分区
http://blog.csdn.net/qiubt__123/article/details/53868874
http://blog.51yip.com/mysql/1013.html
什么是分区:
在物理上将一张表对应的三个文件,分割成许多个小块
1 通俗点说:分区就是将表格里面的数据横向切分,同一个区的数据会放在一起,然后在查询的时候只查某个或某些区的数据。但是分区对于用户是透明的,分区还只是一张表,分表是拆分成了几张表,
分区对PHP来说是无感知的,该怎么查询还是怎么查,代码上不需要改变
2 mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面,myisam引擎的一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
分区类型:
range分区【对连续值进行分区,如对id进行分区,对日期分区,】 partition BY RANGE (id)
list分区 【类似于range,但是LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择,如:(1,3,5) 】 PARTITION BY LIST (provinceid)
hash分区
hash简介:翻译成散列或者哈希。简单的说就是可以把任意长度的字符串经过运算生成固定长度的字符串,并且这个产生的字符串代表着原来字符串里的所有字符。而MD5可以说是目前应用最广泛的Hash算法
hash分区原理:hash分区需设定分区数量n,然后MySQL会对分区的列进行散列函数,来确定数据应该放在n个分区中的哪一个分区。确保数据在n个分区中尽可能的平均分布】
hash分区支持两种散列函数(分区方式):取模算法(默认hash分区方式:partition BY HASH(id))和线性的2的幂的运算法则( 线性hash分区:partition BY linear HASH(id) )
线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量(1000吉)数据的表。
缺点:与使用常规HASH分区得到的数据分布相比,各个分区间数据的分布不大可能均衡。
key分区
类似于按 HASH 分区,区别在于 KEY 分区只支持计算一列或多列,且 MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值
n key分区和hash分区的区别:
n 1)hash分区允许用户自定义表达式,而key分区不允许使用用户自定义的表达式。
n 2)hash分区只支持整数分区,key分区支持除了blob或text类型之外的其他数据类型分区。
n 3)与hash分区不同,创建key分区表的时候,可以不指定分区键,默认会选择使用主键/唯一键作为分区键,没有主键/唯一键,必须指定分区键。
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
**子分区:子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。这 也被称为复合分区(_composite partitioning)。**
分区原理
创建表时使用partition by子句定义每个分区存放的数据,执行查询时,优化器会根据分区定义过滤那些没有我们需要数据的分区。这样查询只需要查询所需数据在的分区即可。【可以按时间,年龄等分区】,如下表:<br />按照年龄分区,把不同年龄的用户分别分到四个区,查询的时候可以定位该年龄段<br />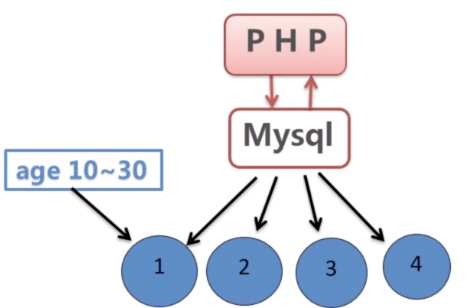<br /> <br /> <br />
分区语句:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) ( #RANGE 分区类型
PARTITION p0 VALUES LESS THAN (6), #1-5 LESS THAN不到的意思
PARTITION p1 VALUES LESS THAN (11), #6-10
PARTITION p2 VALUES LESS THAN (16), #11-15
PARTITION p3 VALUES LESS THAN MAXVALUE #其它值在这个分区。
);
查询分区语句:
select * from employees partition(p0);
删除分区:
alter table employees drop partition p3;
对现有表分区:
ALTER TABLE employees PARTITION BY RANGE (store_id)
(
PARTITION p0 VALUES LESS THAN (6), 1-5 ,
PARTITION p1 VALUES LESS THAN (11), 6-10
PARTITION p2 VALUES LESS THAN (16), 11-15
PARTITION p3 VALUES LESS THAN MAXVALUE
);
分区策略基于两个非常重要的假设:
l 查询都能够过滤掉很多额外的分区,
l 分区本身不会带来很多的额外的代价。
分区适用场景:
l 表非常大,无法全部存内存,
l 把热点数据和历史数据分开:只在表的最后有热点数据(活跃用户的信息或常查询的信息),其他都是历史数据(不怎么查询的信息)
分区优点:
l 分区可以分在多个磁盘,存储更大一点。
l 根据查找条件,也就是where后面的条件,只查找相应的分区不用全部查找了。
l 进行大数据搜索时可以进行并行处理。
l 跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
l 分区表的数据某些情况更容易维护。如:想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化,检查,修复等操作。
6.可以备份和恢复独立的分区。
分区表的限制(缺点):
l 一个表最多只能有1024个分区。但分区不是越多越好
选择分区的成本可能很高。对于范围分区来说,回答“这一行属于哪个分区”,“这些符合查询条件的行在哪些分区”这样问题的成本可能会非常高,因为服务器需要扫描所有的分区定义的列表来找到正确的答案。对于大多数系统来说,100个左右的分区是没有问题的。
l 分区字段如果有主键和唯一索引。那么主键列和唯一索引列都必须包含进来。
l 分区表中不能使用外键索引
l NULL 值会使分区过滤无效
l 需要对现有表的结构进行修改。改表的机构。需要加partition by
l 所有分区都必须使用相同的存储引擎。
l 分区函数中可以使用的函数和表达式会有一些限制。
l 某些存储引擎不支持分区。(如:MERGE,CSV,FEDERATED联合存储引擎。)
l 对于myisam的分区表。不能使用load index into cache(把数据缓存到内存中)
l 对于MyISAM表,使用分区表时需要打开更多的文件描述符
l 维护分区的成本可能很高。新增或者删除分区时,可能会很快。但是重组分区或者类似ALTER语句的操作:这类操作需要复制数据。重组分区的原理与ALTER类似,先创建一个临时的分区,然后将数据复制到其中,最后删除原分区。
分库分表的原理:
为什么要分表:
当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,可能会卡死。分表的目的就在于此,减小数据库的负担,缩短查询时间。
由于MySQL的锁机制,一条数据在被修改,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。如果数据太多,一次执行的时间太长,等待的时间就越长,这也是我们为什么要分表的原因。
工作原理
通过一些hash算法或者工具,将一张数据表垂直或者水平进行物理切分。
使用场景:
1.单表数据达到百万。<br /> 2.解决表锁的问题。<br />
垂直拆分:
冷热数据分离:把主键和一些常用列放在一个表。然后把主键和另外的不常用的列放到另一张表中。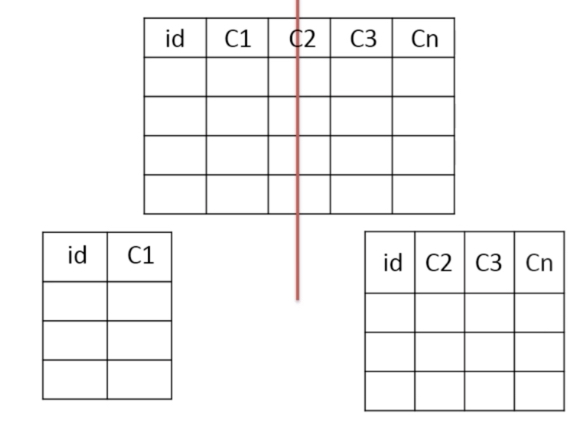
使用场景:
如果一个表中某些列常用,而另外一些列不常用。【常用的列拆分出来】
优点:
可以使得行数据变小,一个数据块 (Block) 就能存放更多的数据,在查询时就会减少 I/O 次数 (每次查询时读取的 Block 就少)
缺点:
主键出现冗余,需要管理冗余列。删除数据需要将多表的数据一起删除
任何查询都要join关联。(增加 CPU 开销)可以通过在业务服务器上进行 join 来减少数据库压力
依然存在单表数据量过大的问题(需要水平拆分)
事务处理复杂
有些分表的策略是基于应用层的逻辑算法。一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差。
对于应用层来说,逻辑算法上会增加开发成本。
水平拆分:
水平拆分,是通过某种策略将数据分片来存储,库内分表和分库两部分,每片数据会分散到不同的 MySQL 表或库,达到分布式的效果,能够支持非常大的数据量。前面的表分区本质上也是一种特殊的库内分表
库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上,因此对于减轻 MySQL 服务器的压力来说,并没有太大的作用,大家还是竞争同一个物理机上的 IO、CPU、网络,这个就要通过分库来解决
实际情况中往往会是垂直拆分和水平拆分的结合,如垂直拆分成两张表之后,总行数还是没有变化,还可以通过水平拆分,再次拆分。
如下面图:将一张表的数据分成几部分。相当于一张表变为几张小表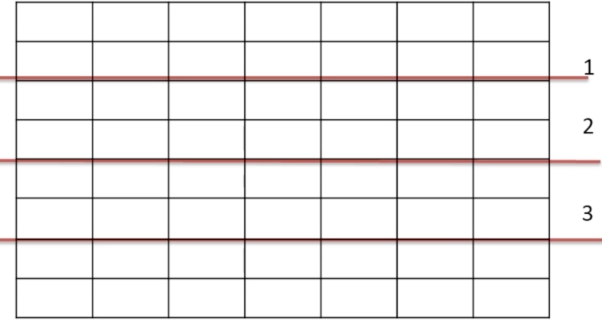
使用场景:
1.表中的数据本身就有独立性。例如表中分表记录各个地区的数据或者不同时期的数据。特别是有些数据常用。有些不常用。
2.需要把数据存放到多个介质上。【比如将经常查询的后面部分的数据放到缓存里面】
优点:
表很大,分割后可以降低查询时需要读的数据和索引的页数。同时也降低了索引的层数,提高查询速度。
不存在单库大数据和高并发的性能瓶颈
应用端改造较少
提高了系统的稳定性和负载能力
缺点:
分片事务一致性难以解决
跨节点 Join 性能差,逻辑复杂
数据多次扩展难度跟维护量极大
给应用增加复杂度。通常查询时需要多个表名。查询分布在多个表中的数据需union操作。
如果要查询id=5的在第一部分的表里,id=260的在第三部分的表里,我们需要根据分表的方法,如规定:id小于100的在第一部分的表里,大于100小于200的在第二部分的表里,200和300之间的在第三部分的表里。所以需要从第一部分表里查找到id=5的,在第三部分表里找到id=260,然后把两个查询语句使用union进行连接
1、按时间分
典型应用:订单、交易记录,新闻类、qq状态、朋友圈动态等关注实时或最近的,可以用时间划分,比如当月一张表,上个月一张表。
2、按区间分
通常每张表都会有个自增id,可以利用自增id分,比如
user1表 是1~50
user2表 是51~100 //insert 操作完成后,判断id值,超过50w时,创建新表
3、hash分表
对每一条插入的数据进行取模, 对于单记录查询还ok,如果查询相邻几行数据时,就悲剧了,有可能分到不同的表里了。
function get_hash_table($table,$userid) {
//crc32计算字符串的 32 位 CRC,返回整数值
$str = crc32($userid);
if($str<0){
$hash = "0".substr(abs($str), 0, 1);
}else{
$hash = substr($str, 0, 2);
}
return $table."_".$hash;
}
echo get_hash_table('message','user18991'); //结果为message_10
echo '<br>';
echo get_hash_table('message','user34523'); //结果为message_13
原则:
能不分就不分(数据量少不需要分)
分片数量尽量少,分片尽量均匀分布在多个数据结点上,因为一个查询 SQL 跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量
分片规则需要慎重选择做好提前规划,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性 Hash 分片,这几种分片都有利于扩容
尽量不要在一个事务中的 SQL 跨越多个分片,分布式事务一直是个不好处理的问题
查询条件尽量优化,尽量避免 Select * 的方式,大量数据结果集下,会消耗大量带宽和 CPU 资源,查询尽量避免返回大量结果集,并且尽量为频繁使用的查询语句建立索引。
通过数据冗余和表分区降低跨库 Join 的可能
如果某个表的数据有明显的时间特征,比如订单、交易记录等,则他们通常比较合适用时间范围分片,因为具有时效性的数据,我们往往关注其近期的数据,查询条件中往往带有时间字段进行过滤,比较好的方案是,当前活跃的数据,采用跨度比较短的时间段进行分片,而历史性的数据,则采用比较长的跨度存储。
总体上来说,分片的选择是取决于最频繁的查询 SQL 的条件,因为不带任何 Where 语句的查询 SQL,会遍历所有的分片,性能相对最差,因此这种 SQL 越多,对系统的影响越大,所以我们要尽量避免这种 SQL 的产生。

若有收获,就点个赞吧
0 人点赞
