kube-scheduler的调度过程
Step1: 筛选
节点预选(Predicate):排除完全不满足条件的节点,如内存大小,端口等条件不满足。
Step2: 打分
节点优先级排序(Priority):根据优先级选出最佳节点
Step3: 调度
节点择优(Select):根据优先级选定节点
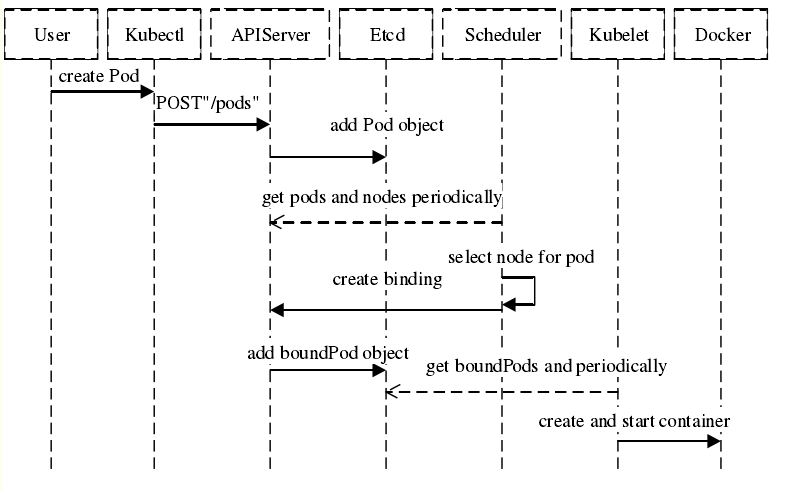
对于新建的或是未被调度的Pod,kube-scheduler会选择最优节点运行Pod。除此之外,每个Pod中的容器也会有其特定需求,如资源限制等;因此调度器会根据这些限制条件过滤掉不符合条件的节点。
在集群中,符合Pod调度条件的节点被称为Feasible Node,如果没有节点符合条件,那么pod会一直停留在unscheduled状态,直到有节点符合条件。
调度器寻找到Feasible Node后,还要通过一组函数对这些节点进行打分,从这些节点中找出分数最高的节点作为“最适合节点”,如果最适合节点有多个的话,就需要随机选择了。最后,调度器要将“调度结果”上报给API Server(这个过程叫做“绑定”)。
调度算法要考虑的因素有很多,包括单独的、整体的资源请求、软硬件条件、策略条件、亲和性与反亲和性、数据本地化、负载间通信等。
案例
今天将老的worker节点替换掉,结果发现有个“有状态服务”一直pedding,查看一圈才发现服务器可用区的问题
0/19 nodes are available: 11 node(s) had no available volume zone, 2 node(s) were unschedulable, 3 node(s) didn’t match pod affinity/anti-affinity, 3 node(s) didn’t satisfy existing pods anti-affinity rules, 3 node(s) had taints that the pod didn’t tolerate.
如果是云服务器,释放服务器时,如果服务器上有”有状态服务“,要考虑到服务器所在的可用区,新购买的服务器一定要和释放的服务器在一个可用区。如果集群中同一个可用区的节点不满足调度条件,即使其它可用区节点各种条件都满足,但不跟当前节点在同一个可用区,也是不会调度的。
为什么需要限制挂载了磁盘的 Pod 不能漂移到其它可用区的节点?试想一下,云上的磁盘虽然可以被动态挂载到不同机器,但也只是相对同一个数据中心,通常不允许跨数据中心挂载磁盘设备,因为网络时延会极大的降低 IO 速率。

若有收获,就点个赞吧
0 人点赞
