学习链接:https://www.bilibili.com/video/BV11A411L7CK?p=4&spm_id_from=pageDriver
1 创建Maven项目
1.1 增加Scala插件


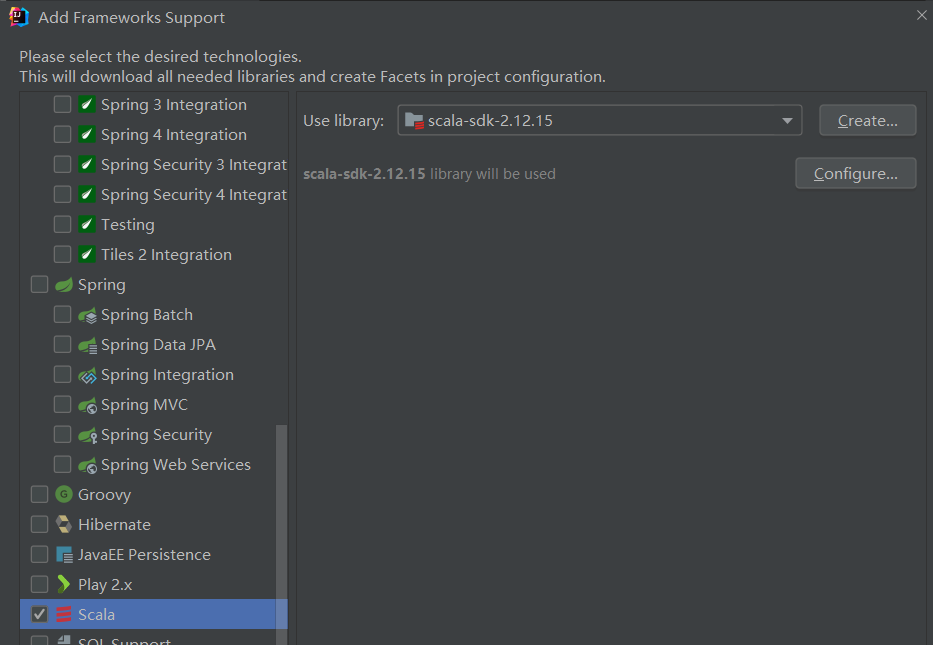
1.2 增加依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.3</version></dependency></dependencies>
1.3 WordCount
object Spark01_WordCount {def main(args: Array[String]): Unit = {// Application// Spark框架// TODO 建立和Spark框架的连接val sparkConf = new SparkConf().setMaster("local").setAppName("WorldCount")val sc = new SparkContext(sparkConf)// TODO 执行业务操作// 1. 读取文件,获取一行一行的数据// hello worldval lines = sc.textFile("datas")// 2. 将一行数据进行拆分,形成一个一个单词(分词)// 扁平化:将整体拆分成个体的操作// "hello world" => hello, world, hello, worldval words: RDD[String] = lines.flatMap(_.split(" "))// 3. 将数据根据单词进行分组,便于统计// (hello, hello, hello), (world, world)val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)// 4. 对分组后的数据进行转换// (hello, 3), (world, 2)val wordToCount = wordGroup.map {case (word, list) => {(word, list.size)}}// 5. 将转换结果打印val array: Array[(String, Int)] = wordToCount.collect()array.foreach(println)// TODO 关闭连接sc.stop()}}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// Application
// Spark框架
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WorldCount")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作
// 1. 读取文件,获取一行一行的数据
// hello world
val lines = sc.textFile("datas")
// 将一行数据进行拆分,形成一个一个单词(分词)
// 扁平化:将整体拆分成个体的操作
// "hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne = words.map(word => (word, 1))
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(
t => t._1
)
val wordToCount = wordGroup.map {
case (word, list) => {
list.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
// TODO 关闭连接
sc.stop()
}
}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// Application
// Spark框架
// TODO 建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WorldCount")
val sc = new SparkContext(sparkConf)
// TODO 执行业务操作
// 1. 读取文件,获取一行一行的数据
// hello world
val lines = sc.textFile("datas")
// 将一行数据进行拆分,形成一个一个单词(分词)
// 扁平化:将整体拆分成个体的操作
// "hello world" => hello, world, hello, world
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne = words.map(word => (word, 1))
// Spark框架提供了更多的功能,将分组和聚合使用一个方法实现
// reduceByKey:相同的key的数据,可以对value进行reduce聚合
// wordToOne.reduceByKey((x, y) => {x + y})
// wordToOne.reduceByKey((x, y) => x + y)
val wordToCount = wordToOne.reduceByKey(_ + _)
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
// TODO 关闭连接
sc.stop()
}
}
不打印日志:在resources目录创建log4j.properties文件,添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2 Spark运行环境
Spark作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行
2.1 Local模式
2.1.1 解压缩文件
将spark-3.0.0-bin-hadoop3.2.tgz文件上传到Linux虚拟机/opt/software下并解压缩到/opt/module
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C ../module
改名
[qtbhy@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-local
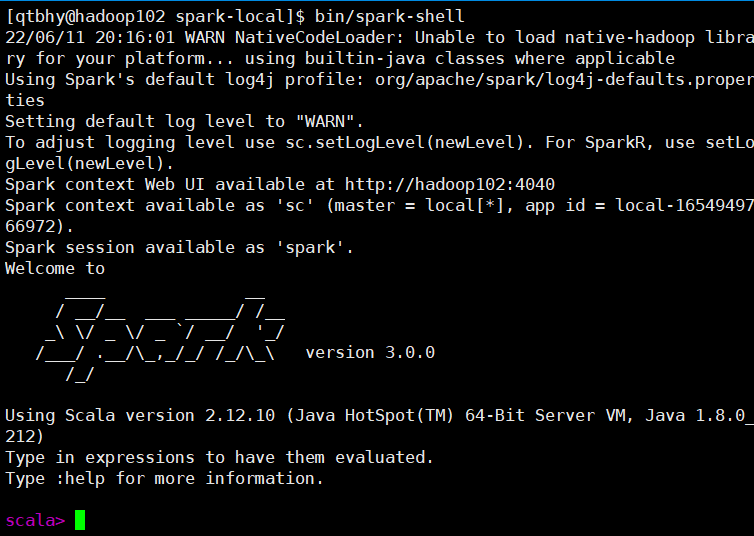
2.1.2 启动Local环境
进入解压缩后的路径,执行
[qtbhy@hadoop102 spark-local]$ bin/spark-shell
测试WordCount运行
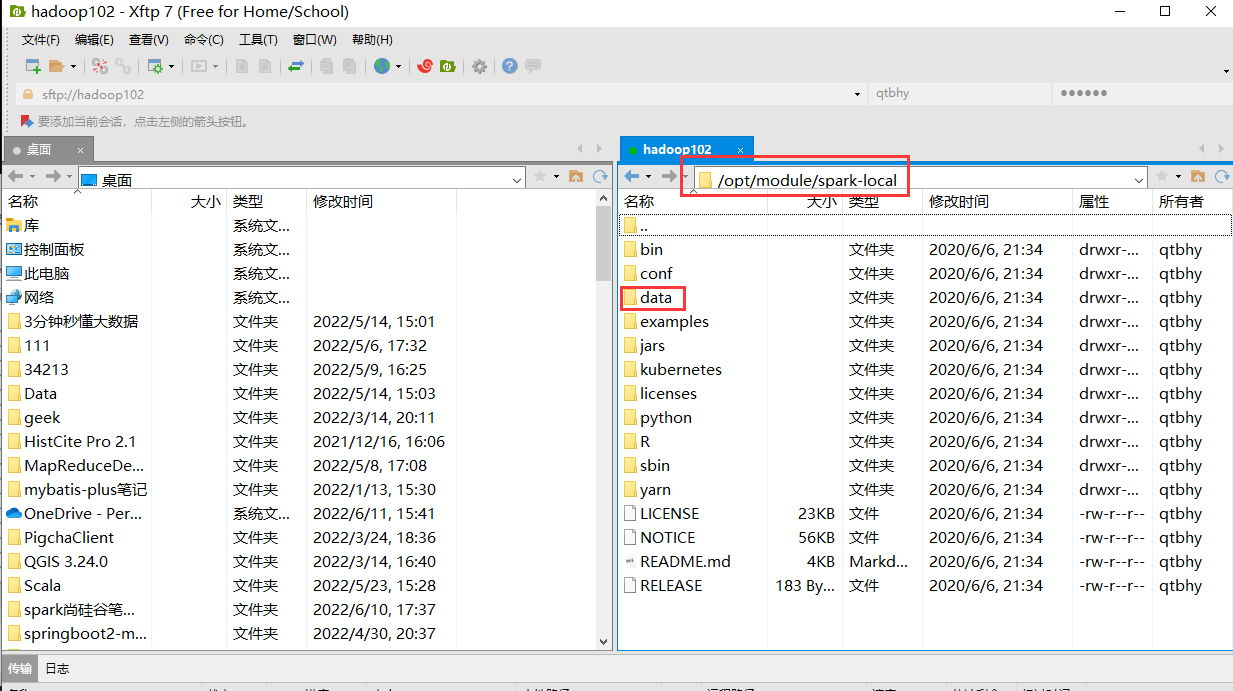
用Xftp在/opt/module/spark-local/data下创建word.txt
如果中文显示乱码,属性->选项->编码->将默认改为Unicode(UTF-8)

scala> sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

访问http://hadoop102:4040/,web UI监控页面

2.1.3 退出本地模式
2.1.4 提交应用
[qtbhy@hadoop102 spark-local]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \ // --class表示要执行程序的主类
> --master local[2] \ // --master local[2] 部署模式,默认本地模式,[]是分配的CPU核数
> ./examples/jars/spark-examples_2.12-3.0.0.jar \ // spark-examples_2.12-3.0.0.jar运行的应用类所在的jar包
> 10 // 程序的入口参数,设定当前应用的任务数量

2.2 Standalone 模式
独立部署(Standalone模式):只使用Spark自身节点运行的集群模式,体现了经典的master-slave模式
集群规划:
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
2.2.1 解压缩文件
[qtbhy@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
[qtbhy@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-standalone
2.2.2 修改配置文件
- /opt/module/spark-local/conf目录,把slaves.template重命名为slaves
- 修改slaves文件,添加work节点

- /opt/module/spark-local/conf目录,把spark-env.sh.template重命名为spark-env.sh
- 修改spark-env.sh文件,添加JAVA_HOME环境遍历和集群对应的master节点

- 分发spark-standalone集群
[qtbhy@hadoop102 module]$ xsync spark-standalone2.2.3 启动集群
[qtbhy@hadoop102 module]$ cd spark-standalone/ [qtbhy@hadoop102 spark-standalone]$ sbin/start-all.sh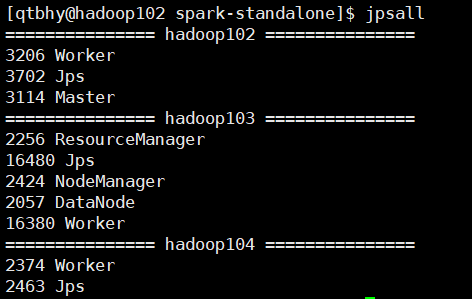
访问http://hadoop102:8080/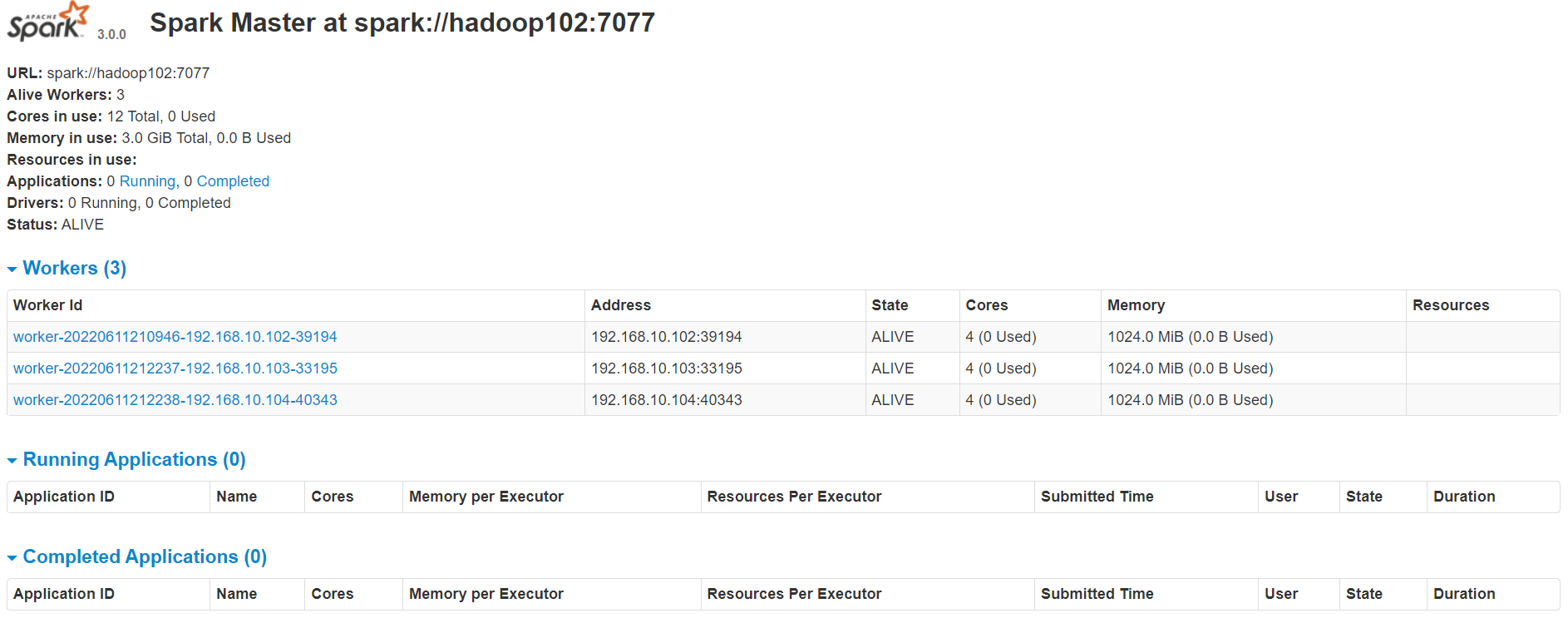
2.2.4 提交应用
| 参数 | 解释 | | —- | —- | | —class | Spark程序中包含主函数的类 | | —master | Spark程序运行的模式(环境),模式,如local[*]、spark://hadoop102:7077、Yarn | | —executor-memory 1G | 指定每个executor可用内存为1G | | —total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | | —executor-cores | 指定每个executor使用的cpu核数 | | application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。比如hdfs:// 共享存储系统,如果是file://path,所有的节点的path都包含同样的jar | | application-arguments | 传给main()方法的参数 |[qtbhy@hadoop102 spark-standalone]$ bin/spark-submit \ > --class org.apache.spark.examples.SparkPi \ > --master spark://hadoop102:7077 \ > ./examples/jars/spark-examples_2.12-3.0.0.jar \ > 10
2.2.5 配置历史服务
- 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop102:8020/directory修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory -Dspark.history.retainedApplications=30"
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序
信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
分发
[qtbhy@hadoop102 spark-standalone]$ xsync conf重新启动集群和历史服务 :::danger 这里要启动hadoop集群并保证已经有了HDFS 上的 directory 目录
没启动,start-dfs.sh
没目录,hadoop fs -mkdir /directory
遇到log出现问题报错关闭hadoop集群 myhadoop.sh stop
- 在hadoop102上 hdfs namenode -format
- 删除logs
[qtbhy@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
重启hadoop集群 myhadoop.sh start :::
[qtbhy@hadoop102 spark-standalone]$ sbin/start-all.sh [qtbhy@hadoop102 spark-standalone]$ sbin/start-history-server.sh重新执行任务
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop102:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10查看历史服务http://hadoop102:18080/

2.2.6 配置高可用(HA)
当前集群中的Master节点只有一个,会存在单点故障问题。为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置。
集群规划:
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| Spark | Master Zookeeper Worker |
Master Zookeeper Worker |
Zookeeper Worker |
停止集群
[qtbhy@hadoop102 spark-standalone]$ sbin/stop-all.sh
Zookeeper集群安装启动
集群安装
- apache-zookeeper-3.5.7- bin.tar.gz 上传到 /opt/software
解压到/opt/module
[qtbhy@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/修改 apache-zookeeper-3.5.7-bin 名称为 zookeeper-3.5.7
[qtbhy@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.配置服务器编号
在/opt/module/zookeeper-3.5.7目录下创建zkData
[qtbhy@hadoop102 zookeeper-3.5.7]$ mkdir zkData
在zkData下创建一个myid文件
[qtbhy@hadoop102 zkData]$ vim myid
在文件中添加与 server 对应的编号
2
分发到hadoop103、hadoop104并修改myid为3、4
[qtbhy@hadoop102 module]$ xsync zookeeper-3.5.7/
- 配置zoo.cfg文件
重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[qtbhy@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
打开zoo.cfg
[qtbhy@hadoop102 conf]$ vim zoo.cfg
修改添加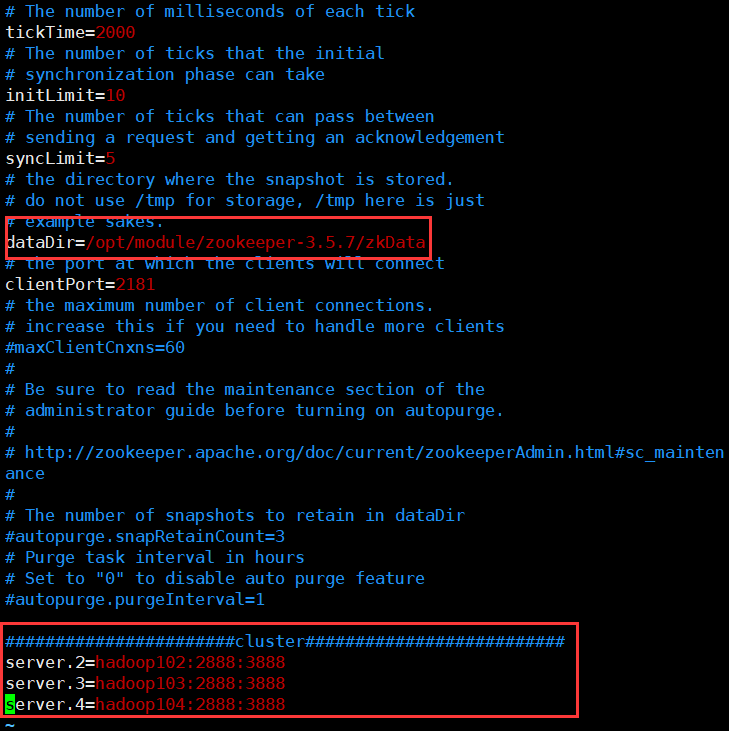
分发
[qtbhy@hadoop102 conf]$ xsync zoo.cfg
集群启动
[qtbhy@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start [qtbhy@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start [qtbhy@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start查看状态
[qtbhy@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower [qtbhy@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: leader [qtbhy@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower修改spark-env.sh文件

分发[qtbhy@hadoop102 spark-standalone]$ xsync conf/启动集群
[qtbhy@hadoop102 spark-standalone]$ sbin/start-all.sh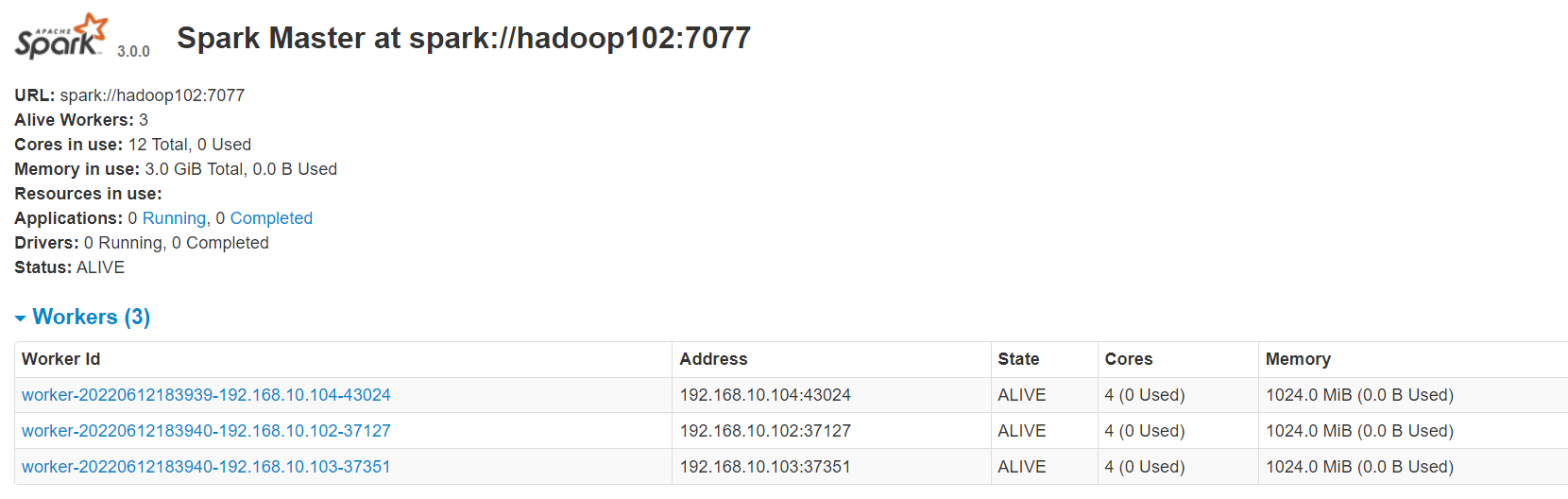
启动 hadoop103 的单独 Master 节点,此时 hadoop103 节点 Master 状态处于备用状态[qtbhy@hadoop103 spark-standalone]$ sbin/start-master.sh
测试提交[qtbhy@hadoop103 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077,hadoop103:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10停止hadoop102的Master资源监控进程
[qtbhy@hadoop102 spark-standalone]$ jps 12992 Jps 12549 Worker 12439 Master 9688 JobHistoryServer 9498 NodeManager 11914 QuorumPeerMain 9022 NameNode 5855 HistoryServer [qtbhy@hadoop102 spark-standalone]$ kill -9 12439http://hadoop102:8989/无法访问,http://hadoop103:8989/ 等一会儿变成活动状态
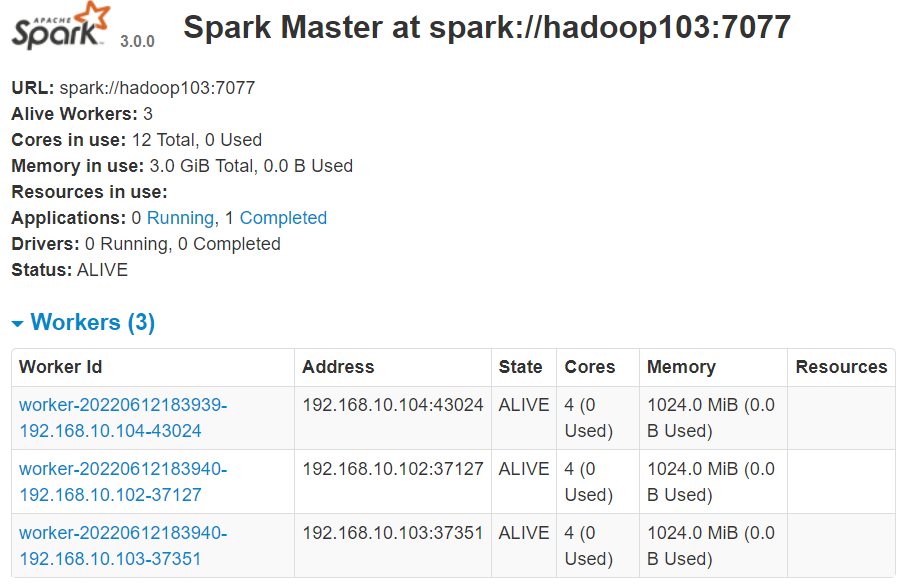
2.3 Yarn模式
解压改名
[qtbhy@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module [qtbhy@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2 spark-yarn修改配置文件
修改 hadoop 配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml, 并分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认 是 true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认 是 true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>[qtbhy@hadoop102 hadoop]$ xsync yarn-site.xml修改conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
export JAVA_HOME=/opt/module/jdk1.8.0_212 YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
启动HDFS和YARN
- 提交应用
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10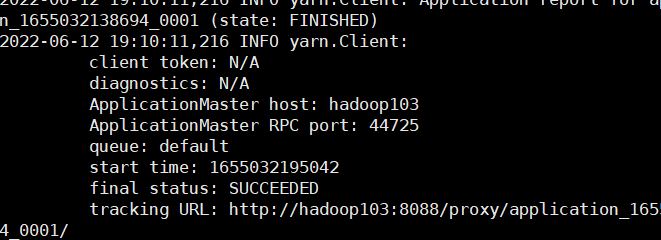
查看http://hadoop103:8088/
配置历史服务器与Standalone模式类似2.4 Windows模式
2.4.1 解压到无中文无空格的路径中
2.4.2 启动本地环境
执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境
在bin下创建一个input,input里写word.txt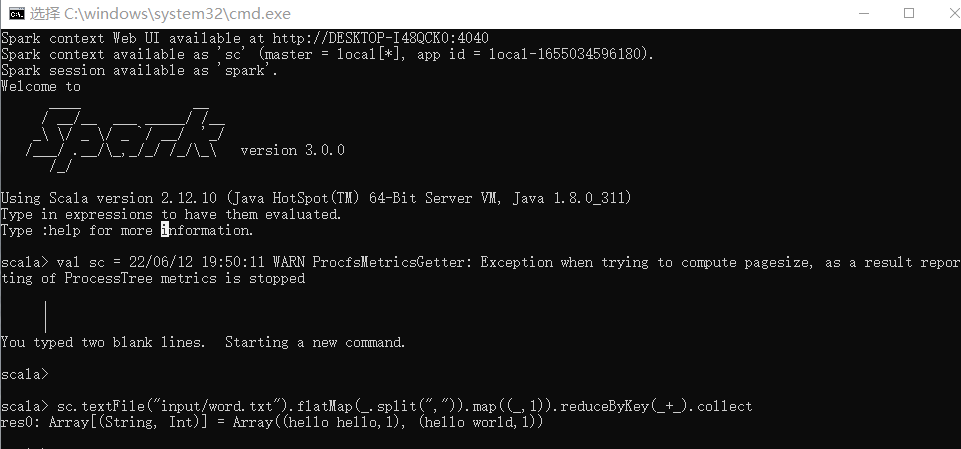
2.4.3 bin目录cmd
C:\Users\ace\Documents\software_install\spark-3.0.0-bin-hadoop3\spark-3.0.0-bin-hadoop3.2\bin>spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10

若有收获,就点个赞吧
0 人点赞
