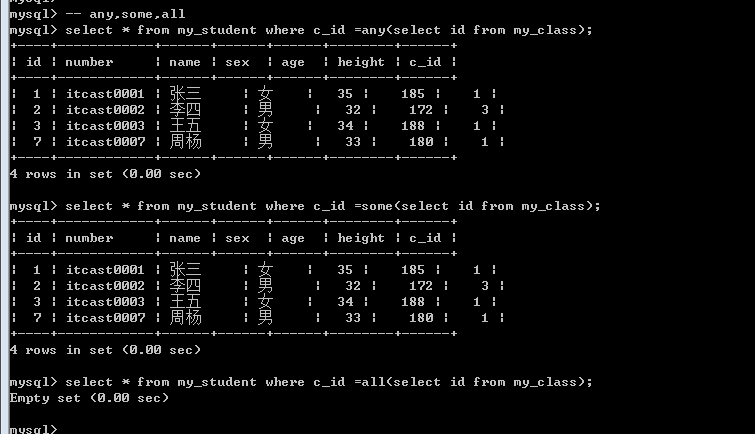
否定结果(不常用)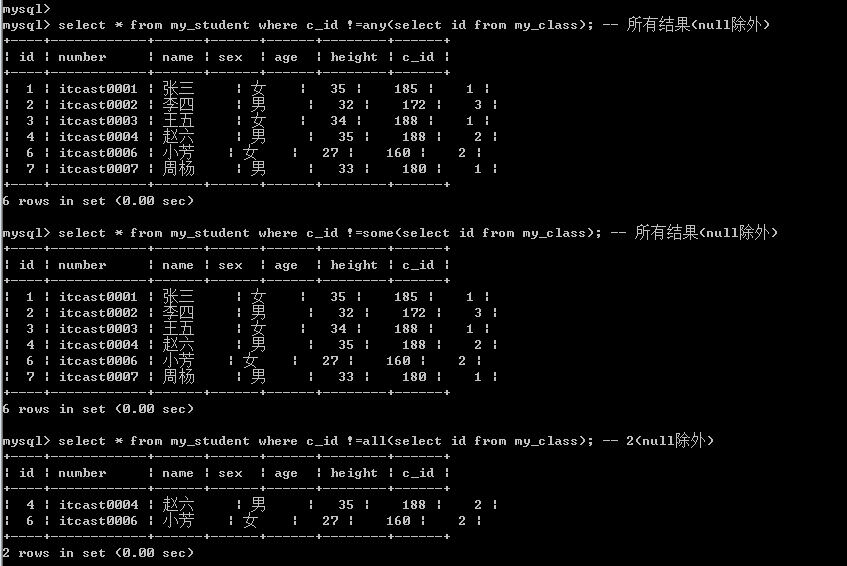
行子查询
行子查询: 返回的结果可以是多行多列(一行多列)
需求: 要求查询整个学生中,年龄最大且身高是最高的学生.
1. 确定数据源
Select * from my_student where age = ? And height = ?;
2. 确定最大的年龄和最高的身高;
Select max(age),max(height) from my_student;
普通查询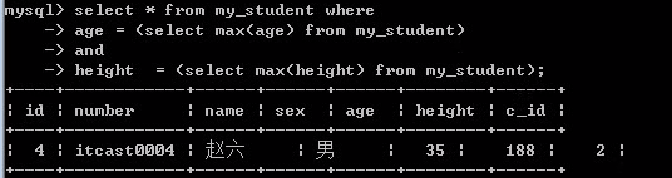
行子查询: 需要构造行元素: 行元素由多个字段构成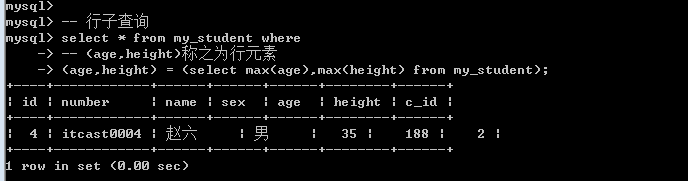
表子查询
表子查询: 子查询返回的结果是多行多列的二维表: 子查询返回的结果是当做二维表来使用
需求: 找出每一个班最高的一个学生.
1. 确定数据源: 先将学生按照身高进行降序排序
Select from my_student order by height desc;
2. 从每个班选出第一个学生
Select from my_student group by c_id; — 每个班选出第一个学生
因为group by 分组之后默认显示的是第一条结果,所以这里需要按照学生身高倒叙生成一张虚拟表,在这个虚拟表中进行分组操作。
表子查询: from子查询: 得到的结果作为from的数据源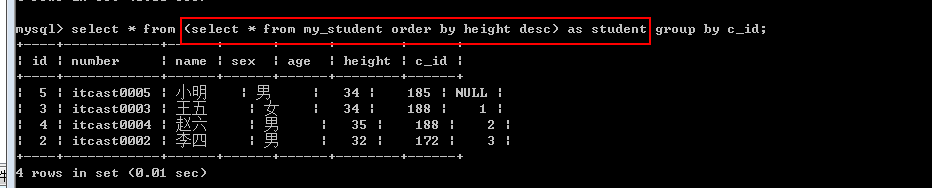
Exists子查询
Exists: 是否存在的意思, exists子查询就是用来判断某些条件是否满足(跨表), exists是接在where之后: exists返回的结果只有0和1.
需求: 查询所有的学生: 前提条件是班级存在
1. 确定数据源
Select from my_student where ?;
2. 确定条件是否满足
Exists(Select from my_class); — 是否成立
Exists子查询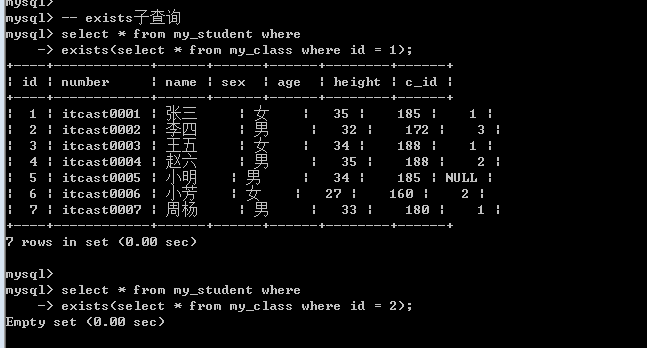
视图
视图: view, 是一种有结构(有行有列)但是没结果(结构中不真实存放数据)的虚拟表, 虚拟表的结构来源不是自己定义, 而是从对应的基表中产生(视图的数据来源).
创建视图
基本语法
Create view 视图名字 as select语句; — select语句可以是普通查询;可以是连接查询; 可以是联合查询; 可以是子查询.
创建单表视图: 基表只有一个
创建多表视图: 基表来源至少两个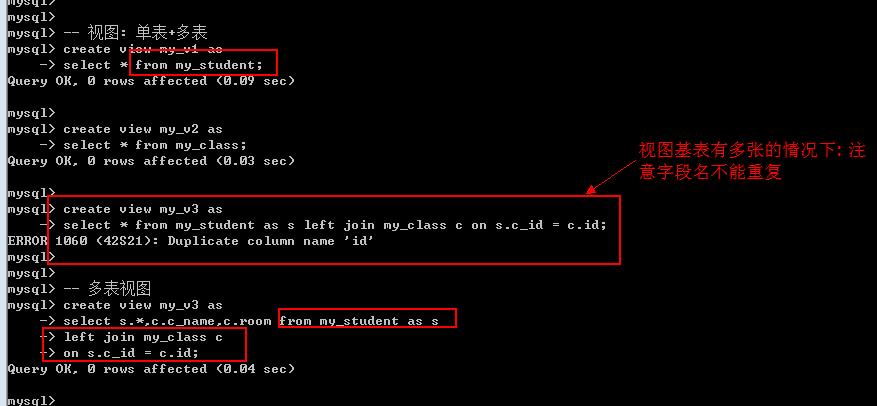
查看视图
查看视图: 查看视图的结构
视图是一张虚拟表: 表, 表的所有查看方式都适用于视图: show tables [like]/desc 视图名字/show create table 视图名;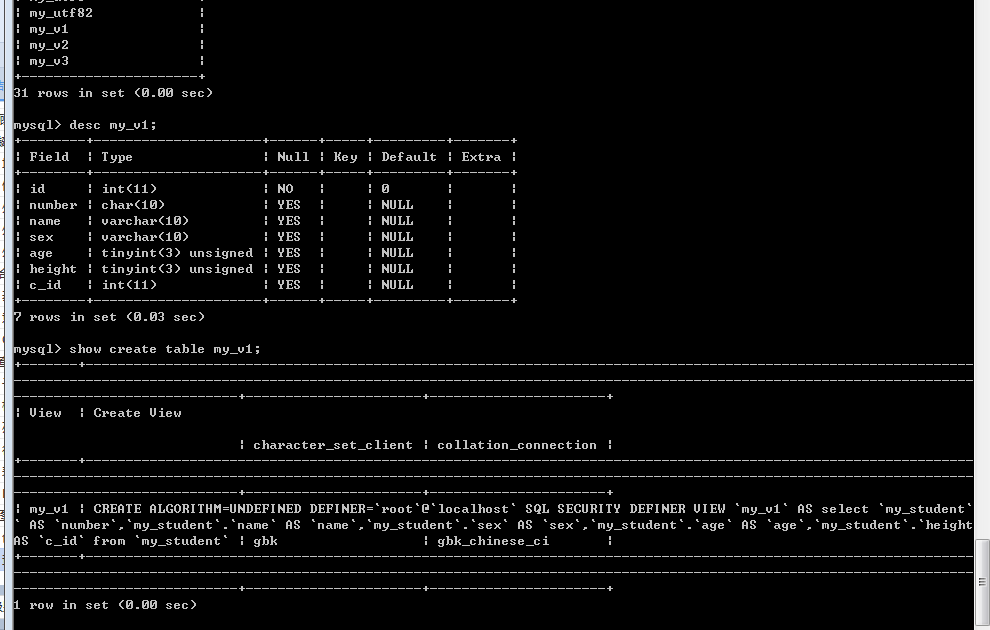
视图比表还是有一个关键字的区别: view. 查看”表(视图)”的创建语句的时候可以使用view关键字
视图一旦创建: 系统会在视图对应的数据库文件夹下创建一个对应的结构文件: frm文件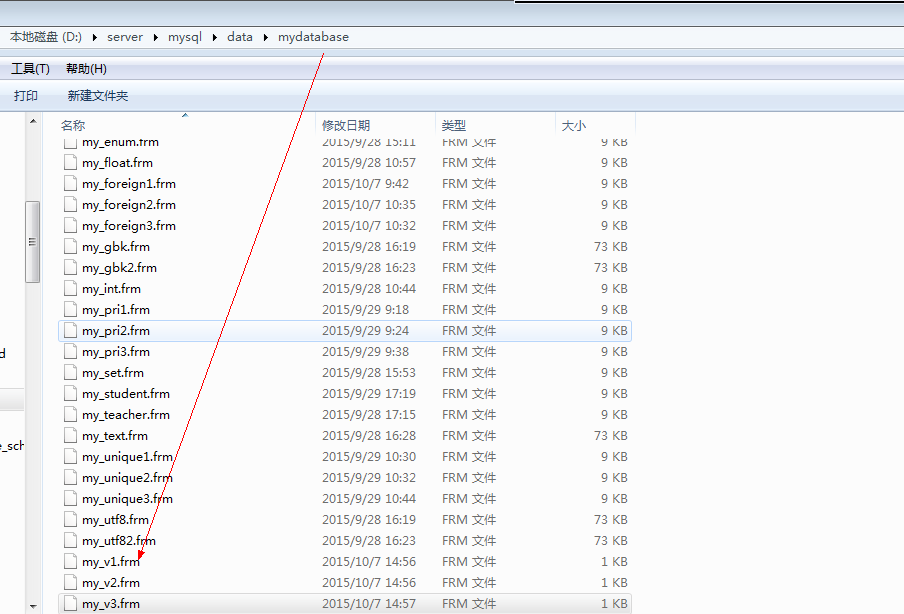
使用视图
使用视图主要是为了查询: 将视图当做表一样查询即可.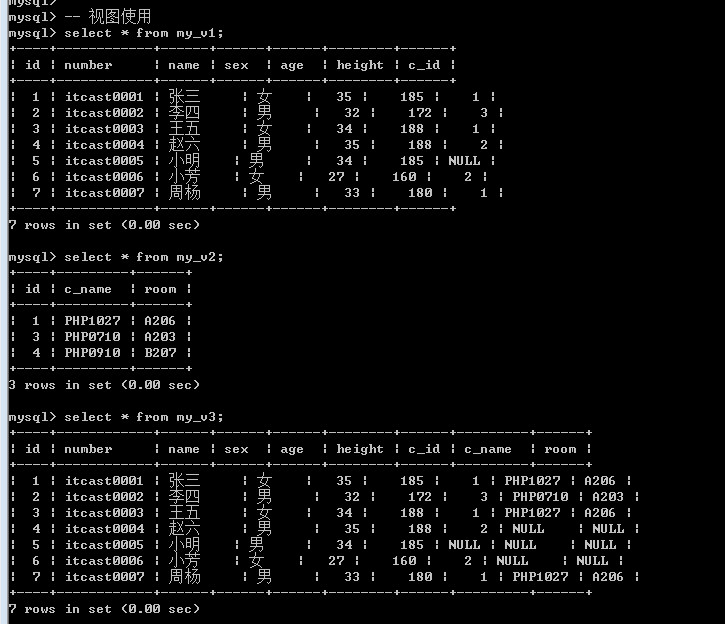
视图的执行: 其实本质就是执行封装的select语句.
修改视图
视图本身不可修改, 但是视图的来源是可以修改的.
修改视图: 修改视图本身的来源语句(select语句)
Alter view 视图名字 as 新的select语句;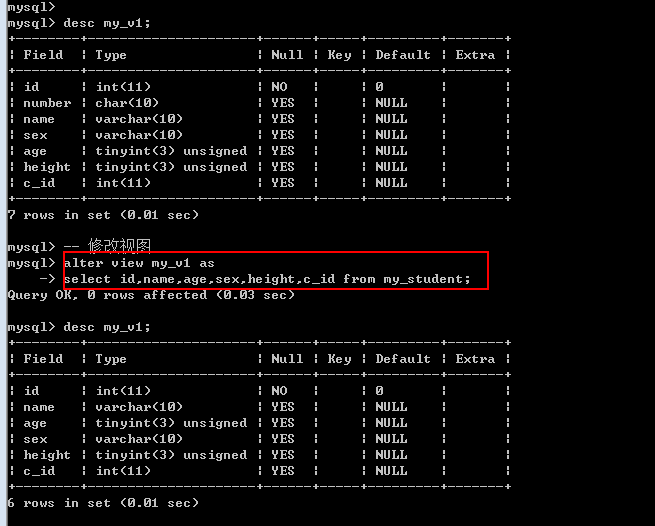
删除视图
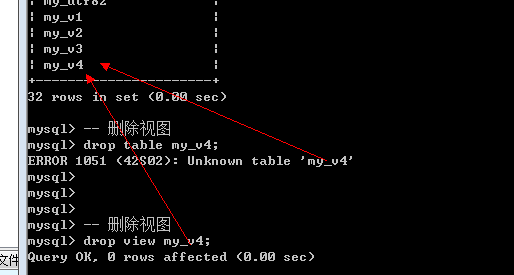
视图意义
1. 视图可以节省SQL语句: 将一条复杂的查询语句使用视图进行保存: 以后可以直接对视图进行操作
2. 数据安全: 视图操作是主要针对查询的, 如果对视图结构进行处理(删除), 不会影响基表数据(相对安全).
3. 视图往往是在大项目中使用, 而且是多系统使用: 可以对外提供有用的数据, 但是隐藏关键(无用)的数据: 数据安全。(如用户表有很多用户的隐私,通过创建用户表中的普通信息进行创建视图,对外访问这个视图表即可。,)
4. 视图可以对外提供友好型: 不同的视图提供不同的数据, 对外好像专门设计
5. 视图可以更好(容易)的进行权限控制
视图数据操作
视图是的确可以进行数据写操作的: 但是有很多限制
将数据直接在视图上进行操作.
新增数据
数据新增就是直接对视图进行数据新增.
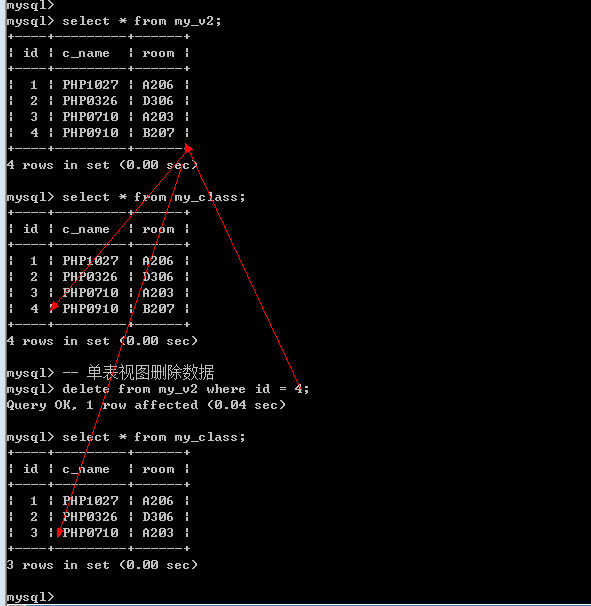
1. 多表视图不能新增数据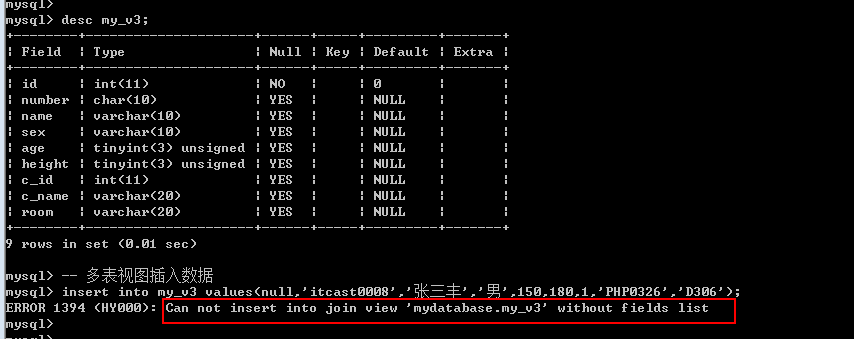
2. 可以向单表视图插入数据: 但是视图中包含的字段必须有基表中所有不能为空(或者没有默认值)字段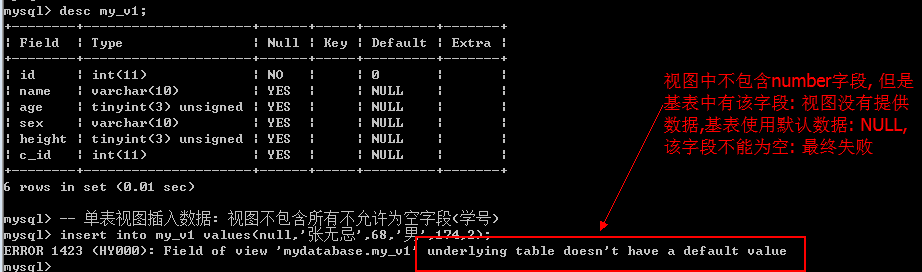
3. 视图是可以向基表插入数据的.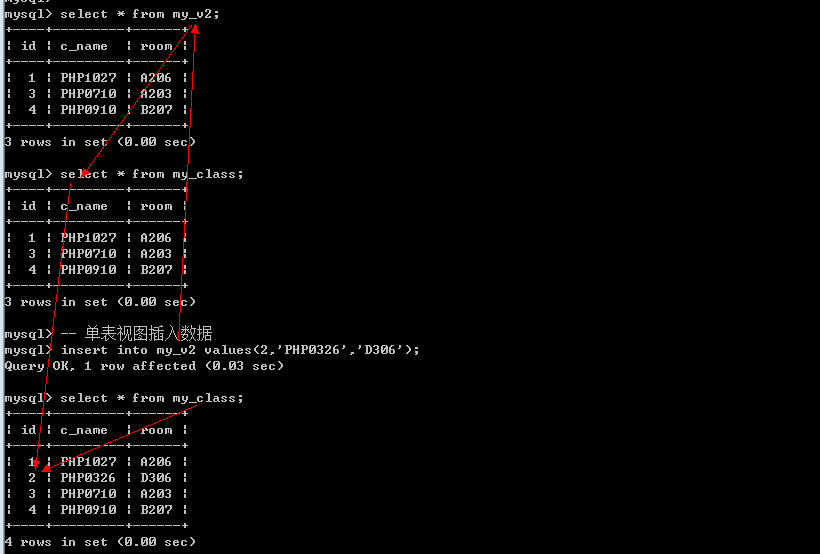
删除数据
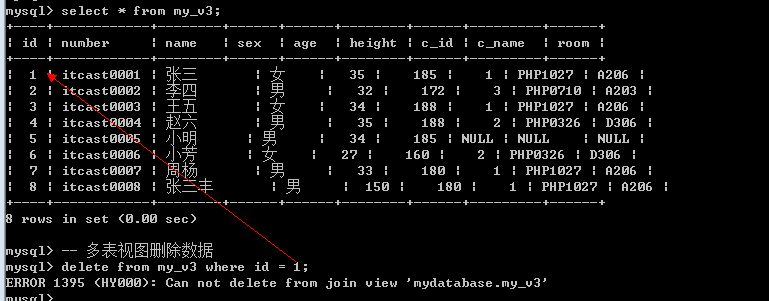
更新数据
理论上无论单表视图还是多表示视图都可以更新数据.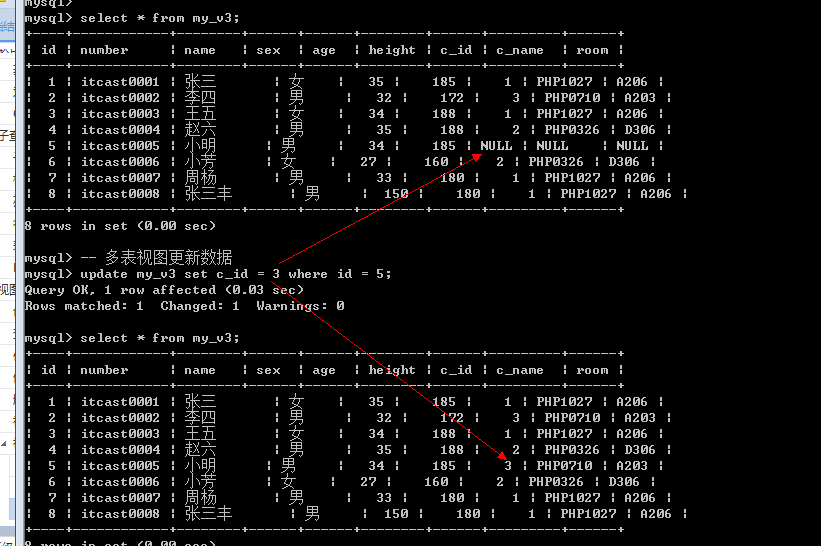
更新限制: with check option, 如果对视图在新增的时候,限定了某个字段有限制: 那么在对视图进行数据更新操作时,系统会进行验证: 要保证更新之后,数据依然可以被实体查询出来,否则不让更新.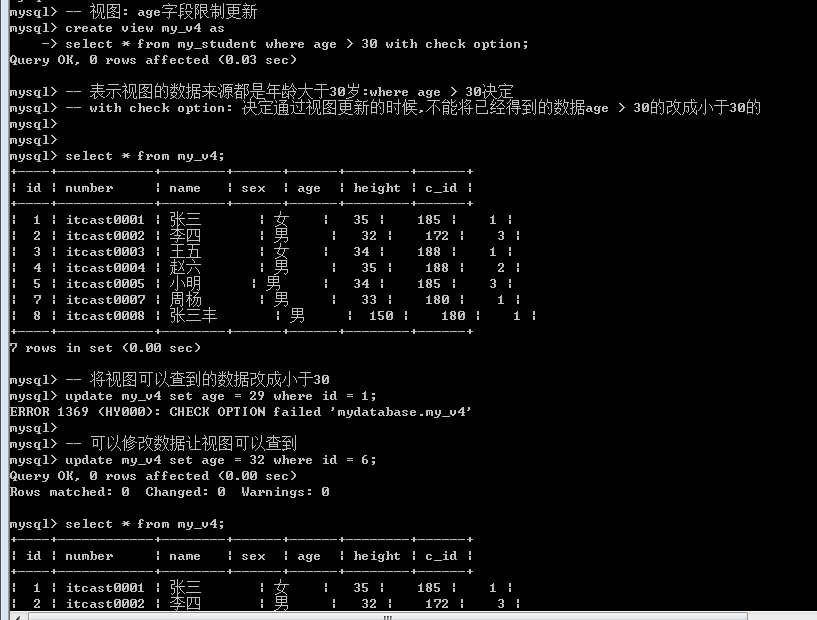
视图算法
视图算法: 系统对视图以及外部查询视图的Select语句的一种解析方式.
视图算法分为三种
Undefined: 未定义(默认的), 这不是一种实际使用算法, 是一种推卸责任的算法: 告诉系统,视图没有定义算法, 系统自己看着办
Temptable: 临时表算法: 系统应该先执行视图的select语句,后执行外部查询语句
Merge: 合并算法: 系统应该先将视图对应的select语句与外部查询视图的select语句进行合并,然后执行(效率高: 常态)
算法指定: 在创建视图的时候
Create algorithm = 指定算法 view 视图名字 as select语句;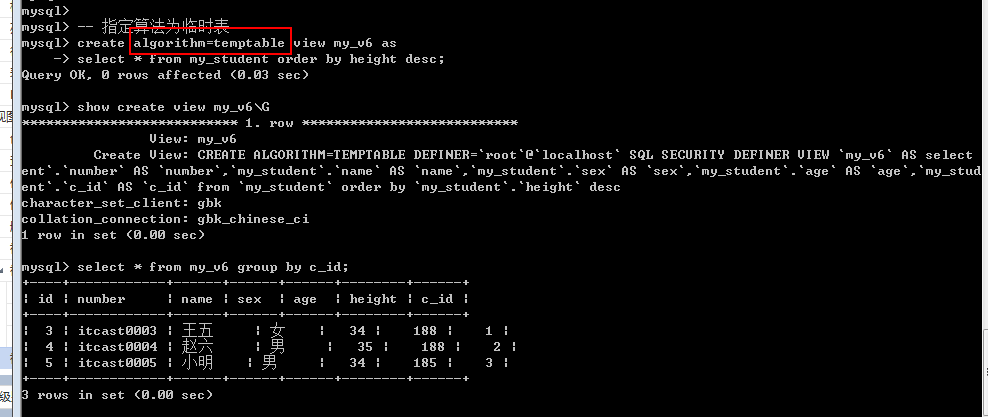
视图算法选择: 如果视图的select语句中会包含一个查询子句(五子句where, group by, order by,limit,having ), 而且很有可能顺序比外部的查询语句要靠后, 一定要使用算法temptable,其他情况可以不用指定(默认即可).
数据备份与还原
备份: 将当前已有的数据或者记录保留
还原: 将已经保留的数据恢复到对应的表中
为什么要做备份还原?
1. 防止数据丢失: 被盗, 误操作
2. 保护数据记录
数据备份还原的方式有很多种: 数据表备份, 单表数据备份, SQL备份, 增量备份.
数据表备份
不需要通过SQL来备份: 直接进入到数据库文件夹复制对应的表结构以及数据文件, 以后还原的时候,直接将备份的内容放进去即可.
数据表备份有前提条件: 根据不同的存储引擎有不同的区别.
存储引擎: mysql进行数据存储的方式: 主要是两种: innodb和myisam(都免费)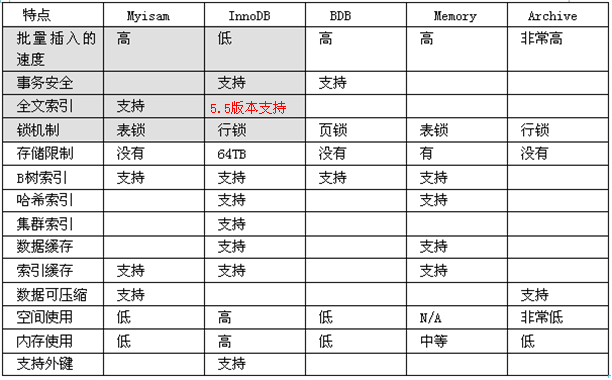
对比myisam和innodb: 数据存储方式
InnoDB表组成部分:
共享表空间文件(data目录下的ibdata1):将所有的表的数据和索引保存在ibdata1中,
优点:表空间文件大小不受表大小的限制,如一个表可以分布在不同的文件上
缺点:拷贝时必须拷贝整个大文件,而且删除表后容易产生碎片。对于统计分析,日志系统这类应用最不适合用共享表空间。
独占表空间文件(ibd):若将innodb_file_per_table设置为on,则系统将为每一个表单独的生成一个table_name.ibd的文件,在每个表对应的.idb文件内只是存放了数据、索引和插入缓冲,而撤销(undo)信息,系统事务信息,二次写缓冲等还是存放在了原来的共享表空间内。
优点:可以实现单表在不同的数据库中移动。
空间可以回收,不管怎么删除,表空间的碎片不会太严重的影响性能
在服务器资源有限,单表数据不是特别多的情况下,独立表空间明显比共享方式效率更高
缺点:单表体积可能过大,如超过100个G。
表结构文件(.frm):用来保存每个数据表的元数据(meta)信息,包括表结构的定义等
日志文件(redo文件等):ib_logfile1、ib_logfile2
innodb 的表,直接复制文件是无法使用的,会提示 table doesn’t exists ,在复制的时候,应将data目录下的 ibdata1 文件一并复制过去,并且删除 ib_logfile0 、ib_logfile1 文件。
但是出现的问题是,本地的一些其它数据库打不开了,select会报错。
最好的办法就是停止本地的mysql服务器,将data目录改名,然后将服务器上备份的data目录整个都复制过来。或者只复制需要的某一个数据库,但是也得将data目录下的ibdata1复制过来。并且删除本地的ib_logfile0 、ib_logfile1 文件。然后打开需要操作的数据库,导出sql文件。处理完成之后本地将原先的data目录改不了就行。
Myisam: 表,数据和索引全部单独分开存储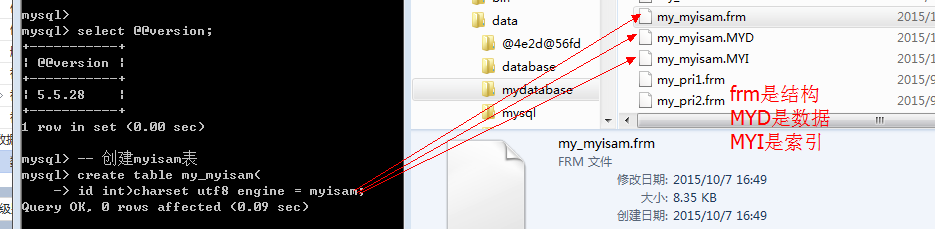
这种文件备份通常适用于myisam存储引擎: 直接复制三个文件即可, 然后直接放到对应的数据库下即可以使用.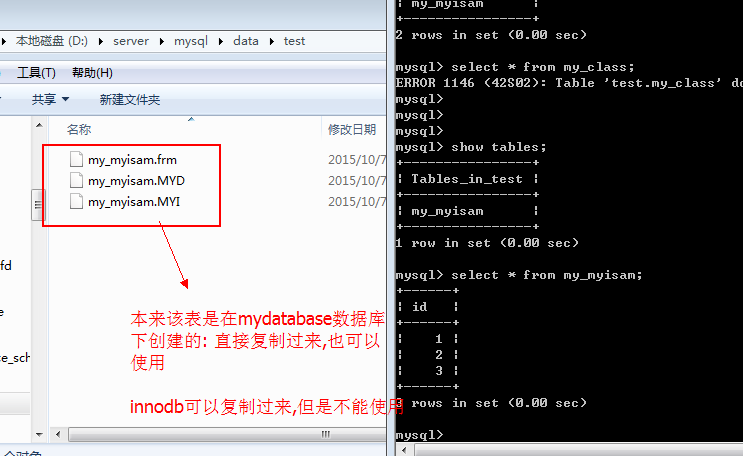
单表数据备份
每次只能备份一张表; 只能备份数据(表结构不能备份)
通常的使用: 将表中的数据进行导出到文件
备份: 从表中选出一部分数据保存到外部的文件中(outfile)
Select /字段列表 into outfile 文件所在路径 from 数据源; — 前提: 外部文件不存在
高级备份: 自己制定字段和行的处理方式
Select /字段列表 into outfile 文件所在路径 fields 字段处理 lines 行处理 from 数据源;
Fields: 字段处理
Enclosed by: 字段使用什么内容包裹, 默认是’’,空字符串
Terminated by: 字段以什么结束, 默认是”\t”, tab键
Escaped by: 特殊符号用什么方式处理,默认是’\’, 使用反斜杠转义
Lines: 行处理
Starting by: 每行以什么开始, 默认是’’,空字符串
Terminated by: 每行以什么结束,默认是”\r\n”,换行符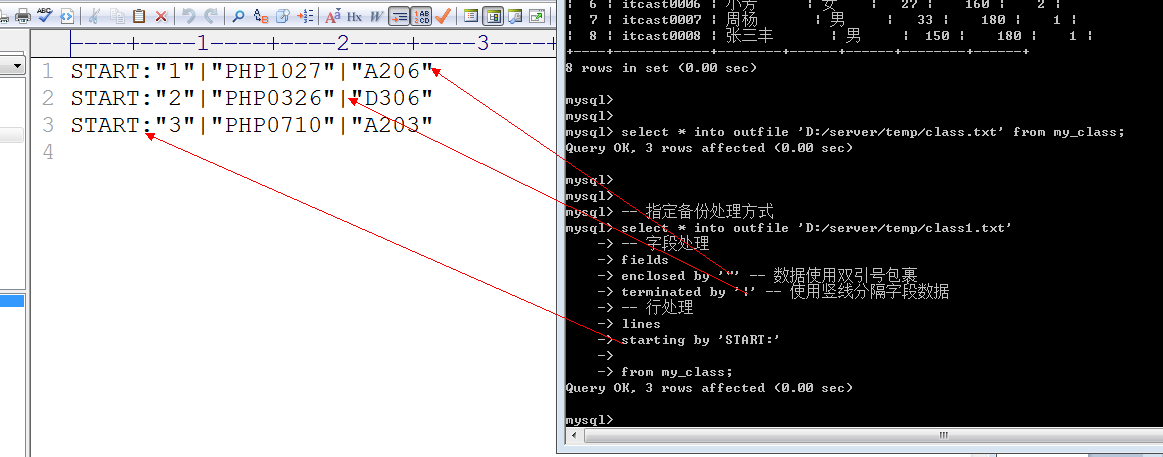
数据还原: 将一个在外部保存的数据重新恢复到表中(如果表结构不存在,那么sorry)
Load data infile 文件所在路径 into table 表名[(字段列表)] fields字段处理 lines 行处理; — 怎么备份的怎么还原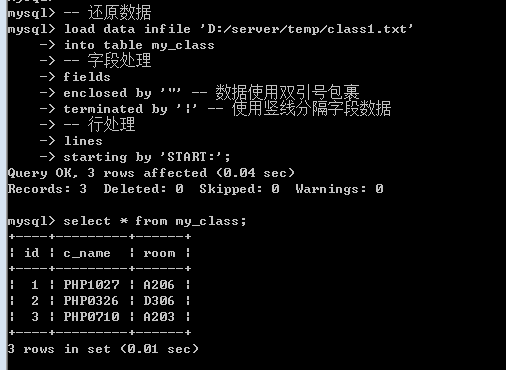
SQL备份
备份的是SQL语句: 系统会对表结构以及数据进行处理,变成对应的SQL语句, 然后进行备份: 还原的时候只要执行SQL指令即可.(主要就是针对表结构)
备份: mysql没有提供备份指令: 需要利用mysql提供的软件: mysqldump.exe
Mysqldump.exe也是一种客户端,需要操作服务器: 必须连接认证,连接前要退出当前mysql命令行模式。因为mysqldump.exe也是一个客户端。不能再mysql客户端中使用另一个客户端。
Mysqldump/mysqldump.exe -hPup 数据库名字 [数据表名字1[ 数据表名字2…]] > 外部文件目录(建议使用.sql)
单表备份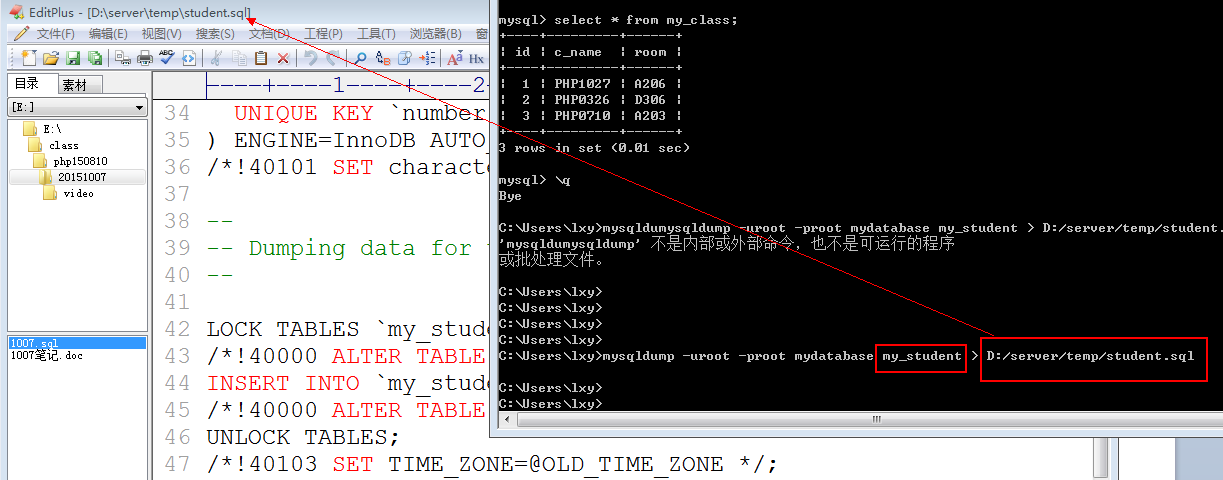
插入数据的时候进行锁表的写操作
整库备份
Mysqldump/mysqldump.exe -hPup 数据库名字 > 外部文件目录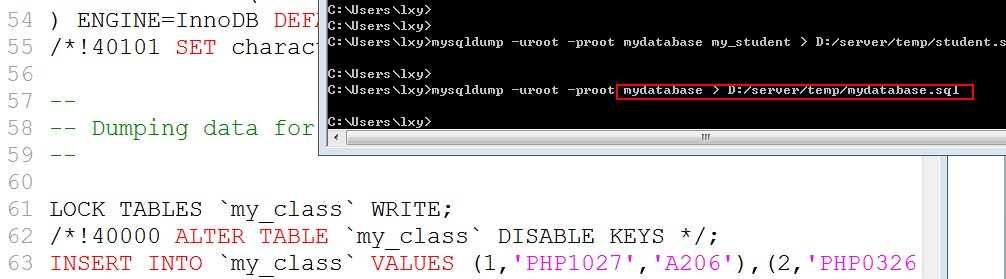
SQL还原数据: 两种方式还原
方案1: 使用mysql.exe客户端还原
Mysql.exe/mysql -hPup 数据库名字 < 备份文件目录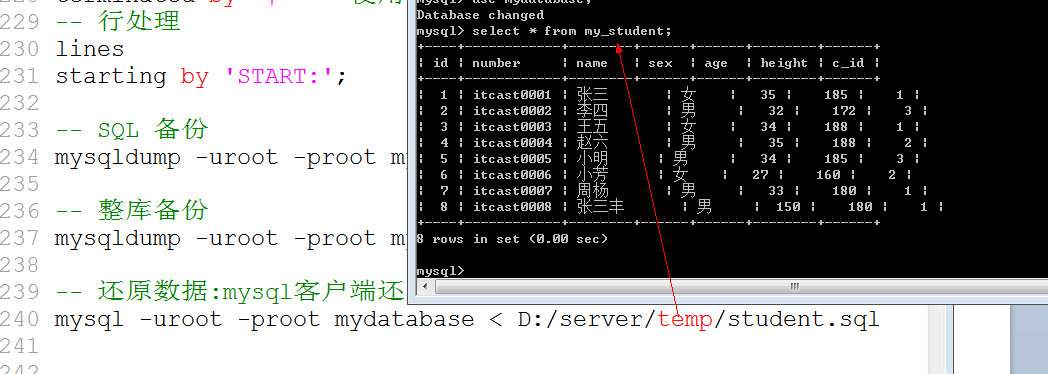
方案2: 使用SQL指令还原
Source 备份文件所在路径;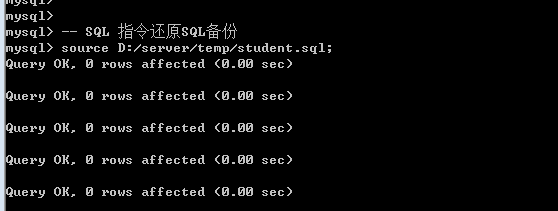
SQL备份优缺点
1. 优点: 可以备份结构,数据
2. 缺点: 会浪费空间(额外的增加SQL指令),大项目的数据库不适用sql备份。时间太长
增量备份
适合大项目的备份
不是针对数据或者SQL指令进行备份: 是针对mysql服务器的日志文件进行备份
增量备份: 指定时间段开始进行备份., 备份数据不会重复, 而且所有的操作都会备份(大项目都用增量备份)

若有收获,就点个赞吧
0 人点赞
