9 redis主从复制
9.1 redis主从复制是什么
根据配置和策略搭建多台redis服务器,将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave)。数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave以读为主。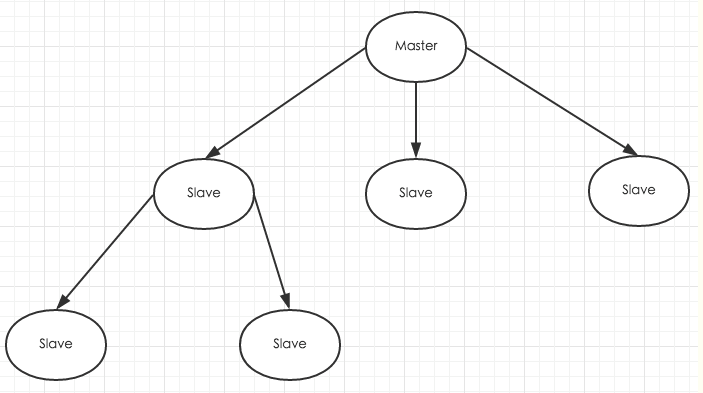
9.2 redis为什么需要主从复制
- include 引用基础配合
- pidfile pid名称(不可相同)
- daemonize yes 表示后台配置启动
- port 配置端口
- dbfilename 配置持久化文件名称
- requirepass 服务启动密码
- bind 绑定ip地址 (使用外部客户端需要放开)
- replicaof 配置连接master地址 (可以不配置,但是需要每次启动时手动配置连接)阿里云需要用外网ip
masterauth master密码
include /home/myredis/redis-6.2.1/redis.confpidfile /var/run/redis_6390.pidport 6390dbfilename dump6390.rdbdaemonize yesrequirepass 123456bind 0.0.0.0masterauth 123456
include /home/myredis/redis-6.2.1/redis.confpidfile /var/run/redis_6391.pidport 6391dbfilename dump6391.rdbdaemonize yesrequirepass 123456bind 0.0.0.0replicaof 127.0.0.1 6390masterauth 123456
include /home/myredis/redis-6.2.1/redis.confpidfile /var/run/redis_6392.pidport 6392dbfilename dump6392.rdbdaemonize yesrequirepass 123456bind 0.0.0.0# 主节点信息replicaof 127.0.0.1 6390masterauth 123456
9.3.2 查看主从信息
info replication
9.4 redis主从三大特点
9.4.1 一主两从
当手动配置replicaof 不是在配置文件中配置时,从服务器挂掉之后重启不再是原先master的从服务器,需要重新加入
- 从服务器重新加载时会重新拉取所有主服务器的数据
主服务器挂掉后从服务不能成为主服务器,主服务器依旧存在 (解决主服务器挂机 搭建集群)
9.4.2 薪火相传
从服务器也可以拥有从服务器
- 优点:可以减轻master的写压力
- 缺点:当中间的从服务器挂掉后,后面的从服务器也不可用
9.4.3 反客为主
当主服务器挂掉之后执行 slaveof no one 将从服务器升为主服务器,如果该服务器后面也有从服务那么后面的从服务会认为前面升为主服务器的认为是主服务器。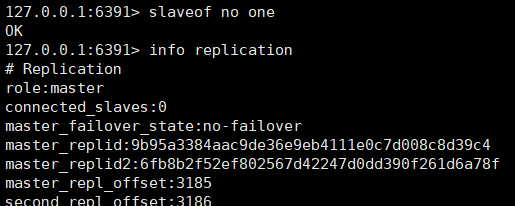
9.5 redis主从复制原理
- 采取异步复制
- Slave启动成功连接到Master后会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,Master将传送整个数据文件到Slave,以完成一次完全同步
- 全量复制:Slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给Slave,完成同步
但是只要是重新连接Master,一次完全同步(全量复制)将被自动执行
9.6 哨兵模式
能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
在生产上为了保证节点高可用 至少需要配置三个哨兵节点9.6.1 配置哨兵
配置一个 sentinel.conf host需要配置一个客户端访问的地址
daemonize yesbind 0.0.0.0port 6399# 配置监听的主服务器,这里sentinel monitor代表监控,redisMaster代表服务器的名称,可以自定义,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。sentinel monitor redisMaster 127.0.0.1 6390 1# sentinel author-pass定义服务的密码,redisMaster是服务名称,123456是Redis服务器密码sentinel auth-pass redisMaster 123456
9.6.2 启动哨兵模式
在正常的一主两从模式下 启动一个哨兵 默认端口26379
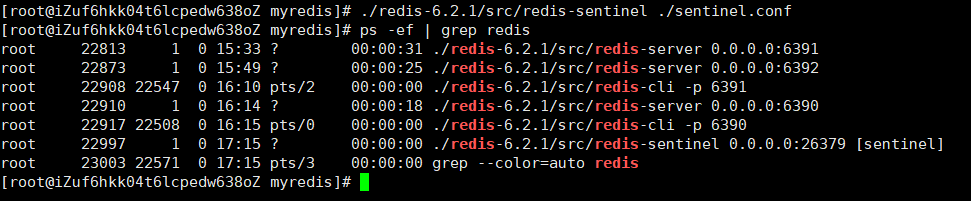
最初master是 6390端口 关闭 6390的节点 6392节点升为master 6390变为slave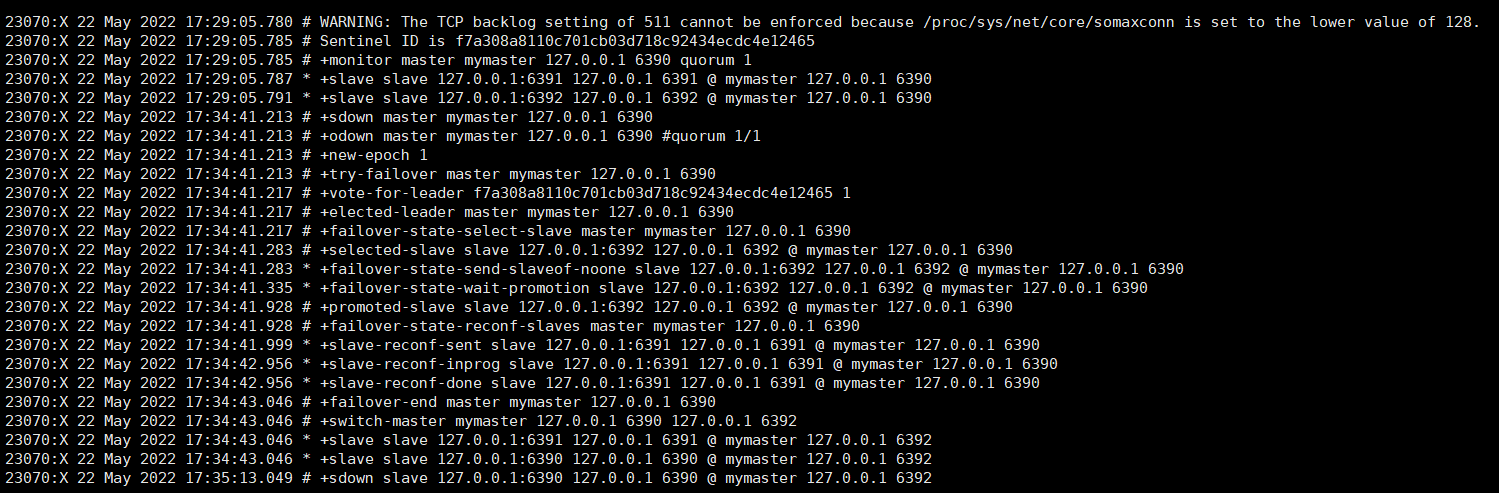
9.6.3 master选举机制
当主节点挂掉之后,其中一个从节点升为主节点,挂掉的主节点恢复过来变成了从节点。
从节点选为主节点依次优先级选择redis.conf配置中 replica-priority 中数字最小的 (默认100)
- 选择偏移量最大的 (偏移量指同步master数据最全的)
- runid最小的 (每个节点启动随机生成一个40为runid)
9.6.4 springboot 配置哨兵模式
spring:redis: ## redis哨兵配置timeout: 2000connect-timeout: 1000database: 0password: 123456 # master节点密码lettuce:pool:max-idle: 8 #连接池最大连接数 默认8min-idle: 0 #连接池最小连接数 默认0max-active: 8 # 池在给定时间可以分配的最大连接数。使用负值表示无限制max-wait: -1 #当池耗尽时,在抛出异常之前连接分配应该阻塞的最长时间。使用负值来无限期地阻止sentinel:nodes: 106.14.72.13:6399 #哨兵节点:哨兵端口master: redisMaster# password: 123456 # 哨兵密码
10 redis集群
10.1 什么是redis集群
redis集群就是对单台redis进行水平扩展,即有N个节点就会将数据分布在这个N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
redis在3.0之后就配置了无中心化配置,连接到任一节点就可以连接到集群所有节点。10.2 搭建redis集群
10.2.1 配置文件
配置 redis.6381~ redis.6386 6个配置文件 三主三从
阿里云配置集群一定要配置公网ip,密码 需要开启防火墙和__集群内部通信端口防火墙
设置了密码也必须配置 _masterauth 不然故障恢复切换会报错_
复制修改include /home/myredis/redis-6.2.1/redis.confcluster-enabled yescluster-config-file nodes-6381.confcluster-node-timeout 15000cluster-announce-ip 106.14.72.13pidfile "/var/run/redis_6381.pid"port 6381dbfilename "dump6381.rdb"daemonize yesrequirepass "123456"bind 0.0.0.0masterauth "123456"
10.2.2 构建集群
第一次创建集群使用该命令 后续不需要
—cluster-replicas 1 表示每个主节点创建一个从节点./redis-cli --cluster create --cluster-replicas 1 -a '123456' 106.14.72.13:6381 106.14.72.13:6382 106.14.72.13:6383 106.14.72.13:6384 106.14.72.13:6385 106.14.72.13:6386
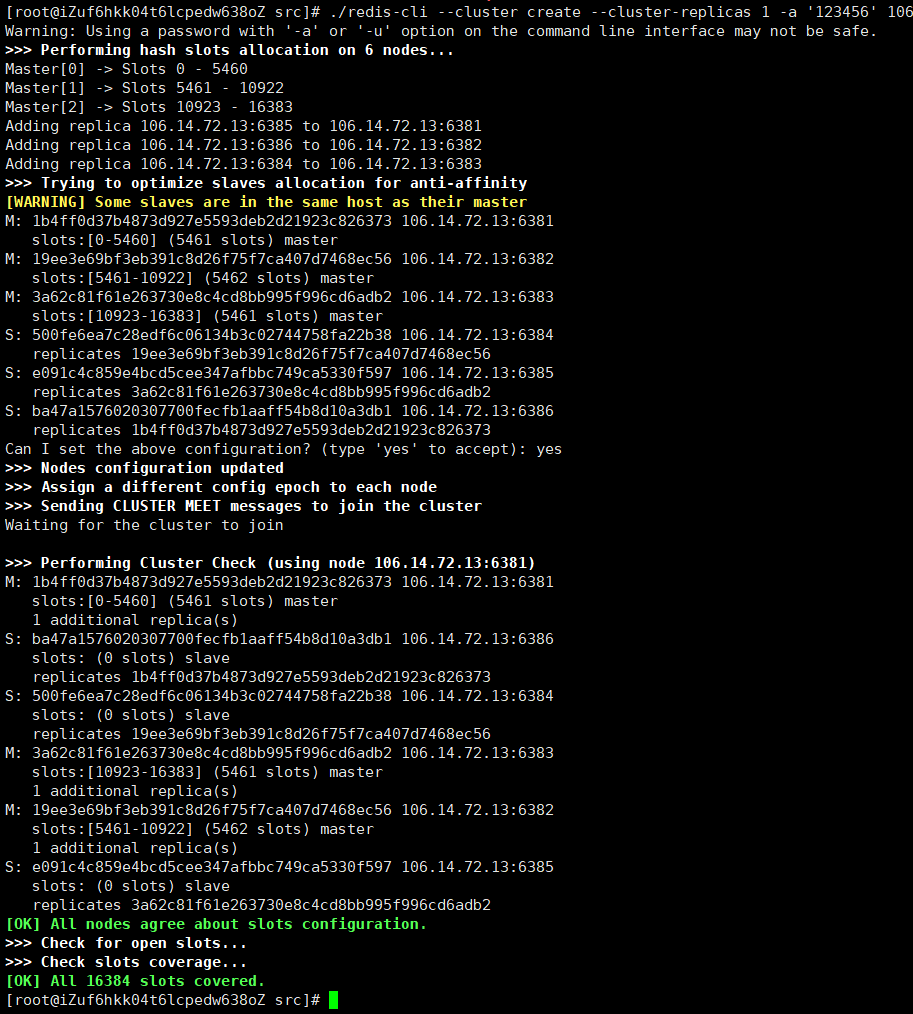
10.2.2 进入集群 查看节点信息

10.3 slots 插槽
一个redis集群有16384 个插槽 0~16383。
集群中每个节点负责其中一部分插槽
集群使用公式CRC16(key) % 16384 来计算键key 属于哪个槽,其中CRC16(key) 语句用于计算键key 的CRC16 校验和。
10.4 集群命令操作
集群不能批量操作key mget,mset 都会报错,因为涉及到计算插槽,只能通过定义组的方式,通过组来计算插槽的位置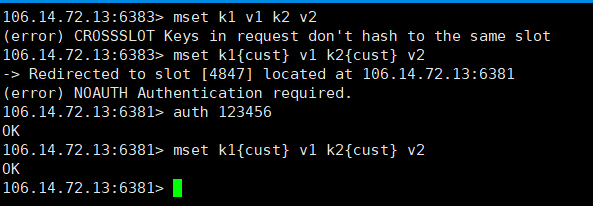
#计算key或者组在插槽的位置cluster keyslot <key>#计算在该number位置插槽的key的数量cluster countkeysinslot <number>#计算在该slot位置插槽的key的数量cluster countkeysinslot <slot>#获取slot插槽位置的key的value 最多获取count个cluster getkeysinslot <slot> <count>
10.5 故障恢复
将其中一个主节点(6383)下线 它的从节点(6385)会变成主节点,当以前主节点(6383)恢复上线依旧是从节点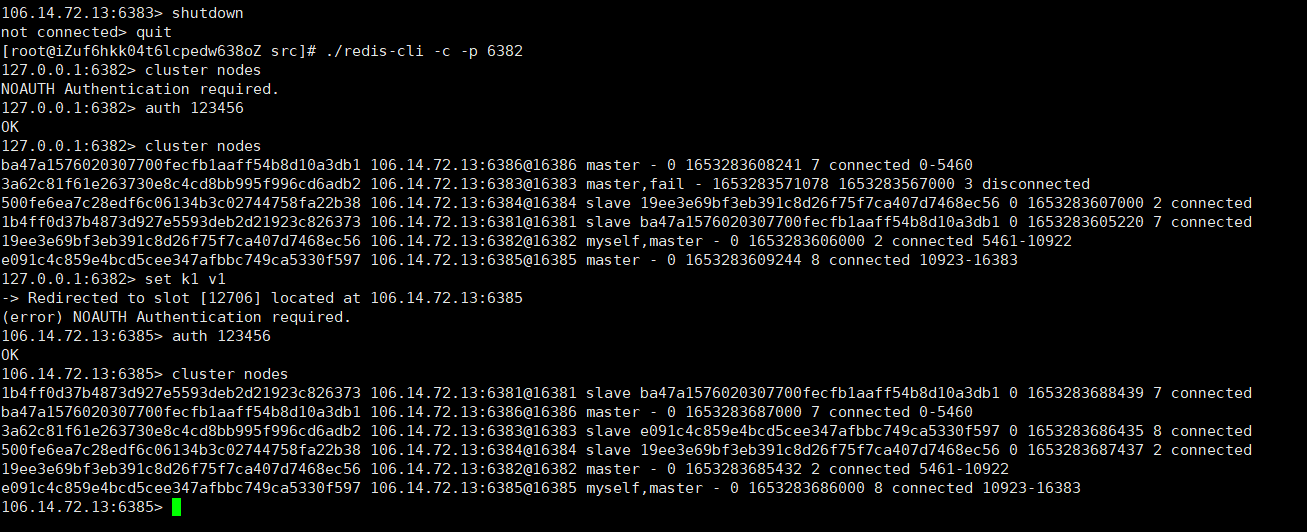
10.6 redis集群优缺点
优点
- 实现扩容
- 分摊压力
- 无中心化配置
缺点
- 数据通过异步复制,不保证数据的强一致性
- slave在集群中是冷备,不能实现读写分离
- 多键不被支持
- 不在同一节点不能支持lua脚本
10.7 springboot配置集群
spring:redis: ## redis集群配置timeout: 2000connect-timeout: 1000database: 0password: 123456 # master节点密码lettuce:pool:max-idle: 8 #连接池最大连接数 默认8min-idle: 0 #连接池最小连接数 默认0max-active: 8 # 池在给定时间可以分配的最大连接数。使用负值表示无限制max-wait: -1 #当池耗尽时,在抛出异常之前连接分配应该阻塞的最长时间。使用负值来无限期地阻止cluster:nodes: 106.14.72.13:6381,106.14.72.13:6382,106.14.72.13:6383,106.14.72.13:6384,106.14.72.13:6385,106.14.72.13:6386max-redirects: 2
11 redis应用问题解决
11.1 缓存穿透
问题描述:
访问一个db和redis都不存在的key,此时会直接访问db,并且没发写缓存,导致db压力大
解决方案:
- 缓存空值:对空值进行缓存,并且设置较短的过期时间(根据业务而定)
- 设置校验:
- 可以对接口入参进行校验
- 使用bitmaps设置访问白名单
-
11.1.1 布隆过滤器的实现
使用guava自带内存实现的布隆过滤器
- 使用Redission带的使用redis做布隆过滤器
- 使用redis原生bitField做布隆过滤器 ```java package com.rem.redis;
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import com.rem.redis.config.BloomFilterHelper; import com.rem.redis.config.RedisBloomFilter; import org.junit.jupiter.api.Test; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.client.codec.IntegerCodec; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest;
/**
- 测试布隆过滤器 *
- @author Rem
- @date 2022-05-24 */
@SpringBootTest public class Redis11BloomFilter {
@AutowiredRedissonClient redissonClient;@AutowiredRedisBloomFilter redisBloomFilter;Double fpp = 0.02;Integer expectedInsertions = 1000000;/*** 创建一个具有预期插入次数和预期误报概率的BloomFilter 。* 请注意,溢出的元素比指定的多得多的BloomFilter将导致其饱和,并导致其误报概率急剧恶化。* 如果提供的Funnel<T>是,则构造的BloomFilter将是可序列化的。* 建议将funnel实现为 Java 枚举。这有利于确保正确的序列化和反序列化,这很重要,因为equals还依赖于漏斗的对象标识。* <p>* <p>* funnel – 构造的BloomFilter将使用的 T 的漏斗* expectedInsertions – 构造的BloomFilter的预期插入次数;必须是正面的* fpp – 期望的误报概率(必须为正且小于 1.0)*/@Testvoid guavaBloomFilter() {BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);for (int i = 0; i < expectedInsertions; i++) {bloomFilter.put(i);}int count = 0;for (int i = expectedInsertions; i < expectedInsertions * 2; i++) {if (bloomFilter.mightContain(i)) {count++;}}System.out.println("一共误判了:" + count);}/*** 使用redission带的布隆过滤器*/@Testvoid RedissionBloomFilter() {expectedInsertions = 500;RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("redission01", IntegerCodec.INSTANCE);bloomFilter.tryInit(expectedInsertions, fpp);for (int i = 0; i < expectedInsertions; i++) {bloomFilter.add(i);}int count = 0;for (int i = expectedInsertions; i < expectedInsertions * 2; i++) {if (bloomFilter.contains(i)) {count++;}}System.out.println("一共误判了:" + count);}/*** 使用redis bitField原生做布隆过滤器*/@Testvoid RedisBloomFilter() {expectedInsertions = 500;BloomFilterHelper<Integer> integerBloomFilterHelper = new BloomFilterHelper<>(Funnels.integerFunnel(), expectedInsertions, fpp);for (int i = 0; i < expectedInsertions; i++) {redisBloomFilter.addByBloomFilter(integerBloomFilterHelper, "redis05", i);}int count = 0;for (int i = expectedInsertions; i < expectedInsertions * 2; i++) {if (redisBloomFilter.includeByBloomFilter(integerBloomFilterHelper, "redis05", i)) {count++;}}System.out.println("一共误判了:" + count);}
}
<br />```javapackage com.rem.redis.config;import com.google.common.base.Preconditions;import com.google.common.hash.Funnel;import com.google.common.hash.Funnels;import com.google.common.hash.Hashing;import java.nio.charset.Charset;/*** 基于redis位运算 布隆过滤器** @author Rem* @date 2022/5/24*/public class BloomFilterHelper<T> {private int numHashFunctions;private int bitSize;private Funnel<T> funnel;public BloomFilterHelper(int expectedInsertions) {this.funnel = (Funnel<T>) Funnels.stringFunnel(Charset.defaultCharset());bitSize = optimalNumOfBits(expectedInsertions, 0.03);numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);}public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {Preconditions.checkArgument(funnel != null, "funnel不能为空");this.funnel = funnel;bitSize = optimalNumOfBits(expectedInsertions, fpp);numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);}public int[] murmurHashOffset(T value) {int[] offset = new int[numHashFunctions];long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();int hash1 = (int) hash64;int hash2 = (int) (hash64 >>> 32);for (int i = 1; i <= numHashFunctions; i++) {int nextHash = hash1 + i * hash2;if (nextHash < 0) {nextHash = ~nextHash;}offset[i - 1] = nextHash % bitSize;}return offset;}/*** 计算bit数组长度*/private int optimalNumOfBits(long n, double p) {return (int) (-n * Math.log(p == 0 ? Double.MIN_VALUE : p) / (Math.log(2) * Math.log(2)));}/*** 计算hash方法执行次数*/private int optimalNumOfHashFunctions(long n, long m) {return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));}}
package com.rem.redis.config;import com.google.common.base.Preconditions;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.connection.BitFieldSubCommands;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.stereotype.Component;import java.util.List;/*** redis操作布隆过滤器** @author Rem* @date 2022/5/24*/@Componentpublic class RedisBloomFilter<T> {@Autowiredprivate RedisTemplate redisTemplate;/*** 根据给定的布隆过滤器添加值*/public void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");int[] offset = bloomFilterHelper.murmurHashOffset(value);BitFieldSubCommands commands = BitFieldSubCommands.create();for (int i : offset) {commands = commands.set(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(i).to(1);}redisTemplate.opsForValue().bitField(key, commands);}/*** 根据给定的布隆过滤器判断值是否存在*/public boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");int[] offset = bloomFilterHelper.murmurHashOffset(value);BitFieldSubCommands commands = BitFieldSubCommands.create();for (int i : offset) {commands = commands.get(BitFieldSubCommands.BitFieldType.unsigned(1)).valueAt(i);}List<Long> values = redisTemplate.opsForValue().bitField(key, commands);assert values != null;for (Long val : values) {if (val == 0) {return false;}}return true;}}
11.2 缓存击穿
问题描述:
redis中存在某一个热点key,在key过期的一瞬间,有大量请求进来直接打到db,造成db压力骤增
解决方案:
- 预先设置热门数据:在访问高峰前预先设置一批数据到redis,加大过期时长
- 实时调整key过期时间:通过监控调整热门key的过期时间,或永不过期
-
11.3 缓存雪崩
问题描述:
缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案: 设置过期时间随机:设置过期时间加一个随机值,防止大批量同时过期
- 构建多级缓存:nginx缓存,redis缓存,ehcache缓存等
- 设置过期标志:记录缓存过期提前量,过期时触发线程更新key
11.4 分布式锁
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
- 互斥性。在任意时刻,只有一个客户端能持有锁。
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 加锁和解锁必须具有原子性。
单机redis分布式锁
/*** redis setIfAbsent lock* 存在问题:* * 1.redis集群/哨兵模式下* * * - 客户端 A 在master 节点获取锁成功。* * * - 还没有把获取锁的信息同步到 salve 的时候,master 宕机* * * - salve 被选举为 新的 master ,这个时候客户端 A 的获取锁的数据是不存在 salve 中的。* * * - 其他的客户端就可以获取 客户端 A 持有的 锁。* * 2.高并发下* * * - if (clientId.equals(redisTemplate.opsForValue().get(lockKey)))执行完成后锁过期了* * * - 下面执行删除锁,就会删除其他线程的锁** @return*/public String setIfAbsentTransaction() {// 设置客户端idString clientId = IdUtil.fastSimpleUUID();try {// 设置锁 如果redis中已经存在 lockKey 则会添加失败Boolean result = redisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);if (result == null || !result) {return "error";}//具体业务Integer stock = (Integer) redisTemplate.opsForValue().get("stock");if (stock == null) {return ">>>>>>>> 数据异常请稍后重试";}if (stock > 0) {Long lastNumber = redisTemplate.opsForValue().decrement("stock");System.out.println(">>>>>>>>>>> 扣除库存成功,剩余:" + lastNumber);} else {System.out.println(">>>>>>>>>>> 扣除库存失败,库存不足");}} finally {// 如果客户端id相等if (clientId.equals(redisTemplate.opsForValue().get(lockKey))) {redisTemplate.delete(lockKey);}}return "success";}
redisson分布式锁
配置redisson
srping:redis:redisson:config: |sentinelServersConfig:sentinelAddresses:- redis://106.14.72.13:6399masterName: ${spring.redis.sentinel.master}password: ${spring.redis.password}checkSentinelsList: false
@BeanRedissonClient redissonClient() {Config config = new Config();SentinelServersConfig serverConfig = config.useSentinelServers().addSentinelAddress("redis://106.14.72.13:6399").setMasterName("redisMaster").setPassword("123456").setCheckSentinelsList(false);return Redisson.create(config);}
redisson锁实现
/*** redisson lock* 支持集群模式,支持锁根据业务时长自动延迟释放** @return*/public String redissonLock() {RLock lock = redissonClient.getLock(lockKey);boolean locked = lock.tryLock();try {if (locked) {//具体业务Integer stock = (Integer) redisTemplate.opsForValue().get("stock");if (stock == null) {return ">>>>>>>> 数据异常请稍后重试";}if (stock > 0) {Long lastNumber = redisTemplate.opsForValue().decrement("stock");System.out.println(">>>>>>>>>>> 扣除库存成功,剩余:" + lastNumber);} else {System.out.println(">>>>>>>>>>> 扣除库存失败,库存不足");}}} catch (Throwable throwable) {return "error";} finally {if (lock.isLocked()) {if (lock.isHeldByCurrentThread()) {lock.unlock();}}}return "success";}
12 redis6 新特性
12.1 ACL
12.1.1 ACL(Access Control List)简介
访问控制列表,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。在Redis 5版本之前,Redis 安全规则只有密码控制还有通过rename 来调整高危命令比如 flushdb , KEYS , shutdown 等。
*Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制:
- 接入权限:用户名和密码
- 可以执行的命令
- 可以操作的 KEY
12.1.2 ACL命令
#查看用户列表acl list#查看添加权限指令列表acl cat#查看具体类型下属命令acl cat <instruct>#查看当前用户acl whoami#添加用户 username:设置用户名,on/off:设置是否启用,pattern:可操作键模式,actegory:设置权限acl setuser <username> <on/off> ><password> ~<pattern> +@<actegory>#设置用户user2,密码abc,可操作ca:开头的键,权限是只读acl setuser user2 on >abc ~ca:* +@read
12.1.3 ACL规则
| 类型 | 参数 | 说明 | | —- | —- | —- | | 启动和禁用用户 | on | 激活某用户账号 | | | off | 禁用某用户账号。注意,已验证的连接仍然可以工作。如果默认用户被标记为off,则新连接将在未进行身份验证的情况下启动,并要求用户使用AUTH选项发送AUTH或HELLO,以便以某种方式进行身份验证。 | | 权限的添加删除 | +| 将指令添加到用户可以调用的指令列表中 | | | - | 从用户可执行指令列表移除指令 | | | +@ | 添加该类别中用户要调用的所有指令,有效类别为@admin、@set、@sortedset…等,通过调用ACL CAT命令查看完整列表。特殊类别@all表示所有命令,包括当前存在于服务器中的命令,以及将来将通过模块加载的命令。 | | | -@ | 从用户可调用指令中移除类别 | | | allcommands | +@all的别名 | | | nocommand | -@all的别名 | | 可操作键的添加或删除 | ~ | 添加可作为用户可操作的键的模式。例如~*允许所有的键 |
12.2 IO多线程
redis多线程参考链接
IO多线程其实指客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。Redis6执行命令依然是单线程。
redis的多路IO复用:在单个线程中记录跟踪每个socket(I/O流)的状态来管理多个I/O流。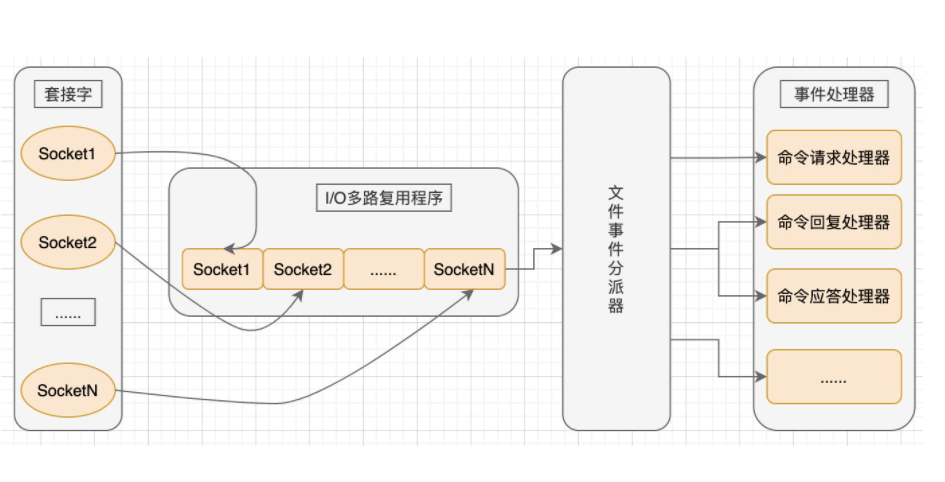
redis6开启多线程,默认是关闭的需要在配置文件中开启 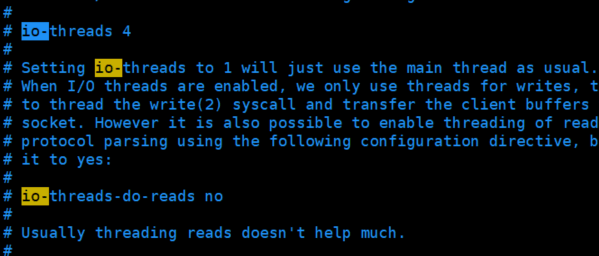
在Redis中虽然使用了IO多路复用,并且是基于非阻塞的IO进行操作的,但是IO的读写本身是阻塞的。比如当socket中有数据时,Redis会先将数据从内核态空间拷贝到用户态空间,然后再进行相关操作,而这个拷贝过程是阻塞的,并且当数据量越大时拷贝所需要的的时间就越多,而这些操作都是基于单线程完成的。redis6以后增加了多线程功能就可以提高I/O读写性能,它的主要实现思路是将主线程的IO读写任务拆分给一组独立的线程去执行,这样就可以使用多个socket的读写并行化了,但Redis的命令依旧是主线程串行执行的。
[关于线程数的设置,官方的建议是如果为4核CPU,那么设置线程数为2或3;如果为8核CPU,那么设置线程数为6.总之线程数一定要小于机器的CPU核数,线程数并不是越大越好]
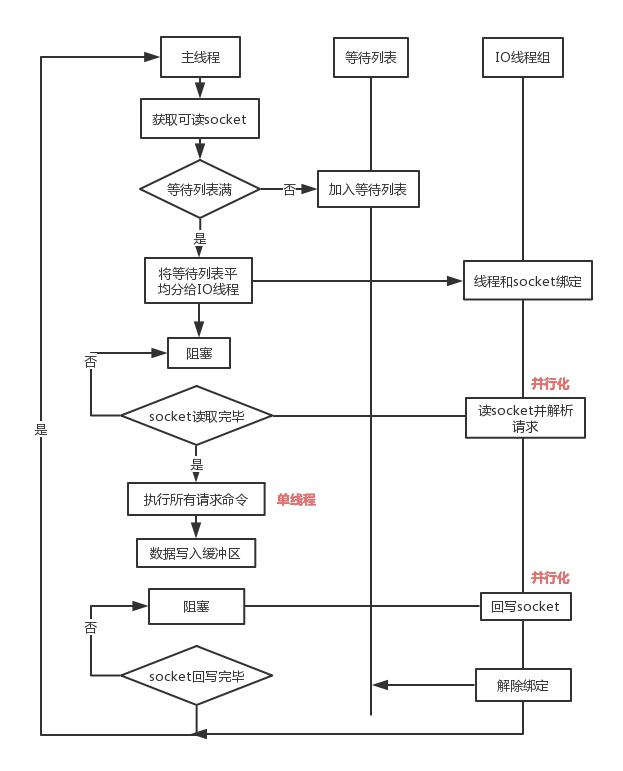
流程简述如下:
- 主线程负责接收建立连接请求,获取 Socket 放入全局等待读处理队列。
- 主线程处理完读事件之后,通过 RR(Round Robin)将这些连接分配给这些 IO 线程。
- 主线程阻塞等待 IO 线程读取 Socket 完毕。
- 主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行。
- 主线程阻塞等待 IO 线程将数据回写 Socket 完毕。
解除绑定,清空等待队列。
12.3 其他新特性
- 集成了ruby环境,将 redis-trib.rb 的功能集成到 redis-cli,官方 redis-benchmark 工具开始支持 cluster 模式了,通过多线程的方式对多个分片进行压测。
- RESP3新的 Redis 通信协议:优化服务端与客户端之间通信
- Client side caching客户端缓存:基于 RESP3 协议实现的客户端缓存功能。为了进一步提升缓存的性能,将客户端经常访问的数据cache到客户端。减少TCP网络交互。
- Proxy集群代理模式:Proxy 功能,让 Cluster 拥有像单实例一样的接入方式,降低大家使用cluster的门槛。不过需要注意的是代理不改变 Cluster 的功能限制,不支持的命令还是不会支持,比如跨 slot 的多Key操作。
- Redis 6中模块API开发进展非常大,因为Redis Labs为了开发复杂的功能,从一开始就用上Redis模块。Redis可以变成一个框架,利用Modules来构建不同系统,而不需要从头开始写然后还要BSD许可。Redis一开始就是一个向编写各种系统开放的平台。

若有收获,就点个赞吧
0 人点赞
