学习链接:https://www.bilibili.com/video/BV1Qp4y1n7EN?spm_id_from=333.999.0.0
1. 概念
1.1 大数据概念
大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决海量数据的采集、存储和分析计算问题。
数据存储单位:bit Byte KB MB GB TB PB EB ZB YB BB NB DB
1Byte = 8bit 1K = 1024Byte 1MB = 1024K 1G = 1024M 1T = 1024G 1P = 1024T
1.2 大数据特点 4V
- Volumn 大量
- Velocity 高速
- Variety 多样
相比于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据包括网络日志、音频、视频、图片、地理位置信息等越来越多
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
- Cloudera内部集成了很多大数据框架,对应产品CDH
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
- Hortonworks文档较好,对应产品HDP
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
2.3 Hadoop优势
- 高可靠性:Hadoop底层维护多个数据副本,某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点
- 高效性:在MapReduce思想下,Hadoop是并行工作的,以加快任务处理速度
- 高容错性:能够自动将失败的任务重新分配
2.4 Hadoop组成
Hadoop1.x 2.x 3.x区别
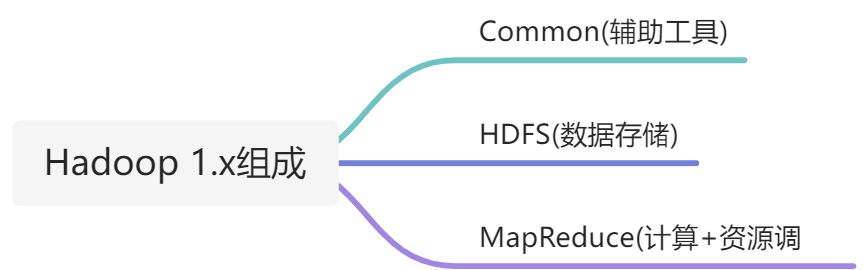
- Hadoop1.x
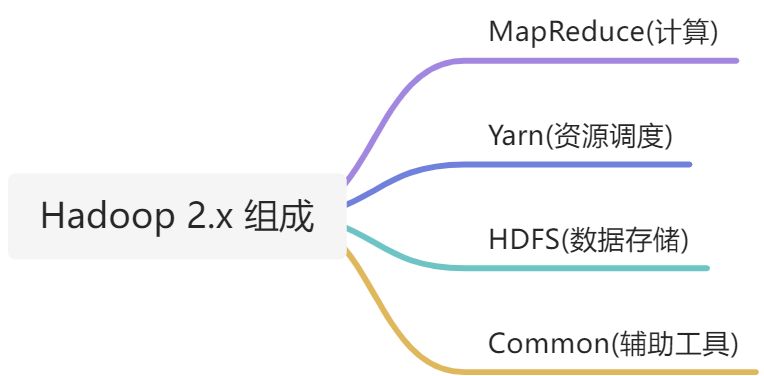
- Hadoop 2.x
-
HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统
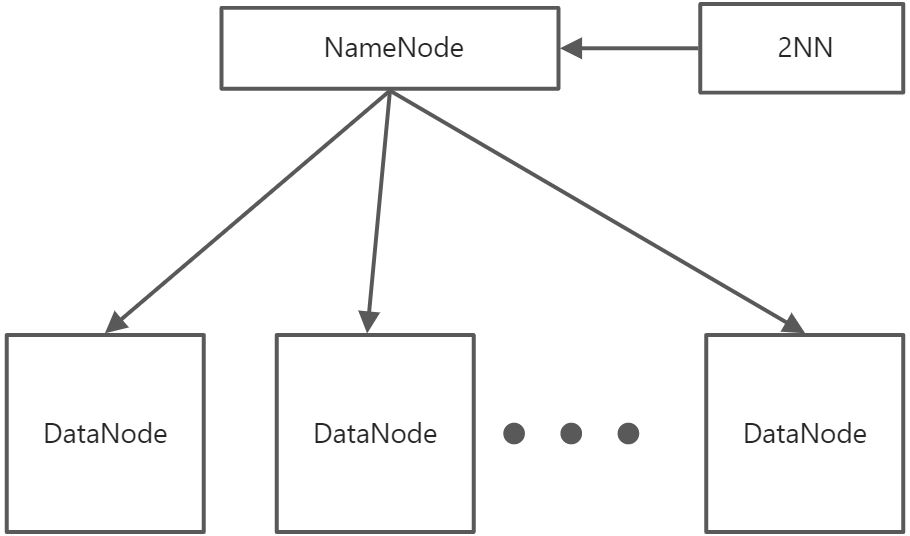
NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份
YARN架构概述
Yet Another Resource Negotiator 简称YARN,另一种资源协调者,是Hadoop的资源管理器

客户端可以有多个
- 集群上可以运行多个ApplicationMaster
- 每个NodeManager上可以有多个Container
MapReduce架构概述
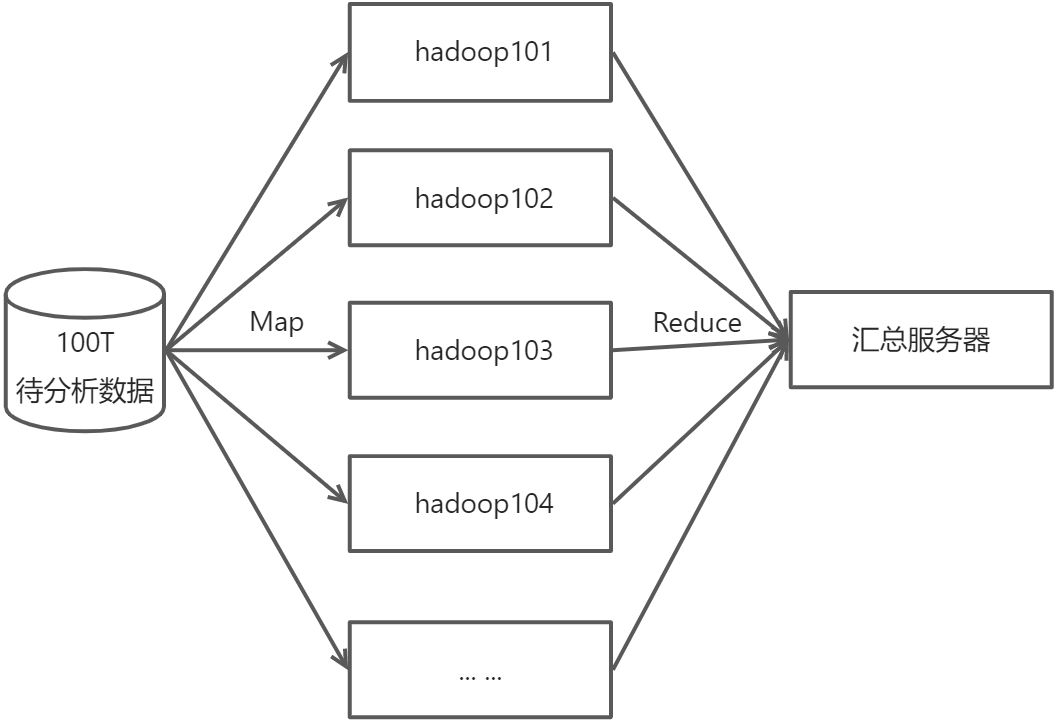
HDFS、YARN、MapReduce三者关系

2.5 大数据生态系统


若有收获,就点个赞吧
0 人点赞
