1.认识mongdb
mongodb是一个开源,文档类型的非关系型数据库,是最像关系型数据库的非关系型数据库。
mongodb存储的是由字段和值组成的数据类型称为BSON,类似于JSON对象。包含字段的值,数组,文档数组。
与mysql的对比:
| mysql | mongodb | 解释/说明 |
|---|---|---|
| column | field | 数据字段/域 |
| database | database | 数据库 |
| index | index | 索引 |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
| row | document | 数据记录行/文档 |
| table | collection | 数据库表/集合 |
| table joins | 无 | 表连接/mongo只能嵌入文档 |
主要特性
- 高性能
- 对嵌入式数据模型的支持减少了数据库系统上的I / O操作
- 索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。
- 高可用 -副本集
- 自动_故障转移
- 数据冗余
- 水平拓展
- 分片将数据分布在一个集群的集群上
- 3.4以后支持基于分片键创建数据区域
- 丰富的查询支持
- 支持CRUD 聚合,空间地理查询
应用场景
- 数据量较大;
- 读写频繁;
- 价值较低的数据,对事物要求不高。
集群模式-副本集
为了保证数据的冗余和可靠性和提高整个系统的负载 所以需要搭建mongo集群,mongo不是mysql那种主备模式,mongo是有自动故障恢复功能的主从集群
主从集群和副本集最大的区别就是副本集没有固定的“主节点”;整个集群会选出一个“主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(主、primary)和一个或多个备份节点(从、econdary)。
搭建mongo副本集 至少需要三个节点 有两种模式可选择
- 主节点(Primary)类型:数据操作的主要连接点,可读写。
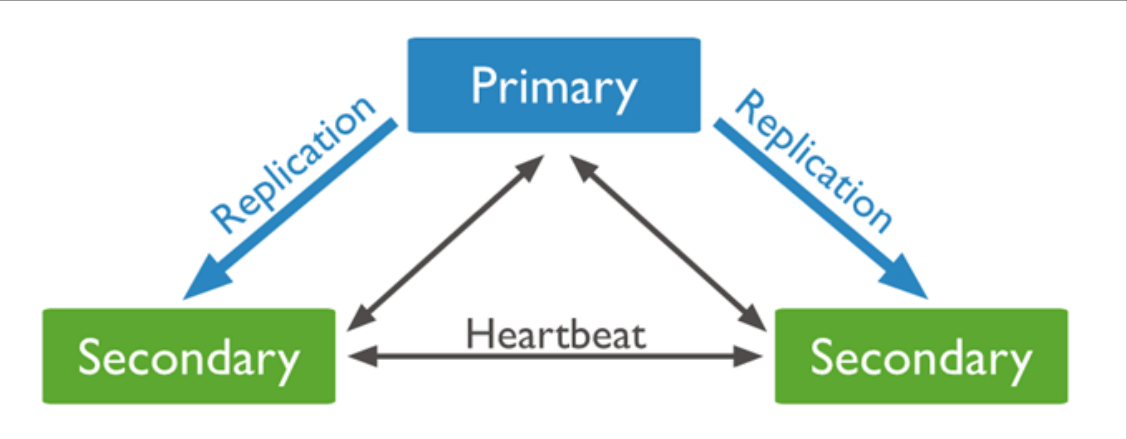
- 次要(辅助、从)节点(Secondaries)类型:数据冗余备份节点,可以读或选举。
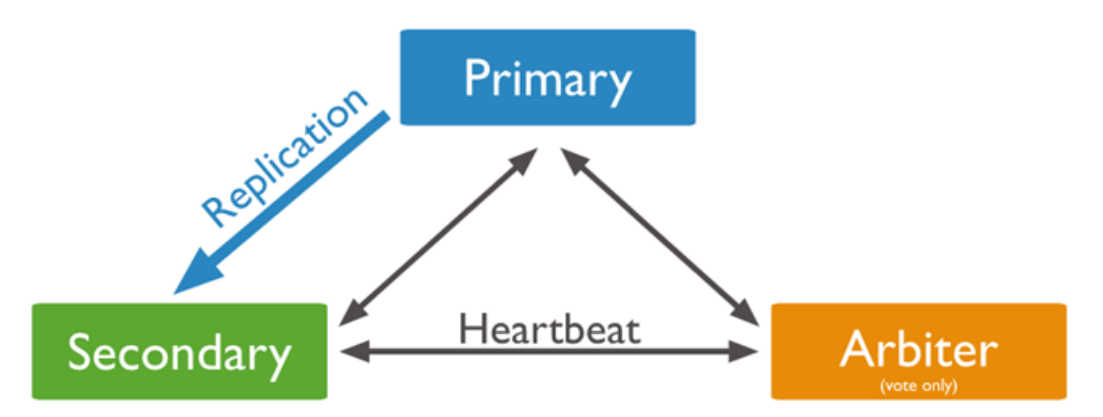
主节点类型:当主节点挂点后,两个从节点会竞争产生一个主节点 ,再当其中一个节点挂掉号 整个集群不可用 ,当挂掉的主节点启动后会变成从节点
从节点类型:带有仲裁节点,仲裁节点不存储数据,可以节省成本 当主节点挂掉后 仲裁节点可以投票 从节点变成主节点
2.docker 安装 mongdb 单机与副本集
创建单机只需要执行一次,也不需要指定副本集名称
此次没有挂载日志和存储目录 采用一主一从一仲裁
docker run --name mongo3 -p 57017:27017 -id mongo --replSet "rs"docker run --name mongo2 -p 47017:27017 -id mongo --replSet "rs"docke run --name mongo1 -p 37017:27017 -id mongo --replSet "rs"
随便进入一个容器执行,如果是阿里云服务器,需指定外网ip
arbiterOnly:true 指定为仲裁节点
rs.initiate({"_id":"rs",members:[{_id:0,host:"106.14.72.13:37017"},{_id:1,host:"106.14.72.13:47017"},{_id:2,host:"106.14.72.13:57017",arbiterOnly:true}]})
3.可视化工具与基本操作命令
nosqlbooster 可视化
mongdb-compass-可视化
文档的操作
/********************数据库 操作*********/// 选择或创建数据库 use 数据库名称use articledb//查看有权限查看的所有的数据库命令show dbsshow databases//查看当前正在使用的数据库db//删除数据库db.dropDatabase()/********************集合/表 操作*********///显示创建集合 /表 db.createCollection(name)db.createCollection("mycollection")//当前库中的表show collectionsshow tables//删除集合 db.collection.drop()db.comment.drop()//插入文档(单条) 不存在则会隐式创建db.comment.insert({ "articleid": "100000", "content": "今天天气真好,阳光明媚", "userid": "1001", "nickname": "Rose", "createdatetime": new Date(), "likenum": NumberInt(10), "state": null })//批量插入db.comment.insertMany([{ "_id": "1", "articleid": NumberInt(100001), "content": "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。", "userid": NumberInt(1002), "nickname": "相忘于江湖", "createdatetime": new Date("2019-08-05T22:08:15.522Z"), "likenum": NumberInt(1000), "state": NumberInt(1) }, { "_id": "2", "articleid": NumberInt(100001), "content": "我夏天空腹喝凉开水,冬天喝温开水", "userid": NumberInt(1005), "nickname": "伊人憔悴", "createdatetime": new Date("2019-08-05T23:58:51.485Z"), "likenum": NumberInt(888), "state": NumberInt(1) }, { "_id": "3", "articleid": NumberInt(100001), "content": "我一直喝凉开水,冬天夏天都喝。", "userid": NumberInt(1004), "nickname": "杰克船长", "createdatetime": new Date("2019-08-06T01:05:06.321Z"), "likenum": NumberInt(666), "state": NumberInt(1) }, { "_id": "4", "articleid": NumberInt(100001), "content": "专家说不能空腹吃饭,影响健康。", "userid": NumberInt(1003), "nickname": "凯撒", "createdatetime": new Date("2019-08-06T08:18:35.288Z"), "likenum": NumberInt(2000), "state": NumberInt(1) }, { "_id": "5", "articleid": NumberInt(100001), "content": "研究表明,刚烧开的水千万不能喝,因为烫嘴。", "userid": NumberInt(1003), "nickname": "凯撒", "createdatetime": new Date("2019-08-06T11:01:02.521Z"), "likenum": NumberInt(3000), "state": NumberInt(1) }]);//批量插入 某行报错不会回滚可以加try catchtry {db.comment.insertMany([{ "_id": "1", "articleid": NumberInt(100001), "content": "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。", "userid": NumberInt(1002), "nickname": "相忘于江湖", "createdatetime": new Date("2019-08-05T22:08:15.522Z"), "likenum": NumberInt(1000), "state": NumberInt(1) }, { "_id": "2", "articleid": NumberInt(100001), "content": "我夏天空腹喝凉开水,冬天喝温开水", "userid": NumberInt(1005), "nickname": "伊人憔悴", "createdatetime": new Date("2019-08-05T23:58:51.485Z"), "likenum": NumberInt(888), "state": NumberInt(1) }, { "_id": "3", "articleid": NumberInt(100001), "content": "我一直喝凉开水,冬天夏天都喝。", "userid": NumberInt(1004), "nickname": "杰克船长", "createdatetime": new Date("2019-08-06T01:05:06.321Z"), "likenum": NumberInt(666), "state": NumberInt(1) }, { "_id": "4", "articleid": NumberInt(100001), "content": "专家说不能空腹吃饭,影响健康。", "userid": NumberInt(1003), "nickname": "凯撒", "createdatetime": new Date("2019-08-06T08:18:35.288Z"), "likenum": NumberInt(2000), "state": NumberInt(1) }, { "_id": "5", "articleid": NumberInt(100001), "content": "研究表明,刚烧开的水千万不能喝,因为烫嘴。", "userid": NumberInt(1003), "nickname": "凯撒", "createdatetime": new Date("2019-08-06T11:01:02.521Z"), "likenum": NumberInt(3000), "state": NumberInt(1) }]);} catch (e) {print(e);}/********************文档 操作*********///查询所有db.comment.find()db.comment.find({})//条件查询db.comment.find({userid:'1003'})//查询单条db.comment.findOne({userid:'1003'})//投影查询db.comment.find({userid:NumberInt(1003)},{userid:1,nickname:1})//覆盖修改 其他字段全不见db.comment.update({_id:"1"},{likenum:NumberInt(1001)})//局部修改db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})//批量更新 增加标志 multidb.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})//自增长db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})//根据条件删除 没有条件删除全部db.comment.remove({_id:"1"})//统计记录数 没有参数统计全部db.comment.count({userid:"1003"})//分页操作 ->截取前三位db.comment.find().limit(3)//分页操作 跳过多少行,查询多少行 类似sql limit 4,6db.comment.find().skip(3).limit(2)//排序操作 -1 倒序 1升序db.comment.find().sort({userid:-1,likenum:1})//复杂查询 ->正则表达式匹配db.comment.find({content:/^专家/})//比较查询db.comment.find({ "field" : { $gt: value }}) // 大于: field > valuedb.comment.find({ "field" : { $lt: value }}) // 小于: field < valuedb.comment.find({ "field" : { $gte: value }}) // 大于等于: field >= valuedb.comment.find({ "field" : { $lte: value }}) // 小于等于: field <= valuedb.comment.find({ "field" : { $ne: value }}) // 不等于: field != value//包含查询db.comment.find({userid:{$in:["1003","1004"]}})//不包含查询db.comment.find({userid:{$nin:["1003","1004"]}})//连接查询 anddb.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})//连接查询 ordb.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
4.索引
官网链接
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。
mongodb的数据结构是B-tree
4.1 单字段索引
在文档上的单个字段创建自定义的升序/降序索引,称为单字段索引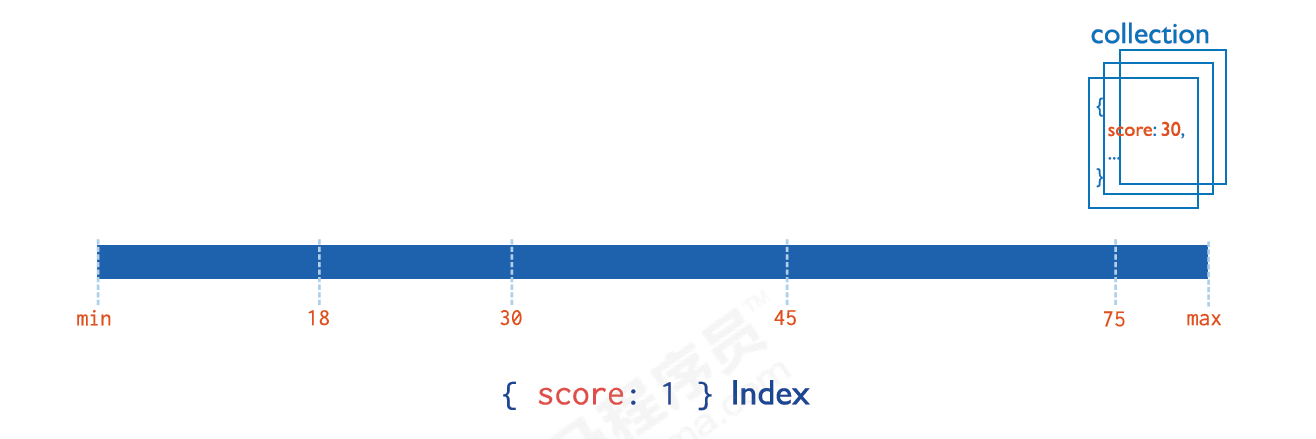
4.2 复合索引
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由{ userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。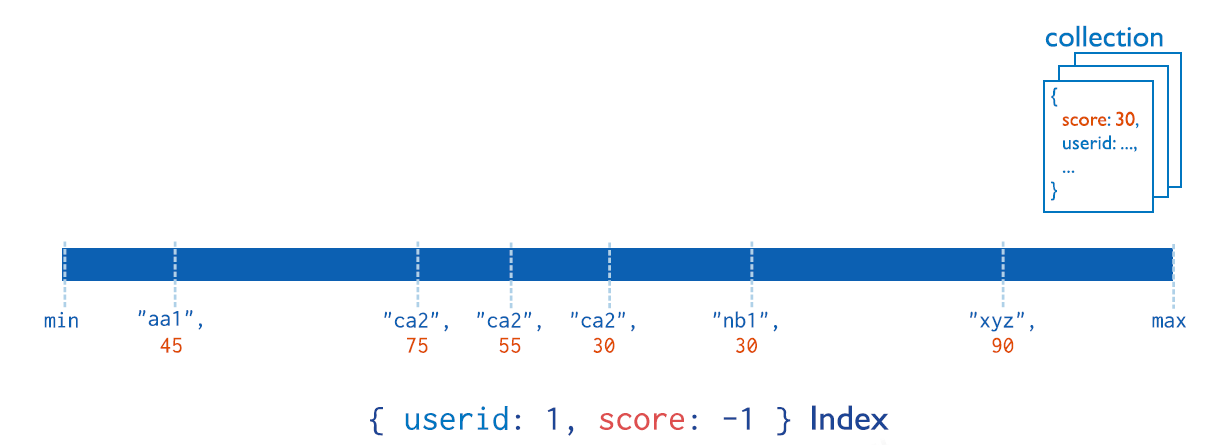
3.3 其他索引
地理空间索引(Geospatial Index)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)。
3.4 关于索引的语法
//查看索引db.collection.getIndexes()//创建索引db.collection.createIndex(keys, options)//移除索引db.collection.dropIndex(index)
5.分片集群
分片是一种将数据分配到多个机器上的方法。MongoDB通过分片技术来支持具有海量数据集和高吞吐量操作的部署方案
数据库系统的数据集或应用的吞吐量比较大的情况下,会给单台服务器的处理能力带来极大的挑战。例如,高查询率会耗尽服务器的CPU资源。工作的数据集大于系统的内存压力、磁盘驱动器的I/O容量。
分片集群包含组件
- 分片:每个shard(分片)包含被分片的数据集中的一个子集。每个分片可以被部署为副本集架构。
- mongs:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
- config服务器:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
分片的优势
- 读写负载
- 存储容量
- 高可用性
6.安全认证
1.启用访问控制
在实例启动时添加选项—auth 或指定启动配置文件中添加选项auth=true 容器启动配置-auth为true
2.角色
在MongoDB中通过角色对用户授予相应数据库资源的操作权限,每个角色当中的权限可以显式指定,也可以通过继承其他角色的权限,或者两都都存在的权限。
3.权限
权限由指定的数据库资源(resource)以及允许在指定资源上进行的操作(action)组成。
- 资源(resource)包括:数据库、集合、部分集合和集群;
- 操作(action)包括:对资源进行的增、删、改、查(CRUD)操作。
在角色定义时可以包含一个或多个已存在的角色,新创建的角色会继承包含的角色所有的权限。在同一个数据库中,新创建角色可以继承其他角色的权限,在admin 数据库中创建的角色可以继承在其它任意数据库中角色的权限。
// 查询所有角色权限(仅用户自定义角色)db.runCommand({ rolesInfo: 1 })// 查询所有角色权限(包含内置角色)db.runCommand({ rolesInfo: 1, showBuiltinRoles: true })// 查询当前数据库中的某角色的权限db.runCommand({ rolesInfo: "<rolename>" })// 查询其它数据库中指定的角色权限db.runCommand({ rolesInfo: { role: "<rolename>", db: "<database>" } }
| 角色 | 权限描述 |
|---|---|
| read | 可以读取指定数据库中任何数据。 |
| readWrite | 可以读写指定数据库中任何数据,包括创建、重命名、删除集合。 |
| readAnyDatabase | 可以读取所有数据库中任何数据(除了数据库config和local之外)。 |
| readWriteAnyDatabase | 可以读写所有数据库中任何数据(除了数据库config和local之外)。 |
| userAdminAnyDatabase | 可以在指定数据库创建和修改用户(除了数据库config和local之外)。 |
| dbAdminAnyDatabase | 可以读取任何数据库以及对数据库进行清理、修改、压缩、获取统计信息、执行检查等操作(除了数据库config和local之外)。 |
| dbAdmin | 可以读取指定数据库以及对数据库进行清理、修改、压缩、获取统计信息、执行检查等操作。 |
| userAdmin | 可以在指定数据库创建和修改用户。 |
| clusterAdmin | 可以对整个集群或数据库系统进行管理操作。 |
| backup | 备份MongoDB数据最小的权限。 |
| restore | 从备份文件中还原恢复MongoDB数据(除了system.profile集合)的权限。 |
| root | 超级账号,超级权限 |
7.springboot连接mongdb
加入jia包支持 自动跟随springboot版本
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId></dependency>
配置mongodb连接 权限认证如果不是在本库创建的用户 则需要在admin库进行权限认证。可以在/直接跟admin
然后在database 指定要连接的库
spring:data:mongodb:#test 指需要连接的库 authSource=admin指权限在admin认证uri: mongodb://rem:123456@106.14.72.13:37017,106.14.72.13:47017/test?replicaSet=rs&readPreference=secondaryPreferred&connectTimeoutMS=15000&slaveOk=true&write=1&authSource=adminuuid-representation: standardauto-index-creation: true#database:
使用springboot连接mongodb 和使用其他springdata操作一样 继承MongoRepository
package com.rem.mongodb.dao;import com.rem.mongodb.entity.Comment;import org.springframework.data.mongodb.repository.MongoRepository;import org.springframework.stereotype.Repository;/*** 集成springDate 基本操作* 评论的持久层接口** @author Rem* @date 2021/11/9*/@Repositorypublic interface CommentRepository extends MongoRepository<Comment, String> {}
简单的CRUD以及分页操作,也可以直接使用mongoTemplate操作对象和dao层操作数据一样,如果不需要查询出对象再进行操作 比如加一操作,直接使用template操作更加简单。
springboot集成的事务对mongodb依然有效在方法上加上事务注解,在启动类加上开启事务或者单独配置事务类,当报错时不会对mongodb中数据进行操作。
package com.rem.mongodb.service;import com.rem.mongodb.dao.CommentRepository;import com.rem.mongodb.entity.Comment;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.domain.*;import org.springframework.data.mongodb.core.MongoTemplate;import org.springframework.data.mongodb.core.query.Criteria;import org.springframework.data.mongodb.core.query.Query;import org.springframework.data.mongodb.core.query.Update;import org.springframework.stereotype.Service;import org.springframework.transaction.annotation.Transactional;import java.util.List;/*** 文章 服务层** @author Rem* @date 2021/11/9*/@Servicepublic class CommentService {@Autowiredprivate CommentRepository commentRepository;@Autowiredprivate MongoTemplate mongoTemplate;/*** 保存一个评论** @param comment*/@Transactionalpublic void saveComment(Comment comment) {//如果需要自定义主键,可以在这里指定主键;如果不指定主键,MongoDB会自动生成主键 设置一些默认初始值commentRepository.save(comment);}/*** 更新评论** @param comment*/public void updateComment(Comment comment) {commentRepository.save(comment);}/*** 根据id删除评论** @param id*/public void deleteCommentById(String id) {commentRepository.deleteById(id);}/*** 查询所有评论* ,** @return*/public List<Comment> findCommentList() {return commentRepository.findAll();}/*** 根据id查询评论** @param id* @return*/public Comment findCommentById(String id) {return commentRepository.findById(id).get();}/*** 根据多个id 批量查询评论** @return*/public List<Comment> findCommentList(List<String> ids) {return (List<Comment>) commentRepository.findAllById(ids);}/*** 根据条件查询** @param comment* @return*/public List<Comment> findComment(Comment comment) {return commentRepository.findAll(Example.of(comment));}/*** 模糊查询* StringMatcher 枚举中可选择各种匹配模式* ExampleMatcher.StringMatcher.DEFAULT 默认* ExampleMatcher.StringMatcher.EXACT 精确匹配* ExampleMatcher.StringMatcher.STARTING 前缀匹配* ExampleMatcher.StringMatcher.ENDING 后缀匹配* ExampleMatcher.StringMatcher.CONTAINING 模糊查询* ExampleMatcher.StringMatcher.REGEX 正则表达式* matching 匹配** @param comment* @return*/public List<Comment> findCommentDim(Comment comment) {ExampleMatcher matcher = ExampleMatcher.matching().withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING).withIgnoreCase(true);return commentRepository.findAll(Example.of(comment, matcher));}/*** 分页查询 并且按照 likenum 点赞数倒序** @param comment* @return*/public Page<Comment> findCommentByPage(Comment comment, Integer page, Integer size) {Sort sort = Sort.by(Sort.Direction.DESC, "likenum");//分页 0代表第一页Pageable pageable = PageRequest.of(page, size, sort);return commentRepository.findAll(Example.of(comment), pageable);}/*** 使用mongoTemplate 简单操作* 点赞数+1** @param id*/public void updateCommentLikenum(String id) {//查询对象Query query = Query.query(Criteria.where("_id").is(id));//更新对象Update update = new Update();//局部更新,相当于$set// update.set(key,value)//递增$inc// update.inc("likenum",1);update.inc("likenum");//参数1:查询对象//参数2:更新对象//参数3:集合的名字或实体类的类型Comment.classmongoTemplate.updateFirst(query, update, "comment");}}

若有收获,就点个赞吧
0 人点赞
