学习链接:https://www.bilibili.com/video/BV11A411L7CK?spm_id_from=333.999.0.0
1 Spark是什么
一种基于内存的快速、通用、可扩展的大数据分析计算引擎(没有存储)
2 Spark and Hadoop
Hadoop
- Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
- 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的数据,支持着 Hadoop 的所有服务
- MapReduce是一种编程模式,作为Hadoop的分布式计算模型,是Hadoop的核心
- HBase是一个基于HDFS的分布式数据库,擅长实时地随机读、写超大规模数据集,是Hadoop非常重要的组件
Hadoop是一次性数据计算
一次性数据计算:框架在处理数据的时候,会从存储设备中读取数据,进行逻辑操作,然后将处理的结果重新存储到介质中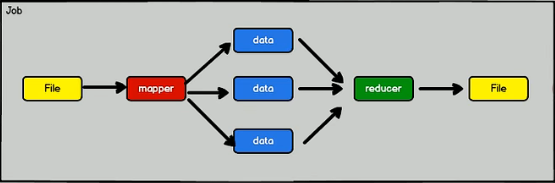
hadoop的作业提交流程是从磁盘拉取数据作为输入数据,处理结束后重新写入磁盘,如果需要多个job串联——一个job的输出作为另一个job的输入,那么hadoop就需要进行频繁的磁盘交互
Spark
- Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core中提供了Spark最基础与最核心的功能
- Spark SQL是Spark用来操作结构化数据的组件
- Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API

Spark把job的处理结果放到内存中,为下一次job的使用提供了遍历,带来的问题是Spark基于内存,由于内存的限制,会由于内存资源不足导致Job执行失败,所以MapReduce不能完全被Spark替代
:::info
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘
:::
3 Spark核心模块

- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的
- Spark SQL
Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
- Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。

若有收获,就点个赞吧
0 人点赞
