安装Node Exporter
在 Prometheus 的架构设计中,Prometheus Server 并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的 CPU 使用率,我们需要使用到 Exporter。Prometheus 周期性的从 Exporter 暴露的HTTP服务地址(通常是 /metrics)拉取监控样本数据。
从上面的描述中可以看出 Exporter 可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus 提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如 CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter 同样采用 Golang 编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gztar -xzf node_exporter-0.17.0.linux-amd64.tar.gzcd node_exporter-0.17.0.linux-amd64/mv node_exporter /usr/local/bin/
配置脚本
cat >> /etc/rc.d/init.d/node_exporter <<EOF#!/bin/bash## /etc/rc.d/init.d/node_exporter## Prometheus node exporter## description: Prometheus node exporter# processname: node_exporter# Source function library.. /etc/rc.d/init.d/functionsPROGNAME=node_exporterPROG=/opt/prometheus/$PROGNAMEUSER=rootLOGFILE=/var/log/prometheus.logLOCKFILE=/var/run/$PROGNAME.pidstart() {echo -n "Starting $PROGNAME: "cd /opt/prometheus/daemon --user $USER --pidfile="$LOCKFILE" "$PROG &>$LOGFILE &"echo $(pidofproc $PROGNAME) >$LOCKFILEecho}stop() {echo -n "Shutting down $PROGNAME: "killproc $PROGNAMErm -f $LOCKFILEecho}case "$1" instart)start;;stop)stop;;status)status $PROGNAME;;restart)stopstart;;reload)echo "Sending SIGHUP to $PROGNAME"kill -SIGHUP $(pidofproc $PROGNAME)#!/bin/bash;;*)echo "Usage: service node_exporter {start|stop|status|reload|restart}"exit 1;;esacEOF
运行node exporter
service node_exporter start
启动成功后,查看端口
netstat -anplt|grep 9100
访问http://localhost:9100/可以看到以下页面:
Node Exporter页面
初始Node Exporter监控指标
访问http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:
主机监控指标
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.# TYPE node_cpu counternode_cpu{cpu="cpu0",mode="idle"} 362812.7890625# HELP node_load1 1m load average.# TYPE node_load1 gaugenode_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- nodedisk*:磁盘IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- nodememeory*:内存使用量
- nodenetwork*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']# 采集node exporter监控数据- job_name: 'node'static_configs:- targets: ['localhost:9100']
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
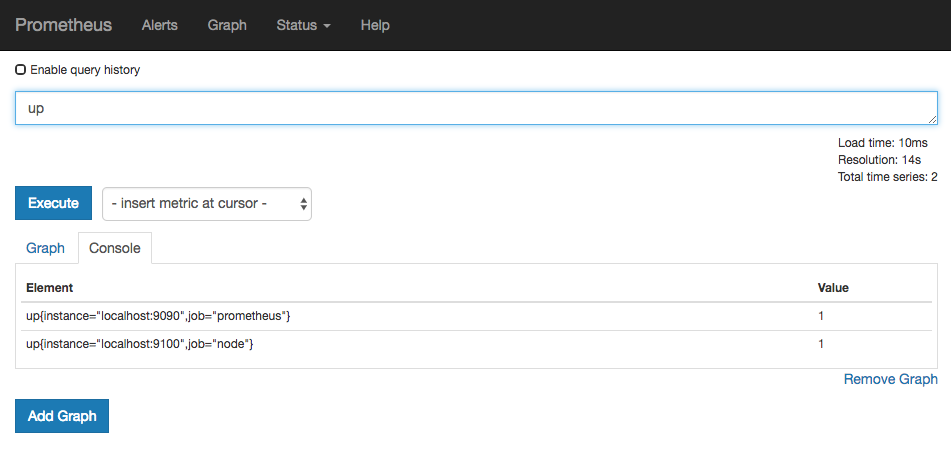
Expression Browser
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1up{instance="localhost:9100",job="node"} 1
其中 “1” 表示正常,反之 “0” 则为异常。

若有收获,就点个赞吧
0 人点赞
