0. 软件包准备
- JDK
版本:jdk-8u221-linux-x64.tar.gz
下载:https://www.oracle.com/technetwork/pt/java/javase/downloads/jdk8-downloads-2133151.html?printOnly=1
- Hadoop
版本:hadoop-2.7.2.tar.gz
下载:http://archive.apache.org/dist/hadoop/core
1. 获取镜像
# 查看可用的稳定版本docker search centosdocker pull centos:centos7.7.1908docker image ls |grep centos
2. 单机伪分布式
1. 资源规划
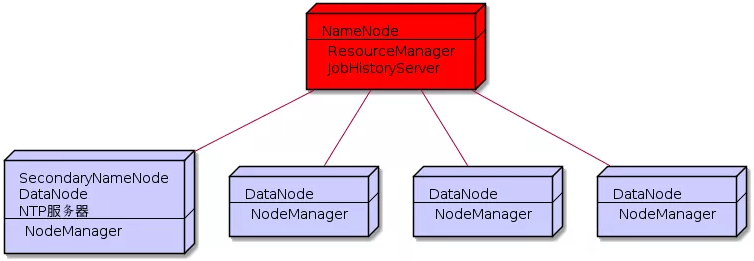
| hadoop01 | hadoop02 | hadoop03 | hadoop04 | hadoop05 |
|---|---|---|---|---|
| CentOS-7.7 | CentOS-7.7 | CentOS-7.7 | CentOS-7.7 | CentOS-7.7 |
| JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 |
| NTP Client | NTP Server | NTP Client | NTP Client | NTP Client |
| NameNode | SecondaryNameNode/DataNode | DataNode | DataNode | DataNode |
| ResourceManager | NodeManager | NodeManager | NodeManager | NodeManager |
| JobHistoryServer | N.A | N.A | N.A | N.A |
2. 创建容器
1. 手动搭建方式
下面会用到systemctl管理服务,需要加上参数—privileged来增加权,并且不能使用默认的bash,换成/usr/sbin/init。
sudo docker run -d --name hadoop01 --hostname hadoop01 --net hadoop-network --ip 172.24.0.101 -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop02 --hostname hadoop02 --net hadoop-network --ip 172.24.0.102 -P -p 50090:50090 --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop03 --hostname hadoop03 --net hadoop-network --ip 172.24.0.103 -P --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop04 --hostname hadoop04 --net hadoop-network --ip 172.24.0.104 -P --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop05 --hostname hadoop05 --net hadoop-network --ip 172.24.0.105 -P --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/init
2. 脚本搭建方式
vi /share/hadoop-cluster.sh
shell脚本内容如下:
#!/bin/bash# description: Batch start Containers Script# author: polarisif [ $# -ne 1 ];thenecho "You need to start several containers explicitly."echo "Some like './hadoop-cluster.sh 3' or 'sh hadoop-cluster.sh 3'"exit 1fi# 要启动的容器数量NUM_CONTAINERS=$1# 自定义网络名称NETWORK_NAME=hadoop-network# Hadoop基础镜像ID或者名称IMAGE_ID=registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2# 前缀PREFIX="0"for (( i=1;i<=$NUM_CONTAINERS;i++ ))doif [ $i -eq 1 ];thensudo docker run -d --name hadoop$PREFIX$i --hostname hadoop$PREFIX$i --net ${NETWORK_NAME} --ip 172.24.0.$[$i+100] -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --privileged $IMAGE_ID /usr/sbin/initelif [ $i -eq 2 ];thensudo docker run -d --name hadoop$PREFIX$i --hostname hadoop$PREFIX$i --net ${NETWORK_NAME} --ip 172.24.0.$[$i+100] -P -p 50090:50090 --privileged $IMAGE_ID /usr/sbin/initelsesudo docker run -d --name hadoop$PREFIX$i --hostname hadoop$PREFIX$i --net ${NETWORK_NAME} --ip 172.24.0.$[$i+100] -P --privileged $IMAGE_ID /usr/sbin/initfidoneecho "$NUM_CONTAINERS containers started!"echo "==================================="sudo docker ps | grep hadoopecho "============IPv4==================="sudo docker inspect $(sudo docker ps -q) | grep -i ipv4
启动5个容器:
sh /share/hadoop-cluster.sh 5
3. 容器配置
1. 进入容器
docker exec -ti hadoop01 /bin/bashdocker exec -ti hadoop02 /bin/bashdocker exec -ti hadoop03 /bin/bashdocker exec -ti hadoop04 /bin/bashdocker exec -ti hadoop05 /bin/bashsu hadoop
2. 配置映射
# 所有节点执行sudo vi /etc/hosts
节点ip分配如下:
hadoop01=172.24.0.101hadoop02=172.24.0.102hadoop03=172.24.0.103hadoop04=172.24.0.104hadoop05=172.24.0.105
3. 免密配置
# 所有节点执行-生成公私钥(-N:无密码)ssh-keygen -t rsa -N '' -C "450733605@qq.com"# 所有节点执行-提供公钥给别的节点ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop01ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop04ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop05# 所有节点执行-验证免密ssh hadoop01ssh hadoop02ssh hadoop03ssh hadoop04ssh hadoop05
4. 时间同步
1. 安装NTP服务
# 所有节点执行rpm -qa | grep ntpsudo yum -y install ntp
2. 设置时间配置文件
# hadoop02节点执行sudo vi /etc/ntp.conf
配置如下:
# 修改一(设置本地网络上的主机不受限制-新增)restrict 172.24.0.0 mask 255.255.255.0 nomodify notrap# 修改二(添加默认的一个内部时钟数据,使用它为局域网用户提供服务-新增)server 127.127.1.0fudge 127.127.1.0 stratum 10# 修改三(设置为不采用公共的服务器-注释)#server 0.centos.pool.ntp.org iburst#server 1.centos.pool.ntp.org iburst#server 2.centos.pool.ntp.org iburst#server 3.centos.pool.ntp.org iburst
3. 设置BIOS与系统时间同步
# hadoop02节点执行sudo vim /etc/sysconfig/ntpd
配置如下:
# 删除如下内容OPTIONS="-g"# 增加如下内容(让硬件时间与系统时间一起同步)OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"SYNC_HWCLOCK=yes
4. 启动ntp服务并测试
# hadoop02节点执行sudo systemctl start ntpdsudo systemctl restart ntpd# 设置ntp服务开机自启sudo systemctl enable ntpd.service# 查看NTP服务状态systemctl status ntpdntpstatsudo ntpq -p# 查看时区timedatectl# 设置时区(所有节点执行,服务端)sudo timedatectl set-timezone Asia/Shanghai
5. 客户端与时间服务器同步时间
注意:先关闭非时间服务器节点的ntpd服务。
# 非hadoop02节点执行sudo systemctl stop ntpd
设置时区:
# 设置时区(所有节点执行,客户端)sudo timedatectl set-timezone Asia/Shanghai
客户端安装crontabs以定时同步时间:
# 非hadoop02节点执行sudo yum -y install vixie-cron crontabs
添加定时任务:
# 非hadoop02节点执行sudo vi /etc/crontab
任务内容如下:
*/1 * * * * /usr/sbin/ntpdate hadoop02
任务生效:
# 非hadoop02节点执行sudo /bin/systemctl start crondsudo /bin/systemctl stop crondsudo /bin/systemctl restart crondsudo /bin/systemctl reload crondsudo /bin/systemctl status crond# 使任务生效sudo crontab /etc/crontab
6. 测试
# 修改时间服务器时间sudo date -s "2020-12-31 12:12:12"# 服务器时间同步修正sudo ntpdate -u ntp.api.bz# 客户端手动同步时间sudo /usr/sbin/ntpdate hadoop02###### NTP服务器(上海) :ntp.api.bz###### 中国国家授时中心:210.72.145.44###### 美国:time.nist.gov###### 复旦:ntp.fudan.edu.cn###### 微软公司授时主机(美国) :time.windows.com###### 台警大授时中心(台湾):asia.pool.ntp.org
5. Hadoop配置
注意:主节点上配置完成后分发至其他节点。
创建所需文件夹
# 主节点(hadoop01)执行su hadoopmkdir -p /opt/software/hadoop-2.7.2/tmpmkdir -p /opt/software/hadoop-2.7.2/dfs/namenode_datamkdir -p /opt/software/hadoop-2.7.2/dfs/datanode_datamkdir -p /opt/software/hadoop-2.7.2/checkpoint/dfs/cname
1. hadoop-env.sh
vi ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
配置如下:
export JAVA_HOME=/opt/moudle/jdk1.8.0_221export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.2/etc/hadoop
2. core-site.xml
vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
配置如下:
<configuration><property><!--用来指定hdfs的master,namenode的地址--><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value></property><property><!--用来指定hadoop运行时产生文件的存放目录--><name>hadoop.tmp.dir</name><value>/opt/software/hadoop-2.7.2/tmp</value></property><property><!--设置缓存大小,默认4kb--><name>io.file.buffer.size</name><value>4096</value></property></configuration>
3. hdfs-site.xml
指定副本系数和hdfs操作权限。
vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
配置如下:
<configuration><property><!--数据块默认大小128M--><name>dfs.block.size</name><value>134217728</value></property><property><!--副本数量,不配置的话默认为3--><name>dfs.replication</name><value>1</value></property><property><!--定点检查--><name>fs.checkpoint.dir</name><value>/opt/software/hadoop-2.7.2/checkpoint/dfs/cname</value></property><property><!--namenode节点数据(元数据)的存放位置--><name>dfs.name.dir</name><value>/opt/software/hadoop-2.7.2/dfs/namenode_data</value></property><property><!--datanode节点数据(元数据)的存放位置--><name>dfs.data.dir</name><value>/opt/software/hadoop-2.7.2/dfs/datanode_data</value></property><property><!--指定secondarynamenode的web地址--><name>dfs.namenode.secondary.http-address</name><value>hadoop02:50090</value></property><property><!--hdfs文件操作权限,false为不验证--><name>dfs.permissions</name><value>false</value></property></configuration>
4. mapred-site.xml
cp ${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template ${HADOOP_HOME}/etc/hadoop/mapred-site.xmlvi ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
配置如下:
<configuration><property><!--指定mapreduce运行在yarn上--><name>mapreduce.framework.name</name><value>yarn</value></property><property><!--配置任务历史服务器地址--><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value></property><property><!--配置任务历史服务器web-UI地址--><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value></property></configuration>
5. yarn-site.xml
vi ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
配置如下:
<configuration><property><!--指定yarn的主节点,resourcemanager的地址--><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><property><name>yarn.resourcemanager.address</name><value>hadoop01:8032</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop01:8088</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop01:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop01:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>hadoop01:8033</value></property><property><!--NodeManager获取数据的方式--><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><!--开启日志聚集功能--><name>yarn.log-aggregation-enable</name><value>true</value></property><property><!--配置日志保留7天--><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
6. master
vi ${HADOOP_HOME}/etc/hadoop/master
配置如下:
hadoop01
7. slaves
vi ${HADOOP_HOME}/etc/hadoop/slaves
配置如下:
hadoop02hadoop03hadoop04hadoop05
6. 分发
sudo scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop02:/opt/software/sudo scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop03:/opt/software/sudo scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop04:/opt/software/sudo scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop05:/opt/software/
4. 启动Hadoop
1. HDFS初始化
# 主节点(hadoop01)执行hdfs namenode -format
2. 启动HDFS和YARN
# 主节点(hadoop01)执行# 启动dfs服务start-dfs.sh# 启动yarn服务start-yarn.sh# 启动任务历史服务器mr-jobhistory-daemon.sh start historyserver
5. 验证
进程查看 ```bash [hadoop@hadoop01 ~]$ jps
NameNode ResourceManager JobHistoryServer
[hadoop@hadoop02 ~]$ jps
[hadoop@hadoop03 ~]$ jps
[hadoop@hadoop04 ~]$ jps
[hadoop@hadoop05 ~]$ jps
- **Web UI**- **NameNode WebUI**:[http://192.168.0.99:50070](http://192.168.0.99:50070)- **SecondaryNameNode WebUI**:[http://192.168.0.99:50090](http://192.168.0.99:50090)- **ResourceManager WebUI**:[http://192.168.0.99:8088](http://192.168.0.99:8088)- **HistoryServer WebUI**:[http://192.168.0.99:19888](http://192.168.0.99:19888)<a name="SBOBn"></a>## 6. 测试集群提交 Hadoop 内置的计算 Pi 的示例程序为例,在任何一个节点上执行都可以,命令如下:```bashhadoop jar /opt/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar pi 11 24
任务完成后可以在任务历史服务器(端口19888)中找到相应的job:http://192.168.0.99:19888。
7. 提交镜像到公仓
# 登录公仓docker login --username=alypolarisbigdata registry.cn-qingdao.aliyuncs.com# 镜像tagdocker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop01" hadoop01 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop01docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop02" hadoop02 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop02docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop03" hadoop03 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop03docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop04" hadoop04 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop04docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop05" hadoop05 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop05docker images |grep hadoop# 镜像推送docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop01docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop02docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop03docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop04docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop05# 拉取镜像docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop01docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop02docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop03docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop04docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-cluster:hadoop05
3. 单机伪分布式HA
1. 资源规划
| hadoop01 | hadoop02 | hadoop03 | hadoop04 | hadoop05 |
|---|---|---|---|---|
| CentOS-7.7 | CentOS-7.7 | CentOS-7.7 | CentOS-7.7 | CentOS-7.7 |
| JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 | JDK-1.8.221 |
| NTP Client | NTP Server | NTP Client | NTP Client | NTP Client |
| NameNode/DFSZKFailoverController/DataNode/JournalNode | NameNode/DFSZKFailoverController/DataNode/JournalNode | DataNode/JournalNode | DataNode/JournalNode | DataNode/JournalNode |
| ResourceManager | NodeManager | ResourceManager/NodeManager | NodeManager | NodeManager |
| JobHistoryServer | N.A | N.A | N.A | N.A |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain | N.A | N.A |
2. 创建容器
sudo docker run -d --name hadoop-ha-01 --hostname hadoop-ha-01 --net hadoop-network --ip 172.24.0.101 -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop-ha-02 --hostname hadoop-ha-02 --net hadoop-network --ip 172.24.0.102 -P -p 50072:50070 --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop-ha-03 --hostname hadoop-ha-03 --net hadoop-network --ip 172.24.0.103 -P -p 8083:8088 --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop-ha-04 --hostname hadoop-ha-04 --net hadoop-network --ip 172.24.0.104 -P --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/initsudo docker run -d --name hadoop-ha-05 --hostname hadoop-ha-05 --net hadoop-network --ip 172.24.0.105 -P --privileged registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-single:2.7.2 /usr/sbin/init
3. 进入容器
sudo docker exec -ti hadoop-ha-01 /bin/bashsudo docker exec -ti hadoop-ha-02 /bin/bashsudo docker exec -ti hadoop-ha-03 /bin/bashsudo docker exec -ti hadoop-ha-04 /bin/bashsudo docker exec -ti hadoop-ha-05 /bin/bashsu hadoop
4. 容器配置
1. 配置映射
# 所有节点执行sudo vi /etc/hosts
节点ip分配如下:
hadoop-ha-01=172.24.0.101hadoop-ha-02=172.24.0.102hadoop-ha-03=172.24.0.103hadoop-ha-04=172.24.0.104hadoop-ha-05=172.24.0.105
2. 免密配置
# 所有节点执行-生成公私钥(-N:无密码)ssh-keygen -t rsa -N '' -C "450733605@qq.com"# 所有节点执行-提供公钥给别的节点ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-ha-01ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-ha-02ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-ha-03ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-ha-04ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-ha-05# 所有节点执行-验证免密ssh hadoop-ha-01ssh hadoop-ha-02ssh hadoop-ha-03ssh hadoop-ha-04ssh hadoop-ha-05
3. 时间同步
1. 安装NTP服务
# 所有节点执行rpm -qa | grep ntpsudo yum -y install ntp
2. 设置时间配置文件
# hadoop-ha-02节点执行sudo vi /etc/ntp.conf
配置如下:
# 修改一(设置本地网络上的主机不受限制-新增)restrict 172.24.0.0 mask 255.255.255.0 nomodify notrap# 修改二(添加默认的一个内部时钟数据,使用它为局域网用户提供服务-新增)server 127.127.1.0fudge 127.127.1.0 stratum 10# 修改三(设置为不采用公共的服务器-注释)#server 0.centos.pool.ntp.org iburst#server 1.centos.pool.ntp.org iburst#server 2.centos.pool.ntp.org iburst#server 3.centos.pool.ntp.org iburst
3. 设置BIOS与系统时间同步
# hadoop02节点执行sudo vi /etc/sysconfig/ntpd
配置如下:
# 删除如下内容OPTIONS="-g"# 增加如下内容(让硬件时间与系统时间一起同步)OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"SYNC_HWCLOCK=yes
4. 启动ntp服务并测试
# hadoop02节点执行sudo systemctl start ntpdsudo systemctl restart ntpd# 设置ntp服务开机自启sudo systemctl enable ntpd.service# 查看NTP服务状态systemctl status ntpdntpstatsudo ntpq -p# 查看时区timedatectl# 设置时区(所有节点执行,服务端)sudo timedatectl set-timezone Asia/Shanghai
5. 客户端与时间服务器同步时间
注意:先关闭非时间服务器节点的ntpd服务。
# 非hadoop-ha-02节点执行sudo systemctl stop ntpd
设置时区:
# 设置时区(所有节点执行,客户端)sudo timedatectl set-timezone Asia/Shanghai
客户端安装crontabs以定时同步时间:
# 非hadoop-ha-02节点执行sudo yum -y install vixie-cron crontabs
添加定时任务:
# 非hadoop-ha-02节点执行sudo vi /etc/crontab
任务内容如下:
*/1 * * * * /usr/sbin/ntpdate hadoop-ha-02
任务生效:
# 非hadoop-ha-02节点执行sudo /bin/systemctl start crondsudo /bin/systemctl stop crondsudo /bin/systemctl restart crondsudo /bin/systemctl reload crondsudo /bin/systemctl status crond# 使任务生效sudo crontab /etc/crontab
6. 测试
# 修改时间服务器时间sudo date -s "2020-12-31 12:12:12"# 服务器时间同步修正sudo ntpdate -u ntp.api.bz# 客户端手动同步时间sudo /usr/sbin/ntpdate hadoop-ha-02###### NTP服务器(上海) :ntp.api.bz###### 中国国家授时中心:210.72.145.44###### 美国:time.nist.gov###### 复旦:ntp.fudan.edu.cn###### 微软公司授时主机(美国) :time.windows.com###### 台警大授时中心(台湾):asia.pool.ntp.org
4. ZooKeeper安装配置
1. 上传安装包
# 宿主机执行,先将zk安装包上传至/share,随后上传至容器sudo docker cp /share/zookeeper-3.4.10.tar.gz hadoop-ha-01:/opt/software/
2. 解压缩
tar -zxvf /opt/software/zookeeper-3.4.10.tar.gz -C /opt/software/
3. 创建所需目录
mkdir /opt/software/zookeeper-3.4.10/zoo_datamkdir /opt/software/zookeeper-3.4.10/zoo_logs
4. 配置zoo.cfg
cd /opt/software/zookeeper-3.4.10/confcp zoo_sample.cfg zoo.cfgvi zoo.cfg
配置如下:
tickTime=2000initLimit=10syncLimit=5dataDir=/opt/software/zookeeper-3.4.10/zoo_datadataLogDir=/opt/software/zookeeper-3.4.10/zoo_logsclientPort=2181server.1=hadoop-ha-01:2888:3888server.2=hadoop-ha-02:2888:3888server.3=hadoop-ha-03:2888:3888
6. 分发
scp -r /opt/software/zookeeper-3.4.10 hadoop@hadoop-ha-02:/opt/software/scp -r /opt/software/zookeeper-3.4.10 hadoop@hadoop-ha-03:/opt/software/
7. 修改myid
# hadoop-ha-01echo 1 >> /opt/software/zookeeper-3.4.10/zoo_data/myid# hadoop-ha-02echo 2 >> /opt/software/zookeeper-3.4.10/zoo_data/myid# hadoop-ha-03echo 3 >> /opt/software/zookeeper-3.4.10/zoo_data/myid
8. 启动zk集群
# 分别在zk的各节点上执行cd /opt/software/zookeeper-3.4.10/bin./zkServer.sh start./zkServer.sh stop./zkServer.sh status
5. Hadoop配置
注意:主节点上配置完成后分发至其他节点。
创建所需文件夹
# 主节点(hadoop-ha-01)执行su hadoop# 若非第一次创建,则需要先清理相关目录rm -rf /opt/software/hadoop-2.7.2/tmp/rm -rf /opt/software/hadoop-2.7.2/dfs/rm -rf /opt/software/hadoop-2.7.2/checkpoint/rm -rf /opt/software/hadoop-2.7.2/logs/mkdir -p /opt/software/hadoop-2.7.2/tmpmkdir -p /opt/software/hadoop-2.7.2/dfs/journalnode_datamkdir -p /opt/software/hadoop-2.7.2/dfs/editsmkdir -p /opt/software/hadoop-2.7.2/dfs/datanode_datamkdir -p /opt/software/hadoop-2.7.2/dfs/namenode_data
1. hadoop-env.sh
vi ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
配置如下:
export JAVA_HOME=/opt/moudle/jdk1.8.0_221export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.2/etc/hadoop
2. core-site.xml
vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
配置如下:
<configuration><property><!--指定hadoop集群在zookeeper上注册的节点名--><name>fs.defaultFS</name><value>hdfs://hacluster</value></property><property><!--用来指定hadoop运行时产生文件的存放目录--><name>hadoop.tmp.dir</name><value>/opt/software/hadoop-2.7.2/tmp</value></property><property><!--设置缓存大小,默认4kb--><name>io.file.buffer.size</name><value>4096</value></property><property><!--指定zookeeper的存放地址 --><name>ha.zookeeper.quorum</name><value>hadoop-ha-01:2181,hadoop-ha-02:2181,hadoop-ha-03:2181</value></property></configuration>
3. hdfs-site.xml
指定副本系数和hdfs操作权限。
vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
配置如下:
<configuration><property><!--数据块默认大小128M--><name>dfs.block.size</name><value>134217728</value></property><property><!--副本数量,不配置的话默认为3--><name>dfs.replication</name><value>1</value></property><property><!--namenode节点数据(元数据)的存放位置--><name>dfs.name.dir</name><value>/opt/software/hadoop-2.7.2/dfs/namenode_data</value></property><property><!--datanode节点数据(元数据)的存放位置--><name>dfs.data.dir</name><value>/opt/software/hadoop-2.7.2/dfs/datanode_data</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.datanode.max.transfer.threads</name><value>4096</value></property><property><name>dfs.nameservices</name><value>hacluster</value></property><property><!-- hacluster集群下有两个namenode,分别为nn1,nn2 --><name>dfs.ha.namenodes.hacluster</name><value>nn1,nn2</value></property><!-- nn1的rpc、servicepc和http通信 --><property><name>dfs.namenode.rpc-address.hacluster.nn1</name><value>hadoop-ha-01:9000</value></property><property><name>dfs.namenode.servicepc-address.hacluster.nn1</name><value>hadoop-ha-01:53310</value></property><property><name>dfs.namenode.http-address.hacluster.nn1</name><value>hadoop-ha-01:50070</value></property><!-- nn2的rpc、servicepc和http通信 --><property><name>dfs.namenode.rpc-address.hacluster.nn2</name><value>hadoop-ha-02:9000</value></property><property><name>dfs.namenode.servicepc-address.hacluster.nn2</name><value>hadoop-ha-02:53310</value></property><property><name>dfs.namenode.http-address.hacluster.nn2</name><value>hadoop-ha-02:50070</value></property><property><!-- 指定namenode的元数据在JournalNode上存放的位置 --><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop-ha-01:8485;hadoop-ha-02:8485;hadoop-ha-03:8485;hadoop-ha-04:8485;hadoop-ha-05:8485/hacluster</value></property><property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><name>dfs.journalnode.edits.dir</name><value>/opt/software/hadoop-2.7.2/dfs/journalnode_data</value></property><property><!-- namenode操作日志的存放位置 --><name>dfs.namenode.edits.dir</name><value>/opt/software/hadoop-2.7.2/dfs/edits</value></property><property><!-- 开启namenode故障转移自动切换 --><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><!-- 配置失败自动切换实现方式 --><name>dfs.client.failover.proxy.provider.hacluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><!-- 配置隔离机制 --><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><!-- 使用隔离机制需要SSH免密登录 --><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hadoop/.ssh/id_rsa</value></property><property><!--hdfs文件操作权限,false为不验证--><name>dfs.permissions</name><value>false</value></property></configuration>
4. mapred-site.xml
cp ${HADOOP_HOME}/etc/hadoop/mapred-site.xml.template ${HADOOP_HOME}/etc/hadoop/mapred-site.xml vi ${HADOOP_HOME}/etc/hadoop/mapred-site.xml配置如下:
<configuration> <property> <!--指定mapreduce运行在yarn上--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!--配置任务历史服务器地址--> <name>mapreduce.jobhistory.address</name> <value>hadoop-ha-01:10020</value> </property> <property> <!--配置任务历史服务器web-UI地址--> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-ha-01:19888</value> </property> <property> <!--开启uber模式--> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> </configuration>5. yarn-site.xml
vi ${HADOOP_HOME}/etc/hadoop/yarn-site.xml配置如下:
<configuration> <property> <!-- 开启Yarn高可用 --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 指定Yarn集群在zookeeper上注册的节点名 --> <name>yarn.resourcemanager.cluster-id</name> <value>hayarn</value> </property> <property> <!-- 指定两个ResourceManager的名称 --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <!-- 指定rm1的主机 --> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop-ha-01</value> </property> <property> <!-- 指定rm2的主机 --> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop-ha-03</value> </property> <property> <!-- 配置zookeeper的地址 --> <name>yarn.resourcemanager.zk-address</name> <value>hadoop-ha-01:2181,hadoop-ha-02:2181,hadoop-ha-03:2181</value> </property> <property> <!-- 开启Yarn恢复机制 --> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!-- 配置执行ResourceManager恢复机制实现类 --> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <!--指定主resourcemanager的地址--> <name>yarn.resourcemanager.hostname</name> <value>hadoop-ha-03</value> </property> <property> <!--NodeManager获取数据的方式--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <!--开启日志聚集功能--> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <!--配置日志保留7天--> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>6. slaves
vi ${HADOOP_HOME}/etc/hadoop/slaves配置如下:
hadoop-ha-01 hadoop-ha-02 hadoop-ha-03 hadoop-ha-04 hadoop-ha-056. 分发
scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop-ha-02:/opt/software/ scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop-ha-03:/opt/software/ scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop-ha-04:/opt/software/ scp -r /opt/software/hadoop-2.7.2/ hadoop@hadoop-ha-05:/opt/software/5. 启动集群
1. 启动ZooKeeper集群
# 分别在zk的各节点上执行 cd /opt/software/zookeeper-3.4.10/bin ./zkServer.sh start ./zkServer.sh stop ./zkServer.sh status2. 启动JournalNode集群
# 分别到各节点执行 hadoop-daemon.sh start journalnode3. HDFS格式化
# NameNode主节点执行 hdfs namenode -format4. NameNode元数据同步
# 将NameNode主节点的元数据同步至NameNode副节点 scp -r /opt/software/hadoop-2.7.2/dfs/namenode_data/current/ hadoop@hadoop-ha-02:/opt/software/hadoop-2.7.2/dfs/namenode_data/5. 启动ZKFC服务
# NameNode主节点、NameNode副节点,二者只能选择一个节点执行 hdfs zkfc -formatZK6. 安装psmisc服务
# NameNode主节点、NameNode副节点 sudo yum -y install psmisc7. 启动HDFS主节点
# NameNode主节点执行 start-dfs.sh8. 启动YARN主节点
# YARN主节点执行 start-yarn.sh9. 启动YARN副节点及历史任务服务器
# hadoop-ha-01 yarn-daemon.sh start resourcemanager mr-jobhistory-daemon.sh start historyserver6. 验证
进程查看 ```bash [hadoop@hadoop-ha-01 ~]$ jps
QuorumPeerMain DFSZKFailoverController ResourceManager NameNode NodeManager DataNode JournalNode JobHistoryServer
[hadoop@hadoop-ha-02 ~]$ jps
[hadoop@hadoop-ha-03 ~]$ jps
[hadoop@hadoop-ha-04 ~]$ jps
[hadoop@hadoop-ha-05 ~]$ jps
- **Web UI**
- **NameNode WebUI**:[http://192.168.0.99:50070](http://192.168.0.99:50070)
- **NameNode WebUI**:[http://192.168.0.99:50072](http://192.168.0.99:50072)
- **ResourceManager WebUI**:[http://192.168.0.99:8088](http://192.168.0.99:8088)
- **ResourceManager WebUI**:[http://192.168.0.99:8083](http://192.168.0.99:8083)
- **HistoryServer WebUI**:[http://192.168.0.99:19888](http://192.168.0.99:19888)
<a name="3c2k9"></a>
## 7. 测试集群
提交 Hadoop 内置的计算 Pi 的示例程序为例,在任何一个节点上执行都可以,命令如下:
```bash
hadoop jar /opt/software/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar pi 11 24
任务完成后可以在任务历史服务器(端口19888)中找到相应的job:http://192.168.0.99:19888。
8. 提交镜像到公仓
# 登录公仓
docker login --username=alypolarisbigdata registry.cn-qingdao.aliyuncs.com
# 镜像tag
docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop-ha-01" hadoop-ha-01 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-01
docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop-ha-02" hadoop-ha-02 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-02
docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop-ha-03" hadoop-ha-03 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-03
docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop-ha-04" hadoop-ha-04 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-04
docker commit -a "polaris<450733605@qq.com>" -m "This is backup for hadoop-2.7.2 hadoop-ha-05" hadoop-ha-05 registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-05
docker images |grep hadoop-2.7.2-ha
# 镜像推送
docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-01
docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-02
docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-03
docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-04
docker push registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-05
# 拉取镜像
docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-01
docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-02
docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-03
docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-04
docker pull registry.cn-qingdao.aliyuncs.com/polaris-docker/hadoop-ha:hadoop-2.7.2-ha-05
参考
B站:Docker环境下DIY你的Hadoop镜像
https://www.bilibili.com/video/BV1C64y1T7FZ?p=1
微信:Docker环境下Hadoop单机伪分布式
https://mp.weixin.qq.com/s/pkS2nWI8RY22AnsHWRTZug
微信:Docker环境下Hadoop完全分布式
https://mp.weixin.qq.com/s/vfUdLohUwmsD4ecm1ldNJw
微信:Docker之镜像拉取、删除及重命名
https://mp.weixin.qq.com/s/7L9aelZRbPl-67jyntdNXg
微信:Docker环境下HA(高可用)-Hadoop集群
https://mp.weixin.qq.com/s/PTLRXsaPj7jtVFiSJPYrSQ
微信:DockerCompose搭建Zookeeper集群
https://mp.weixin.qq.com/s/9wNzofl8hdJlZtqijq7PNQ

若有收获,就点个赞吧
0 人点赞
