namespaces
namespace提供一种资源隔离方案。PID、IPC、Network等系统资源不再是全局性的,而是属于特定的 Namespace。每个 Namespace 里面的资源对其他Namespace都是透明的。要创建新的Namespace,只需要在调用 clone 时指定相应的flag。Linux Namespaces机制为实现基于容器的虚拟化技术提供了很好的基础,LXC就是利用这一特性实现了资源的隔离。不同 container 内的进程属于不同的 Namespace,彼此透明,互不干扰。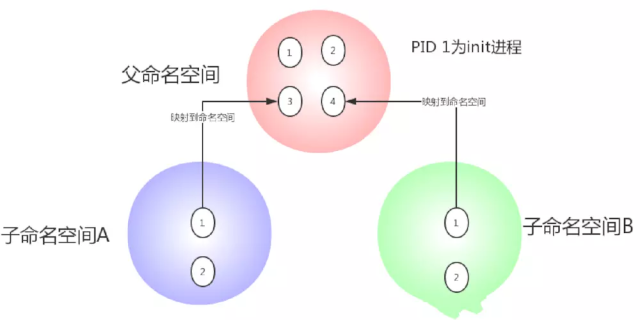
Linux内核2.4.19中开始陆续引用了namespace概念。目的是将某个特定的全局系统资源(global system resource)通过抽象方法使得namespace中的进程看起来拥有它们自己的隔离的全局系统资源实例 命名空间是Linux内核强大的特性。每个容器都有自己的命名空间,运行在其中的应用都是在独立操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
| namespace | 系统调用参数 | 隔离内容 | 内核版本 | 备注 |
|---|---|---|---|---|
| UTS | CLONE_NEWUTS | 主机名和域名 | 2.6.19 | |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 | 2.6.19 | 在相同的名称空间中的进程才能通过IPC实现进程间通信。 |
| PID | CLONE_NEWPID | 进程编号 | 2.6.24 | 在每个名称空间中必须有一个进程ID为1的进程,它是所有进程的父进程,即init进程,所以要实现用户空间隔离,就需要让每个用户空间中进程,以为自己是运行在init进程下的。 |
| Network | CLONE_NEWNET | 网络设备、网格线、端口等 | 2.6.29 | |
| Mount | CLONE_NEWNS | 挂载点(文件系统) | 2.4.19 | |
| User | CLONE_NEWUSER | 用户和用户组 | 3.8 | 要让每个用户空间中的进程以为自己是运行在独立的主机中,那就必须实现每个用户空间中都一个UID为0的用户, 但该用户在真实系统中,却是一个普通用户。 |
注意:由于User namespace是从3.8内核版本才引入的,**Docker官方建议使用3.8+系统内核。CentOS6.x内核小于3.8,不推荐使用。CentOS7是linux 3.10内核,考虑到资源和命名空间隔离、文件系统的支持,D**ocker Swarm和K8s建议使用Centos 7.4 以上的版本。
cgroup
Control Groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory, io 等等)的机制。最初由google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC。
| 资源 | 描述 |
|---|---|
| blkio | 块设备IO |
| cpu | CPU、Core、超线程 |
| cpuacct | CPU资源使用报告 |
| cpuset | 多处理器平台上的CPU集合 |
| devices | 设备访问 |
| freezer | 挂起或恢复任务 |
| memory | 内存用量及报告 |
| perf_event | 对cgroup中的任务进行统一性能测试 |
| net_cls | cgroup中的任务创建的数据报文的类别标识符 |
UnionFS
UnionFS顾名思义,可以把文件系统上多个目录(分支)内容联合挂载到同一个目录下,而目录的物理位置是分开的。要理解unionFS,我们首先需要先了解bootfs和rootfs1.boot file system (bootfs) 包含操作系统boot loader和kernel。用户不会修改这个文件系统,一旦启动成功后,整个Linux内核加载进内存,之后bootfs会被卸载掉,从而释放内存。同样的内核版本不同Linux发行版,其bootfs都是一直的2.root file system (rootfs) 包含典型的目录结构(/dev/,/proc,/bin,/etc,/lib,/usr,/tmp)Linux系统在启动时,rootfs首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。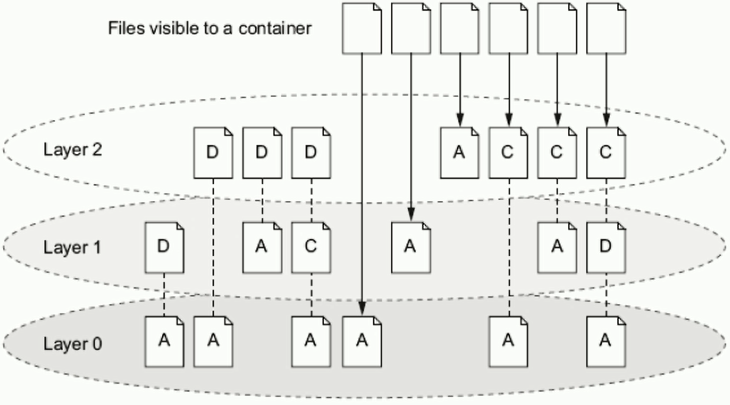
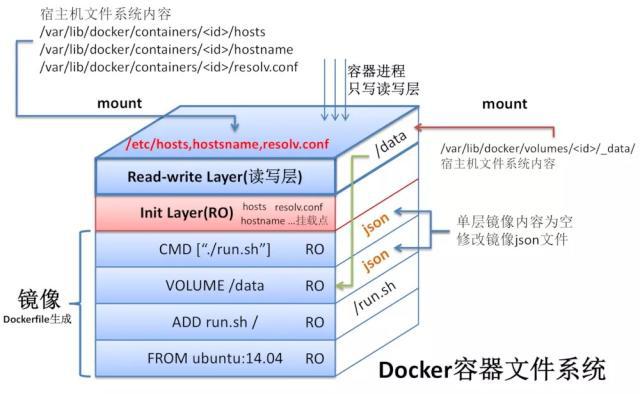
Φ 存储驱动介绍
Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享一个image。但是由于AUFS未并入Linux内核,且只支持Ubuntu,考虑到兼容性问题,在Docker 0.7 版本中引入了存储驱动,目前,Docker支持AUFS、Btrfs、Devicemapper、OverlayFS、ZFS五种存储驱动。**
| 存储驱动 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| AUFS | 联合文件系统、未并入内核主线、文件级存储 | 作为docker的第一个存储驱动,已经有很长的历史,比较稳定,且在大量的生产中实践过,有较强的社区支持 | 有多层,在做写时复制操作时,如果文件比较大且存在比较低的层,可能会慢一些 | 大并发但少IO的场景 |
| overlayFS | 联合文件系统、并入内核主线、文件级存储 | 只有两层 | 不管修改的内容大小都会复制整个文件,对大文件进行修改显示要比小文件消耗更多的时间 | 大并发但少IO的场景 |
| Devicemapper | 并入内核主线、块级存储 | 块级无论是大文件还是小文件都只复制需要修改的块,并不是整个文件 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本,在很多容器启停的情况下可能会导致磁盘溢出 | 适合io密集的场景 |
| Btrfs | 并入linux内核、文件级存储 | 可以像devicemapper一样直接操作底层设备,支持动态添加设备 | 不支持共享存储,当有多个容器读同一个文件时,需要生成多个复本 | 不适合在高密度容器的paas平台上使用 |
| ZFS | 把所有设备集中到一个存储池中来进行管理 | 支持多个容器共享一个缓存块,适合内存大的环境 | COW使用碎片化问题更加严重,文件在硬盘上的物理地址会变的不再连续,顺序读会变的性能比较差 | 适合paas和高密度的场景 |

若有收获,就点个赞吧
0 人点赞
