一、otter介绍
1.1 otter是什么
基于数据库增量日志解析(binlog),准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统。分为两个部分:manger和node。能够实现双A,即两边数据库均可写,并且保证数据一致性的系统。
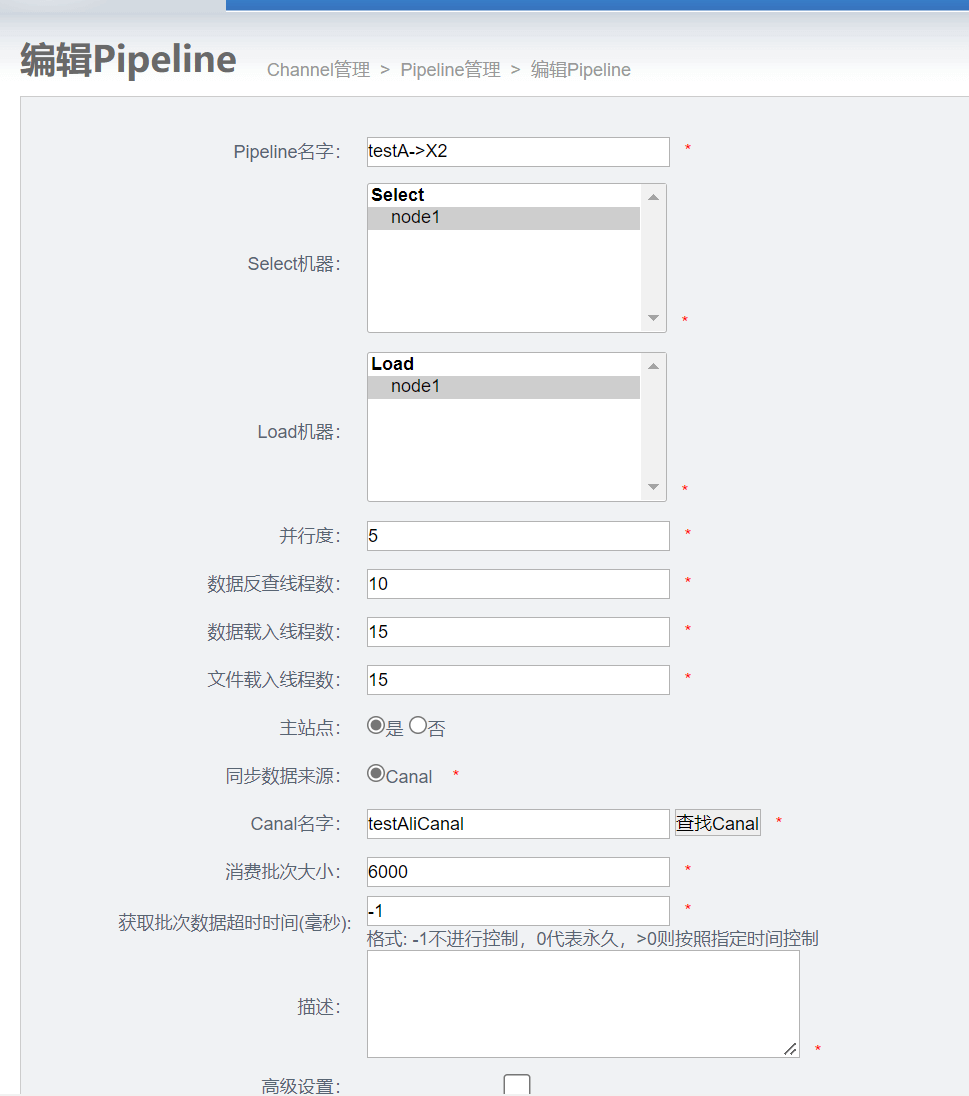
1.2 整体架构
基于一个otter的一个插件 canal 数据采集工具 (嵌入node节点)
manager(web管理)+node(工作节点)+zookeeper 多点之间协同工作的。
名词解释
- Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
- Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
- DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
- DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
- DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
- ColumnPair : 定义字段映射关系
- ColumnGroup : 定义字段映射组
-
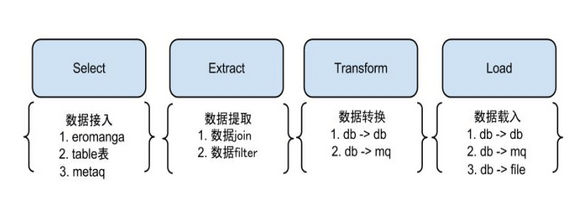
S/E/T/L stage阶段模型
1.3 otter 具体能做什么
异构库同步 mysql -> mysql/oracle
- 单机房同步
- 异地机房同步
- 双向同步
- 重点: 解决双主问题、数据一致性问题
- 文件同步
二、otter安装
下载地址 目前使用版本4.2.18 quick-start
2.1 环境准备
mysql 两个机房同步都需要安装
- 修改 my.cnf 开启biglog
- 开启 设置级别为row 记录每次操作后每行记录的变化
- 设置server-id 每个数据库不能设置一样
- 设置要开启的db 没有就是全部开启
- 修改完成后进入mysql 刷新配置 flush privileges;
[mysqld]log-bin=mysql-binbinlog_format=rowserver-id=1binlog-do-db=mycan
zookeeper 可以是单节点也可以是集群,建议每个机房都搭建一个zk集群然后组成一个物理大集群
- 多线程传输技术 aria2
2.2 安装manager
由于manager是基于数据库进行信息存储,为了防止节点异常,不和node节点装在一台机器上,由于是基于mysql可以装两台manager。
2.2.1 修改配置文件
## otter manager domain nameotter.domainName = 127.0.0.1 (正确访问ip,管理界面使用)## otter manager http portotter.port = 8080 (正确访问端口,管理界面使用)## otter manager database config (修改为正确数据库信息 准备脚本的位置)otter.database.driver.class.name = com.mysql.jdbc.Driverotter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otterotter.database.driver.username = roototter.database.driver.password = hello## default zookeeper address (修改到最近一个能访问的zk地址)otter.zookeeper.cluster.default = 127.0.0.1:2181## default zookeeper sesstion timeout = 60sotter.zookeeper.sessionTimeout = 60000
2.2.2 启动
bin目录下对应启动文件 win、linux均可以启动
第一次进入界面 需要登录才能登陆 初始用户名密码为 admin/admin
2.3 安装node
2.3.1 需要现在manager上先配置好zk节点,再配置一个node节点
2.3.2 添加node 节点 生成一个node节点id
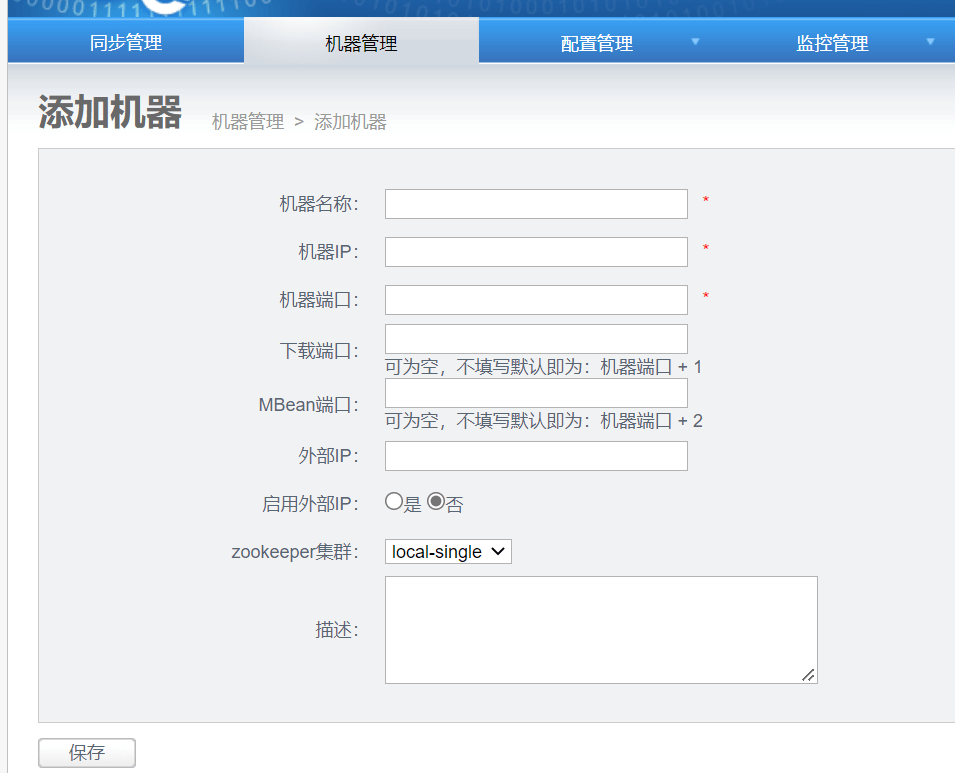
2.3.3 创建nid文件
在conf 文件夹下创建一个nid文件 内容为node节点的序号
linux下创建
echo 1 >~/node/conf/nid
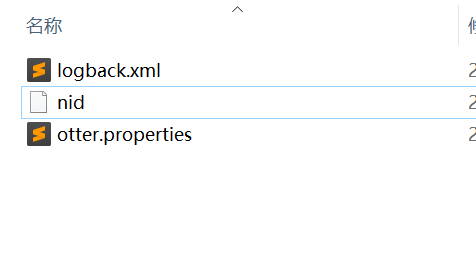
2.3.3 修改otter.properties的配置文件
## otter arbitrate & node connect manager config 修改为正确的manager服务地址otter.manager.address = 127.0.0.1:1099
2.3.4 启动
三、otter使用
3.1 配置数据源
来去两个数据源都需要配置
编码选择mysql节点中 /etc/my.cof中的数据编码
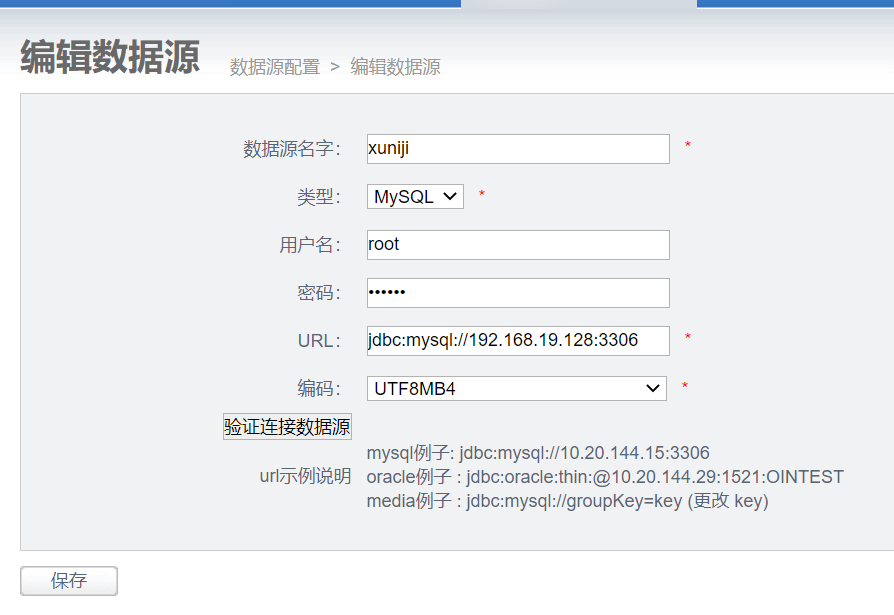
3.2 配置数据表
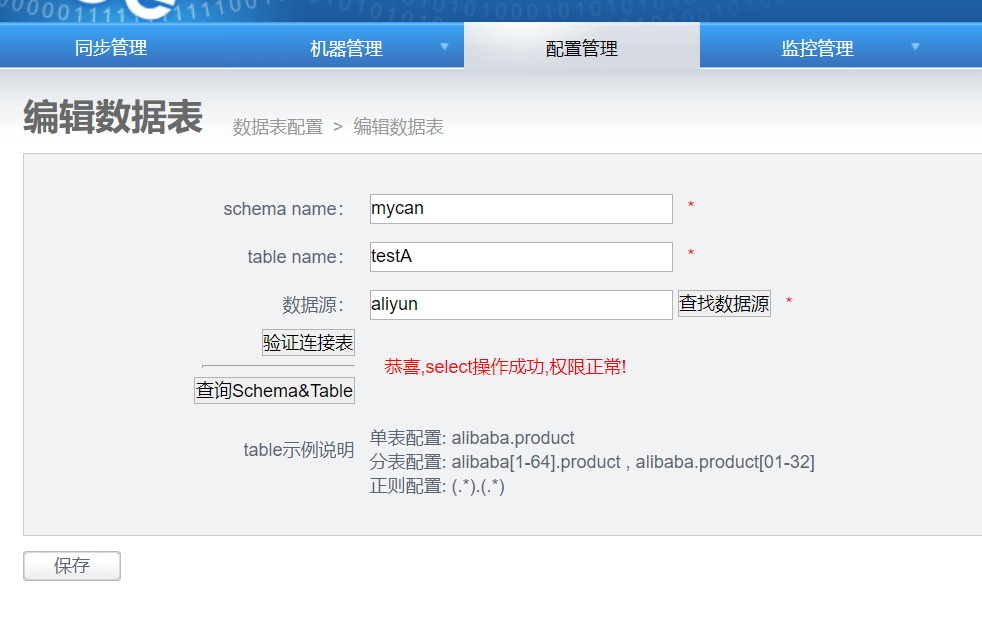
3.3 配置canal
注意:一个pipeline对应一个canal 多个pipeline应该再次创建
可以自定义binlog位置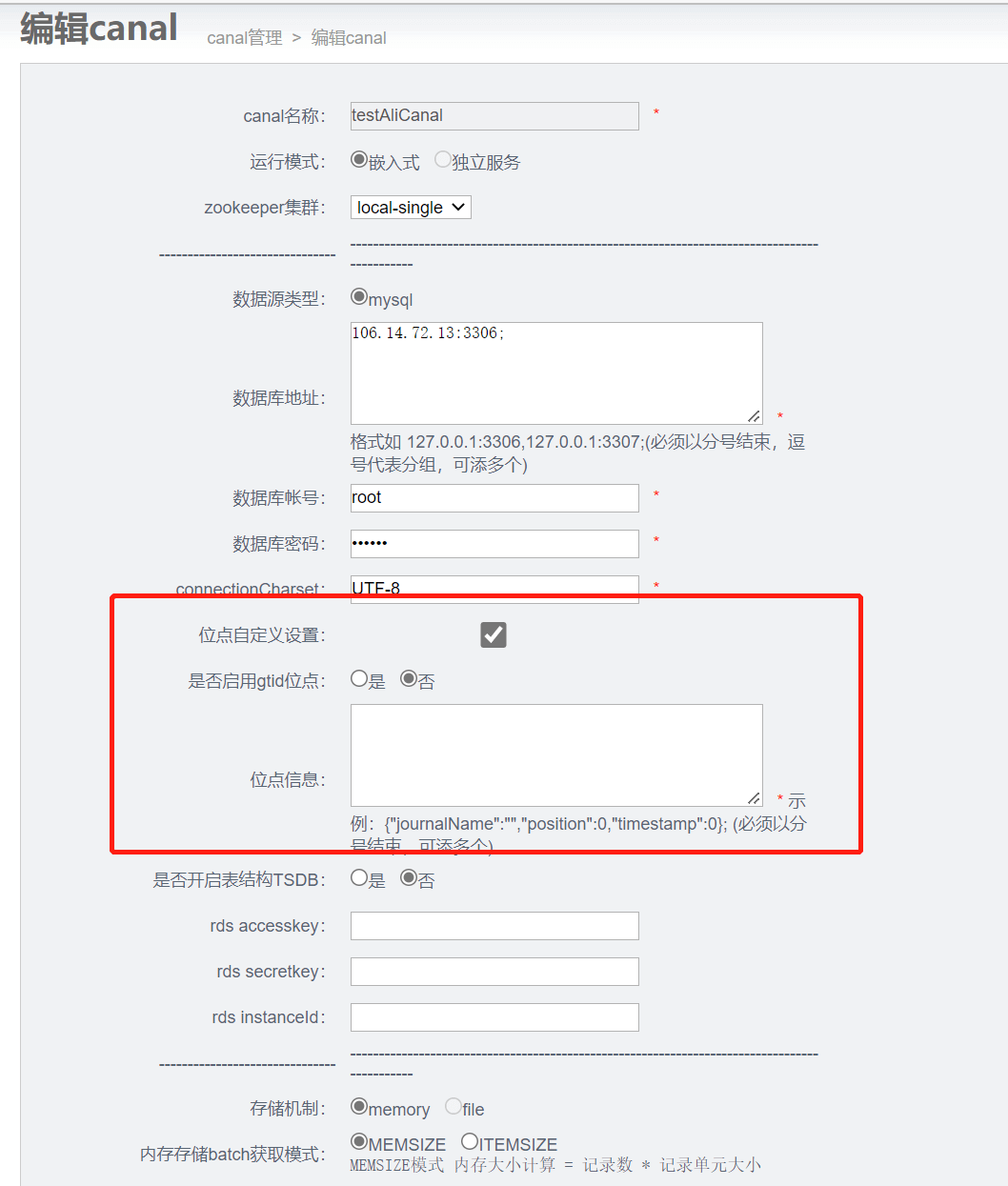
3.4 配置单向同步
3.4.1 添加一个channel
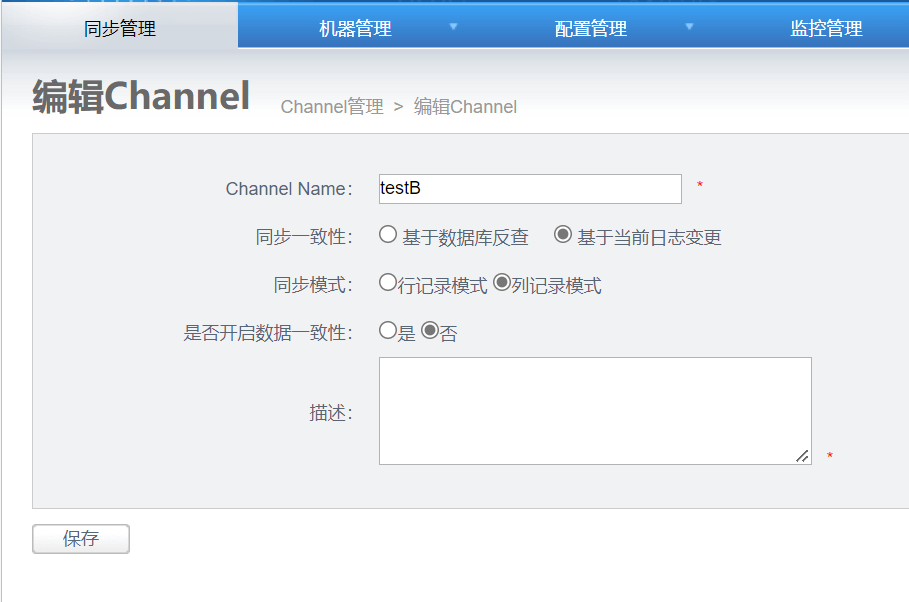
3.4.2 添加一个pipeline
3.4.3 添加映射关系
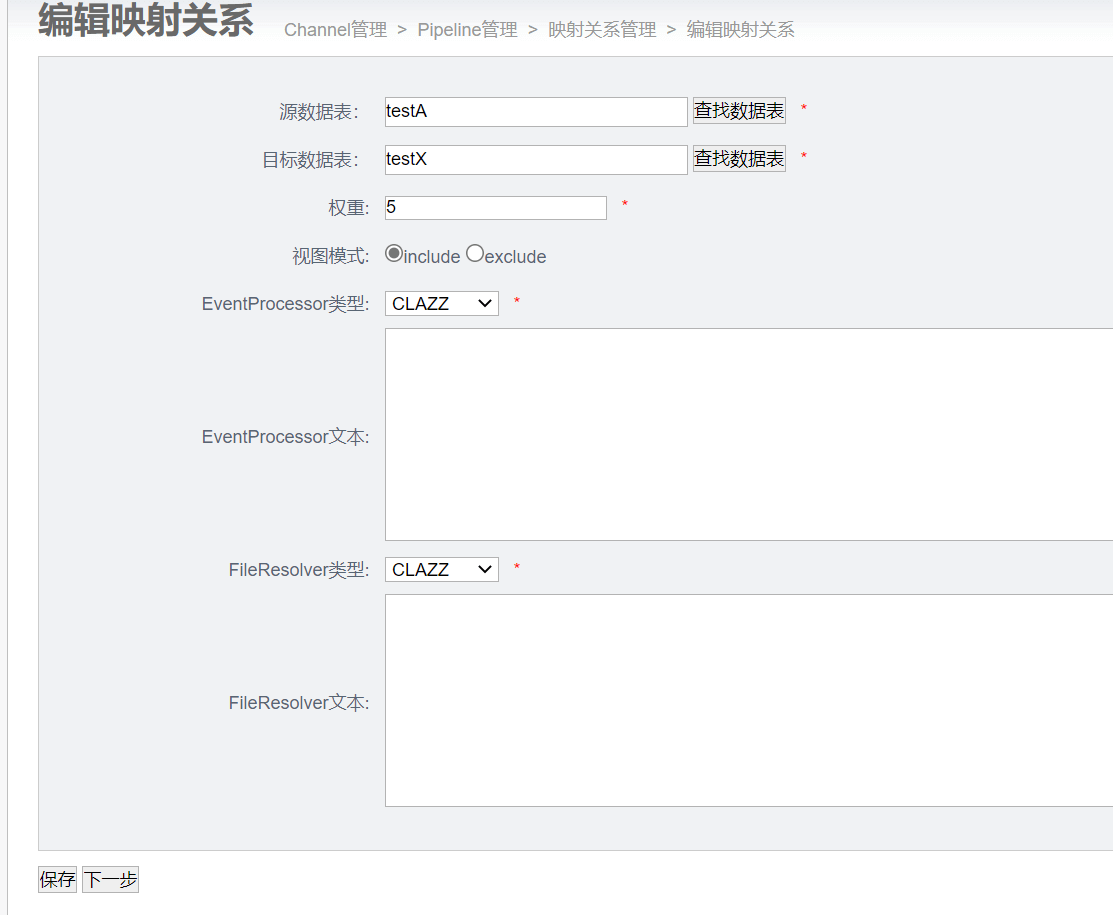
3.4.4 验证
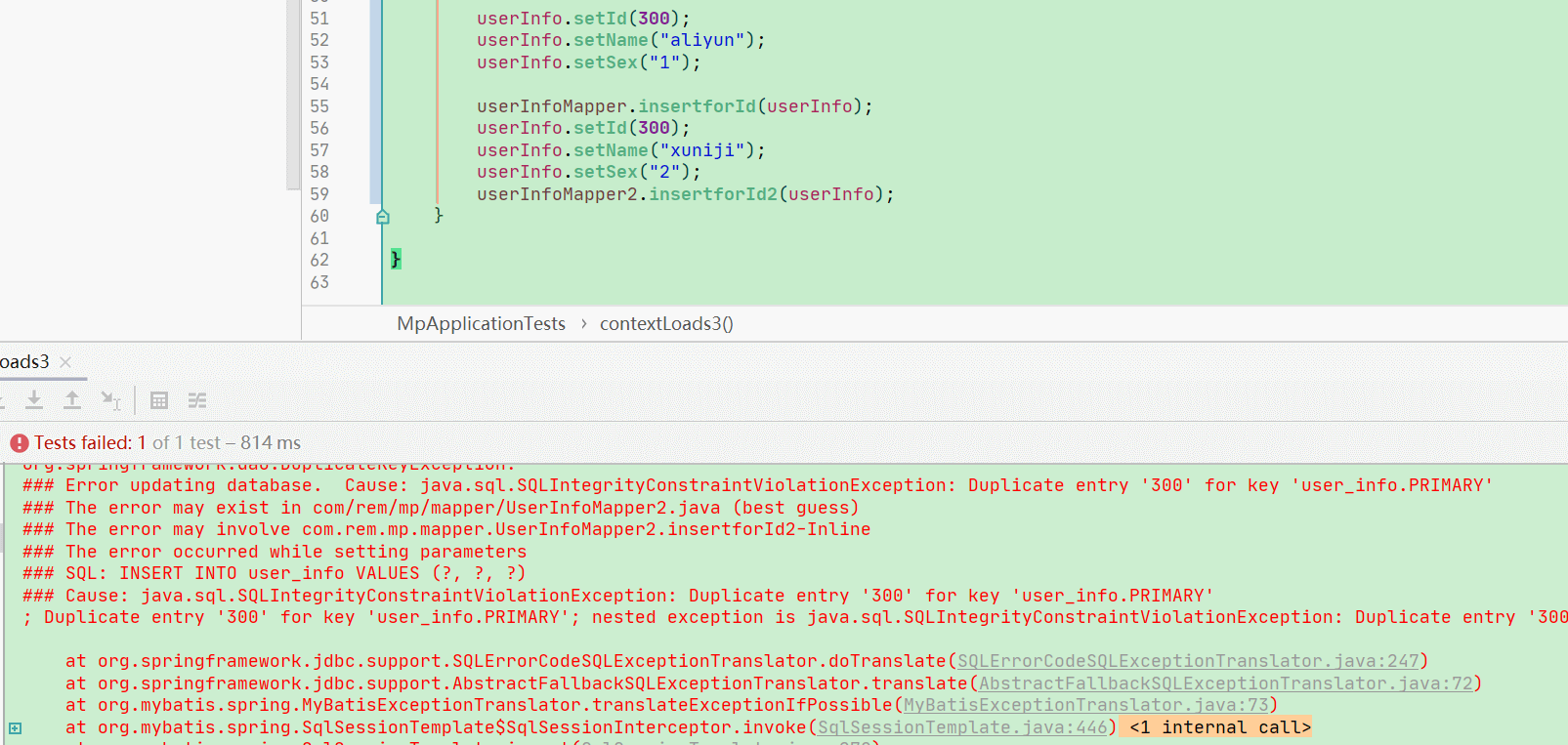
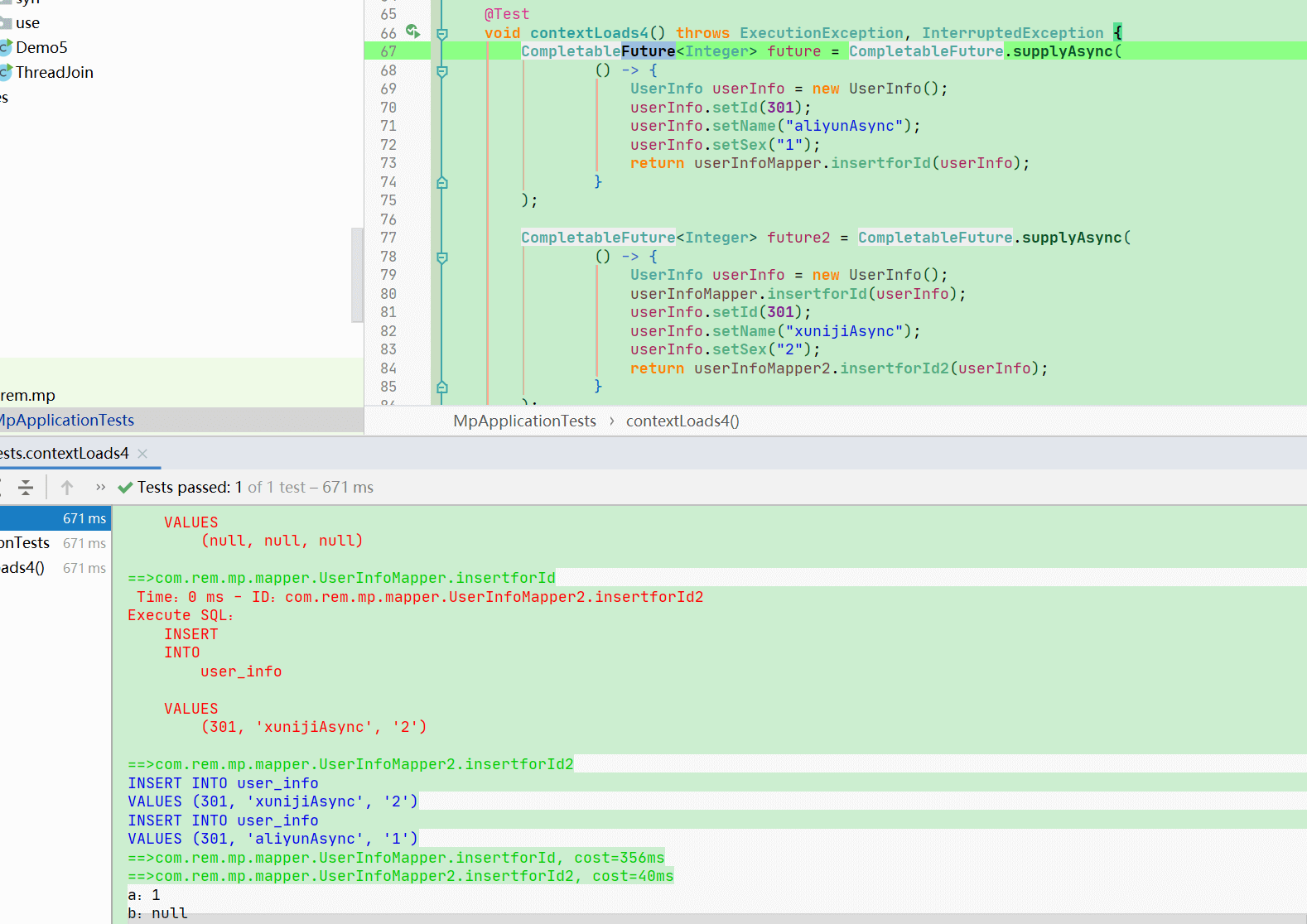
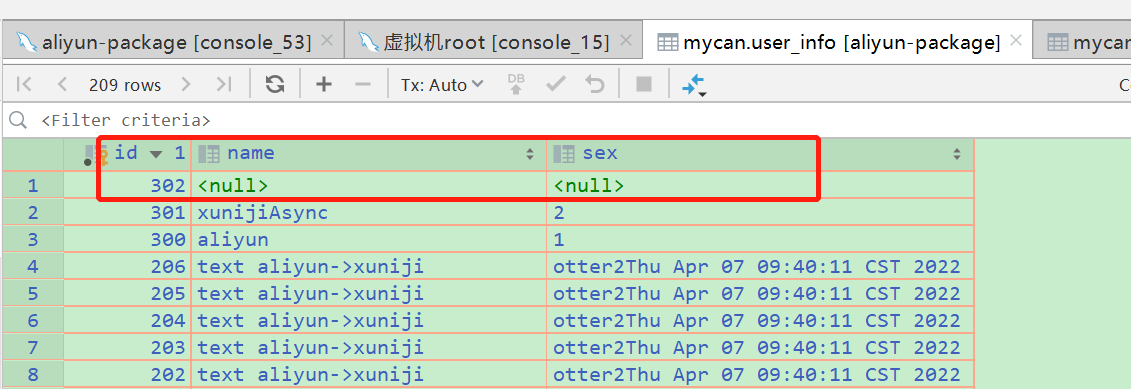
在源表上插入数据 在目标表中同样会出现一条一样的数据
3.5 配置双A同步
3.5.1 双A配置需要在文档中捞取sql 在源端和目标端都需要执行
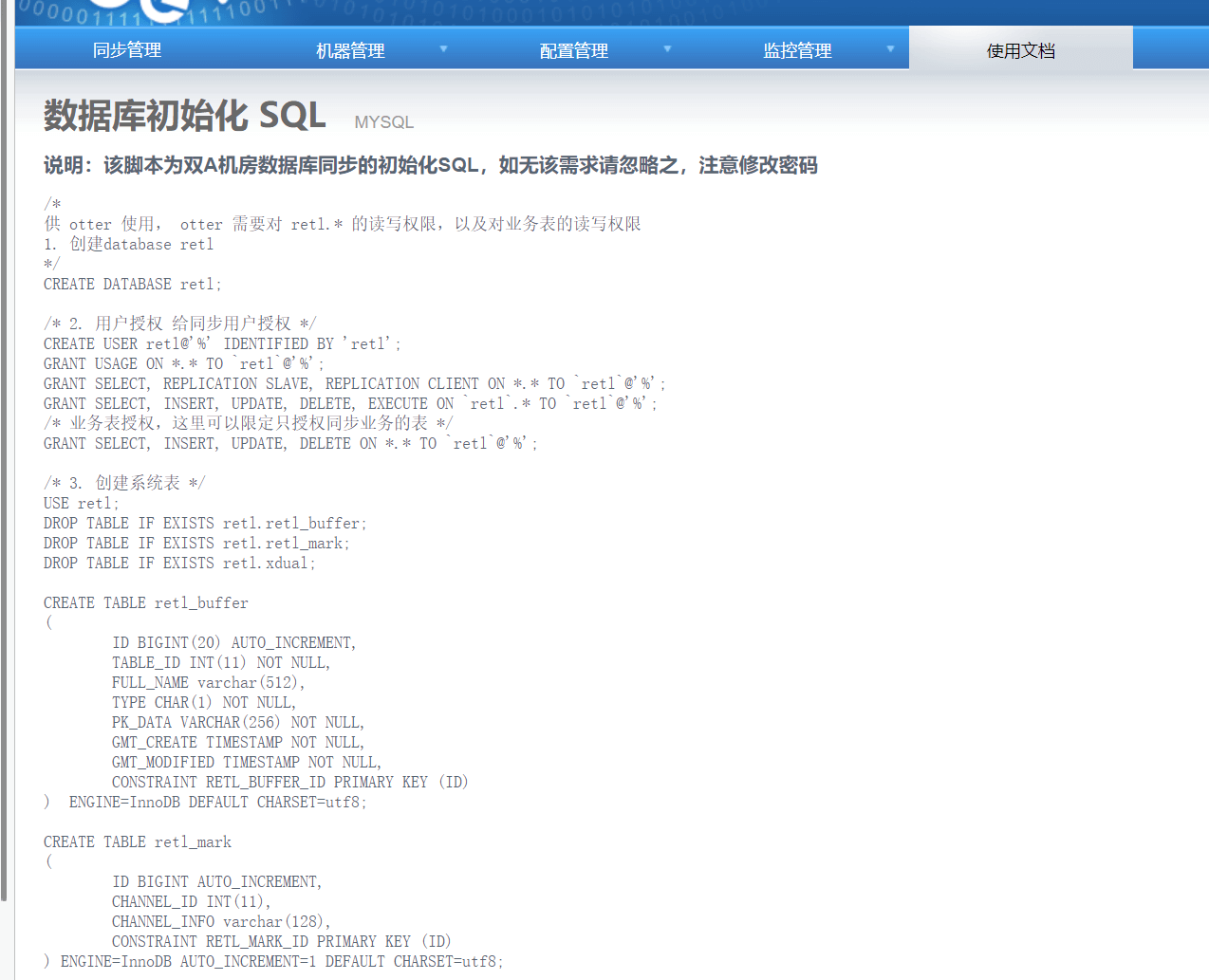
3.5.2 添加一个channel
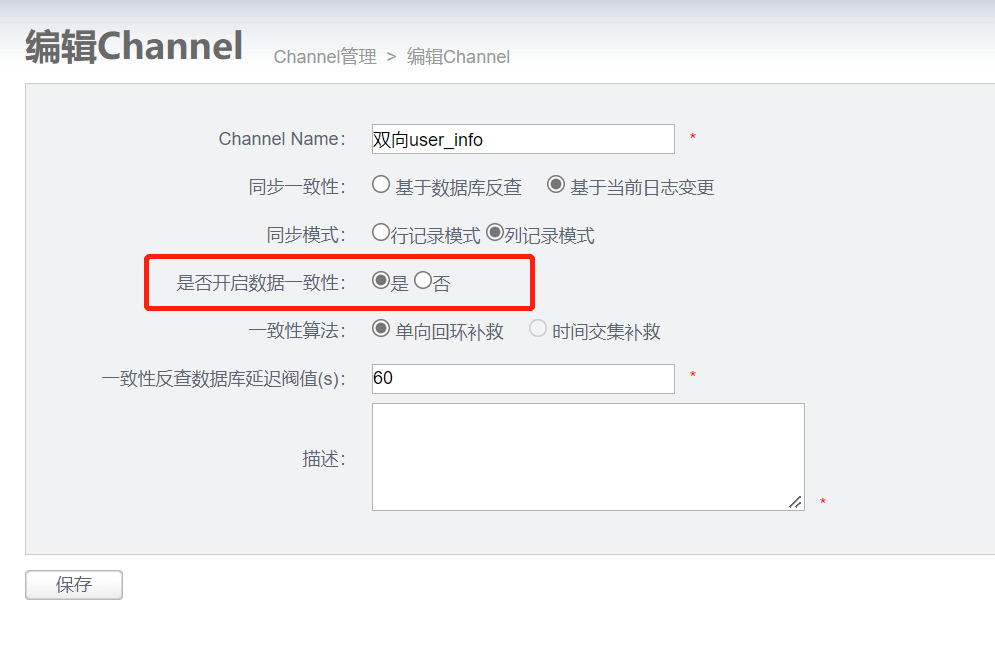
必须开启数据一致性
a. 同步一致性
- 基于数据库反查 (简单点说,就是强制反查数据库,从binlog中拿到pk,直接反查对应数据库记录进行同步,回退到几天前binlog进行消费时避免同步老版本的数据时可采用)
- 基于当前日志变更 (基于binlog/redolog解析出来的字段变更值进行同步,不做数据库反查,推荐使用)
b. 同步模式
- 行模式 (兼容otter3的处理方案,改变记录中的任何一个字段,触发整行记录的数据同步,在目标库执行merge sql)
- 列模式 (基于log中的具体变更字段,按需同步)
c. 特殊组合: (同样支持)
- 基于数据库反查+列模式
- 基于当前日志变更+行模式
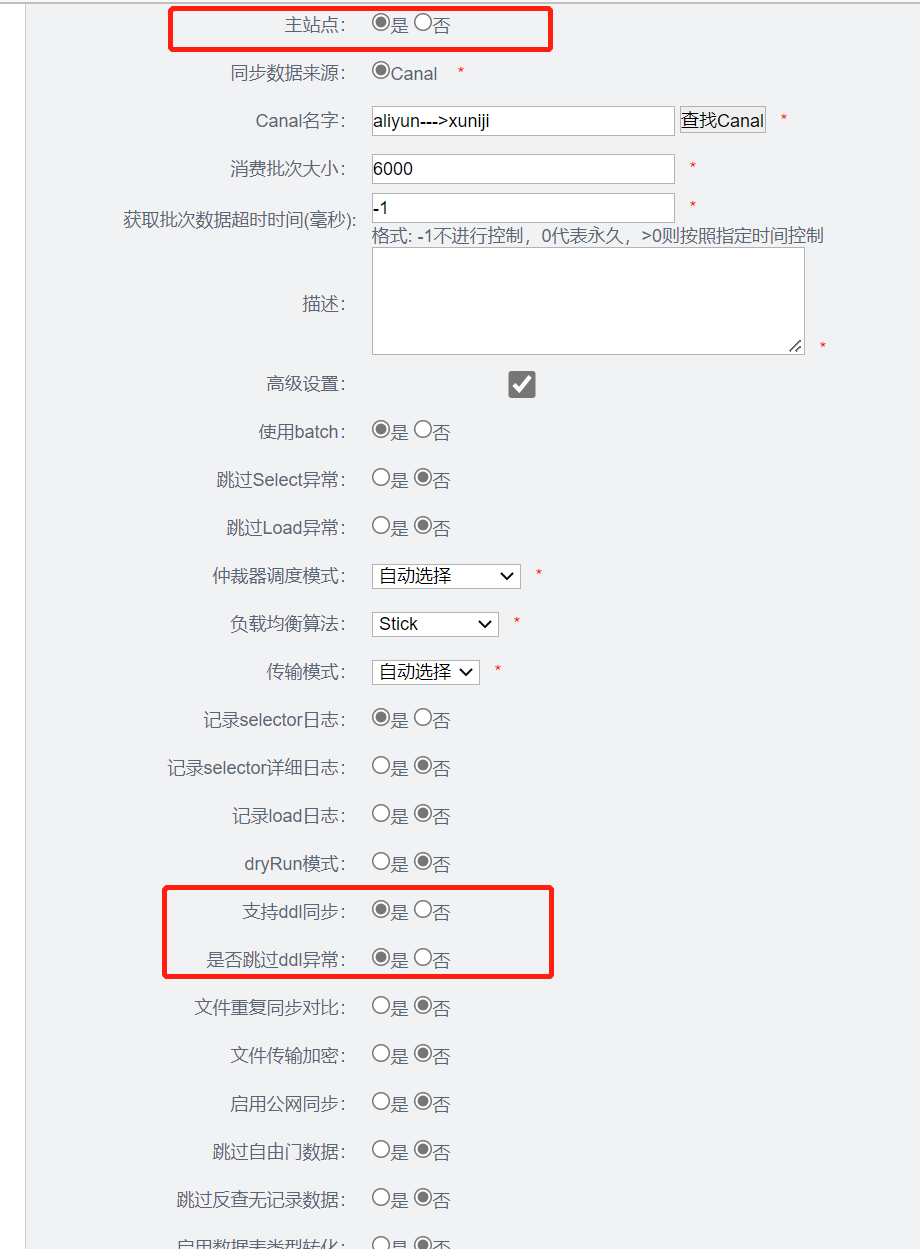
3.5.3 添加两个pipeline
双A 需要正向、逆向pipeline 都要配置,并且需要注意
- _只能有一个_pipeline设置为主站点
- 高级设置中只能有一个支持ddl同步
- 两个都必须设置跳过ddl异常
3.5.4 添加映射关系
3.5.5 验证
3.6 配置监控
前提在manager中properties里配置邮件发送服务器和发送人
Pipeline管理下添加监控配置 key 填写 联系人前面的otterteam 邮件联系人配置是k-v配置
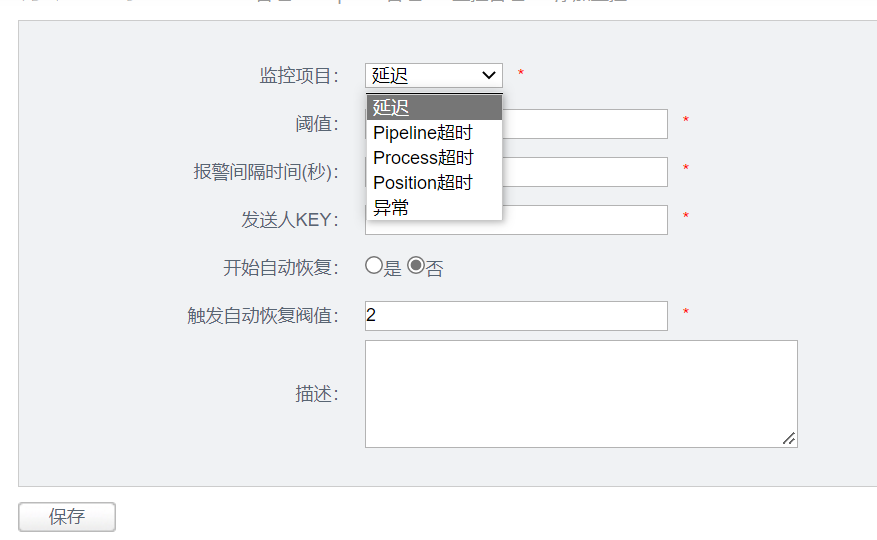
监控项目
- 同步延迟,position超时(位点超过多少时间没有更新) , 一般业务方关心这些即可
- 异常 (同步运行过程中出现的异常,比如oracle DBA关心oracle系统ORA-的异常信息,mysql DBA关心mysql数据库相关异常)
- process超时(一个批次数据执行超过多少时间),同步时间超时(数据超过多少时间没有同步成功过)
阀值设置
- 1800@09:00-18:00 , 这例子是指定了早上9点到下午6点,报警阀值为1800.
3.7 otter使用注意点
3.7.1 使用限制
- 暂不支持无主键表同步. (同步的表必须要有主键,无主键表update会是一个全表扫描,效率比较差)
- 支持部分ddl同步 (支持create table / drop table / alter table / truncate table / rename table / create index / drop index,其他类型的暂不支持,比如grant,create user,trigger等等),同时ddl语句不支持幂等性操作,所以出现重复同步时,会导致同步挂起,可通过配置高级参数:跳过ddl异常,来解决这个问题.
- 不支持带外键的记录同步. (数据载入算法会打散事务,进行并行处理,会导致外键约束无法满足)
数据库上trigger配置慎重. (比如源库,有一张A表配置了trigger,将A表上的变化记录到B表中,而B表也需要同步。如果目标库也有这trigger,在同步时会插入一次A表,2次B表,因为A表的同步插入也会触发trigger插入一次B表,所以有2次B表同步.)
3.7.2 node jvm配置
单node建议的同步任务,建议控制下1~2wtps以下,不然内存不够用. 出现不够用时,具体的解决方案:
调大node的-Xms,-Xmx内存设置,默认为3G,heap区大概是2GB
- 减少每个同步的任务内存配置.
a. canal配置里有个内存存储buffer记录数参数,默认是32768,代表32MB的binlog,解析后在内存中会占用100MB的样子.
b. pipeline配置里有个批次大小设置,默认是6000,代表每次获取6MB左右,解析后在内存占用=并行度6MB3,大概也是100MB的样子.
3.7.3 数据表字段变更

若有收获,就点个赞吧
0 人点赞
