- changgou-day05
- 查询所有文档数据
- 索引的操作 列出索引
- 创建索引
- 删除索引
- 创建映射
- user—->索引名
- userinfo—->类型
- _mapping 标识创建映射
- 文档操作
- 创建文档
- user 标识索引名称
- userinfo 类型名称
- 1 文档的唯一标识
- 新增文档数据 id=3
- 新增文档数据 id=4
- 新增文档数据 id=5
- 新增文档数据 id=6
- 新增文档数据 id=7
- 查询文档 根据文档的ID 查询
- 删除文档
- 更新文档 doc的更新 推荐使用
- =—————————————查询————————————-
- 查询所有文档 如果不指定索引名和类型 查询所有的索引下的数据
- 匹配查询 match 查询 :先分词再进行查询
- term 查询 词条查询,特点 不分词 整体匹配进行分词
- terms 查询多个
- range 范围查询 比如:查询年龄在18到22之间的用户信息 gte >= lte <=
- 查询存在字段为address的用户数据
- bool 多条件组合查询
- 查询年龄在18到22之间的数据 并且 城市在深圳
- MUST 必须要满足
- MUST_NOT 必须不满足
- SHOULD 应该满足
- FIlter 必须要满足
- 分页和排序
- sort排序 order by fieldname desc/asc
- 分页 from ,size
- from: page-1 * rows
- size: rows
- 前缀查询
- 高亮
- ">1.设置高亮显示的字段 2.设置高亮的前缀和后缀
- 匹配查询
changgou-day05
目标:
- 理解需求(实现搜索的功能)
- 安装es服务器
- 安装es-head
- 安装kibana(用DSL语句)
- 安装ik分词器
- 理解掌握搜索的主要的思路
- 数据导入到ES中
- 通过关键字来搜索数据展示给页面
- 实现代码(搭建工程实现搜索的功能和导入数据的功能)
1 使用elasticsearch实现搜索功能
回顾:1.使用倒排索引的方式 速度快2.精准的搜索3.支持PB级别数据 上百个节点扩展
elasticsearch 是一个基于lucene的搜索引擎,目的是隐藏lucene的复杂性,提供简单易用的API(REST api java api) 实现搜索。核心的概念:+ 索引 index 数据库库+ 类型 type 表+ 文档 document 行+ 字段 field 列+ 映射 mapping 约束如何映射?字段的属性3个重要属性:是否分词 分词的目的是为了索引 (为了建立倒排索引)是否索引 索引的目的是为了搜索(为了快速的实现搜索)是否存储 是否存储到lucene ,看页面是否展示(es中默认的情况是不存储的,存到_source字段中)分词器:+ ik分词器+ 分词器策略:+ ik_smart+ ik_max_word
2 搭建es服务器
1.安装es服务器2.安装es-head插件3.安装ik分词器
3 安装kibana的插件(开发人员用)
docker pull docker.io/kibana:5.6.8--删除容器docker rm -f kibana--创建容器docker run -it -d -e ELASTICSEARCH_URL=http://192.168.211.132:9200 --name kibana --restart=always -p 5601:5601 kibana:5.6.8
 ```cpp
```cpp查询所有文档数据
GET _search { “query”: { “match_all”: {} } }
索引的操作 列出索引
GET _cat/indices?v
创建索引
PUT /user
删除索引
DELETE /user
创建映射
user—->索引名
userinfo—->类型
_mapping 标识创建映射
PUT /user/userinfo/_mapping { “properties”: { “name”:{ “type”: “text”, “analyzer”: “ik_smart”, “search_analyzer”: “ik_smart”, “store”: false }, “city”:{ “type”: “text”, “analyzer”: “ik_smart”, “search_analyzer”: “ik_smart”, “store”: false }, “age”:{ “type”: “long”, “store”: false }, “description”:{ “type”: “text”, “analyzer”: “ik_smart”, “search_analyzer”: “ik_smart”, “store”: false } } }
文档操作
创建文档
user 标识索引名称
userinfo 类型名称
1 文档的唯一标识
PUT /user/userinfo/1 { “name”:”李四”, “age”:22, “city”:”深圳”, “description”:”李四来自湖北武汉!” }
PUT /user/userinfo/2 { “name”:”王五”, “age”:35, “city”:”深圳”, “description”:”王五家住在深圳!” }
新增文档数据 id=3
PUT /user/userinfo/3 { “name”:”张三”, “age”:19, “city”:”深圳”, “description”:”在深圳打工,来自湖北武汉” }
新增文档数据 id=4
PUT /user/userinfo/4 { “name”:”张三丰”, “age”:66, “city”:”武汉”, “description”:”在武汉读书,家在武汉!” }
新增文档数据 id=5
PUT /user/userinfo/5 { “name”:”赵子龙”, “age”:77, “city”:”广州”, “description”:”赵子龙来自深圳宝安,但是在广州工作!”, “address”:”广东省茂名市” }
新增文档数据 id=6
PUT /user/userinfo/6 { “name”:”赵毅”, “age”:55, “city”:”广州”, “description”:”赵毅来自广州白云区,从事电子商务8年!” }
新增文档数据 id=7
PUT /user/userinfo/7 { “name”:”赵哈哈”, “age”:57, “city”:”武汉”, “description”:”武汉赵哈哈,在深圳打工已有半年了,月薪7500!” }
查询文档 根据文档的ID 查询
GET /user/userinfo/1
删除文档
DELETE /user/userinfo/1
更新文档 doc的更新 推荐使用
POST /user/userinfo/1/_update { “doc”: { “name”:”李思思” }
}
=—————————————查询————————————-
查询所有文档 如果不指定索引名和类型 查询所有的索引下的数据
GET /user/userinfo/_search { “query”: { “match_all”: {} } }
匹配查询 match 查询 :先分词再进行查询
GET /user/userinfo/_search { “query”: { “match”: { “description”: “武汉” } } }
term 查询 词条查询,特点 不分词 整体匹配进行分词
terms 查询多个
GET /user/userinfo/_search { “query”: { “terms”: { “city”: [ “深圳”, “武汉” ] } } }
range 范围查询 比如:查询年龄在18到22之间的用户信息 gte >= lte <=
GET /user/userinfo/_search { “query”: { “range”: { “age”: { “gte”: 18, “lte”: 22 } } } }
查询存在字段为address的用户数据
GET /user/userinfo/_search { “query”: { “exists”:{ “field”:”address” } } }
bool 多条件组合查询
查询年龄在18到22之间的数据 并且 城市在深圳
MUST 必须要满足
MUST_NOT 必须不满足
SHOULD 应该满足
FIlter 必须要满足
GET /user/userinfo/_search { “query”: { “bool”: { “must”: [ { “range”: { “age”: { “gte”: 18, “lte”: 22 } } }, { “term”: { “city”: { “value”: “深圳” } } } ] } } }
分页和排序
sort排序 order by fieldname desc/asc
分页 from ,size
from: page-1 * rows
size: rows
GET /user/userinfo/_search { “query”: { “match_all”: {} }, “sort”: [ { “age”: { “order”: “desc” } } ], “from”: 4, “size”: 2 }
前缀查询
GET _search { “query”: { “prefix”: { “name”: { “value”: “赵” } } } }
高亮
1.设置高亮显示的字段 2.设置高亮的前缀和后缀
匹配查询
GET /user/userinfo/_search { “query”: { “match”: { “description”: “深圳” } }, “highlight”: { “fields”: { “description”:{} }, “pre_tags”: ““, “post_tags”: ““ } }
<a name="QE4rO"></a>###<a name="QRHxd"></a>### 4 思路
- 导入的流程
- 搜索的流程
1.界面上:点击导入索引按钮 2.搜索微服务接收请求 3.通过feign远程调用goods微服务(4.内部实现从数据库中查询sku的列表数据) 5.搜索微服务获取到数据之后 将数据进行转换JSON 存储到es服务器中导入的流程:<br />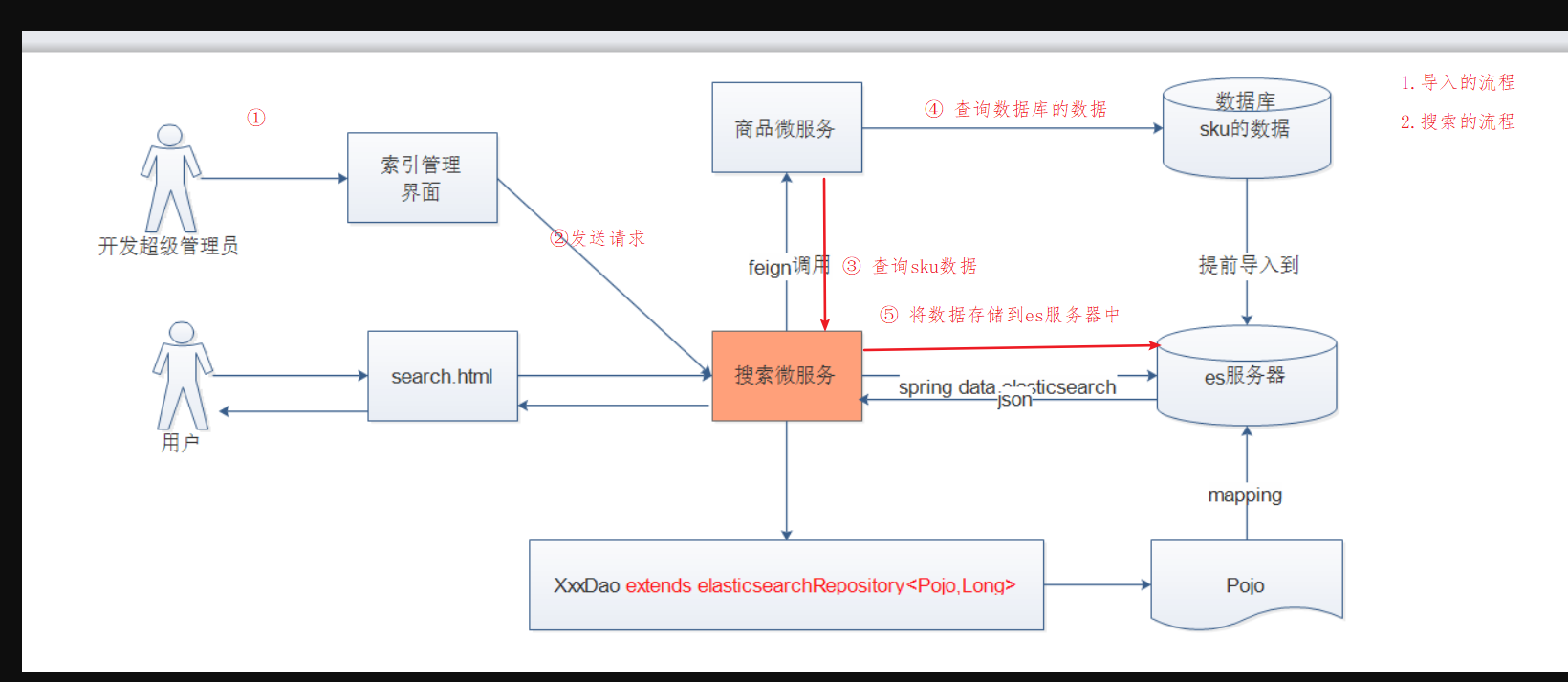
搜索的流程<br />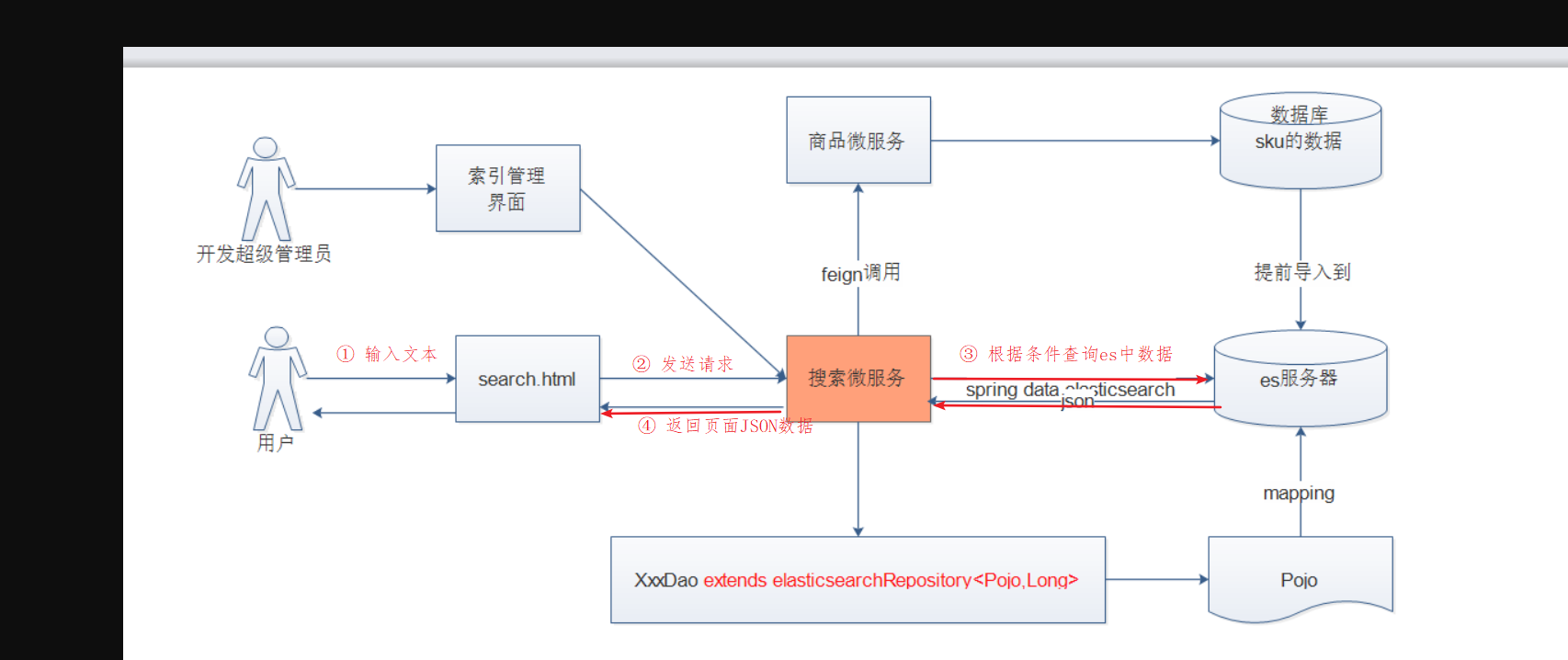
- 用户在界面输入文本
- 点击搜索 后台搜索微服务中获取请求和数据
- 从es服务器中获取到数据返回给前端
1.创建POJO 和es建立映射关系 2.创建接口继承elasticsearchRepository 3.实现CRUD实现搜索和导入都需要用到spring data elasticsearch API来实现。
1.搭建搜索微服务<a name="yo5EZ"></a>### 5 实现步骤
- 添加起步依赖
- 创建启动类
- 创建yml 配置连接到的es的服务器的端ip和端口 以及cluaster-name 2.集成spring data elasticsearch 到微服务中
- 创建POJO(建立映射关系(根据需求来建立))
- 创建DAO
3.实现导入数据
4.实现搜索
```Field 数据类型:text 文本类型 分词keyword 文本类型 一定是不分词的
5.1 实现导入功能
思路:请求给到seaarch微服务search微服务接收请求 远程调用feign获取到sku的列表数据再存到es服务器中请求:/search/import GET参数:没有返回值:result true/falsecontroller service dao(操作的是ES)
5.2 实现关键字搜索功能实现
思路:当输入文本的时候,点击搜索发送请求,当点击搜索面板,发送请求到后台后台接收请求之后,执行搜索,将查询到的数据 返回给前端请求:/search POST参数:map:{"keywords":"手机","brand":"华为",........} 用来封装所有的请求参数返回值:Map:{"rows":[{}],"total":100,"page":1,brandList:["华为","小米"]} 用来封装返回的结果(包括:当前页的记录,总页数,总记录数,品牌列表,分类列表,规格的列表.........)controller service dao

若有收获,就点个赞吧
0 人点赞
