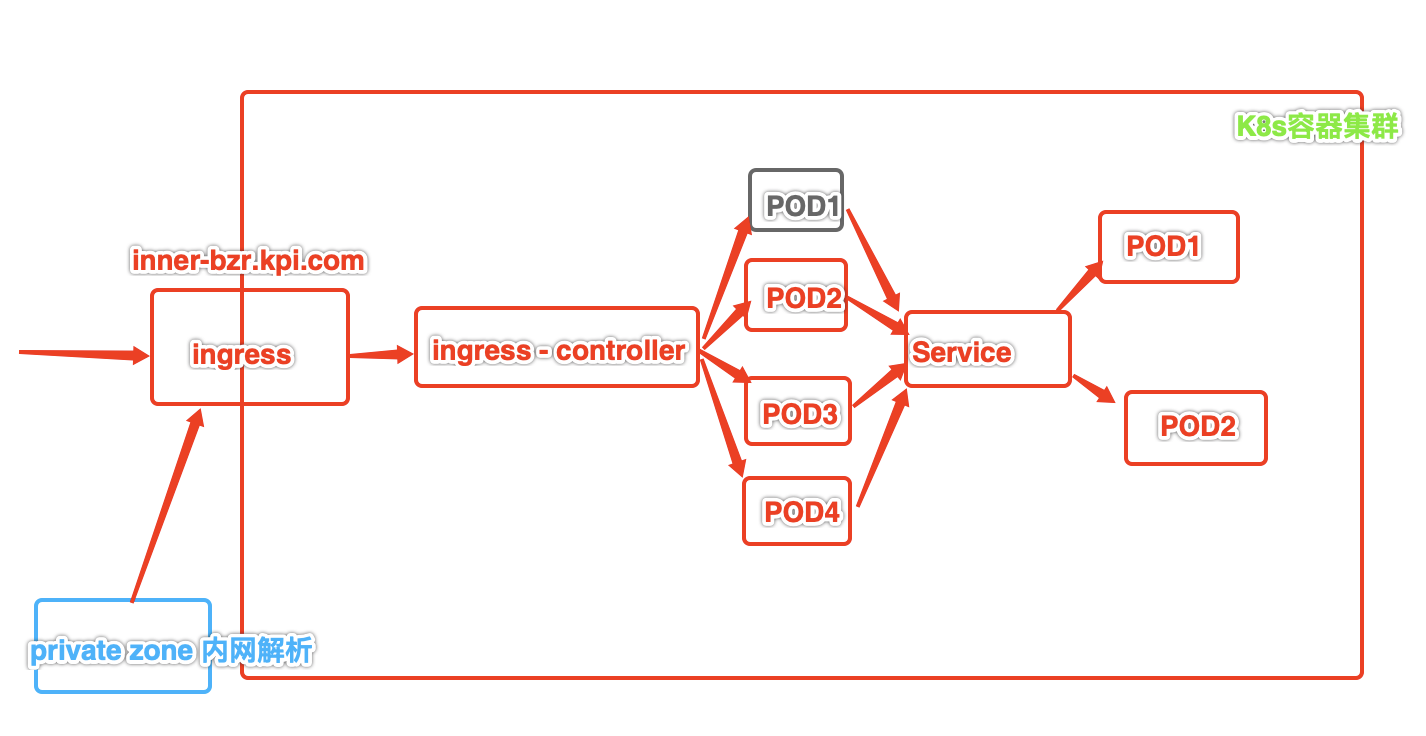
请求阿里云private zone解析的内网域名,偶发性超时
事件时间
2021-02-04 15:40 2021-02-04 19:00
事件描述
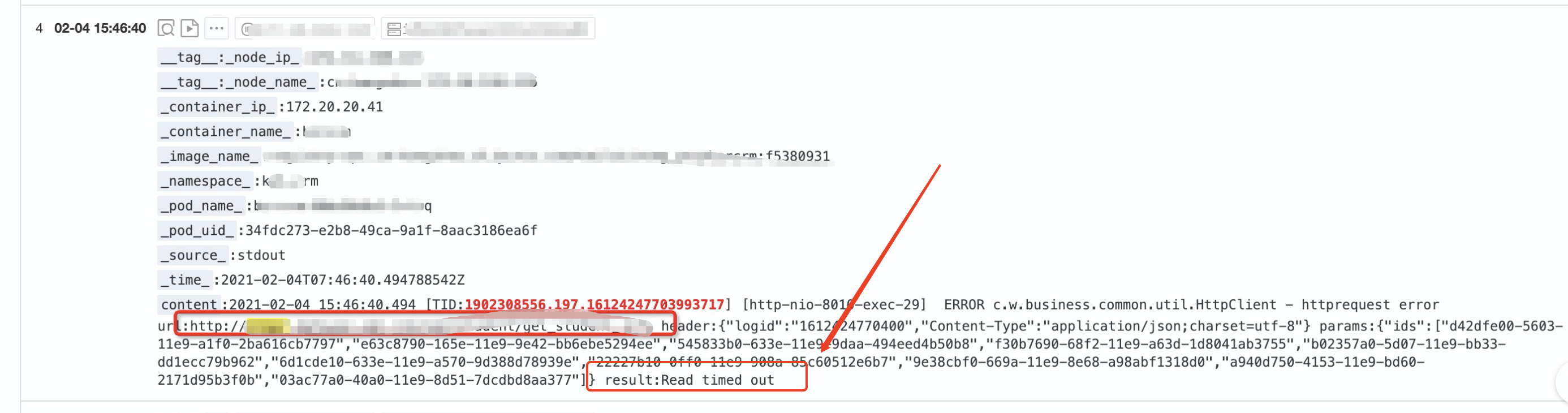
2021-02-04 15:46分发现一个bzrsystem 调用一个内网服务时,偶发性超时,单独拿出内网服务的域名请求时,大概20次有1次调用超时的情况。
事件排查
首先第一反映就是内网域名或者内网服务有问题。
首先检查内网服务,发现服务pod并没有重启或服务假死的情况(因为服务日志一直在不断的打),不敢相信自己的判断,于是重新发布了这个内网服务,但是手动测试还是发现有同样超时的情况。
那么就不是服务本身的问题,接下来可能就是内网域名解析的问题,登陆阿里云内网域名解析服务private zone,后台并没有特别有用的监控信息。
一圈未发现问题,直接就怀疑是阿里云的内网解析服务的问题,提工单等待的同时,也是坚信不疑的相信是阿里云解析的问题,因为只有内网解析的有问题。其他的外网解析的服务暂时没有发现问题。
第三个怀疑的对象就是ingress背后的负载均衡是否超载了,是否压力大等问题,找了一圈监控,但是也排除了负载均衡的问题。此时更坚定了是内网解析的问题了。
阿里云的服务团队也是效率低下,一圈转也没有找到实际处理人,各种dig 域名,各种抓包,也没有找到问题。此时过去了两个小时了,毫无头绪,钉钉业务群里已经各种反馈,”怎么处理一下午还没好“,压力倍增,老板知道了,让直接用IP,快速止血,不影响业务,因为业务中大部分服务都是微服务,一个内网服务可能有十几个服务调用,如果更换为IP,那么工作量还是挺大的。
就在最后打算要更换为IP的时候,技术总监提醒了下,是否是ingress-controller的问题呢,打开pod服务一看,4个pod服务中,只有一个pod重启过,并没有其他异常,查看日志后发现日志也在刷,但是有很多的failed日志,那么是否是这个pod的问题呢?重启了这个pod服务,在重新测试内网域名,没有失败或超时的情况。看来果然是ingress-controller的pod的问题了。

事件反思
此时突然感觉到羞愧难当,这个k8s服务是我维护的,我却不熟悉整个请求流程,找不到到底问题出现在什么地方。
第一:对整个k8s服务的各个组件不熟悉。
第二:出现问题后,总是从一个方面认定或排除问题。
第三:没有冷静梳理整个请求的流程,挨个排除可能出现的问题。
第四:总感觉出问题的是别人,没有自查自检的意识。
总结下排除问题的思路和方法
1、排除法
这是最基础的找问题的方法,梳理流程,挨个排除问题。
2、查日志
日志中记录着最有用的信息
3、对比法
对比好的服务和出问题的服务,结合替换的方法
4、换个方向或思路考虑问题
大胆想象,有可能出问题的方向。

若有收获,就点个赞吧
0 人点赞
