概述
HDFS定义
Hadoop Distributed File System,是一个文件系统,用于存储文件,通过目录树定位文件。是分布式的,由很多服务器联合实现功能,集群中的服务器有各自的角色。
场景:适合一次写入,多次读出
HDFS优点
- 高容错性:数据自动保存多个副本,某一个副本丢失后,可以自动恢复
- 适合处理大数据:
- 数据规模,能够处理规模达到GB、TB、甚至PB级别的数据
- 文件规模,能够处理百万规模以上的文件数量
-
HDFS缺点
不适合低时延数据访问,比如毫秒级的存储数据
- 无法高效的对大量小文件进行存储
- 存储大量小文件会占用NameNode大量的内存存储文件目录和块信息,不可取
- 小文件存储的寻址时间会超过读取时间,违反HDFS的设计目标
- 不支持并发写入、文件随机修改

- NameNode(nn):就是Master,是一个管理者
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块(Block)映射信息
- 处理客户端读写请求
- DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作
- 存储实际的数据块
- 执行数据块的读/写操作
- Client:就是客户端
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,进行上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或写入数据
- Client提供一些命令来管理HDFS,比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作
- Secondary NameNode
- 如果寻址时间约为10ms,即查找到目标block的时间为10ms
- 寻址时间为传输时间的1%时,则为最佳状态 传输时间=10ms/0.01=1000ms=1s
- 目前磁盘的传输速率普遍为100MB/s,块大小选择128M
如果是200-300MB/s,块大小选择256M
块大小不能设置太小,也不能设置太大
- HDFS的块设置太小,会增加寻址时间,程序一致在找块的开始位置
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢
-
HDFS的Shell相关操作
基本语法
以下两个完全相同:
hadoop fs 具体命令
- hadoop dfs 具体命令
命令大全
[qtbhy@hadoop102 ~]$ hdfs dfsUsage: hadoop fs [generic options][-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>][-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...][-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>][-createSnapshot <snapshotDir> [<snapshotName>]][-deleteSnapshot <snapshotDir> <snapshotName>][-df [-h] [<path> ...]][-du [-s] [-h] [-v] [-x] <path> ...][-expunge][-find <path> ... <expression> ...][-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getfacl [-R] <path>][-getfattr [-R] {-n name | -d} [-e en] <path>][-getmerge [-nl] [-skip-empty-file] <src> <localdst>][-head <file>][-help [cmd ...]][-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>][-renameSnapshot <snapshotDir> <oldName> <newName>][-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...][-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]][-setfattr {-n name [-v value] | -x name} <path>][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] [-s <sleep interval>] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...][-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...][-touchz <path> ...][-truncate [-w] <length> <path> ...][-usage [cmd ...]]
常用命令
准备
- 启动Hadoop集群
-help输出这个命令参数,如查询rm这个命令
[qtbhy@hadoop102 ~]$ hadoop fs -help rm-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ... :Delete all files that match the specified file pattern. Equivalent to the Unixcommand "rm <src>"-f If the file does not exist, do not display a diagnostic message ormodify the exit status to reflect an error.-[rR] Recursively deletes directories.-skipTrash option bypasses trash, if enabled, and immediately deletes <src>.-safely option requires safety confirmation, if enabled, requiresconfirmation before deleting large directory with more than<hadoop.shell.delete.limit.num.files> files. Delay is expected whenwalking over large directory recursively to count the number offiles to be deleted before the confirmation.
创建/sanguo文件夹
[qtbhy@hadoop102 ~]$ hadoop fs -mkdir /sanguo
上传
-moveFromLocal:从本地剪切粘贴到HDFS
[qtbhy@hadoop102 ~]$ cd /opt/module/hadoop-3.1.3/[qtbhy@hadoop102 hadoop-3.1.3]$ vim shuguo.txt[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
本地文件没有了,传到了HDFS

-copyFromLocal:从本地文件中拷贝文件到HDFS
[qtbhy@hadoop102 hadoop-3.1.3]$ vim weiguo.txt[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
本地和HDFS中都有文件


-put:等同于copyFromLocal
[qtbhy@hadoop102 hadoop-3.1.3]$ vim wuguo.txt[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -put wuguo.txt /sanguo
-appendToFile:追加一个文件到已经存在的文件末尾
[qtbhy@hadoop102 hadoop-3.1.3]$ vim liubei.txt[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
下载
-copyToLocal:从HDFS拷贝到本地
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
-get:等同于copyToLocal

下载并改名
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt

HDFS直接操作
-ls:显示目录信息
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /

-cat:显示文件内容
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt

-chgrp、-chmod、-chown:修改文件所属权限
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -chown qtbhy:qtbhy /sanguo/shuguo.txt


-mkdir:创建路径
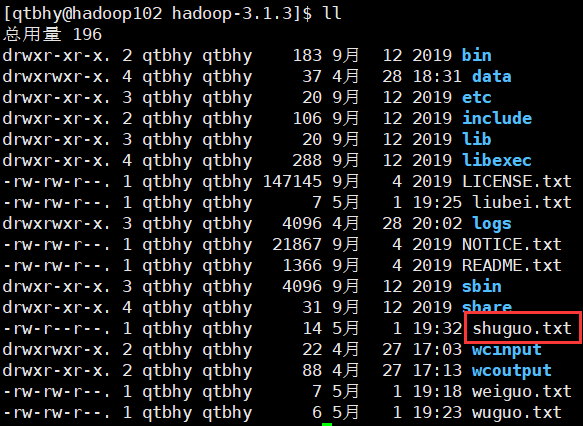
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo

-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo

-mv:在HDFS目录中移动文件
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
-tail:显示一个文件末尾1kb的数据
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt

-rm:删除文件或文件夹
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txtDeleted /sanguo/shuguo.txt
-rm -r:递归删除目录及目录里面的内容
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguoDeleted /sanguo
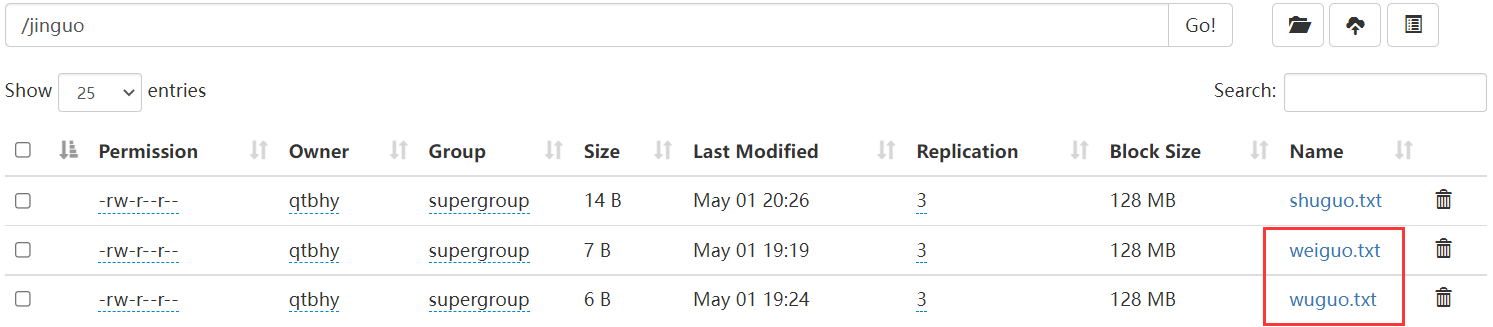
-du:统计文件夹的大小信息
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo27 81 /jinguo[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo14 42 /jinguo/shuguo.txt7 21 /jinguo/weiguo.txt6 18 /jinguo/wuguo.txt
27表示文件大小,81表示有3个副本
-setrep:设置HDFS中文件的副本数量
[qtbhy@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txtReplication 10 set: /jinguo/shuguo.txt
设置的副本数是记录在NameNode的元数据中,是否会有这么多副本,要看DataNode的数量。现在只有3台设备,最多3个副本,节点数增加到10时,副本数才能达到10
HDFS的客户端API
客户端环境准备
windows依赖文件夹

配置HADOOP_HOME环境变量
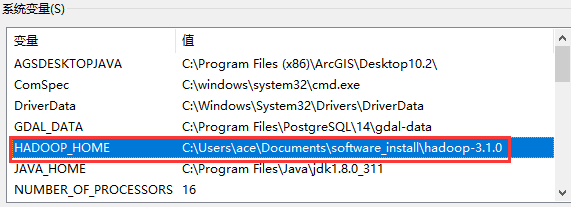
- 配置Path环境变量

在IDEA中创建一个Meaven工程,导入相应的依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies>
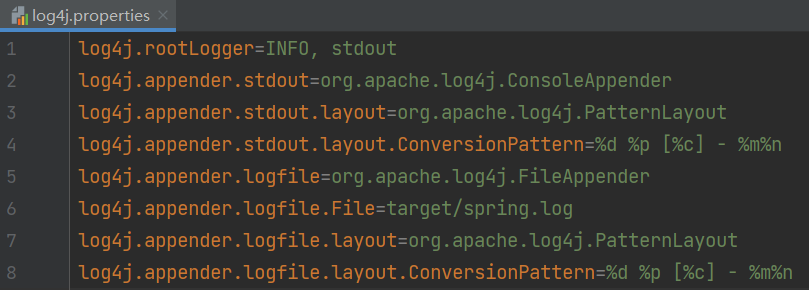
在项目的src/main/resources目录下,新建一个文件,命名为”log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%nlog4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/spring.loglog4j.appender.logfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
创建包名:com.example.hdfs
创建HdfsClient 类
public class HDFSClient {@Testpublic void testdir() throws URISyntaxException, IOException, InterruptedException {// 连接的集群namenode地址URI uri = new URI("hdfs://hadoop102:8020");// 创建一个配置文件Configuration configuration = new Configuration();// 用户String user = "qtbhy";// 1. 获取到客户端对象FileSystem fs = FileSystem.get(uri, configuration, user);// 2. 创建一个文件夹fs.mkdirs(new Path("/xiyou/huaguoshan"));// 3. 关闭资源fs.close();}}
客户端代码常用套路:
- 获取一个客户端对象
- 执行相关的操作命令
- 关闭资源
抽取公共部分
public class HDFSClient {private FileSystem fs;@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException {// 连接的集群namenode地址URI uri = new URI("hdfs://hadoop102:8020");// 创建一个配置文件Configuration configuration = new Configuration();// 用户String user = "qtbhy";// 获取到客户端对象fs = FileSystem.get(uri, configuration, user);}@Afterpublic void close() throws IOException {// 关闭资源fs.close();}@Testpublic void testdir() throws URISyntaxException, IOException, InterruptedException {// 创建一个文件夹fs.mkdirs(new Path("/xiyou/huaguoshan1"));}}
HDFS的API
HDFS文件上传
// 上传@Testpublic void testPut() throws IOException {// 参数:// 参数一:表示删除原数据// 参数二:是否允许覆盖// 参数三:原数据路径// 参数四:目的地路径fs.copyFromLocalFile(false, false, new Path("C:\\Users\\ace\\Desktop\\sunwukong.txt"), new Path("hdfs://hadoop102/xiyou/huaguoshan"));}

在resources资源目录下新建hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>

在代码中配置
@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException {// 连接的集群namenode地址URI uri = new URI("hdfs://hadoop102:8020");// 创建一个配置文件Configuration configuration = new Configuration();configuration.set("dfs.replication", "2");// 用户String user = "qtbhy";// 获取到客户端对象fs = FileSystem.get(uri, configuration, user);}

参数优先级(低————>高): hdfs-default.xml => hdfs-site.xml => 在项目资源目录下的配置文件 => 代码里面的配置
HDFS文件下载
//下载 hadoop->windows@Testpublic void testGet() throws IOException {// 参数:// 参数一:boolean delSrc 是否删除原数据// 参数二:Path src 原数据路径(HDFS)// 参数三:Path dst 目的地路径(windows)// 参数四:boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("hdfs://hadoop102/xiyou/huaguoshan"), new Path("C:\\Users\\ace\\Desktop\\"), true);}
- boolean useRawLocalFileSystem 为true时

- boolean useRawLocalFileSystem 为false时

HDFS文件删除
// 删除@Testpublic void testRm() throws IOException {// 参数:// 参数一:要删除的路径// 参数二:是否递归删除// 删除文件// fs.delete(new Path("/output/part-r-00000"), false);// 删除空目录// fs.delete(new Path("/output"), false);// 删除非空目录 非空目录要递归删除fs.delete(new Path("/xiyou"), true);}
HDFS文件更名和移动
// 文件更名和移动@Testpublic void testmv() throws IOException {// 参数:// 参数一:原文件路径// 参数二:目标文件路径// 修改文件名称// fs.rename(new Path("/jinguo/shuguo.txt"), new Path("/jinguo/shuguo111.txt"));// 文件的移动和更名// fs.rename(new Path("/jinguo/shuguo111.txt"), new Path("/shuguo.txt"));// 目录更名fs.rename(new Path("/jinguo"), new Path("/jinguoguo"));}

HDFS文件详情查看
查看文件名称、权限、长度、块信息
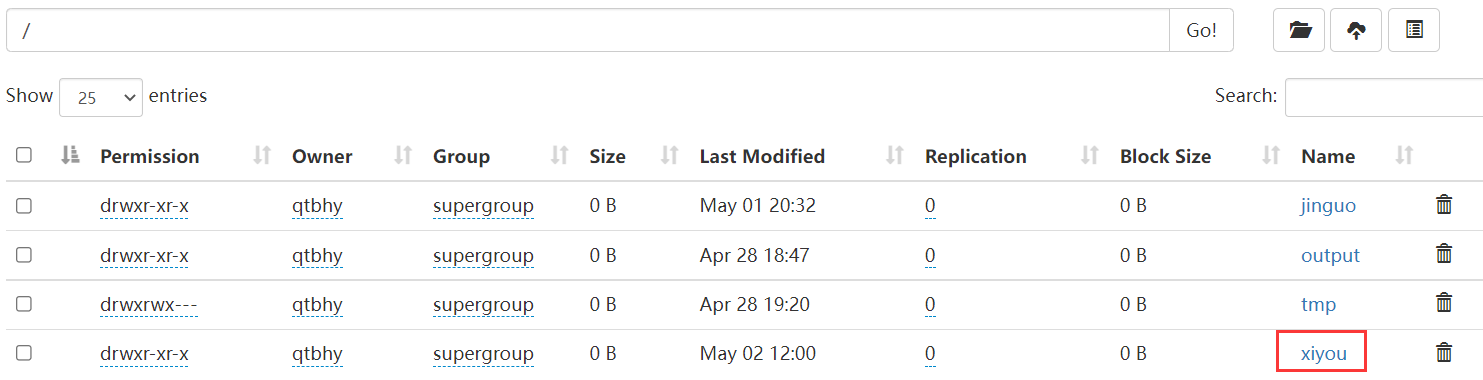
// 获取文件详情@Testpublic void fileDetail() throws IOException {// 获取所有文件信息RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);// 遍历文件while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();System.out.println("=======" + fileStatus.getPath() + "=====");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getGroup());System.out.println(fileStatus.getLen());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockSize());System.out.println(fileStatus.getPath().getName());// 获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}
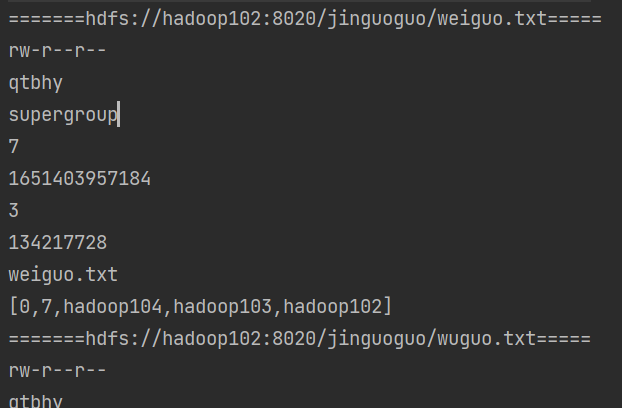
HDFS文件和文件夹判断
// 判断是文件夹还是文件@Testpublic void testFile() throws IOException {FileStatus[] fileStatuses = fs.listStatus(new Path("/"));for (FileStatus fileStatus : fileStatuses) {if (fileStatus.isFile()) {System.out.println("文件:" + fileStatus.getPath().getName());} else {System.out.println("目录:" + fileStatus.getPath().getName());}}}
HDFS的读写流程
1. HDFS写数据流程
文件写入

- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
网络拓扑-节点距离计算
HDFS在写数据的过程中,NameNode会选择距离待上传数据最近的DataNode接收数据。
节点距离=两个节点到达最近的共同祖先的距离总和
- Distance(/d1/r1/n0,/d1/r1/n0)=0 同一节点上
- Distance(/d1/r1/n1,/d1/r1/n2)=2 同一机架上的不同节点
- Distance(/d1/r2/n0,/d1/r3/n2)=4 同一数据中心不同机架上的节点
Distance(/d1/r2/n1,/d2/r4/n1)=6 不同数据中心的节点
机架感知
机架感知说明
副本数为3
一个副本放在本地节点
- 另一个副本在不同(远程)机架上
-
Hadoop3.1.3副本节点选择

第一个副本在Client所处的节点上,如果客户端在集群外,随机选一个
- 第二个副本在另一个机架的随机一个节点
- 第三个副本在第二个副本所在机架的随机节点
2. HDFS读数据流程

- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址
- 挑选一台DataNode服务器,请求读取数据
- DataNode开始传输数据给客户端,从磁盘里面读取数据输入流,以Packet为单位做校验
客户端以Packet为单位接收,先在本地缓存,然后写入目标文件
NameNode和SecondaryNameNode
1. NN和2NN工作机制
FsImage:在磁盘中备份元数据
Edits:元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中 只进行追加操作
SecondaryNamenode:用于FsImage和Edits的合并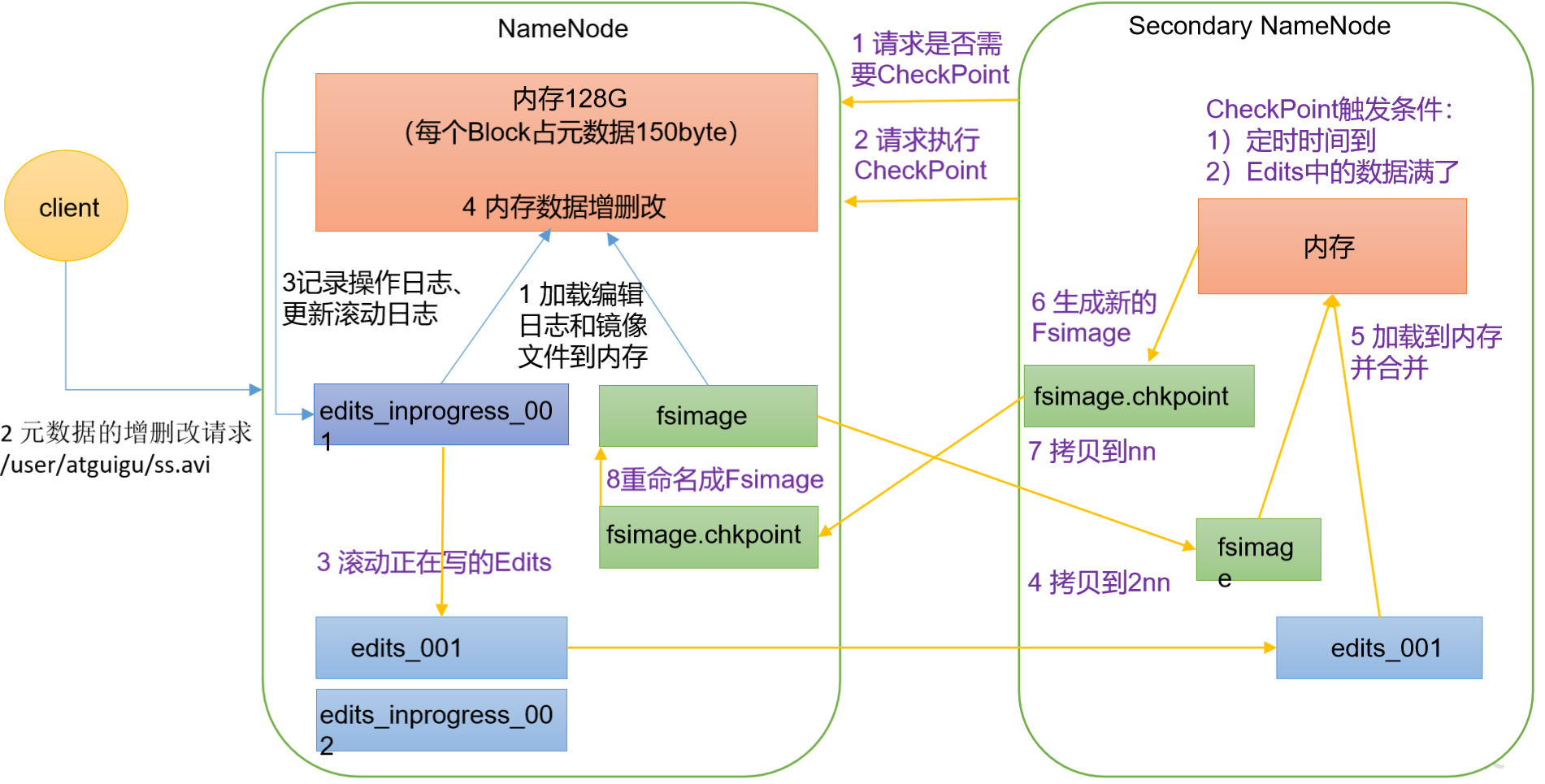
NameNode启动
- 第一次启动NameNode格式化后,创建Fsimage和Edits文件
如果不是第一次启动,直接加载编辑日志和镜像文件到内存
- 客户端对元数据进行增删改请求
- NameNode记录操作日志,更新滚动日志
- NameNode在内存中对元数据进行增删改
- Secondary NameNode工作
- Secondary NameNode询问NameNode是否需要CheckPoint
- Secondary NameNode请求执行CheckPoint
- NameNode滚动正在写的Edits日志
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并
- 生成新的镜像文件fsimage.chkpoint
- 拷贝fsimage.chkpoint到NameNode
- NameNode将fsimage.chkpoint重新命名成fsimage
2. Fsimage和Edits解析
在/opt/module/hadoop-3.1.3/data/dfs/name/current目录下:
- Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,包含HDFS文件系统的所有目录和文件inode的序列化信息
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
- seentxid文件保存的是一个数字——最后一个edits的数字
每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,可以看成NameNode启动的时候将Fsimage和Edits文件进行了合并
oiv查看Fsimage文件
基本语法:hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
[qtbhy@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000415 -o /opt/software/fsimage.xml2022-05-03 10:12:59,996 INFO offlineImageViewer.FSImageHandler: Loading 3 strings
下载到windows<?xml version="1.0"?> <fsimage><version><layoutVersion>-64</layoutVersion><onDiskVersion>1</onDiskVersion><oivRevision>ba631c436b806728f8ec2f54ab1e289526c90579</oivRevision></version> <NameSection><namespaceId>2098091923</namespaceId><genstampV1>1000</genstampV1><genstampV2>1031</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073741854</lastAllocatedBlockId><txid>415</txid></NameSection> <ErasureCodingSection> <erasureCodingPolicy> <policyId>1</policyId><policyName>RS-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema> <codecName>rs</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>2</policyId><policyName>RS-3-2-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema> <codecName>rs</codecName><dataUnits>3</dataUnits><parityUnits>2</parityUnits></ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>3</policyId><policyName>RS-LEGACY-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema> <codecName>rs-legacy</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>4</policyId><policyName>XOR-2-1-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema> <codecName>xor</codecName><dataUnits>2</dataUnits><parityUnits>1</parityUnits></ecSchema> </erasureCodingPolicy> <erasureCodingPolicy> <policyId>5</policyId><policyName>RS-10-4-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema> <codecName>rs</codecName><dataUnits>10</dataUnits><parityUnits>4</parityUnits></ecSchema> </erasureCodingPolicy> </ErasureCodingSection> <INodeSection><lastInodeId>16456</lastInodeId><numInodes>27</numInodes><inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1651495621196</mtime><permission>qtbhy:supergroup:0755</permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode> <inode><id>16386</id><type>DIRECTORY</type><name>tmp</name><mtime>1651144809945</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16387</id><type>DIRECTORY</type><name>hadoop-yarn</name><mtime>1651142540996</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16388</id><type>DIRECTORY</type><name>staging</name><mtime>1651142817316</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16389</id><type>DIRECTORY</type><name>history</name><mtime>1651142541023</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16390</id><type>DIRECTORY</type><name>done</name><mtime>1651142901288</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16391</id><type>DIRECTORY</type><name>done_intermediate</name><mtime>1651142821351</mtime><permission>qtbhy:supergroup:1777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16394</id><type>DIRECTORY</type><name>qtbhy</name><mtime>1651142817316</mtime><permission>qtbhy:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16395</id><type>DIRECTORY</type><name>.staging</name><mtime>1651144833697</mtime><permission>qtbhy:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16401</id><type>DIRECTORY</type><name>qtbhy</name><mtime>1651144880622</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16414</id><type>FILE</type><name>job_1651139062944_0002-1651142818404-qtbhy-word+count-1651142832517-1-1-SUCCEEDED-default-1651142823419.jhist</name><replication>3</replication><mtime>1651142832607</mtime><atime>1651142832581</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0770</permission><blocks><block><id>1073741834</id><genstamp>1010</genstamp><numBytes>22328</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16415</id><type>FILE</type><name>job_1651139062944_0002_conf.xml</name><replication>3</replication><mtime>1651142832641</mtime><atime>1651142832613</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0770</permission><blocks><block><id>1073741835</id><genstamp>1011</genstamp><numBytes>214468</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16416</id><type>DIRECTORY</type><name>2022</name><mtime>1651142901288</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16417</id><type>DIRECTORY</type><name>04</name><mtime>1651142901288</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16418</id><type>DIRECTORY</type><name>28</name><mtime>1651142901288</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16419</id><type>DIRECTORY</type><name>000000</name><mtime>1651144880622</mtime><permission>qtbhy:supergroup:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16425</id><type>DIRECTORY</type><name>logs</name><mtime>1651144809972</mtime><permission>qtbhy:qtbhy:1777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16426</id><type>DIRECTORY</type><name>qtbhy</name><mtime>1651144809974</mtime><permission>qtbhy:qtbhy:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16427</id><type>DIRECTORY</type><name>logs-tfile</name><mtime>1651144809978</mtime><permission>qtbhy:qtbhy:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16428</id><type>DIRECTORY</type><name>application_1651139062944_0003</name><mtime>1651144840215</mtime><permission>qtbhy:qtbhy:0770</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16441</id><type>FILE</type><name>job_1651139062944_0003-1651144809706-qtbhy-word+count-1651144832777-1-1-SUCCEEDED-default-1651144815518.jhist</name><replication>3</replication><mtime>1651144832629</mtime><atime>1651144832601</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0770</permission><blocks><block><id>1073741844</id><genstamp>1020</genstamp><numBytes>25226</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16442</id><type>FILE</type><name>job_1651139062944_0003_conf.xml</name><replication>3</replication><mtime>1651144832659</mtime><atime>1651144832636</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0770</permission><blocks><block><id>1073741845</id><genstamp>1021</genstamp><numBytes>214647</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16443</id><type>FILE</type><name>hadoop104_45015</name><replication>3</replication><mtime>1651144840211</mtime><atime>1651144840134</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:qtbhy:0640</permission><blocks><block><id>1073741846</id><genstamp>1022</genstamp><numBytes>171861</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16446</id><type>FILE</type><name>weiguo.txt</name><replication>3</replication><mtime>1651403957184</mtime><atime>1651403957058</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0644</permission><blocks><block><id>1073741848</id><genstamp>1024</genstamp><numBytes>7</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16447</id><type>FILE</type><name>wuguo.txt</name><replication>3</replication><mtime>1651404261801</mtime><atime>1651404261680</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0644</permission><blocks><block><id>1073741849</id><genstamp>1025</genstamp><numBytes>6</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> <inode><id>16448</id><type>DIRECTORY</type><name>jinguoguo</name><mtime>1651495416598</mtime><permission>qtbhy:supergroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode> <inode><id>16449</id><type>FILE</type><name>shuguo.txt</name><replication>3</replication><mtime>1651407981262</mtime><atime>1651407981126</atime><preferredBlockSize>134217728</preferredBlockSize><permission>qtbhy:supergroup:0644</permission><blocks><block><id>1073741850</id><genstamp>1027</genstamp><numBytes>14</numBytes></block> </blocks> <storagePolicyId>0</storagePolicyId></inode> </INodeSection> <INodeReferenceSection></INodeReferenceSection><SnapshotSection><snapshotCounter>0</snapshotCounter><numSnapshots>0</numSnapshots></SnapshotSection> <INodeDirectorySection><directory><parent>16385</parent><child>16448</child><child>16449</child><child>16386</child></directory> <directory><parent>16386</parent><child>16387</child><child>16425</child></directory> <directory><parent>16387</parent><child>16388</child></directory> <directory><parent>16388</parent><child>16389</child><child>16394</child></directory> <directory><parent>16389</parent><child>16390</child><child>16391</child></directory> <directory><parent>16390</parent><child>16416</child></directory> <directory><parent>16391</parent><child>16401</child></directory> <directory><parent>16394</parent><child>16395</child></directory> <directory><parent>16416</parent><child>16417</child></directory> <directory><parent>16417</parent><child>16418</child></directory> <directory><parent>16418</parent><child>16419</child></directory> <directory><parent>16419</parent><child>16414</child><child>16415</child><child>16441</child><child>16442</child></directory> <directory><parent>16425</parent><child>16426</child></directory> <directory><parent>16426</parent><child>16427</child></directory> <directory><parent>16427</parent><child>16428</child></directory> <directory><parent>16428</parent><child>16443</child></directory> <directory><parent>16448</parent><child>16446</child><child>16447</child></directory> </INodeDirectorySection> <FileUnderConstructionSection></FileUnderConstructionSection> <SecretManagerSection><currentId>0</currentId><tokenSequenceNumber>0</tokenSequenceNumber><numDelegationKeys>0</numDelegationKeys><numTokens>0</numTokens></SecretManagerSection><CacheManagerSection><nextDirectiveId>1</nextDirectiveId><numDirectives>0</numDirectives><numPools>0</numPools></CacheManagerSection> </fsimage>Fsimage中没有记录块所对应DataNode,在集群启动后,DataNode上报数据块信息,并隔一段时间后再次上报。
oev查看Edits文件
基本语法:hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
[qtbhy@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000416-0000000000000000417 -o /opt/software/edits.xml
3. CheckPoint时间设置
默认SecondaryNameNode每隔一小时执行一次
<property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property>一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次 ```xml
dfs.namenode.checkpoint.txns 1000000 操作动作次数
<a name="pzvlZ"></a>
# Datanode工作机制
<a name="krweC"></a>
## 1. DataNode工作机制
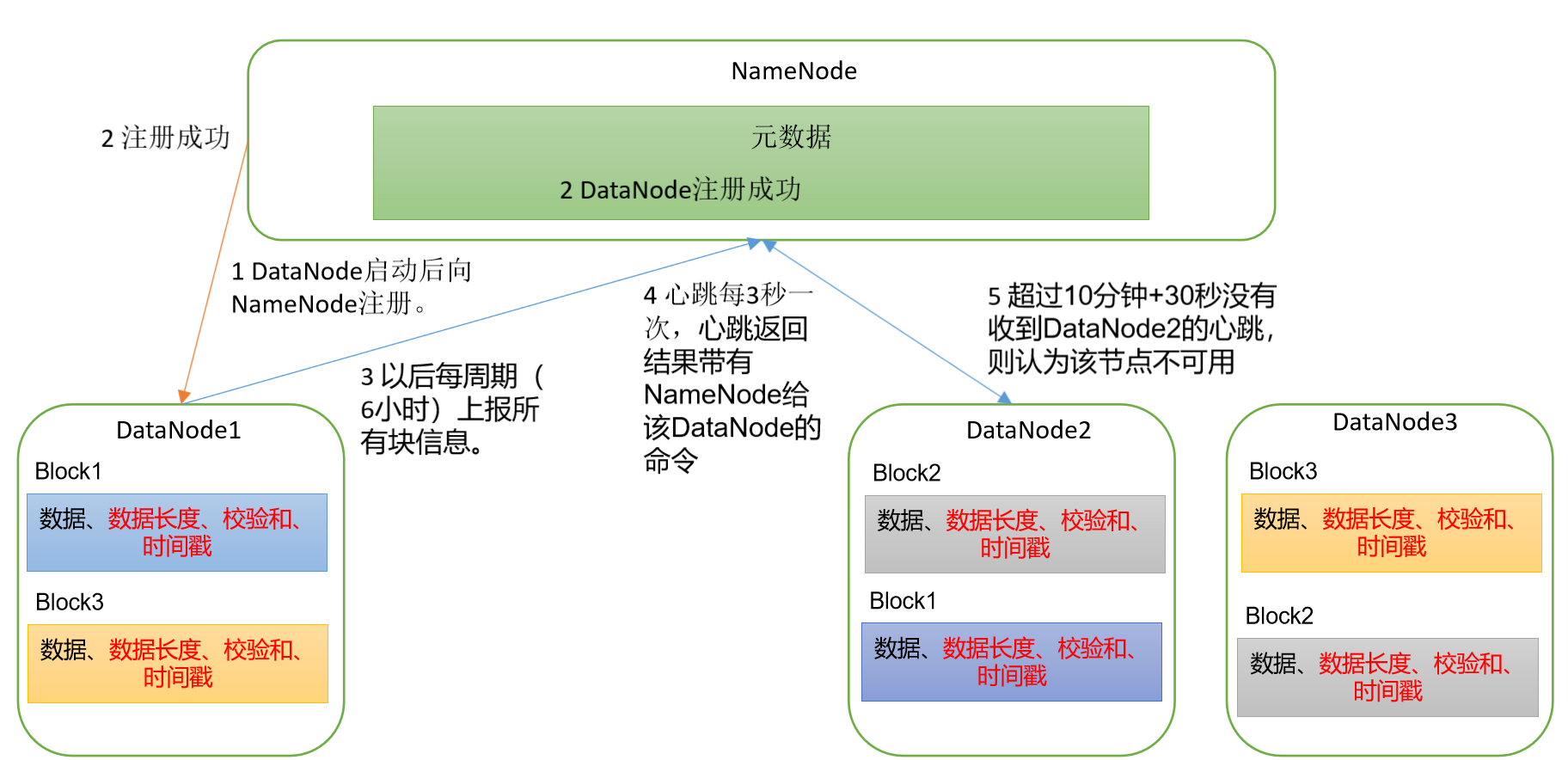<br />(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件:数据、元数据包括数据块的长度,块数据的校验和,时间戳<br />(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息<br />DN向NN汇报当前解读信息的时间间隔,默认6小时xml
DN扫描自己节点块信息列表的时间,默认6小时xml
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据库。<br />如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用<br />(4)集群运行中可以安全加入和退出一些机器
<a name="DI5Xw"></a>
## 2. 数据完整性
DataNode节点保证数据完整性的方法:
1. 当DataNode读取Block时,计算CheckSum
1. 如果计算后的CheckSum,与Block创建时值不一样,说明Block损坏
1. Client读取其他DataNode上的Block
1. 常见的校验算法crc(32),md5(128),sha1(160)
1. DataNode在其文件创建后周期验证CheckSum
<a name="ijuq3"></a>
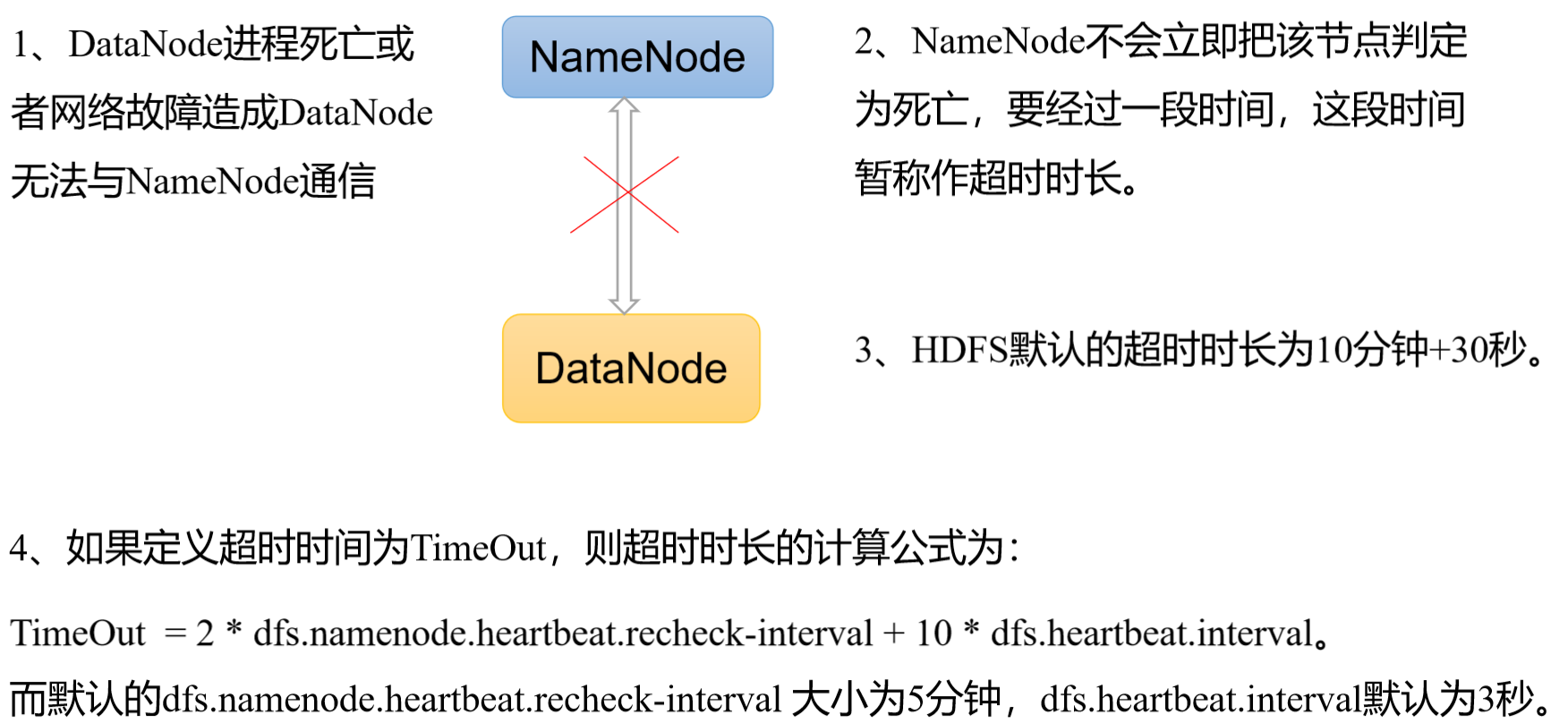
## 3. 掉线时限参数设置
xml

若有收获,就点个赞吧
0 人点赞
