背景
测试环境,k8s集群部署在3个节点的虚拟机服务器上;需要收集集群中pod日志。
创建 Elasticsearch 集群
创建命名空间
$ kubectl create -f kube-logging.yamlapiVersion: v1kind: Namespacemetadata:name: logging
创建了一个命名空间来存放我们的日志相关资源,接下来可以部署 EFK 相关组件,由于在测试环境,首先开始部署一个单节点的 Elasticsearch 。
创建elasticsearch service 服务
$ kubectl create -f elasticsearch-svc.yamlkind: ServiceapiVersion: v1metadata:name: elasticsearchnamespace: logginglabels:app: elasticsearchspec:selector:app: elasticsearchclusterIP: Noneports:- port: 9200name: rest- port: 9300name: inter-node
在测试环境中k8s集群部署在3个虚拟机上,为了数据能够落盘,但是没有可用的磁盘可以挂载,我们只有选择使用本地文件目录local persistent volume,具体创建过程参考本文
$ kubectl get svc -n loggingNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEelasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 27h
我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.logging.svc.cluster.local,接下来我们通过 StatefulSet 来创建具体的 Elasticsearch 的 Pod 应用。
Kubernetes StatefulSet 允许我们为 Pod 分配一个稳定的标识和持久化存储,Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以需要使用 StatefulSet 来管理 Pod。
创建Elasticsearch StatefulSet 服务
创建数据目录
本文采用的是虚拟机创建的k8s集群,所有的存储使用本地存储,数据存放到集群中一台node节点上,因此创建本地存储之前,需要先行在对应节点上创建数据目录
#ssh k8s-worker-node1mkidr -p /data/elasticsearchchmod 777 /data/elasticsearch -R
创建本地PersistentVolume存储
apiVersion: v1kind: PersistentVolumemetadata:name: es-pvspec:capacity:storage: 10GivolumeMode: FilesystemaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: DeletestorageClassName: local-storagelocal:path: /data/elasticsearchnodeAffinity:required:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- k8s-worker-node1
node打标签
由于我们的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,部署时pod不会被调度到master节点上,我们可以给node打标签来解决这个问题,来选择将pod部署到哪个node节点上。
#查询集群节点服务器的labels$ kubectl get node --show-labels#根据下面完整的statefulset文件中可以看出nodeSelector会调度到es=log的节点上.....spec:nodeSelector:es: log.....#因此我们需要给node节点添加标签label#kubectl label nodes <node-name> <label-key>=<label-value>$ kubectl label nodes k8s-worker-node2 es=log
创建statefulset
完整的 Elasticsearch StatefulSet 资源清单文件内容如下:
elasticsearch-statefulset.yamlapiVersion: apps/v1kind: StatefulSetmetadata:name: esnamespace: loggingspec:serviceName: elasticsearchreplicas: 1 #线上最好3个或着奇数个selector:matchLabels:app: elasticsearchtemplate:metadata:labels:app: elasticsearchspec:nodeSelector:es: loginitContainers:- name: increase-vm-max-mapimage: busyboxcommand: ["sysctl", "-w", "vm.max_map_count=262144"]securityContext:privileged: true- name: increase-fd-ulimitimage: busyboxcommand: ["sh", "-c", "ulimit -n 65536"]securityContext:privileged: truecontainers:- name: elasticsearchimage: docker.elastic.co/elasticsearch/elasticsearch:7.6.2ports:- name: restcontainerPort: 9200- name: intercontainerPort: 9300resources:limits:cpu: 1000mrequests:cpu: 1000mvolumeMounts:- name: datamountPath: /usr/share/elasticsearch/dataenv:- name: cluster.namevalue: k8s-logs- name: node.namevalueFrom:fieldRef:fieldPath: metadata.name- name: cluster.initial_master_nodesvalue: "es-0" #由于测试环境,这里只选择一个es- name: discovery.zen.minimum_master_nodesvalue: "1" #线上环境设置为2- name: discovery.seed_hostsvalue: "elasticsearch"- name: ES_JAVA_OPTSvalue: "-Xms512m -Xmx512m"- name: network.hostvalue: "0.0.0.0"volumeClaimTemplates:- metadata:name: datalabels:app: elasticsearchspec:accessModes: [ "ReadWriteOnce" ]storageClassName: local-storageresources:requests:storage: 10Gi
我们这里使用 volumeClaimTemplates 来定义持久化模板,Kubernetes 会使用它为 Pod 创建 PersistentVolume,设置访问模式为ReadWriteOnce,这意味着它只能被 mount 到单个节点上进行读写,然后最重要的是使用了一个 StorageClass 对象,这里我们就直接使用前面创建的 本地pv 类型的名为local-storage对象即可。
最后,我们指定了每个 PersistentVolume 的大小为 10GB,我们可以根据自己的实际需要进行调整该值。
- cluster.name:Elasticsearch 集群的名称,我们这里命名成 k8s-logs。node.name:节点的名称,通过 metadata.name 来获取。这将解析为 es-[0,1,2],取决于节点的指定顺序。
- discovery.seed_hosts:此字段用于设置在 Elasticsearch 集群中节点相互连接的发现方法。由于我们之前配置的无头服务,我们的 Pod 具有唯一的 DNS 域es-[0,1,2].elasticsearch.logging.svc.cluster.local,因此我们相应地设置此变量。
- discovery.zen.minimum_master_nodes:我们将其设置为(N/2) + 1,N是我们的群集中符合主节点的节点的数量。如果线上有3个 Elasticsearch 节点,因此我们将此值设置为2(向下舍入到最接近的整数)。
- ES_JAVA_OPTS:这里我们设置为-Xms512m -Xmx512m,告诉JVM使用512 MB的最小和最大堆。应该根据群集的资源可用性和需求调整这些参数。
直接使用kubectl工具部署即可
$ kubectl create -f elasticsearch-statefulset.yaml
添加成功后,可以看到logging命名空间下所有的资源
$ kubectl get sts -n loggingNAME READY AGEes 0/1 2m21s$ kubectl get pods -n loggingNAME READY STATUS RESTARTS AGEes-0 0/1 Pending 0 2m31s
创建 Kibana 服务
Elasticsearch 集群启动成功了,接下来我们可以来部署 Kibana 服务,新建一个名为 kibana.yaml 的文件,对应的文件内容如下:
apiVersion: v1kind: Servicemetadata:name: kibananamespace: logginglabels:app: kibanaspec:ports:- port: 5601type: NodePortselector:app: kibana---apiVersion: apps/v1kind: Deploymentmetadata:name: kibananamespace: logginglabels:app: kibanaspec:selector:matchLabels:app: kibanatemplate:metadata:labels:app: kibanaspec:nodeSelector:es: logcontainers:- name: kibanaimage: docker.elastic.co/kibana/kibana:7.6.2resources:limits:cpu: 1000mrequests:cpu: 1000menv:- name: ELASTICSEARCH_HOSTSvalue: http://elasticsearch:9200ports:- containerPort: 5601
上面我们定义了两个资源对象,一个 Service 和 Deployment,为了测试方便,我们将 Service 设置为了 NodePort 类型,Kibana Pod 中配置都比较简单,唯一需要注意的是我们使用 ELASTICSEARCH_HOSTS 这个环境变量来设置Elasticsearch 集群的端点和端口,直接使用 Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch,由于是一个 headless service,所以该域将解析为 Elasticsearch Pod 的 IP 地址列表。
配置完成后,直接使用 kubectl 工具创建:
$ kubectl create -f kibana.yamlservice/kibana createddeployment.apps/kibana created
创建完成后,可以查看 Kibana Pod 的运行状态:
kubectl get pod,svc -n loggingNAME READY STATUS RESTARTS AGEpod/es-0 1/1 Running 0 82mpod/kibana-7dc465fbc8-hh95t 1/1 Running 0 83sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 28hservice/kibana NodePort 10.96.49.149 <none> 5601:49609/TCP 28m
如果部署过程中出现imagePullBackOff的情况,可以手动拉下镜像保存到本地镜像仓库,然后替换kibana.yaml镜像即可。
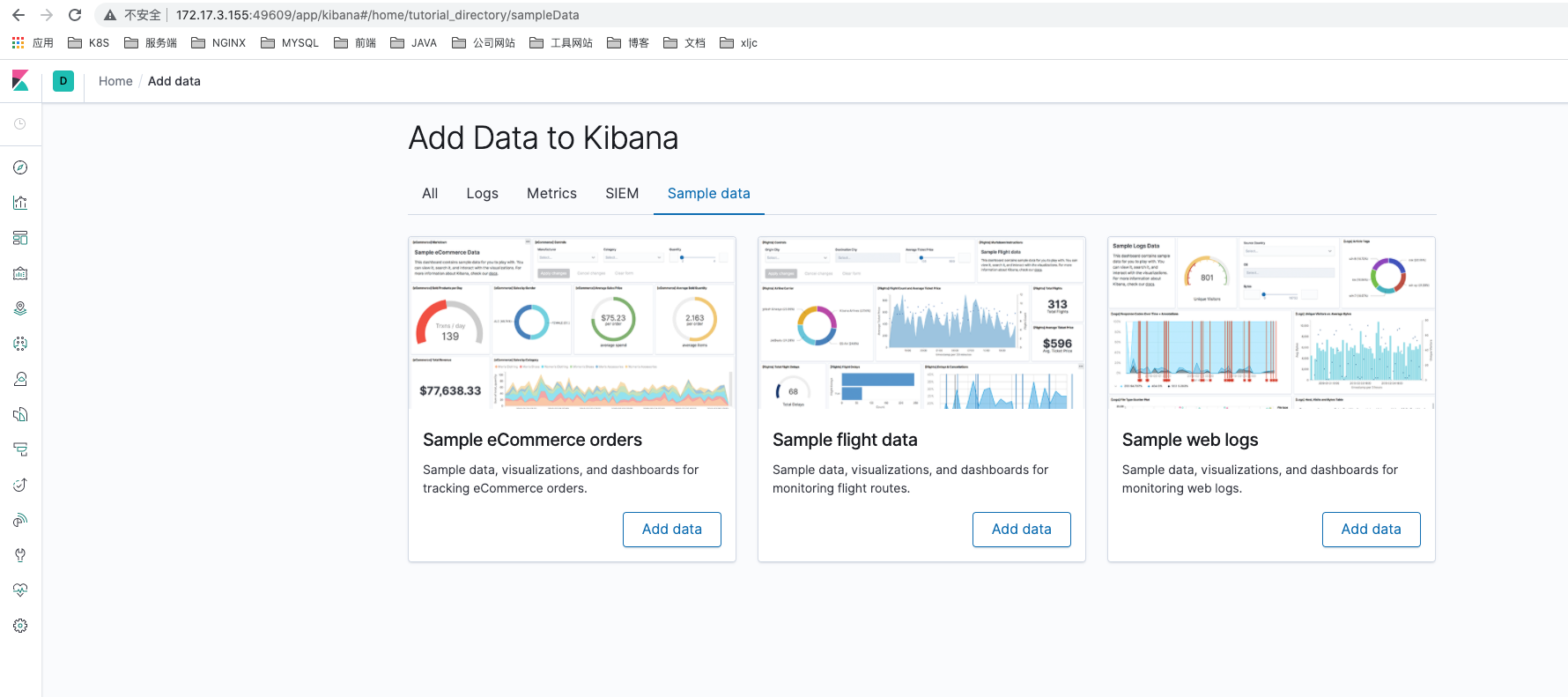
如果 Pod 已经是 Running 状态了,证明应用已经部署成功了,然后可以通过 NodePort 来访问 Kibana 这个服务,在浏览器中打开http://<任意节点IP>:49609即可,如果看到如下界面证明 Kibana 已经成功部署到了 Kubernetes集群之中。
部署 Fluentd

Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具。
工作原理
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。
主要运行步骤如下:
首先 Fluentd 从多个日志源获取数据;
结构化并且标记这些数据;
然后根据匹配的标签将数据发送到多个目标服务去。

配置
一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的,下面简单和大家介绍下 Fluentd 的配置方法。
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>@id fluentd-containers.log@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址pos_file /var/log/es-containers.log.postag raw.kubernetes.* # 设置日志标签read_from_head true<parse> # 多行格式化成JSON@type multi_format # 使用 multi-format-parser 解析器插件<pattern>format json # JSON 解析器time_key time # 指定事件时间的时间字段time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式</pattern><pattern>format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/time_format %Y-%m-%dT%H:%M:%S.%N%:z</pattern></parse></source>
上面配置部分参数说明如下:
id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
type:Fluentd 内置的指令,tail 表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是 http 表示通过一个 GET 请求来收集数据。
path:tail 类型下的特定参数,告诉 Fluentd 采集 /var/log/containers 目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。
pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **>@id elasticsearch@type elasticsearch@log_level infoinclude_tag_key truetype_name fluentdhost "#{ENV['OUTPUT_HOST']}"port "#{ENV['OUTPUT_PORT']}"logstash_format true<buffer>@type filepath /var/log/fluentd-buffers/kubernetes.system.bufferflush_mode intervalretry_type exponential_backoffflush_thread_count 2flush_interval 5sretry_foreverretry_max_interval 30chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"overflow_action block</buffer>
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成**。
- id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成 info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。
- host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为 true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。
- Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
过滤
由于 Kubernetes 集群中应用太多,也还有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示:
# 删除无用的属性<filter kubernetes.**>@type record_transformerremove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash</filter># 只保留具有logging=true标签的Pod日志<filter kubernetes.**>@id filter_log@type grep<regexp>key $.kubernetes.labels.loggingpattern ^true$</regexp></filter>
安装
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
fluentd配置文件
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
kind: ConfigMapapiVersion: v1metadata:name: fluentd-confignamespace: loggingdata:system.conf: |-<system>root_dir /tmp/fluentd-buffers/</system>containers.input.conf: |-<source>@id fluentd-containers.log@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址pos_file /var/log/es-containers.log.postag raw.kubernetes.* # 设置日志标签read_from_head true<parse> # 多行格式化成JSON@type multi_format # 使用 multi-format-parser 解析器插件<pattern>format json # JSON解析器time_key time # 指定事件时间的时间字段time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式</pattern><pattern>format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/time_format %Y-%m-%dT%H:%M:%S.%N%:z</pattern></parse></source># 在日志输出中检测异常,并将其作为一条日志转发# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions<match raw.kubernetes.**> # 匹配tag为raw.kubernetes.**日志信息@id raw.kubernetes@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息remove_tag_prefix raw # 移除 raw 前缀message logstream streammultiline_flush_interval 5max_bytes 500000max_lines 1000</match><filter **> # 拼接日志@id filter_concat@type concat # Fluentd Filter 插件,用于连接多个事件中分隔的多行日志。key messagemultiline_end_regexp /\n$/ # 以换行符“\n”拼接separator ""</filter># 添加 Kubernetes metadata 数据<filter kubernetes.**>@id filter_kubernetes_metadata@type kubernetes_metadata</filter># 修复 ES 中的 JSON 字段# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser<filter kubernetes.**>@id filter_parser@type parser # multi-format-parser多格式解析器插件key_name log # 在要解析的记录中指定字段名称。reserve_data true # 在解析结果中保留原始键值对。remove_key_name_field true # key_name 解析成功后删除字段。<parse>@type multi_format<pattern>format json</pattern><pattern>format none</pattern></parse></filter># 删除一些多余的属性<filter kubernetes.**>@type record_transformerremove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash</filter># 只保留具有logging=true标签的Pod日志<filter kubernetes.**>@id filter_log@type grep<regexp>key $.kubernetes.labels.loggingpattern ^true$</regexp></filter>###### 监听配置,一般用于日志聚合用 ######forward.input.conf: |-# 监听通过TCP发送的消息<source>@id forward@type forward</source>output.conf: |-<match **>@id elasticsearch@type elasticsearch@log_level infoinclude_tag_key truehost elasticsearchport 9200logstash_format truelogstash_prefix k8s # 设置 index 前缀为 k8srequest_timeout 30s<buffer>@type filepath /var/log/fluentd-buffers/kubernetes.system.bufferflush_mode intervalretry_type exponential_backoffflush_thread_count 2flush_interval 5sretry_foreverretry_max_interval 30chunk_limit_size 2Mqueue_limit_length 8overflow_action block</buffer></match>
fluentd-daemonset配置
上面配置文件中我们只配置了 docker 容器日志目录,收集到数据经过处理后发送到 elasticsearch:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1kind: ServiceAccountmetadata:name: fluentd-esnamespace: logginglabels:k8s-app: fluentd-eskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcile---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: fluentd-eslabels:k8s-app: fluentd-eskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups:- ""resources:- "namespaces"- "pods"verbs:- "get"- "watch"- "list"---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata:name: fluentd-eslabels:k8s-app: fluentd-eskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilesubjects:- kind: ServiceAccountname: fluentd-esnamespace: loggingapiGroup: ""roleRef:kind: ClusterRolename: fluentd-esapiGroup: ""---apiVersion: apps/v1kind: DaemonSetmetadata:name: fluentd-esnamespace: logginglabels:k8s-app: fluentd-eskubernetes.io/cluster-service: "true"addonmanager.kubernetes.io/mode: Reconcilespec:selector:matchLabels:k8s-app: fluentd-estemplate:metadata:labels:k8s-app: fluentd-eskubernetes.io/cluster-service: "true"# 此注释确保如果节点被驱逐,fluentd不会被驱逐,支持关键的基于 pod 注释的优先级方案。annotations:scheduler.alpha.kubernetes.io/critical-pod: ''spec:serviceAccountName: fluentd-escontainers:- name: fluentd-esimage: quay.io/fluentd_elasticsearch/fluentd:v3.0.1env:- name: FLUENTD_ARGSvalue: --no-supervisor -qresources:limits:memory: 500Mirequests:cpu: 100mmemory: 200MivolumeMounts:- name: varlogmountPath: /var/log- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: true- name: config-volumemountPath: /etc/fluent/config.dnodeSelector:beta.kubernetes.io/fluentd-ds-ready: "true"tolerations:- operator: ExiststerminationGracePeriodSeconds: 30volumes:- name: varloghostPath:path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containers- name: config-volumeconfigMap:name: fluentd-config
节点打标签
我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中,另外为了能够灵活控制哪些节点的日志可以被收集,所以我们这里还添加了一个 nodSelector 属性:
nodeSelector:beta.kubernetes.io/fluentd-ds-ready: "true"
意思就是要想采集节点的日志,那么我们就需要给节点打上上面的标签
#给node节点添加标签label#kubectl label nodes <node-name> <label-key>=<label-value>kubectl label nodes node名 beta.kubernetes.io/fluentd-ds-ready=true
注意:如果我们不想采集master节点上的日志我们可以给master节点打污点。
安装fluentd
分别创建上面的 ConfigMap 对象和 DaemonSet:
$ kubectl create -f fluentd-configmap.yamlconfigmap "fluentd-config" created$ kubectl create -f fluentd-daemonset.yamlserviceaccount "fluentd-es" createdclusterrole.rbac.authorization.k8s.io "fluentd-es" createdclusterrolebinding.rbac.authorization.k8s.io "fluentd-es" createddaemonset.apps "fluentd-es" created
创建完成后,查看对应的 Pods 列表,检查是否部署成功:
$ kubectl get pod -n loggingNAME READY STATUS RESTARTS AGEes-0 1/1 Running 0 156mfluentd-es-lhjnr 1/1 Running 0 53sfluentd-es-tpmlk 1/1 Running 0 64skibana-7dc465fbc8-hh95t 1/1 Running 0 75m
Fluentd 启动成功后,这个时候就可以发送日志到 ES 了,但是我们这里是过滤了只采集具有 logging=true 标签的 Pod 日志,所以现在还没有任何数据会被采集。
测试
下面我们部署一个简单的测试应用, 新建 counter.yaml 文件,文件内容如下:
apiVersion: v1kind: Podmetadata:name: counterlabels:logging: "true" # 一定要具有该标签才会被采集spec:containers:- name: countimage: busyboxargs: [/bin/sh, -c,'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
该 Pod 只是简单将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,使用 kubectl 工具创建该 Pod:
$ kubectl create -f counter.yaml$ kubectl get podsNAME READY STATUS RESTARTS AGEcounter 1/1 Running 0 9h
Pod 创建并运行后,回到 Kibana Dashboard 页面,点击左侧最下面的 management 图标,然后点击 Kibana 下面的 Index Patterns 开始导入索引数据:
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,定义了一个 k8s 的前缀,所以这里只需要在文本框中输入k8s-*即可匹配到 Elasticsearch 集群中采集的 Kubernetes 集群日志数据,然后点击下一步,进入以下页面: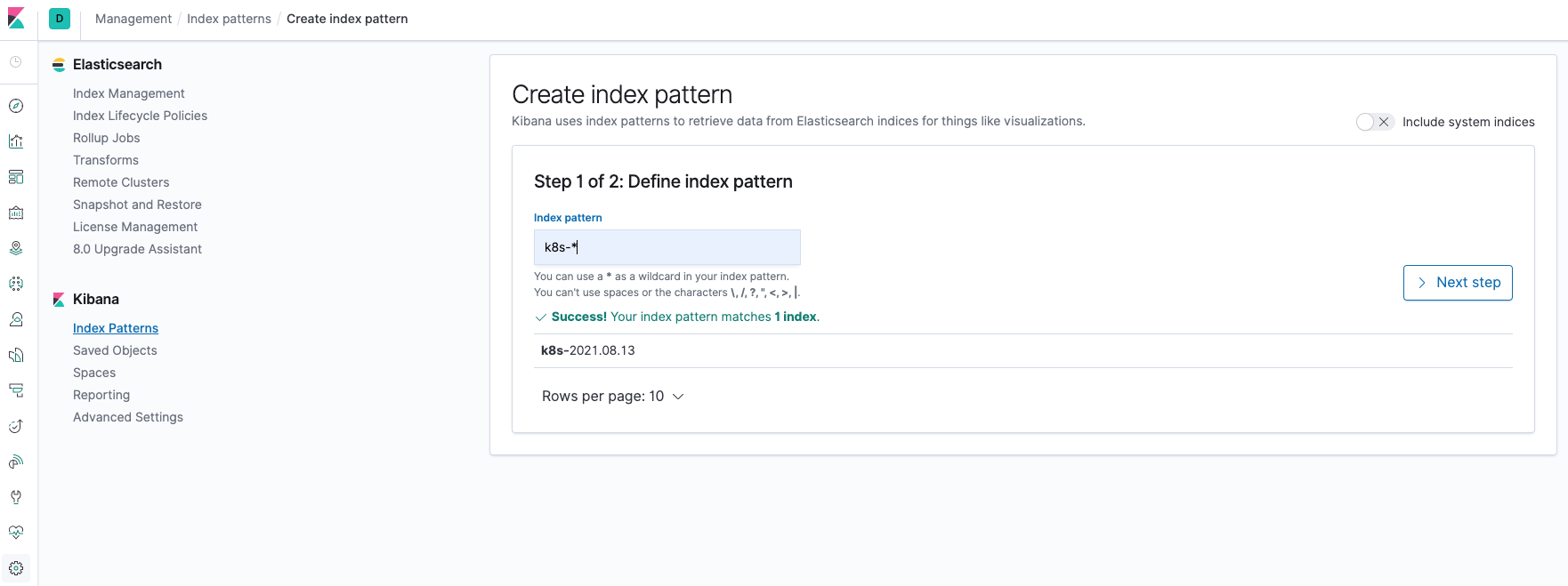
在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击Create index pattern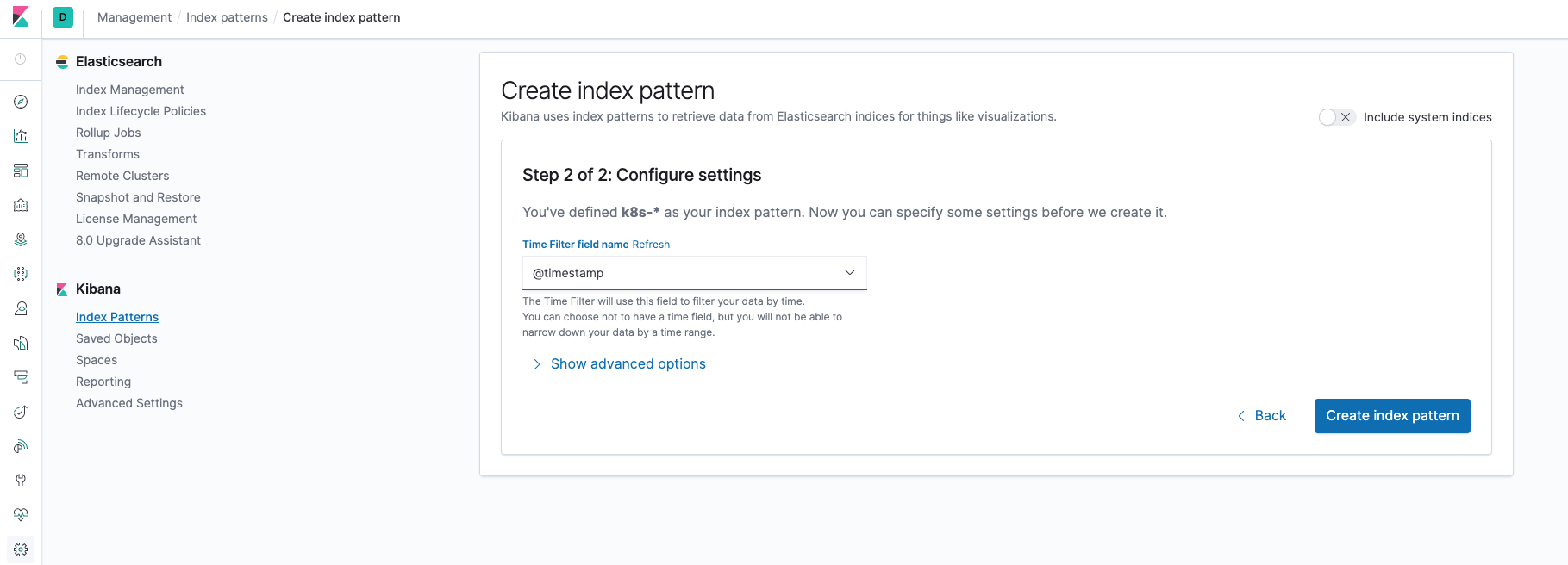
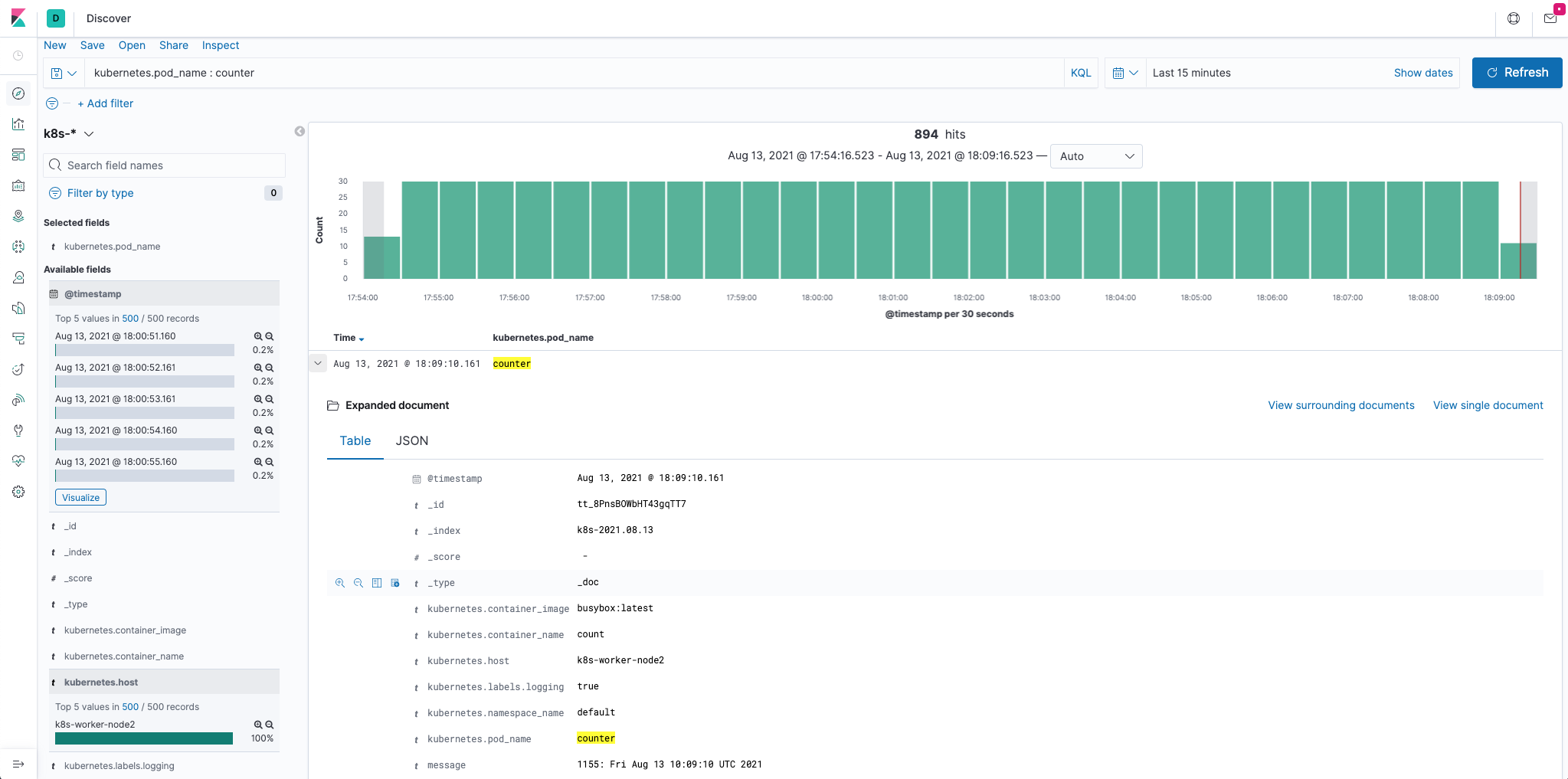
创建完成后,点击左侧导航菜单中的Discover,然后就可以看到一些直方图和最近采集到的日志数据了。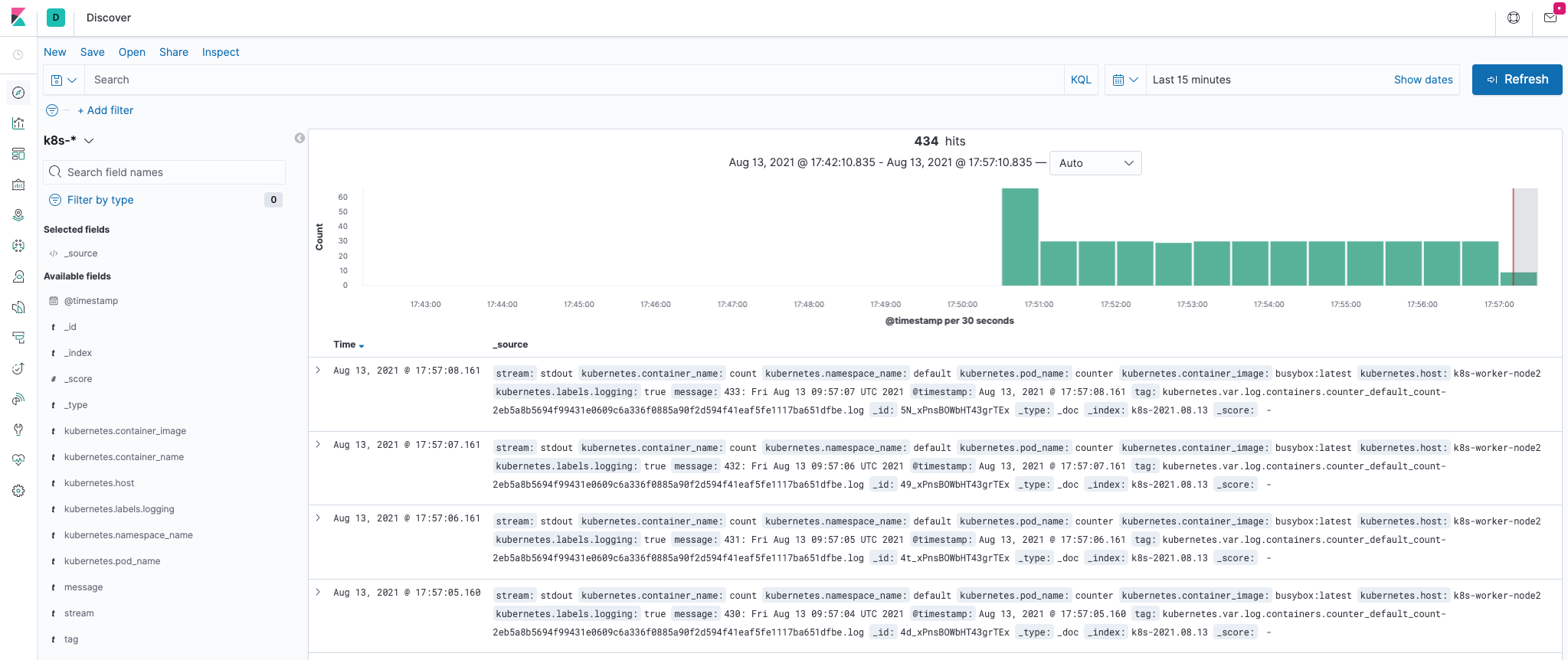
当我们把鼠标放到搜索栏时,会出现所有字段,我们点击某个需要的字段,就可以筛选我们需要的字段。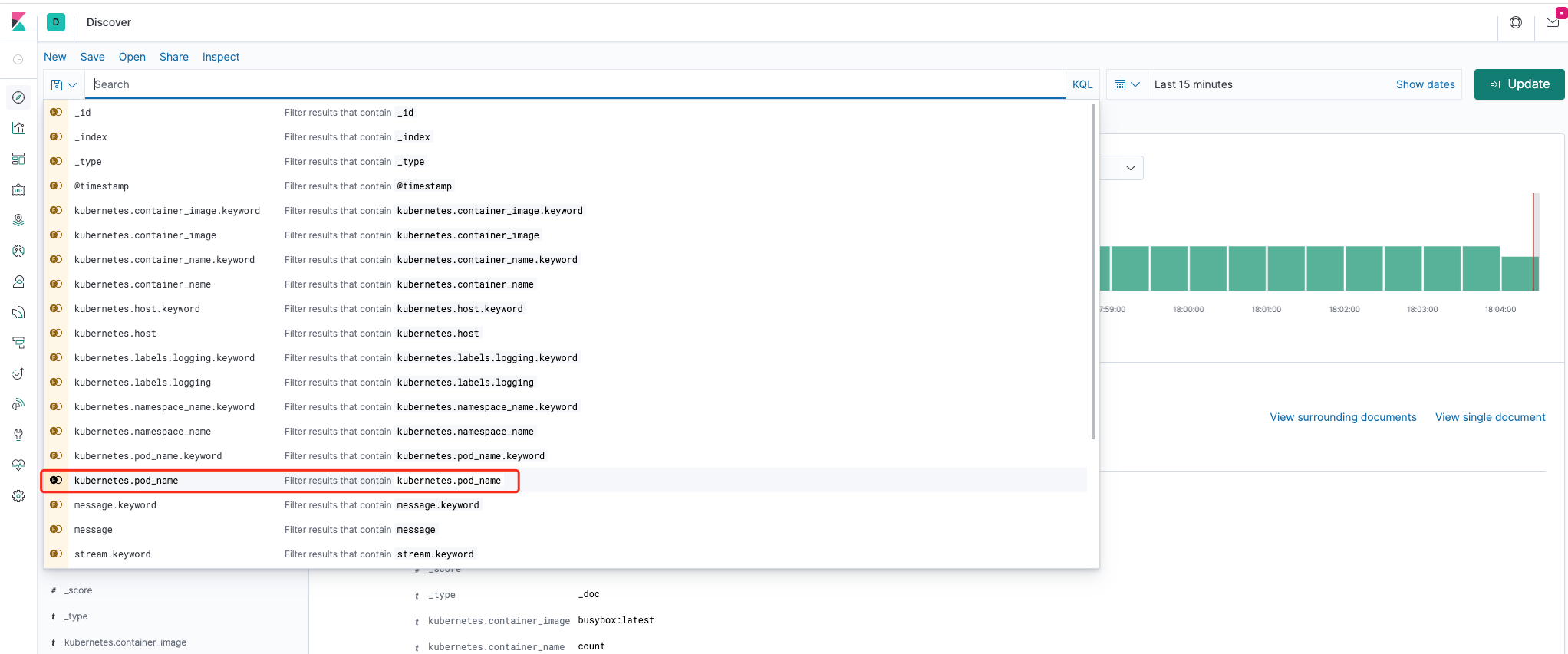
本文参考整理自https://www.qikqiak.com/post/install-efk-stack-on-k8s/

若有收获,就点个赞吧
0 人点赞
